






文章目录
Python文件读写基础
文件概念
文件就是操作系统提供给应用程序来操作硬盘虚拟概念,用户或应用程序通过操作文件,可以将自己的数据永久保存下来。
操作文件的流程
①打开文件,得到文件句柄并赋值给一个变量,默认打开的模式是‘r’(即只读模式)
②通过句柄对文件进行操作
③关闭文件
示例代码如下:
f=open('a.txt','r')
data=f.read()
f.close()
open函数
open的语法格式为:
open(filename,mode)
filename:包含了你要访问的文件名称的字符串值。
mode:决定了打开文件的模式。只读、写入和追加等。所有可取值见如下的完全列表。
mode
打开文件的模式共包含四种:
①r——只读模式(默认模式,文件必须存在,不存在则抛出异常)
②w——只写模式(不可读;不存在则创建;存在则清空内容)
③a——追加写模式(不可读;不存在则创建;存在则只追加内容)
④r+——同时用于读写
mode参数是可选的;‘r’将是默认值。
绝对路径和相对路径

绝对路径:如3,即完整的文件路径(路径3,4,5表达方式是等价的)
相对路径:如1、2,文件同该代码在同一个文件夹下
close函数
f.close()
在文本文件中,只会相对于文件起始位置进行定位。当你处理完一个文件后,调用f.close()来关闭文件并释放系统的资源,如果尝试再调用该文件,则会抛出异常。
读写文件
read函数
read函数的表达式为:
f.read(size)
①为了读取一个文件的内容,调用read函数这将读取一定数目的数据,然后作为字符串或字节对象返回。
②size是一个可选的数字类型的参数。当size被忽略了或者为负数,那么该文件的所有内容都将被读取并返回。示例如下(示例中文本文件已存在,否则会报错):

f=open('D:/new.txt','r')
str=f.read()
print(str)
f.close()

readline函数
此函数会从文件中读取单独的一行。换行符为’\n’。f.readline()如果返回一个空字符串,说明已经读取到最后一行。
readlines函数
该函数将返回该文件中包含的所有行。
如果设置可选参数sizehint,则读取指定长度的字节,并且将这些字节按行分割。
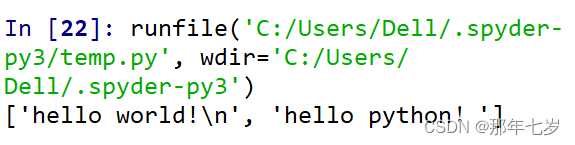
两函数示例如下:
f=open('D:/new.txt','r',encoding='utf-8')
str=f.readline()
print(str)
#str=f.readlines()
#print(str)
f.close()

