






一、算例说明
选用教材《水利水电工程优化调度》(唐德善 唐彦 黄显峰 史记毅超 等编著)(中国水利水电出版社)上对应P43页-P47页的例题3-3进行代码验证。
①具体例题资料
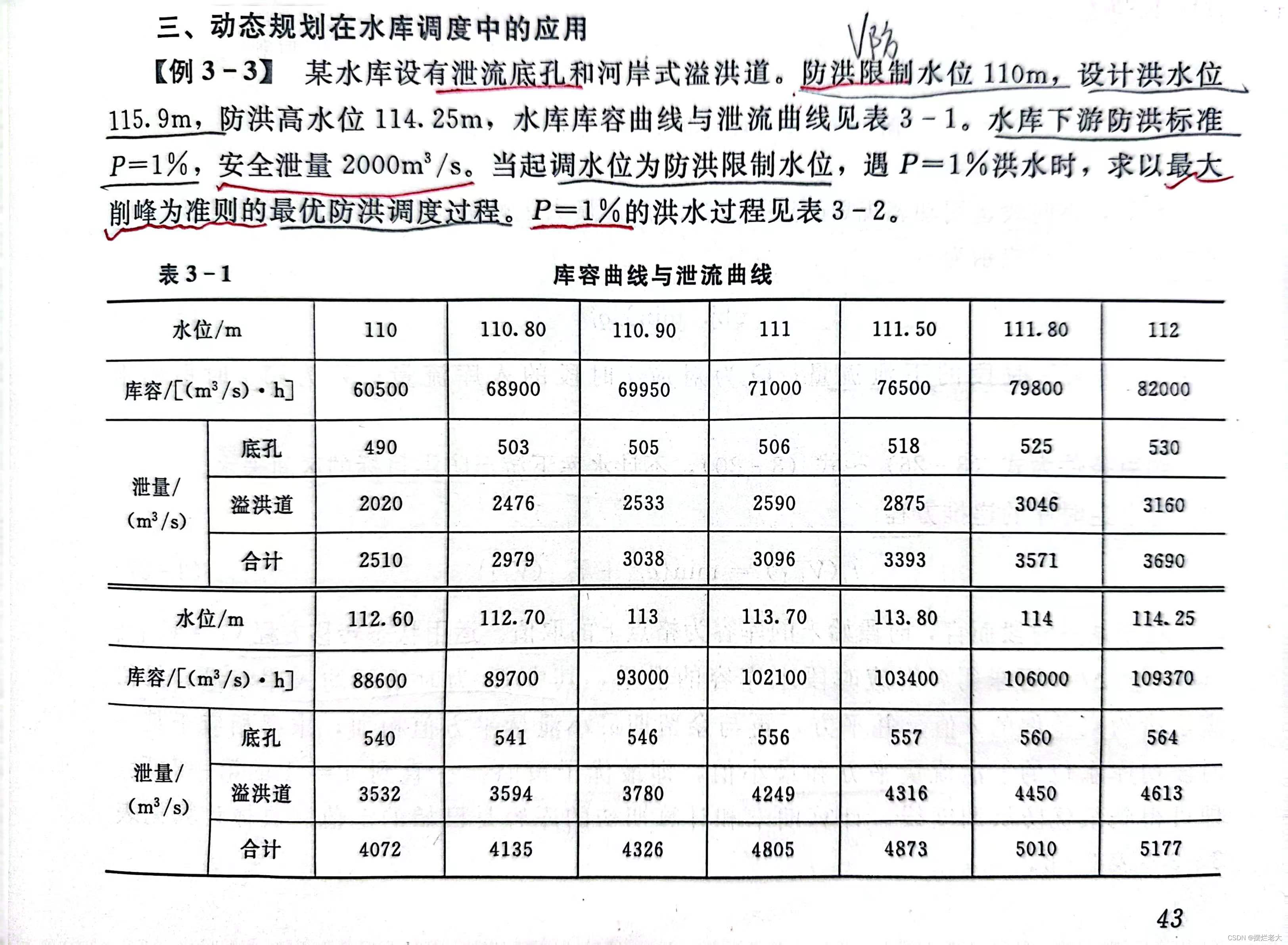
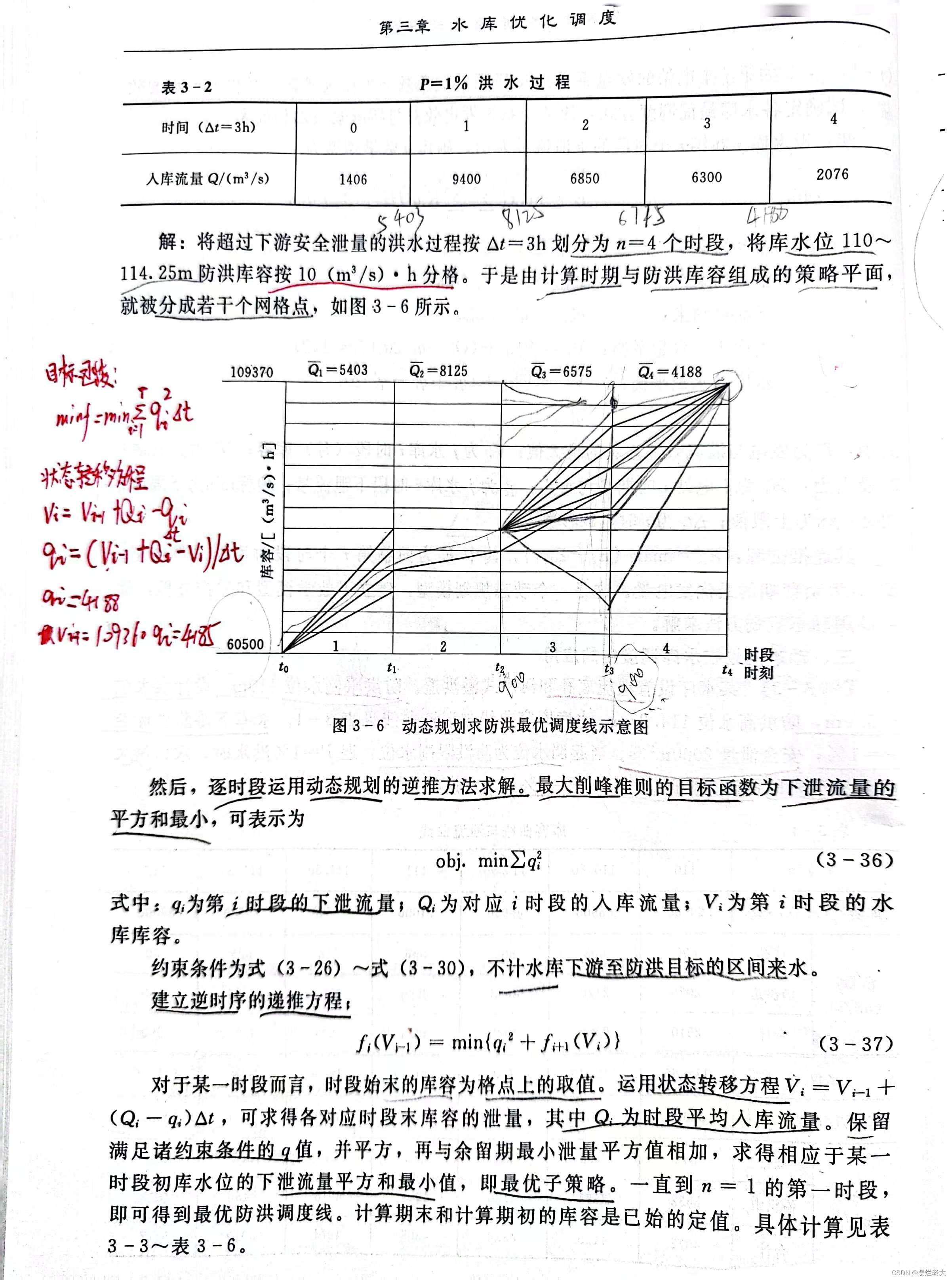
②思路说明
我们需要关注的信息是:
1)水库的防洪限制水位(起调水位)对应库容60500(m³/s)·h、防洪高水位对应库容109370(m³/s)·h;
2)百年一遇设计洪水的来水过程;
3)安全泄量为q安=2000m³/s;
4)要求以最大削峰为准则;
针对上述重点信息,对例题资料做如下处理:
1)动态规划一般逆时序从后往前推,所以将109370作为起点,将60500作为终点;
2)根据图3-6的示意图,可以看出要将相应时刻来水流量转化为时段平均来水流量;
3)安全泄量是每个阶段下泄流量的要求,要保证下泄流量数值在2000附近;
4)最大削峰准则的目标函数为下泄流量的平方和最小,对应公式3-36,结合各种约束条件以及不计区间来水的假定,建立逆时序递推方程,对应公式3-37;
二、代码内容
- 注:以下所有代码均按顺序在同一个py文件里,方便解释才将其拆开
将动态规划阶段按照图3-6分为:
1)阶段:4个阶段(t4-t3、t3-t2、t2-t1、t1-t0)
2)状态:t0、t1、t2、t3、t4时刻对应的库容
3)决策:追求最小累积泄量
①将已知数据列出
各时段平均来水量以及防洪限制水位(起调水位)对应库容、防洪高水位对应库容
# 各时段来水量
come_water_1=5403
come_water_2=8125
come_water_3=6575
come_water_4=4188
# 已知防洪限制水位对应库容/t0对应库容
capacity_1=60500
# 已知防洪高水位对应库容/t4对应库容
capacity_5=109370
