







目录
1 什么是awk
Pattern scanning and text processing language awk模式扫描文本处理语言,没有一个动听的名字,但它是一种很棒的语言。 awk适合于文本处理和报表生成。 awk是一种一旦学会了就会称为您战略编码库的主要部分的语言。
awk是一种非常强大的数据处理工具,其本身可以称为是一种程序设计语言,因而具有其他程序设计语言所共同拥有的一些特征,例如变量、函数以及表达式等。通过awk,用户可以编写一些非常实用的文本处理工具。本节将介绍awk的基础知识。
2 awk的功能
awk是Linux以及UNIX环境中现有的功能最强大的数据处理工具。简单地讲,awk是一种处理文本数据的编程语言。awk的设计使得它非常适合于处理由行和列组成的文本数据。而在Linux或者UNIX环境中,这种类型的数据是非常普遍的。 除此之外,awk还是一种编程语言环境,它提供了正则表达式的匹配,流程控制,运算符,表达式,变量以及函数等一系列的程序设计语言所具备的特性。它从C语言等中获取了一些优秀的思想。awk程序可以读取文本文件,对数据进行排序,对其中的数值执行计算已经生成报表等。
3 awk的工作流程
aaa bbb ccc print $1
对于初学者来说,搞清楚awk的工作流程非常重要。只有在掌握了awk的工作流程之后,才有可能用好awk来处理数据。在awk处理数据时,它会反复执行以下4个步骤:
(1)自动从指定的数据文件中读取行文本。
(2)自动更新awk的内置系统变量的值,例如列数变量NF、行数变量NR、行变量$0以及各个列变量$1、$2等等。 $1
(3)依次执行程序中所有的匹配模式及其操作。'print $1'
(4)当执行完程序中所有的匹配模式及其操作之后,如果数据文件中仍然还有为读取的数据行,则返回到第(1)步,重复执行(1)~(4)的操作。
4 awk程序执行
awk的基本语法
awk 'BEGIN{ commands } pattern{ commands } END{ commands }' [INPUTFILE…]awk [-F|-f|-v] 'BEGIN{} //{command1; command2} END{}' file[-F|-f|-v] 大参数,-F指定分隔符,-f调用脚本,-v定义变量 var=value
' ' 引用代码块
BEGIN 初始化代码块,在对每一行进行处理之前,初始化代码,主要是引用全局变量,设置FS分隔符
// 匹配代码块,可以是字符串或正则表达式
{} 命令代码块,包含一条或多条命令
; 多条命令使用分号分隔
END 结尾代码块,在对每一行进行处理之后再执行的代码块,主要是进行最终计算或输出结尾摘要信息
awk -F: 'BEGIN{print "======BEGIN======"}{print $1$7}END{print "=====END======"}' /etc/passwd
awk 'BEGIN{a=1;b=2;sum}{sum=a+b}END{print sum}' /etc/passwd注:后面必须跟文件名。并且确保文件存在不为空。
1.通过命令行执行awk程序,语法如下:
awk 'program-text' datafile2.执行awk脚本
在awk程序语句比较多的情况下,用户可以将所有的语句写在一个脚本文件中,然后通过awk命令来解释并执行其中的语句。awk调用脚本的语法如下:
awk -f program-file file ..在上面的语法中,-f选项表示从脚本文件中读取awk程序语句,program-file表示awk脚本文件名称,file表示要处理的数据文件。
3.可执行脚本文件
在上面介绍的两种方式中,用户都需要输入awk命令才能执行程序。除此之外,用户还可以通过类似于Shell脚本的方式来执行awk程序。在这种方式中,需要在awk程序中指定命令解释器,并且赋予脚本文件的可执行权限。其中指定命令解释器的语法如下:
#!/bin/awk -f
以上语句必须位于脚本文件的第一行。然后用户就可以通过以下命令执行awk程序:
awk-script file
其中,awk-script为awk脚本文件名称,file为要处理的文本数据文件。
[root@172 ~] cat a.awk
#!/bin/awk -f
{print $1,$2} -------注:脚本只能写主体,命令代码块
[root@172 ~] awk -F: -f a.awk /etc/passwd
#!/bin/awk -f
BEGIN{a=1;b=2;print a+b}
[root@172 ~] awk -f a.sh
3
[root@172 ~] ./a.sh
3awk输出
1)print的使用格式:
print item1, item2, ...要点:
- 各项目之间使用逗号隔开,而输出时则以空白字符分隔; awk -F : '{print "user:",$1,$3}' /etc/passwd 注意按指定参数输出user: 需要加引号,不加引号会识别为变量。
- 输出的item可以为字符串或数值、当前记录的字段(如$1)、变量或awk的表达式;数值会先转换为字符串,而后再输出; awk -F : '{print "user:",$1,$3, 4+3}' /etc/passwd
- print命令后面的item可以省略,此时其功能相当于print $0, 因此,如果想输出空白行,则需要使用print “”;
示例:
[root@localhost ~]# awk 'BEGIN { print "line one\nline two\nline three"}'
line one
line two
line three
[root@localhost ~]# awk -F: '{print $1" "$3}' /etc/passwd | head -n 3
root 0
bin 1
daemon 2
2)printf命令的使用格式:
printf("format\n", [arguments])1、其与print命令的最大不同是,printf需要指定format;
2、format用于指定后面的每个item的输出格式;
3、printf语句不会自动打印换行符;\n
format格式的指示符都以%开头,后跟一个字符;如下:
%c: 显示字符的ASCII码;
%d, %i:十进制整数;
%e, %E:科学计数法显示数值;
%f: 显示浮点数;
%g, %G: 以科学计数法的格式或浮点数的格式显示数值;
%s: 显示字符串;
%u: 无符号整数;
%%: 显示%自身;
修饰符:
N: 显示宽度;
-: 左对齐;
+:显示数值符号;
示例:
[root@localhost ~] awk -F: '{printf "%-15s %i\n",$1,$3}' /etc/passwd |head -n 3
root 0
bin 1
daemon 23)输出重定向
print items > output-file
print items >> output-file
print items | command ****
特殊文件描述符:
/dev/stdin:标准输入
/dev/sdtout: 标准输出
/dev/stderr: 错误输出
/dev/fd/N: 某特定文件描述符,如/dev/stdin就相当于/dev/fd/0;
示例:
[root@localhost ~] awk -F: '{printf "%-15s %i\n",$1,$3 > "test1" }' /etc/passwd
[root@localhost ~] awk -F ':' '{print $1 | "sort"}' passwdawk变量
1) awk内置变量之记录变量
- FS: field separator,读取文件本时,所使用字段分隔符;
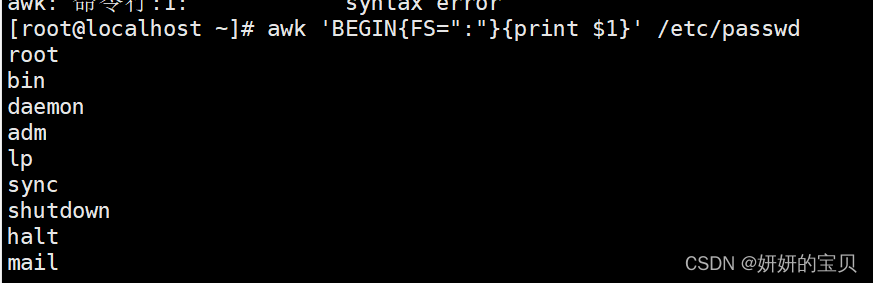
- RS:指定输入换行符\n
[root@localhost test]vim aaa
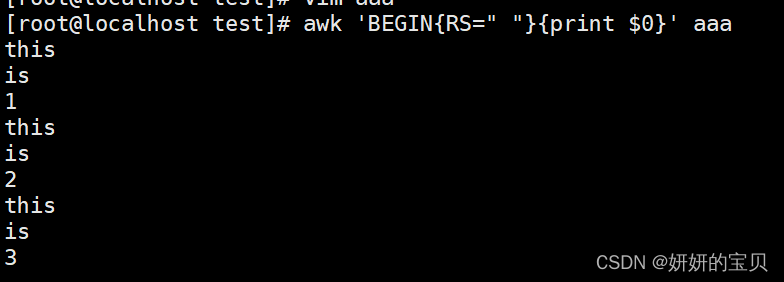
- awk -F: F指定输入分割符
- OFS=”#” 指定输出分割符