f=open('D:/new.txt','r',encoding='utf-8')
#str=f.readline()
#print(str)
str=f.readlines()
print(str)
f.close()
write函数
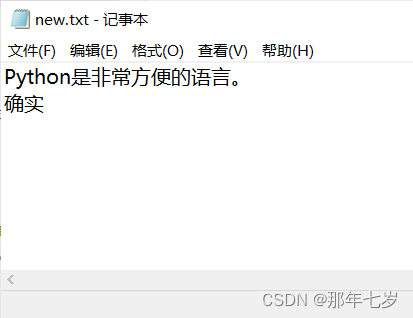
将string写入到文件中,然后返回写入的字符数。该函数会覆盖原文件。示例如下:
f=open('D:/new.txt','w',encoding='utf-8')
f.write('Python是非常方便的语言。\n确实\n')
f.close()
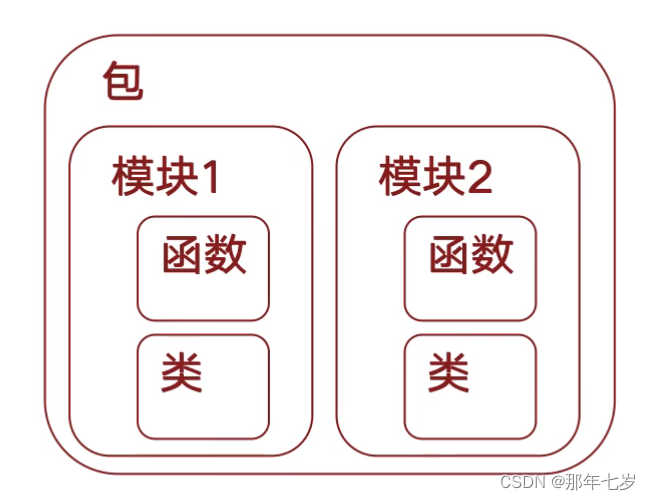
Python的模块
Python 程序框架
将一个程序分割为源代码文件的集合,以及将这些部分连接在一起的方法。
Python的源代码文件:*.py
一个py文件是一个模块(module)
多个模块可以组成一个包(package)
包的本质就是一个文件夹,那么文件夹唯一的功能就是将文件组织起来
(必须包含一个__init__.py的文件)
组成方式如图所示:
模块
模块是Python中的最高级别组织单元(类比函数),它将程序代码和数据封装起来以便复用。如图所示:
模块的三个角色:
①代码重用
②系统命名空间的划分(模块可理解为变量名的封装,即模块就是命名空间)
③实现共享服务和数据
导入模块从本质上讲,就是在一个文件中载入另一个文件,并且能够读取那个文件的内容。
导入模块/包
导入模块或包有两种方式:
①import module_name
即import+模块名称
②from module_name import name
即from+模块名称+import+模块中某些内容的名字(函数、变量等)
#三种具体实现
import x #1
from x import * #2 含义为导入包中所有元素
from x import a,b,c #3 含义为导入包中指定的a,b,c三个变量
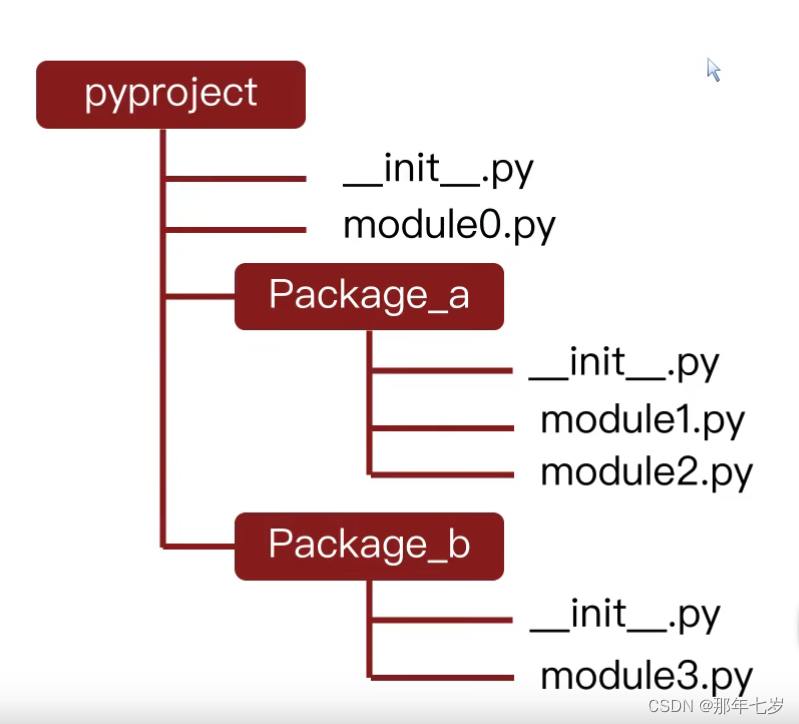
我们仍然用这张图来举例子:
import Package_a.module1 #导入包a中的模块1,如果要导入模块a下的某些元素,继续用'.'运算符来索引并导入
import Package_b.module3 #导入包b中的模块3
from Package_a.module1 import * #导入包a中模块1的全部内容
import module0 #导入模块0.因为模块0不在包中,因此可以直接导入
from module0 import * #导入模块0
两种导入方式区别
import方式
import Package_a.module1 as m1
t=m1.test()
这种方式我们是将包中的模块封装进行导入,如果要用到模块中的函数或者变量必须用到模块的名称或者给包起一个别称(as操作)后通过别称进行实体调用。
from方式
from Package_a.module1 import *
t=test()
对比import方式,from方式在使用模块中的变量或函数时则无需模块的名字,可直接使用模块中的实体。
二者对比
这样看下来from import的方式与import方式相比会用起来更加的方便,因为他无需用模块名进行操作。但这种方式是将包中的所有内容都导入进来,破坏了包的封装性。所以当我们继续编写代码的时候,并不知道当前包中是否会有同名的变量或者函数,所以更容易发生冲突。
所以这里更推荐使用import方式进行包的导入。
模块导入与搜索机制
模块导入
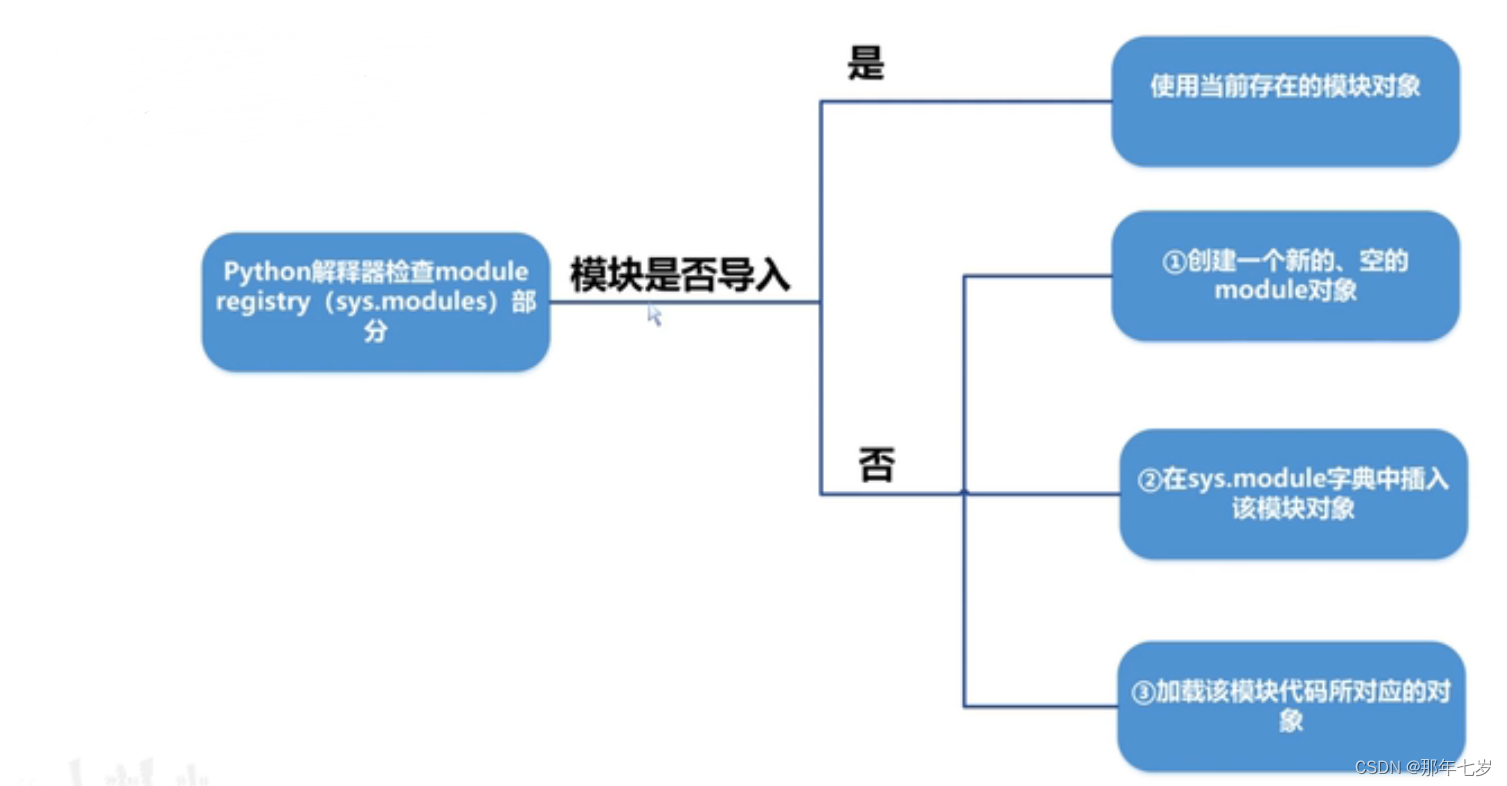
Python中在导入模块时,解释器会检查模块注册表来判断当前模块是否已经被导入。若模块已被导入,那么会终止此次导入来使用当前已存在的模块对象;若模块未被导入,进行以下三步(上图):
①创建一个新的、空的module对象
②在sys.module字典中插入该模块对象
③加载该模块代码所对应的对象
模块搜索路径