②t4-t3阶段
此阶段为初始阶段,起点已知是109370,所以只需要一个for循环。
for循环表示将t3时刻库容从109370开始,遍历至60500,步长为-10,即逐渐减小。
if条件语句是筛选出下泄流量q4与安全泄量2000m³/s的绝对差值在10以内的库容,以及对应的累计泄量平方值。
# t4-t3-------------------------------------------------
# 存储t3时刻库容
lst_capacity_4=[]
# 存储t3-t4累积泄量平方值
lst_min_4=[]
# t3对应库容
for capacity_4 in range(109370,60499,-10):
# 平均泄量
q4=(capacity_4-capacity_5+come_water_4*3)/3
# 泄量平方值
q4_square=q4**2
# 余留时期最小泄量平方值,初始为0
fVi_4_start=0
# 累计泄量平方值
fVi_4_0=q4_square+fVi_4_start
if abs(q4-2000)<10:
lst_capacity_4.append(capacity_4)
lst_min_4.append(fVi_4_0)
③t3-t2阶段
这个阶段相对复杂一些,因为t4和t3时刻的库容都是变动的,所以我们需要进行for循环的嵌套。
此外,还要对本阶段符合if条件的下泄流量q3、累积下泄流量、t4时刻(上一时刻)的库容创建3个空列表进行存储,方便后续相互利用索引查找。
最后,还要将符合if条件的t3时刻的库容进行存储,并保证其不重复,从大到小排列,以便于下一阶段的for循环进行遍历。
#t3-t2-------------------------------------------------
# 存储t2时刻库容
lst_capacity_3=[]
# 存储t2-t3累积泄量平方值
lst_min_3=[]
