






Debug和Release的介绍
Debug 通常称为调试版本,它包含调试信息,并且不作任何优化,便于程序员调试程序。
Release 称为发布版本,它往往是进行了各种优化,使得程序在代码大小和运行速度上都是最优
的,以便用户很好地使用。


我们可以通过查看同一个程序分别使用Debug和Release所生成的可执行文件来观看其差别:


Debug和Release反汇编展示对比:
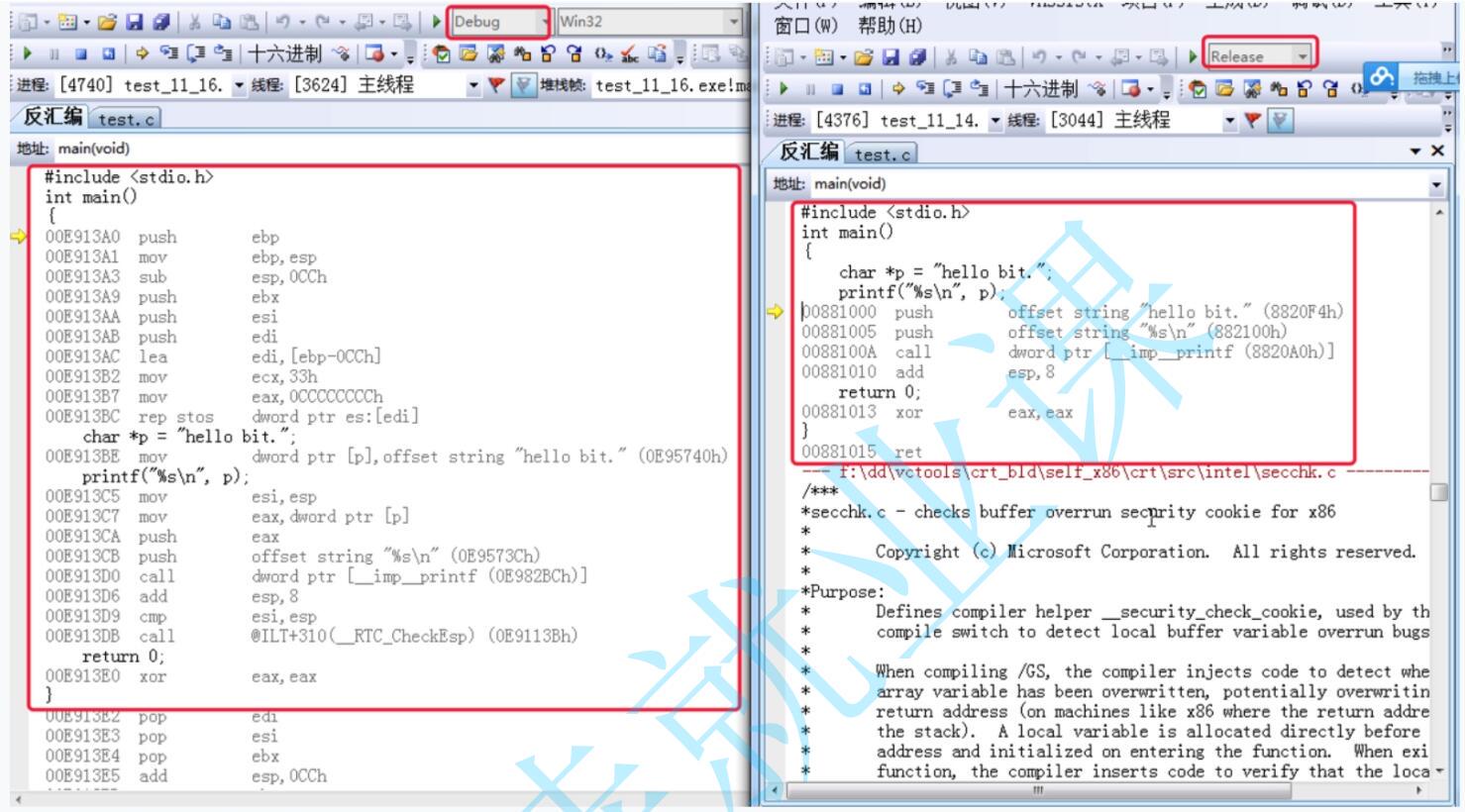
通过上述两个图片,我们可以直观的看出,两个不同版本的可执行文件的大小差异很大,这正是因为Debug版本的文件里面包含了各种调试信息,并且编译器没有对程序进行优化。
所以我们说调试就是在Debug版本的环境当中,寻找代码中潜伏的问题的一个过程。
优化
在介绍Debug和Release时,我们提到了编译器在Release版本的环境中在编译时会对程序进行优化,那么这个优化是怎么回事呢?