- ORS="||||" 指定输出换行符---没有换行功能,换行功能依旧只能是\n
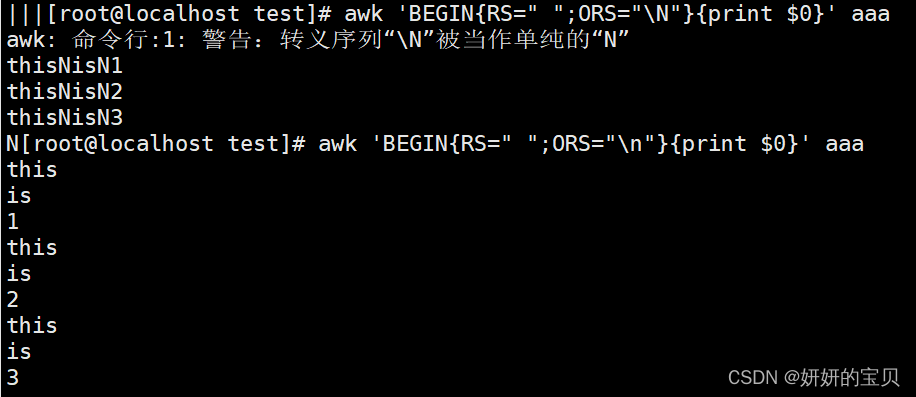
示例:
[root@localhost ~]echo "this is" > test.txt
[root@localhost ~]awk 'BEGIN {OFS="#"} {print $1,$2,"a","test"}' test.txt
this#is#a#test
2) awk内置变量之数据变量
- NR: The number of input records,awk命令所处理的记录数; 如果有多个文件,这个数目会把处理的多个文件中行统一计数;
(每执行一次都会显示一次记录作为技术---写在{}里面每次循环都会执行一遍就相当于显示行号)