# 后续会提到,以下3个列表的索引值是相同的,用于后续相互的查找
lstq3=[]
lst_fVi_3_y=[]
lst_capacity_4_y=[]
# t2对应库容
for capacity_3 in range(109370,60499,-10):
lst_fVi_3 = []
for capacity_4 in lst_capacity_4:
q3=(capacity_3-capacity_4+come_water_3*3)/3
# 平均泄量
q3_square = q3 ** 2
# 余留时期最小泄量平方值(索引得到相应t3时刻库容capacity_4对应的累计泄量平方值)
fVi_3_1 = lst_min_4[lst_capacity_4.index(capacity_4)]
# 累计泄量平方值
fVi_3_0 = q3_square + fVi_3_1
if abs(q3 - 2000) <10:
# 在临时的泄量储存表里添加与2000相近的平均泄量
lstq3.append(q3)
# 下面3个列表的索引值是相同的,用于后续相互的查找
lst_fVi_3.append(fVi_3_0)
lst_fVi_3_y.append(fVi_3_0)
lst_capacity_4_y.append(capacity_4)
#只要lst_fVi_3列表中至少包含一个元素,这个条件就为真。
# 说明t2时刻库容capacity_3的这个值是有效的。
if len(lst_fVi_3) == 1:
lst_capacity_3.append(capacity_3)
# 最小累积泄量平方值
# 1、lst_fVi_3:
# 这是一个列表,如果它不为空(即至少包含一个元素),那么这个条件就为真。
# 2、lst_capacity_4.index(capacity_4) == len(lst_capacity_4) - 1:
# 这个条件检查当前遍历的capacity_4是否是lst_capacity_4列表中的最后一个元素。
# 如果是,那么这个条件就为真。
if lst_fVi_3 and lst_capacity_4.index(capacity_4) == len(lst_capacity_4) - 1:
lst_min_3.append(min(lst_fVi_3))
# 保证不重复:
# 首先,set(lst_capacity_3)会将lst_capacity_3列表转换为一个集合。
# 在Python中,集合是一个无序的、不包含重复元素的数据结构。
# 因此,转换为集合的过程会自动去除列表中的重复元素。
# 然后,list(set(lst_capacity_3))会将这个集合再转换回列表。
# 这样,得到的lst_capacity_3列表就不包含任何重复的元素了。
lst_capacity_3 = list(set(lst_capacity_3))
# 回到原来的降序排序
lst_capacity_3.sort(reverse=True)
④t2-t1阶段
此阶段和上阶段基本一样,参考上阶段的解释以及代码注释即可。
# t2-t1-------------------------------------------------
# 存储t1时刻库容
lst_capacity_2=[]
# 存储t1-t2累积泄量平方值
lst_min_2=[]
# 后续会提到,以下3个列表的索引值是相同的,用于后续相互的查找
lstq2=[]
lst_fVi_2_y=[]
lst_capacity_3_y=[]
# t1对应库容
for capacity_2 in range(109370,60499,-10):
lst_fVi_2 = []
for capacity_3 in lst_capacity_3:
q2=(capacity_2-capacity_3+come_water_2*3)/3
q2_square = q2 ** 2
# 余留时期最小泄量平方值
fVi_2_1 = lst_min_3[lst_capacity_3.index(capacity_3)]