我们看到下面一段代码:
再次声明:本文所使用IDE为Visual Studio 2019 版本,程序所展现的情况仅为此IDE环境导致,不引伸其它IDE或者编译器。
#include<stdio.h>
int main()
{
int i = 0;
int arr[10] = { 0 };
for (i = 0; i <= 12; i++)
{
arr[i] = 0;
printf("hehe\n");
}
return 0;
}分别在Debug和Release环境下执行程序,你会发现结果却是大不相同。
在 Debug环境下,程序的执行结果是死循环。
在 Release环境下,程序的执行结果是打印了十二次 hehe,并没有死循环。
而这就是因为优化导致的。
至于是如何对这个程序进行优化的,我会在下文中的调试实例中,进行分析。
常见错误
编译型错误
编译型错误,即在编写源代码时留下的错误,然后在执行编译时因为源代码中存在问题而出现编译错误,例如语法错误,关键字拼写错误,中英文括号等等问题。
这类问题只需要直接 查看错误提示信息,或者凭借经验即可解决。

链接型错误
链接型错误,即调用函数或者别的文件中的函数时,找不到目标。
1.标识符名不存在(拼写错误)。
2.项目工程与第三方库版本不一致,比如工程师64位的,而库是32位的;
3.找不到相应的库文件。
这类问题,主要是 看错误提示信息,在代码中找到错误信息的标识符,然后定位问题所在。

运行时错误
运行时错误,即代码语法没有问题,编译器可以编译通过。但是程序执行的结果不是预期的结果。
例如: 1+1 预期为 2 但是没有输出结果或者输出结果为 1。
这类问题只能通过调试来进行定位问题。
Visual Studio 2019 调试环境介绍
调试环境
在进行调试之前,应该把环境设置为Debug选项,才能使代码正常进行调试。

常用快捷键
快捷键的使用可以提高我们的开发效率,使用快捷键是一个好的习惯。
