






一、简介:
KNN(K-近邻,K-Nearest Neighbors)算法是一种基本的分类与回归方法,属于监督学习。其核心思想是:给定一个样本,通过计算其与训练集中所有样本的距离,找到距离最近的K个样本,然后根据这K个样本的类别或值来预测该样本的类别或值。
二、主要步骤:
1. 计算距离:使用欧氏距离、曼哈顿距离等方法计算待预测样本与训练集中每个样本的距离。

2. 选择K个最近邻:根据距离排序,选择距离最近的K个样本。
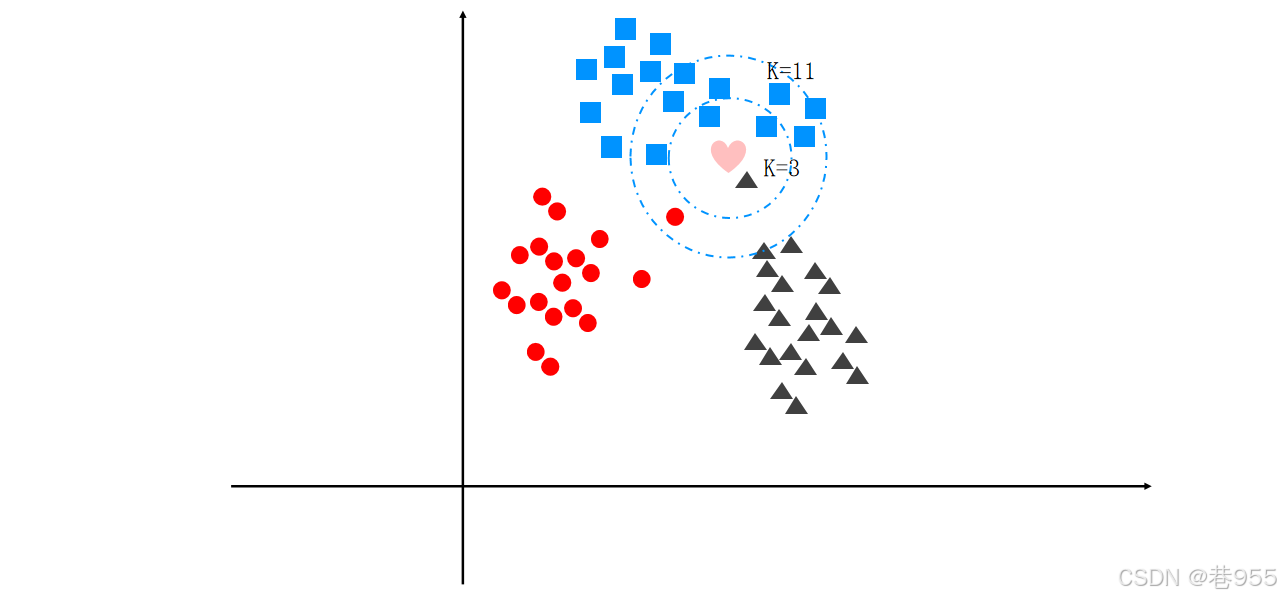
3. 类型应用:
- 分类:通过多数投票确定待预测样本的类别。
- 回归:通过K个最近邻的平均值预测待预测样本的值。
三、简单的实现
1.导入相关的库:
首先,我们要导入两个重要的库,numpy 和 matplotlib
import matplotlib.pyplot as plt
import numpy as np
from sklearn.neighbors import KNeighborsClassifier2.读取数据,并将数据切片
随后,我们获取最后一列的数据,并依据他们的状态分类
data = np.loadtxt('datingTestSet2.txt')
data_1=data[data[: ,-1] == 1]
data_2=data[data[: ,-1] == 2]
data_3=data[data[: ,-1] == 3]3.实现数据可视化
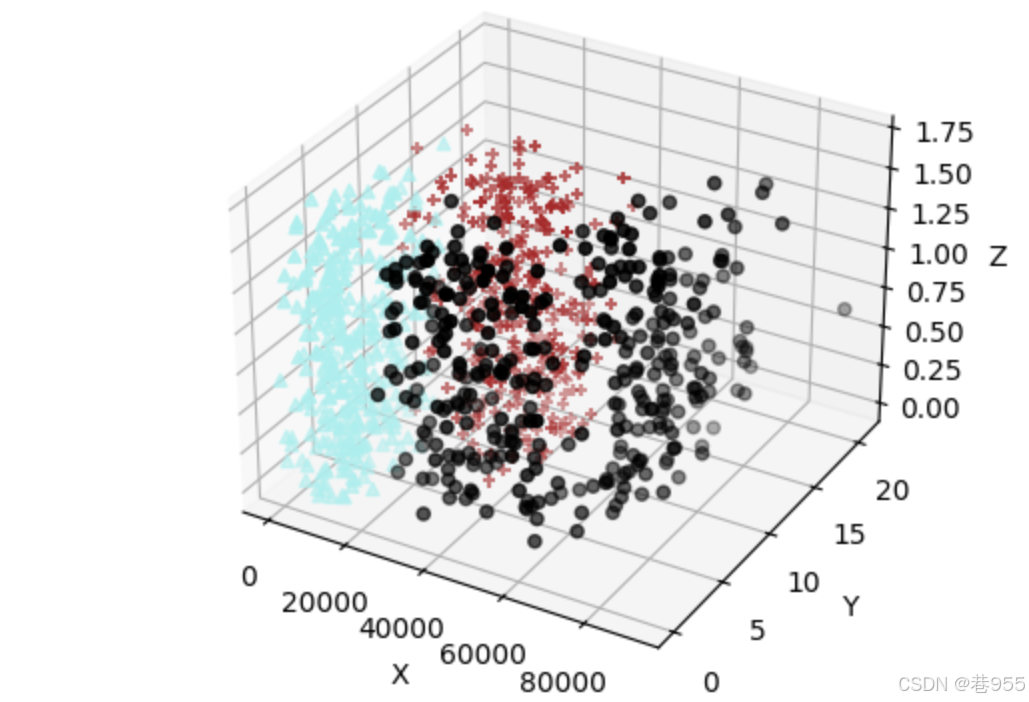
创建画布:
fig = plt.figure()将画布转化为3d类型:
ax=plt.axes(projection='3d')绘制散点图,并显示:
ax.scatter(data_1[:,0],data_1[:,1],zs=data_1[:,2],c='#000000',marker='o')
ax.scatter(data_2[:,0],data_2[:,1],zs=data_2[:,2],c='#AFEEEE',marker='^')
ax.scatter(data_3[:,0],data_3[:,1],zs=data_3[:,2],c='#A52A2A',marker='+')
ax.set(xlabel='X',ylabel='Y',zlabel='Z')
plt.show()结果显示:
4.建立模型
数据测试完毕后,再次选取要求的数据:
X=data[ : , :-1]
y=data[ : , -1]开始建立模型,并训练:
neigh=KNeighborsClassifier(n_neighbors=10) # 创建模型对象
neigh.fit(X,y) # fit训练模型
测试模型:
predict_data = [[9744,11.453225,0.732532],
[131444,0.213144,0.13141],
[231444,11.313434,1.52424]]
print(neigh.predict(predict_data))测试结果显示:

总结:
KNN算法通过计算样本间的距离进行分类或回归,虽然简单,但在实际应用中需注意K值选择和数据标准化等问题。
注:本文仅代表个人观点,若有错误,欢迎指正

















 1703
1703

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