# 累计泄量平方值
fVi_2_0 = q2_square + fVi_2_1
if abs(q2 - 2000) <10:
# 在临时的泄量储存表里添加与2000相近的平均泄量
lst_fVi_2.append(fVi_2_0)
# 以下3个列表的索引值是相同的,用于后续相互的查找
lstq2.append(q2)
lst_fVi_2_y.append(fVi_2_0)
lst_capacity_3_y.append(capacity_3)
if len(lst_fVi_2)==1:
lst_capacity_2.append(capacity_2)
# 最小累积泄量平方值
if lst_fVi_2 and lst_capacity_3.index(capacity_3) == len(lst_capacity_3) - 1:
lst_min_2.append(min(lst_fVi_2))
# 保证不重复
lst_capacity_2 = list(set(lst_capacity_2))
# 回到原来的降序排序
lst_capacity_2.sort(reverse=True)
⑤t1-t0阶段
这是最后一个阶段了,相比于前两个阶段,该阶段的终点是60500,所以代码的处理也相对简单一些。
# t1-t0-------------------------------------------------
lst_capacity_1=[]
lst_fVi_1=[]
lstq1=[]
# t0对应库容
capacity_1=60500
for capacity_2 in lst_capacity_2:
q1=(capacity_1-capacity_2+come_water_1*3)/3
# 最大削峰
# 平均泄量
q1_square = q1 ** 2
# 余留时期最小泄量平方值
fVi_1_1 = lst_min_2[lst_capacity_2.index(capacity_2)]