而从哪里可以找到什么快捷键对应什么功能呢?你可以在VS编译器的工具栏中,依次点开,你就会看到功能描述的后面对应着的就是其快捷键,下面,我们来讲一些经常用的快捷键。当然这只是我目前所经常用到的,如果你还有别的需求可以自行查找。
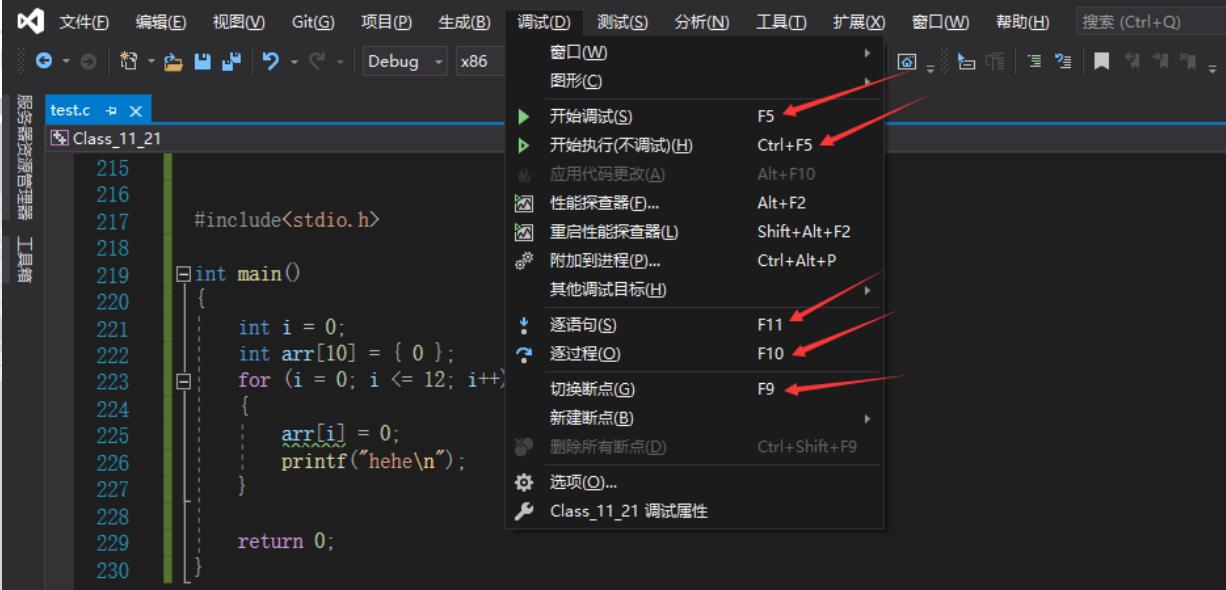
注:笔记本电脑在使用键盘的功能键区,也就是F1 ~ F12时,在开启功能键的情况下,需要按住Fn键然后在按F1 ~ F12,否则所对应的功能就是加减声音等标注在按键上的图案。
记住以下常用的快捷键:
开始调试(F5)
启动调试,经常用来直接跳到下一个断点处,所以通常与切换断点(F9),配合使用。
切换断点(F9)
创建断点和取消断点。
断点的重要作用:可以在程序的任意位置设置断点。这样就可以在调试时使得程序在想要的位置随意的停止执行,继而一步步执行下去。
逐过程(F10)
通常用来处理一个过程。一个过程可以是一次函数调用,也可以只是一条语句。
逐语句(F11)
每次都执行一条语句,但是这个快捷键可以使我们的执行逻辑进入函数的内部(这是最长用的)。
开始执行-不调试(Ctrl+F5)
开始执行,并且不进行调试。如果你想让程序直接运行起来而不进行调试就可以使用此快捷键。
开始调试与断点
这里我们将开始调试快捷键和断点快捷键一起讲解。
1.设置断点(F9)
首先是设置断点,设置断点的方式有3种
方法一:把光标点在需要设置断点的那一行代码上,然后右击鼠标,在出现的一级菜单中选择断点,然后在二级菜单中选择插入断点,之后就会看到行号的前面出现一个红色圆点。
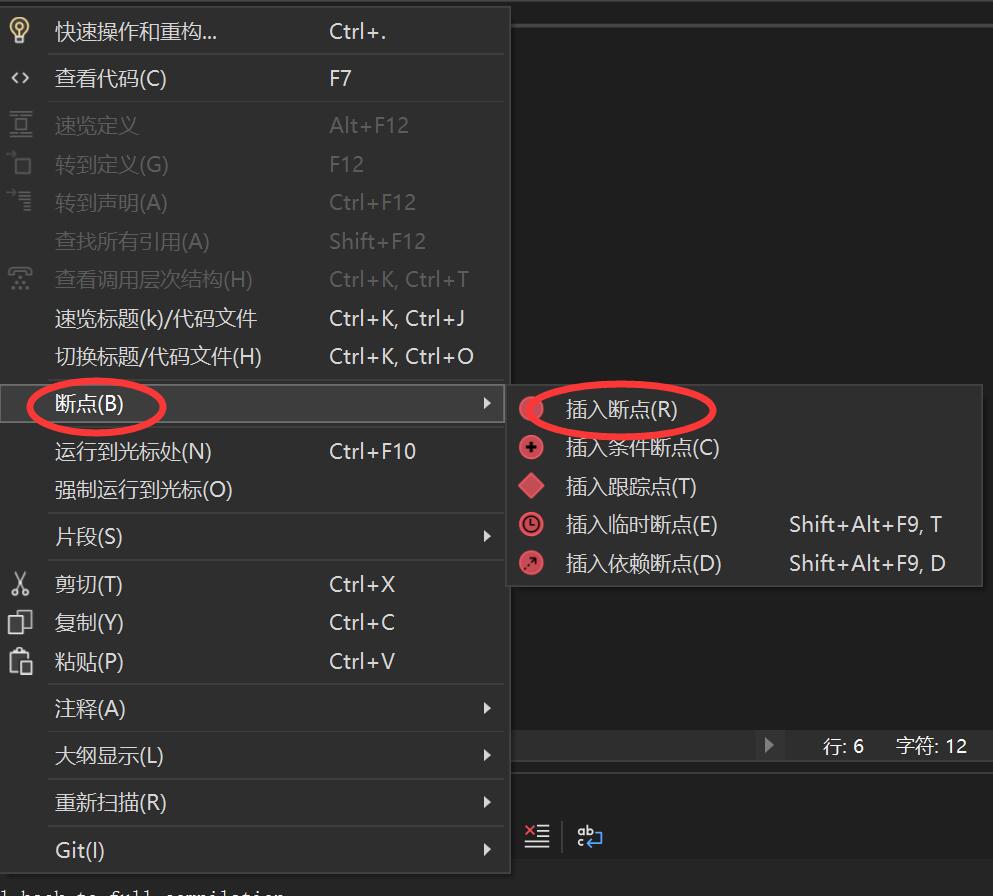
方法二:把光标点在需要设置断点的那一行代码上,然后在键盘上敲击F9键,就可以设置断点(如果是笔记本用户,可能是Fn+F9),如果需要删除断点只需要再敲击一次F9键即可。
方法三:鼠标点击行号前面的空白区域,也可以进行设置断点或者删除断点的操作。