以上四个组件组合起来就变成了sys.path,其保存了模块搜索路径在机器上的实际配置,可以通过打印内置的sys.path列表来查看这些路径。
搜索路径①和③是系统自定义的,而②和④可以用于拓展路径,从而加入自己的源代码目录。
Numpy基础
Numpy是一个开源的Python科学计算基础库,也就是Python的matlab,它包含:
①一个强大的N维数组对象 ndarray
②广播功能函数
③整合C/C++/Fortran代码的工具
④线性代数、傅里叶变换、随机数生成等功能
Numpy时Scipy、Pandas等数据处理或科学计算库的基础
Numpy的导入
Numpy作为一个模块,通常的导入方式如下:
import numpy as np #np为模块别名
尽管别名可以省略或者修改,但仍建议使用上述约定的别名
ndarray
ndarray(array)是一个多维数组对象,由两部分构成:
①实际的数据
②描述这些数据的元数据(数据维度、数据类型等)
ndarray数组一般要求所有元素类型相同(同质),数组下标从0开始(和c语言中相同)。
ndarray创建方法
从Python中的列表、元组等类型创建ndarray数组,即x=np.array(list/tuple),具体代码如下:
import numpy as np
list1=[1,2,3,4]
x=np.array(list1)
print(list1)
print(type(list1))
print(x)
print(type(x))
通过numpy中的array函数可以从列表或者元组中提取出元素放入数组中,上面代码的运行结果为:
不难看出ndarray(数组)类型和列表类型的区别,即有无逗号。
我们也可以通过array函数来创建二维数组,实现代码如下:
import numpy as np
x=np.array([[1,2,3,4],[5,6,7,8]])
print(x)
print(type(x))