# 累计泄量平方值
fVi_1_0 = q1_square + fVi_1_1
lstq1.append(q1)
lst_fVi_1.append(fVi_1_0)
# 最小累积泄量平方值
min_fVi_1_0=min(lst_fVi_1)
最后输出的便是最小的累积泄量平方值。
⑥对变量整合、输出最优下泄方案
这一部分比较难以相同的是如何获取最优调度方案对应的各时刻库容、各阶段下泄流量、各阶段累积泄量这就需要利用先前创建的列表进行索引来相互寻找来获取
# t0时库容
capacity_1=60500
# t1时库容
capacity_2=lst_capacity_2[lst_fVi_1.index(min_fVi_1_0)]
# t0-t1平均泄量
q_1=lstq1[lst_capacity_2.index(capacity_2)]
# t2时库容
min_fvi2=lst_min_2[lst_capacity_2.index(capacity_2)]
capacity_3=lst_capacity_3_y[lst_fVi_2_y.index(min_fvi2)]
# t1-t2平均泄量
q_2=lstq2[lst_fVi_2_y.index(min_fvi2)]
# t3时库容
min_fvi3=lst_min_3[lst_capacity_3.index(capacity_3)]
capacity_4=lst_capacity_4_y[lst_fVi_3_y.index(min_fvi3)]
# t2-t3平均泄量
q_3=lstq3[lst_fVi_3_y.index(min_fvi3)]
# t4时库容
min_fvi4=lst_min_4[lst_capacity_4.index(capacity_4)]
capacity_5=109370
# t3-t4平均泄量
q_4=(capacity_4-109370+come_water_4*3)/3