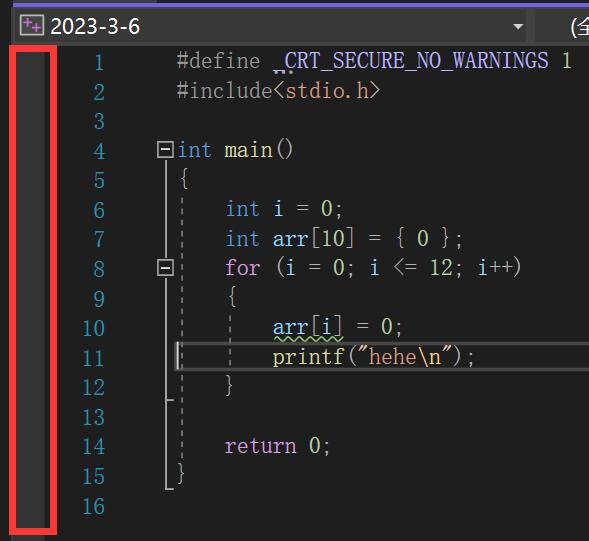

开始调试(F5)
当设置好断点之后,敲击键盘F5键,开始调试。调试开始之后程序会自动执行到断点处,然后暂停程序,进入等待。等候你的下一步操作。
如果设置多个断点,并且断点不在循环内部,那么每敲击一次F5键,程序就执行到下一个断点处。
如果你设置的断点在循环内部,那么你第一次敲击F5,程序会执行到设置的断点处;第二次敲击程序会执行第二次循环,一直到这个循环执行结束。
逐过程与逐语句
逐过程(F10)
调试时,每一次敲击F10键,都只会执行一条语句,也就是一行代码,如果遇到函数,不会进入函数内部,会直接完成函数调用,然后执行下一条语句。
逐语句(F11)
在进行调试时,每一次敲击F11键,也会执行一条语句,但是遇到函数时,会进入到函数内部,然后按F11键,会执行函数内部的第一条语句,直到函数执行完成,再执行函数的下一条语句。
开始执行-不调试
与F5键(开始执行)不同的是,F5+Ctrl键(开始执行-不调试),在执行程序时遇到断点不会暂停,会一直把这一个程序执行完毕。
调试时查看程序当前信息
在调试时,如果只是执行程序,然后逐语句执行程序,这样来进行排查bug,也太low了吧。什么都看不到,这样的调试是很没有意义的,如果能看到程序执行过程中,每一次执行一条语句发生了什么,有没有达到你的预期,这种才是好的调试过程。
在VS IDE中可以在调试过程中查看这几种信息:
其中常用到的:
监视
内存
调用堆栈
反汇编
寄存器
重要的一点是,这些窗口,一定是你在 调试开始之后才能看到,平时是不显示的。
监视
在上图中,我们可以看到监视的下面还有自动窗口和局部变量。
自动窗口和局部变量
这两个在使用时其实不是那么方便,使用时不可以由使用者添加或者删除监视的变量。其会根据程序所执行到的语句或者程序执行到的局部范围内,自动删减监视的变量。
