






一、集群结构
ES通常以集群方式工作,这样做不仅能够提高 ES的搜索能力还可以处理大数据搜索的能力,同时也增加了系统的
容错能力及高可用。
下图是ES集群结构的示意图:
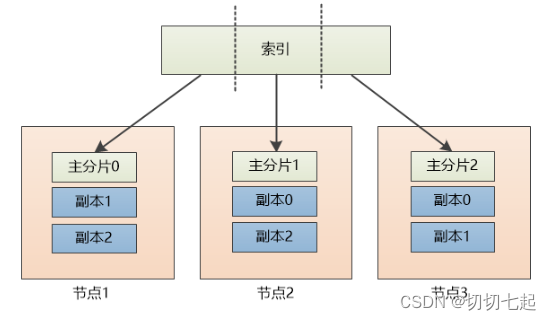
此处的设置为:每个主分片有两个副本, 如果某个节点挂了也不怕,比如节点1挂了,我们可以查询位于节点3和节点3上的副本0
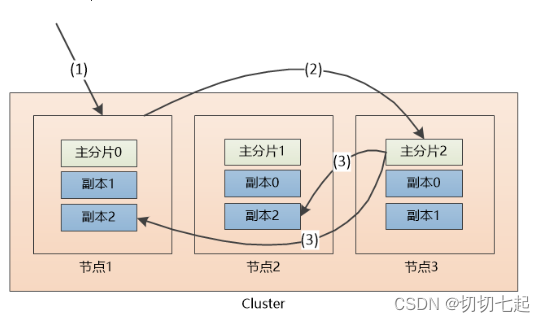
添加文档过程:
(1)假设用户把请求发给了节点1
(2)系统通过余数算法得知这个’文档’应该属于主分片2,于是请求被转发到保存该主分片的节点3
(3)系统把文档保存在节点3的主分片2中,然后将请求转发至其他两个保存副本的节点。
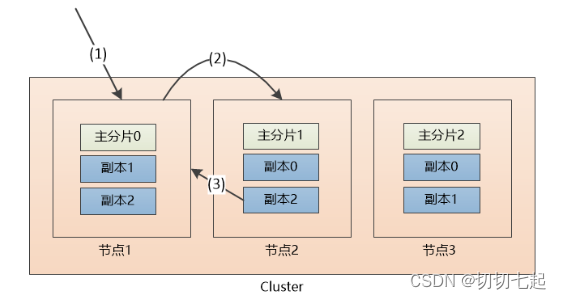
查询文档过程:
(1) 请求被发给了节点1
(2)节点1计算出该数据属于主分片2,这时候,有三个选择,分别是位于节点1的副本2, 节点2的副本2,节点3
的主分片2, 假设节点1负载均衡,采用轮询的方式,选中了节点2,把请求转发。
(3) 节点2把数据返回给节点1, 节点1 最后返回给客户端。
二、创建结点2
1、拷贝节点elasticsearch-1
全文检索Elasticsearch安装和配置_切切七起的博客-CSDN博客 (elasticsearch-1安装和配置)
2、修改elasticsearch.yml内容如下:
注意:复制的第二台elasticsearch一定要删除data目录
#配置第二台elasticsearch名字
node.name: power_shop_node_2
#配置两台elasticsearch的地址和端口号
discovery.zen.ping.unicast.hosts: ["192.168.204.132:9300", "192.168.204.133:9300"]
三、查看集群健康状态
1、查询当前集群的健康信息:
GET /_cluster/health2、结果:
{
"cluster_name": "power_shop",
"status": "green",
"timed_out": false,
"number_of_nodes": 2,
"number_of_data_nodes": 2,
"active_primary_shards": 2,
"active_shards": 4,
"relocating_shards": 0,
"initializing_shards": 0,
"unassigned_shards": 0,
"delayed_unassigned_shards": 0,
"number_of_pending_tasks": 0,
"number_of_in_flight_fetch": 0,
"task_max_waiting_in_queue_millis": 0,
"active_shards_percent_as_number": 100
}
status:用三种颜色来展示健康状态
green:索引库的每个 primary shard 和 replica shard 都是 active 的
yellow:索引库的每个 primary shard 都是 active 的,但部分的 replica shard 不是 active 的,如单节点创建
备份分配
red:不是所有的 primary shard 都是 active 状态的。
四、测试
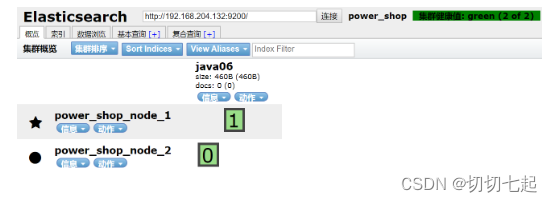
1、启动两个节点 ,测试集群健康状况和分片
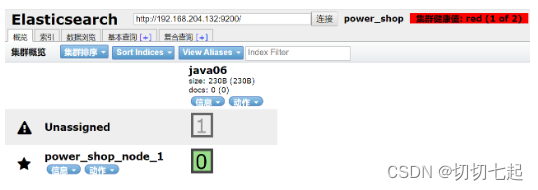
2、关闭节点2,测试集群状态
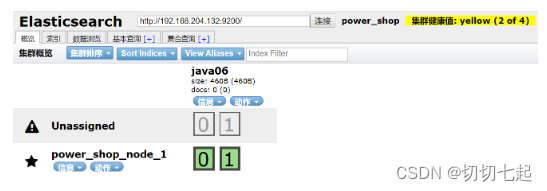
3、创建备份分配,关闭节点2,再测试集群状态















 2649
2649











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