print("t0时库容",capacity_1)
print("t0-t1时段平均泄量",q_1)
print("t1时库容",capacity_2)
print("t0-t1最小累积泄量平方值:",min_fVi_1_0)
print("t1-t2时段平均泄量",q_2)
print("t2时库容",capacity_3)
print("t1-t2累计最小泄量平方值",min_fvi2)
print("t2-t3时段平均泄量",q_3)
print("t3时库容",capacity_4)
print("t2-t3累计最小泄量平方值",min_fvi3)
print("t3-t4时段平均泄量",q_4)
print("t4时库容",capacity_5)
print("t3-t4累计最小泄量平方值",min_fvi4)
print("最小累积泄量平方值:",min_fVi_1_0)
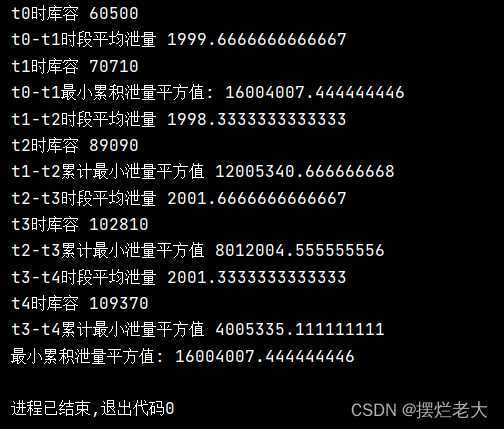
输出结果如下:
三、与案例进行结果对比
教材给出的过程及结果如下:
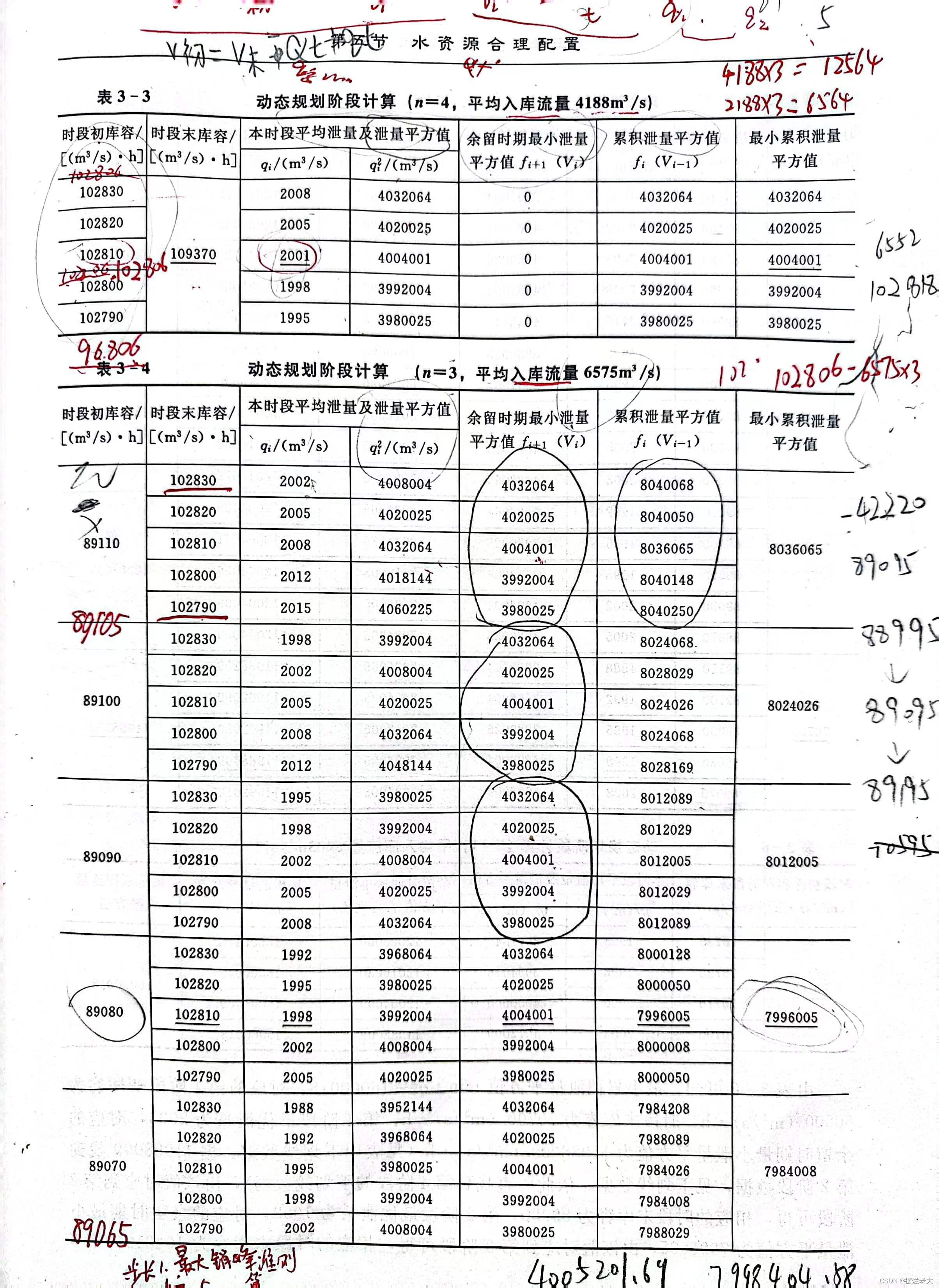
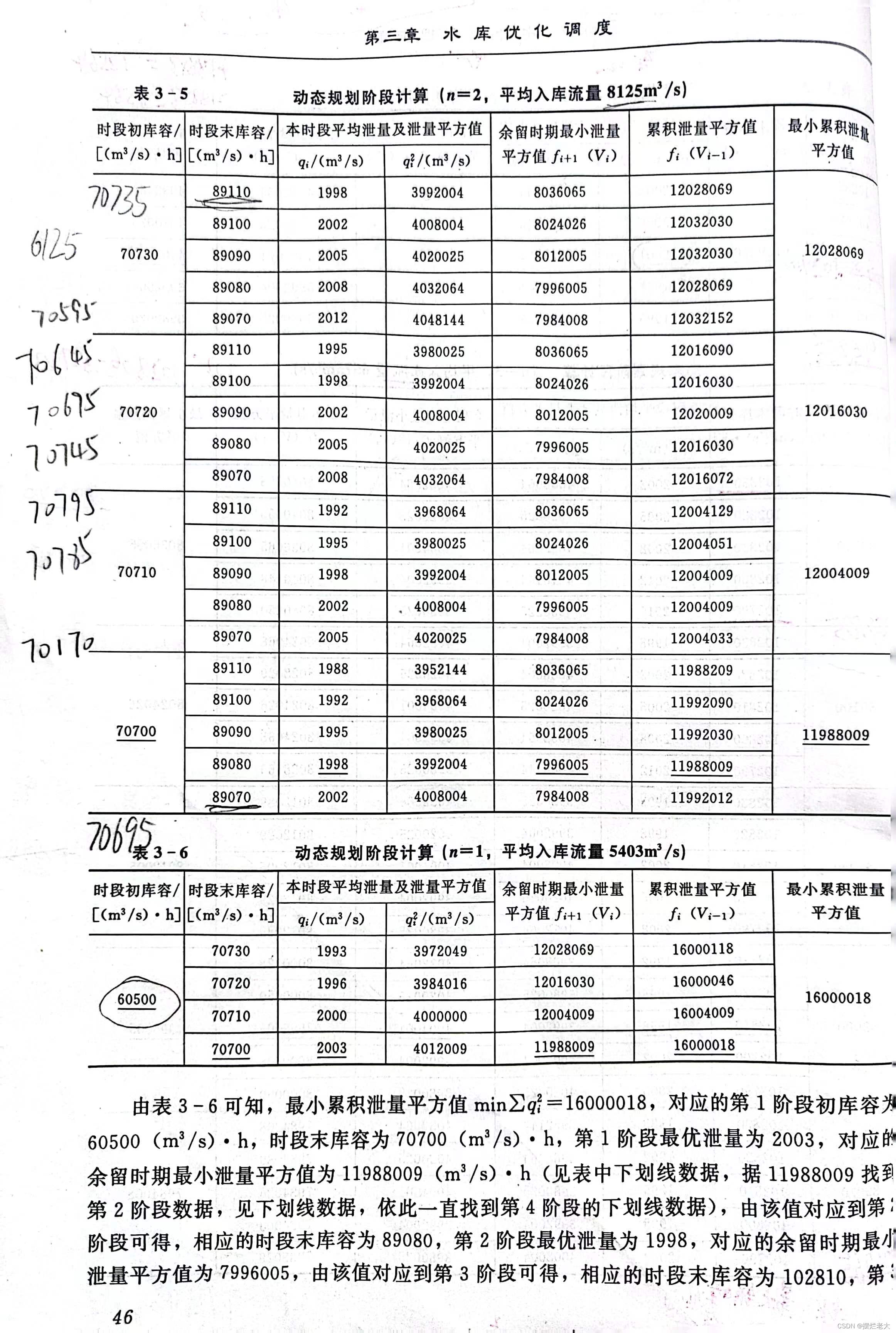
通过对比,发现Python代码结果对应最小累积泄量为16004007,教材案例所给结果为16000018,且各阶段的下泄流量方案也有略微的差别。
这是因为教材为了便于读者理解和练习,将下泄流量q进行了四舍五入的简化,这样导致了细微的差别,演算到最后也会有略微的差别。
本篇博客旨在帮助大家理解练习动态规划在水库调度中的应用,在实际的水库调度案例中将会有更为复杂的状况,实际的调度常是水库群的联合调度,且在考虑防洪的前提下,还要尽可能的兴利。
以上是全部内容,欢迎大家评论区留言,批评指正。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