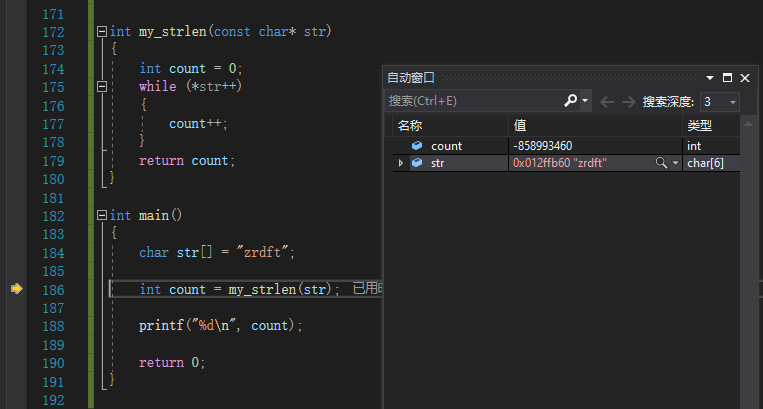
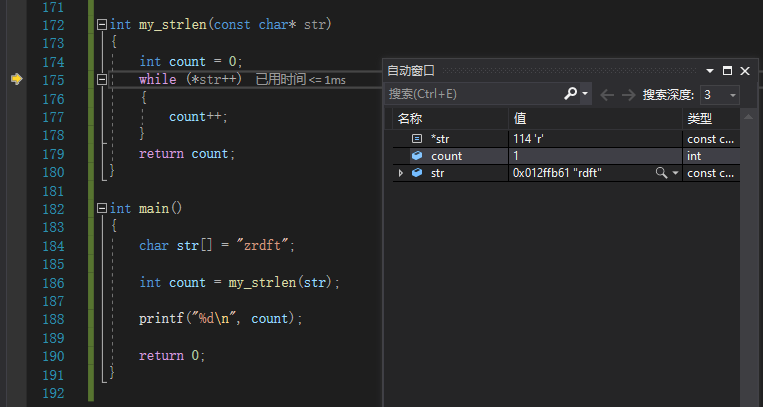
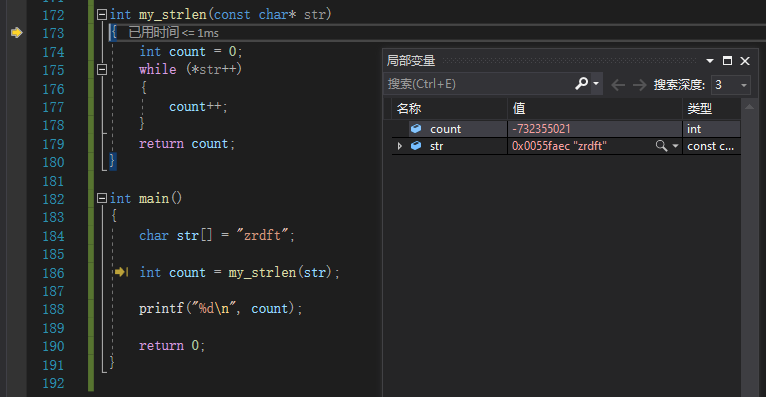
自动窗口
如下图,当程序在主函数内执行时,会自动增加你所执行语句中的变量,但是当你进入函数内部时,主函数中的变量就不再可以观察。只有当你出了函数,回到主函数才会再次出现主函数内部的变量。
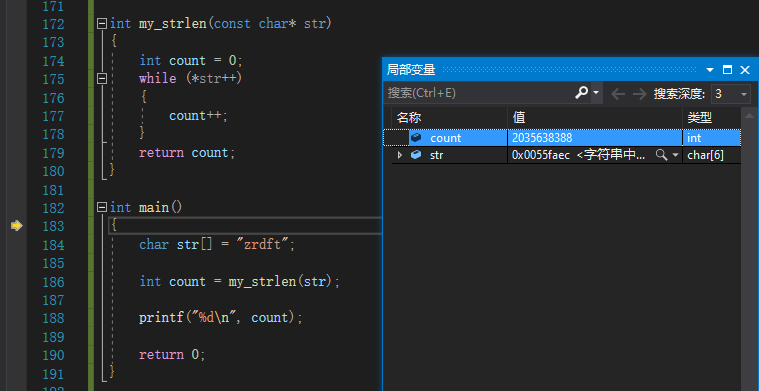
局部变量
与自动窗口不同的是,在使用局部变量时,即使程序并没有执行到局部变量所在的那一条语句,局部变量窗口也会直接显示出这个变量。也就是说局部变量窗口会直接显示程序执行所在的局部内的所有可监视的变量。当然也是不可以由操作者自行添加和删除,并且程序执行到别的函数内,就只显示当前局部的变量。
监视
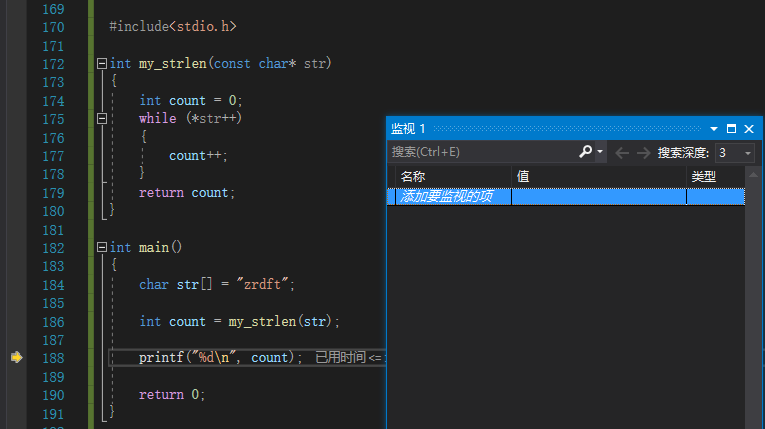
既然说了自动窗口和局部变量的缺点,并且说其不方便,那么监视中肯定不会出现这些不方便的点。
监视,顾名思义监视你想要看到的值,或者值的变化。
在使用监视窗口的过程中,你可以随意的增加和删除你想监视的量,例如变量、地址、数组等等等。当然相对于另外两位,它也有不方便的点,就是不自动还要咱们手动输入。
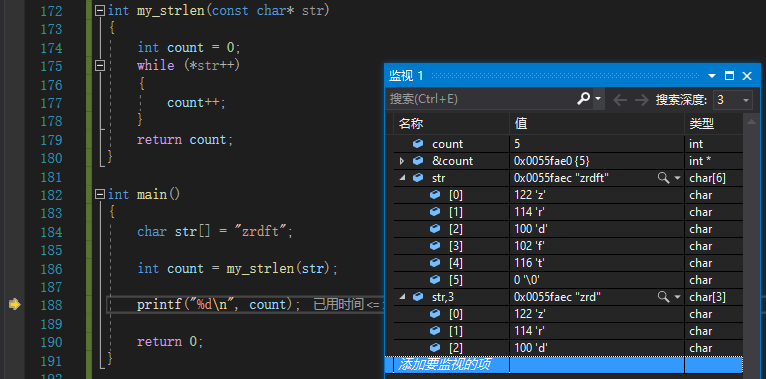
小技巧,当你监视一个数组时,如果只想看到这个数组的前面的某些元素,你可以在监视中添加名称时,在数组名后面加上一个英文的逗号和一个你想要看的元素的范围,例如你想看到三个元素, str,3 ,即可。
内存
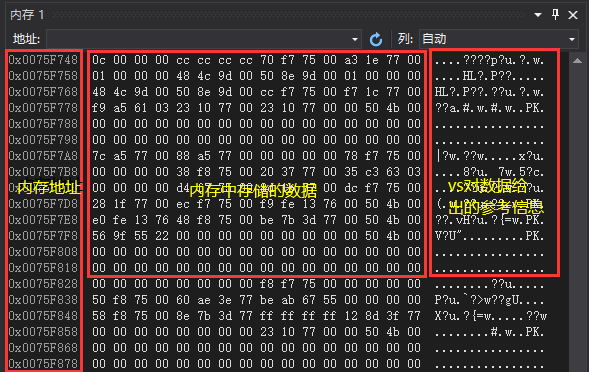
为了方便显示与查看,当你打开内存窗口时你看到的是十六进制的数。

在内存窗口,你可以查看你想要查看的变量的地址,以及这个变量在内存中是怎么存储的。