不难看出,想要创建二维数组,则是使array函数的参数变为一个二维列表,则可以实现二维数组的创建。
ndarray索引方法
ndarray的索引方法包含以下两种:
①切片索引:切片索引和对列表list的切片索引一致.
②布尔值索引:通过添加条件判断数组中每个值的 真/假 转为布尔值,再对原数组进行索引,判断为真(True)时会被抽取出来。示例如下:
import numpy as np
np_ar=np.array([[1,2,3],[4,5,6]])
c=np_ar[np_ar>2]
print(c)

ndarray常用函数
arange函数
arange函数的作用为产生连续的序列,其使用范式为:arange([start,]stop[,step]),其中开始数字为start(默认为0),stop为停止数字(不包括),step为每次跨越的步长(默认为1),其中放在方括号中的值可省略。具体实现的代码及其效果如下:
import numpy as np
x1=np.arange(5)
x2=np.arange(3,7)
x3=np.arange(1,10,2)
print('x1=',x1)
print('x2=',x2)
print('x3=',x3)

linspace函数
linspace函数也用于产生连续的序列,其使用范式为linspace(start,stop,num),其中start和stop仍为开始和结束的数字,而num的含义为将start到stop这个区间平均分为num个数,每个数之间的间距相同,且这个num要包括start和stop两个数。具体实现的代码及其效果如下:
import numpy as np
x1=np.linspace(1,10,5)
print('x1=',x1)

arange函数和linspace函数是生成坐标轴或者采样数据的常用函数,因为他们可以产生连续的、等间隔的数据。
ndarray的切片、重构和转置操作
切片操作
ndarray的切片方法和列表非常相似,这里我们借用二维数组来进行举例:
import numpy as np
a=[[1,2,3],[4,5,6],[7,8,9]]
print(a)
np_ar=np.array(a)
print(np_ar[0:2,1:3])

数组切片操作中逗号前为行,也就是切片后保留哪几行,这里我们保留了0行和1行;逗号后为列,也就是保留了1列和2列,所以切片结果为第0行的2和3以及第1行的5和6。
重构操作
重构操作用到了处理array的reshape函数,reshape函数的使用范式为reshape(row,column),但需要注意的是对数组进行重构需要保证row和column之积与原数组中的元素个数相等,即需要保证数组中元素个数不变。具体实现的代码及其效果如下:
import numpy as np
a=[[1,2,3,4],[5,6,7,8],[9,10,11,12]]
print(a)
np_ar=np.array(a)
np_ar=np_ar.reshape(4,3)
print(np_ar)
np_ar=np_ar.reshape(12,1)
print(np_ar)

可以看出,reshape函数是将原数组拉直,然后再根据参数进行切开重组,在后面机器学习中的图像处理时经常用到。
转置操作
转置操作为函数T。我们知道,转置就是使原来的行变为列,原来的列变为行。具体实现的代码及其效果如下:
import numpy as np
a=[[1,2,3,4],[5,6,7,8],[9,10,11,12]]
print(a)
np_ar=np.array(a)
np_ar=np_ar.T
print(np_ar)

结束语
本篇博客主要介绍了Python中的文件读写、模块化(封装)以及numpy基础等内容,后面将继续更新Python绘图基础、pandas基础等内容,感谢观看。















 1933
1933











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