如果是一个变量只需要在内存窗口中输入&a,如果是数组名直接输入数组名即可。


例如:创建一个整型变量a,查看a的内存地址,以及a的值在内存中是怎么存储的。

a的值为12,转换为16进制是0x0000000c
内存窗口显示的列数,如果你没有更改过,最初为自动显示,如果有要求,可以随意更改为你想要的列数。
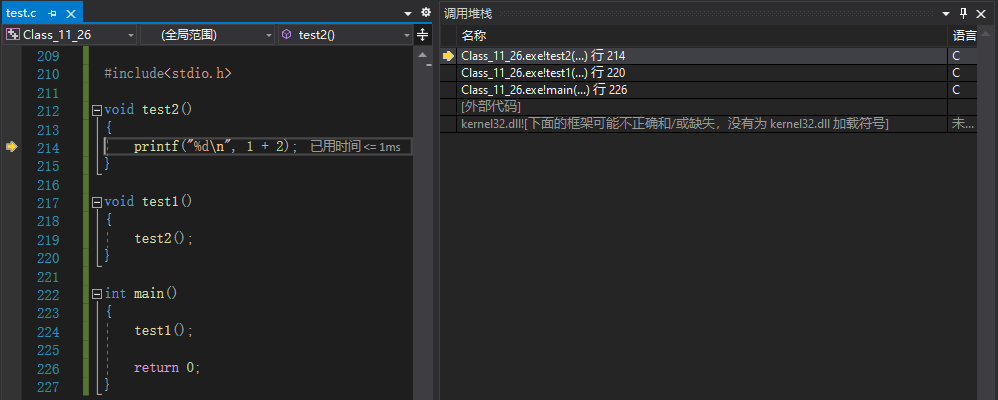
调用堆栈
调用堆栈窗口可以清晰的反应函数的调用关系以及当前调用所处的位置。

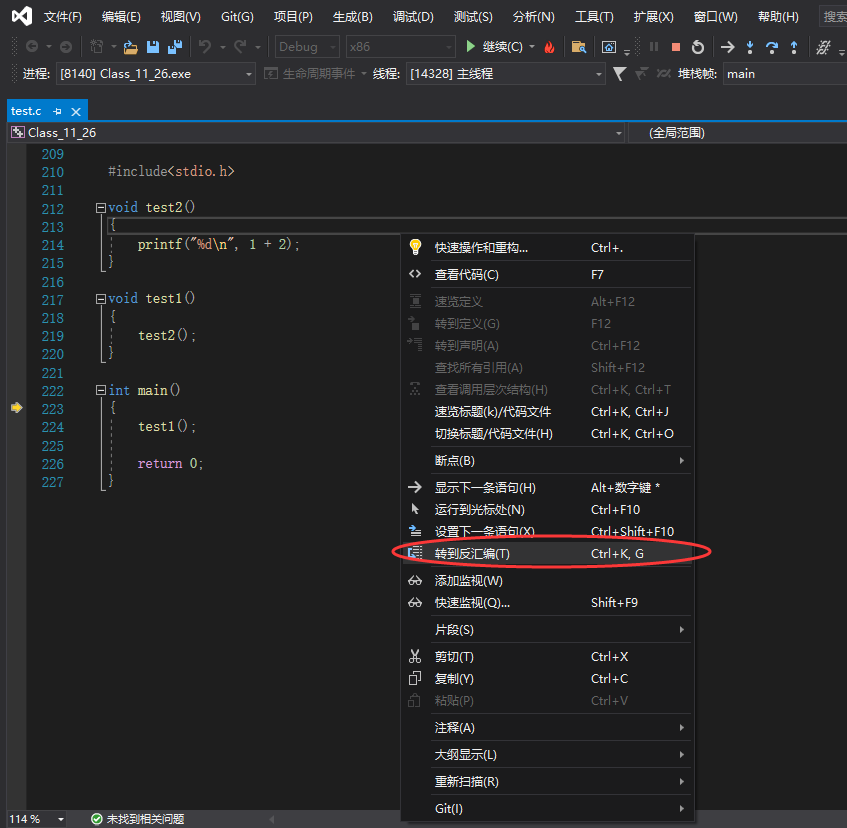
查看汇编信息
在调试开始之后有两种方式打开反汇编窗口,查看反汇编信息
方法一:调试->窗口->反汇编

方法二:右击鼠标->转到反汇编
查看寄存器
打开方式:
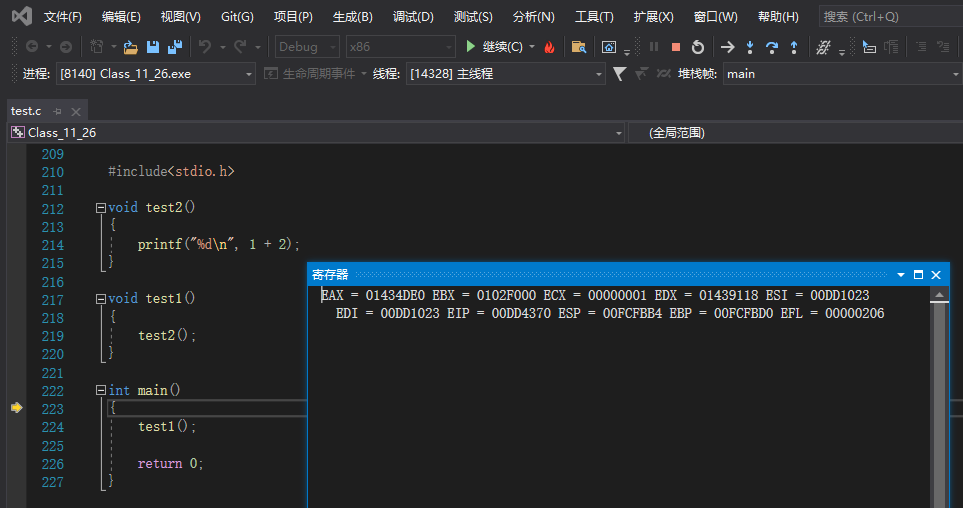
什么是寄存器
寄存器是一块速度非常快的计算机内存,相比于其余存储设备,计算机的速度是最快的,同时也是造价最昂贵的。
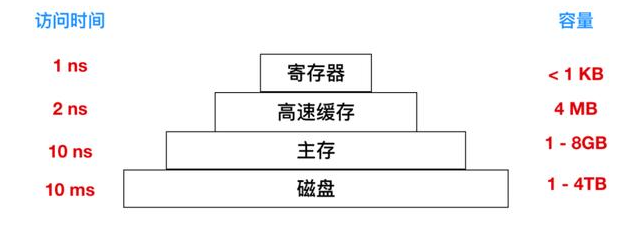
在 8086 架构中,所有的内部寄存器、内部以及外部总线都是 16 位宽,可以存储两个字节,因为是完全的 16 位微处理器。8086 处理器有 14 个寄存器,每个寄存器都有一个特有的名称。
通用寄存器
通用寄存器主要有四种,这四个寄存器一般用来存放数组,也被称为数据寄存器。
AX:累加寄存器,它主要用于输入/输出和大规模的指令运算。
BX:基址寄存器,用来存储基础访问地址
CX:计数寄存器,CX 寄存器在迭代的操作中会循环计数
DX:数据寄存器,它也用于输入/输出操作。它还与 AX 寄存器以及 DX 一起使用,用于涉及大数值的乘法和除法运算。
段寄存器
CPU中包含四个段寄存器,用作程序指令,数据或栈的基础位置。
CS:代码寄存器,程序代码的基础位置
DS:数据寄存器,变量的基本位置
SS:栈寄存器,栈的基础位置
ES:其他寄存器,内存中变量的其他基本位置。
牵引寄存器
牵引寄存器主要包含段地址的偏移量。
BP:基础指针,它是栈寄存器上的偏移量,用来定位栈上变量
SP: 栈指针,它是栈寄存器上的偏移量,用来定位栈顶
SI : 变址寄存器,用来拷贝源字符串
DI : 目标变址寄存器,用来复制到目标字符串
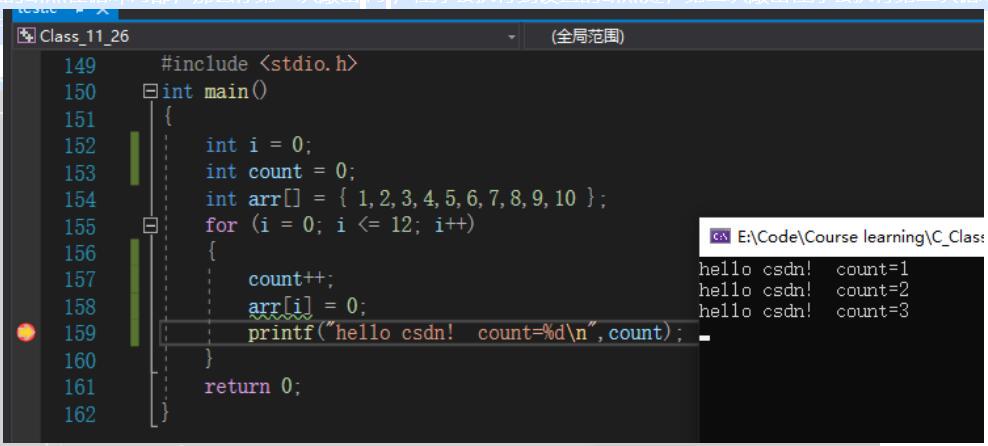
调试实例
下面这段程序,在Debug环境中,会死循环打印“hehe”,而在Release环境中只会打印12次“hehe”。
#include<stdio.h>
int main()
{
int i = 0;
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
for (i = 0; i <= 12; i++)
{
arr[i] = 0;
printf("hehe\n");
}
return 0;
}监视
通过监视i的循环一次加一,以及数组的相应变化进行调试
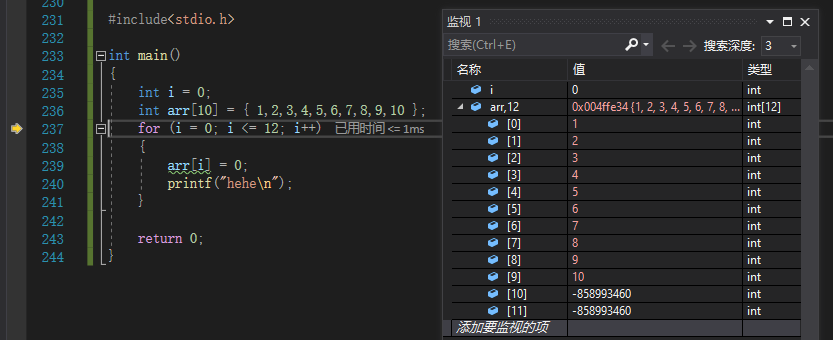
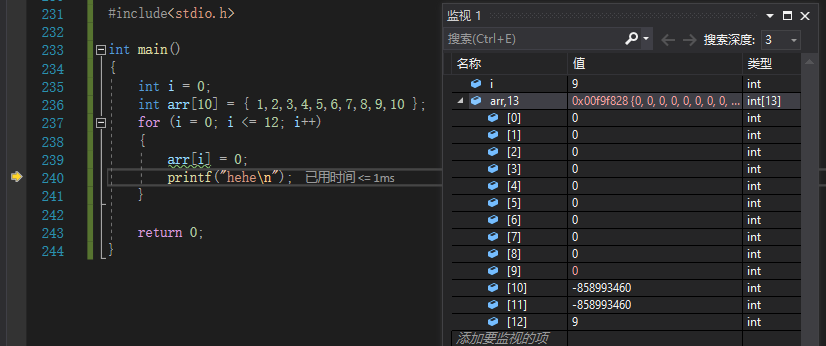
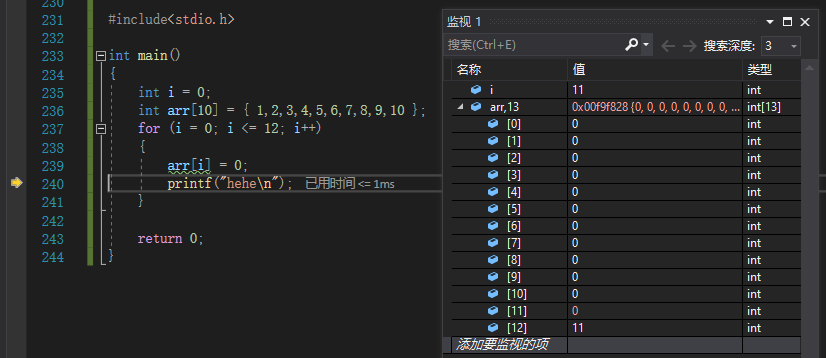
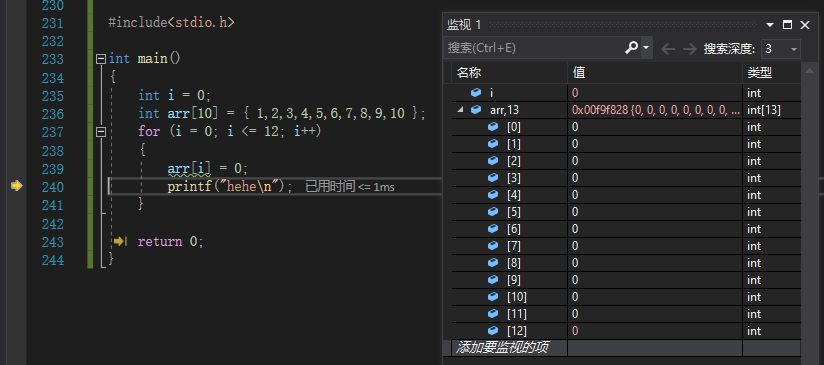
当我们进行了十三次循环之后发现程序中的i和数组越界后的arr[12]同时变成了0此时,我们有理由怀疑它们两个在内存中的地址可能是相同的。
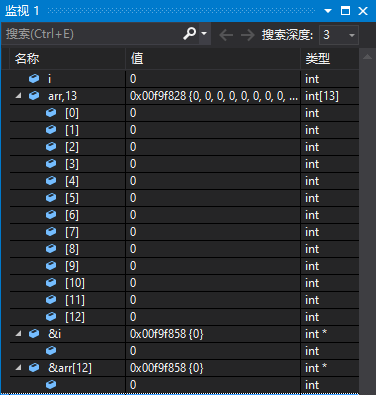
内存
通过监视内存也证实了这一想法
画图解释
Debug 环境
在创建局部变量时,局部变量分配的内存空间在栈区,当创建好一个局部变量之后,再创建其它的局部变量,同时也在内存空间的栈区分配空间,此时就会进行压栈。在栈区创建变量时,先使用内存高地址,再使用内存低地址。
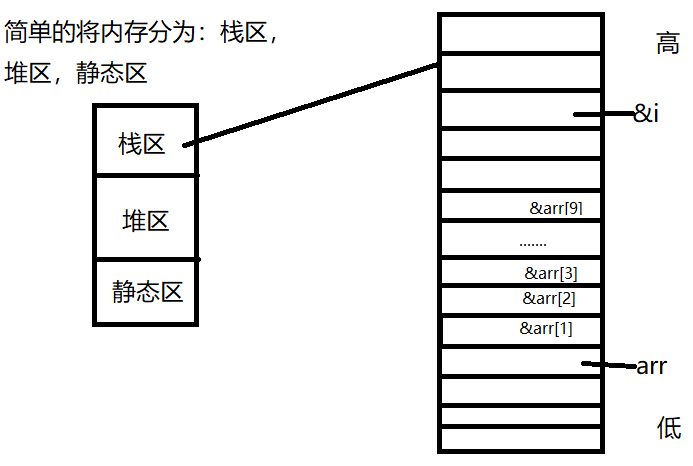
从图中可以看出,当数组越界访问2个4四个字节的内存空间之后,再越界访问第三个,也就是arr[12],正好是i在内存中分配的内存空间,也就是&arr[12] = &i。所以当i = 12时进入循环,执行arr[12] = 0,也就使得了他俩相同的那块内存地址中的值变为了0,使得i = 0,之后循环再进入判断,执行。此时程序死循环。
Release
当一个程序在生成Release版本的可执行文件时,编译器会对程序进行各种优化,使得程序在代码大小和运行速度上都是最优的。
在这个程序中,编译器对程序的优化,我们可以通过简单修改代码,然后在执行程序,就可以发现。
#include<stdio.h>
int main()
{
int i = 0;
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
for (i = 0; i <= 12; i++)
{
arr[i] = 0;
printf("&i = %p\n", &i);
printf("&arr[%d] = %p\n", i,&arr[i]);
}
return 0;
}
截取程序输出结果的一部分:
&i = 0137F860
&arr[12] = 0137F894从输出结果可以看出,此时i在内存空间的地址比数组arr在内存空间中的地址要低,从图像上看:
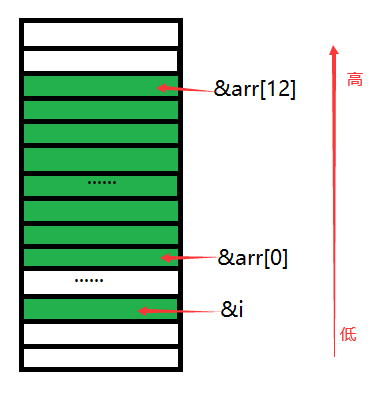
所以Release版本下,不会出现把i的值赋值为0的情况,即不会出现死循环。















 452
452

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