- NF:Number of Field,当前记录的field个数; 当前行的字段总数(每行有几列做一个记录)

- FNR: 与NR不同的是,FNR用于记录正处理的行是当前这一文件中被总共处理的行数; awk可能处理多个文件,各自文件计数
- ENVIRON:当前shell环境变量及其值的关联数组;

- $NR=$1
- $NF
示例:
[root@localhost ~]$ awk 'BEGIN{print ENVIRON["PATH"]}'
/usr/kerberos/sbin:/usr/kerberos/bin:/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin:/root/bin
3) 用户自定义变量
gawk允许用户自定义自己的变量以便在程序代码中使用,变量名命名规则与大多数编程语言相同,只能使用字母、数字和下划线,且不能以数字开头。gawk变量名称区分字符大小写。
A、 在gawk中给变量赋值使用赋值语句进行
示例:
[root@localhost ~] awk 'BEGIN{test="hello";print test}'
hello
[root@172 test] awk 'BEGIN{test="hello";t="world";print test,t}'B、 在命令行中使用赋值变量
gawk命令也可以在“脚本”外为变量赋值,并在脚本中进行引用。例如,上述的例子还可以改写为:
[root@localhost ~]awk -v test="hello" 'BEGIN {print test}'
hello变量总结(常用)
| 变量 | 说明 |
|---|---|
| $0 | 记录变量,表示当前正在处理的记录 |
| $n | 字段变量,其中n为整数,且n大于1。表示第n个字段的值 |
| NF | 整数值,表示当前记录(变量$0所代表的记录)的字段数 |
| NR | 整数值,表示awk已经读入的记录数;如果有多个文件,这个数目会把处理的多个文件中行统一计数。(显示的是文件的每一行的行号) |
| FNR | 与NR不同的是,FNR用于记录正处理的行是当前这一文件中被总共处理的行数; |
| FILENAME | 表示正在处理的数据文件的名称 |
| FS | 输入字段分隔符,默认值是空格或者制表符,可使用-F指定分隔符 |
| OFS | 输出字段分隔符 ,OFS=”#”指定输出分割符为#。 |
| RS | 记录分隔符,默认值是换行符 \n |
| ENVIRON | 当前shell环境变量及其值的关联数组; |
awk操作符
1) 算术操作符
-x:负值
+x:转换为数值
x^y:次方
x**y:次方
x*y:
x/y:
x+y:
x-y:
x%y:
示例:
[root@localhost ~] awk 'BEGIN{print 123abc}'
123
[root@localhost ~] awk 'BEGIN{print +abc123}' 输入不加双引号识别为数字由于第一个字符不是数子所以显示空
0
[root@localhost ~] awk 'BEGIN{print "123abc"}'
123abc
[root@localhost ~] awk 'BEGIN{print +"123abc"}'
123 ----将字符串转换为数值,但前提是字符串第一位必须是数字否则转换为0值
[root@localhost ~] awk 'BEGIN{print +"abc123"}'
0
[root@localhost ~] awk 'BEGIN{x=2;y=3;print x**y,x^y,x*y,x/y,x+y,x-y,x%y}'
8 8 6 0.666667 5 -1 2
[root@localhost ~] awk 'BEGIN{x=2;y=3;print x**y,x^y,x*y,x/y,x+y,x-y,x%y}'
8 8 6 0.666667 5 -1 22) 字符串操作符
只有一个,而且不用写出来,用于实现字符串拼接;
示例:
[root@localhost ~] awk 'BEGIN{print "This","is","test"}'
This is test3) 赋值操作符
| 运算符 | 说明 | 举例 |
|---|---|---|
| = | 赋值运算 | x=5表示将数值5赋给变量x |
| += | 复合赋值运算,表示将前后两个数值相加后的和赋给前面的变量 | x+=5表示先将x的值与5相加,然后再将和赋给变量x,等价于x=x+5 |
| -= | 复合赋值运算,表示将前后两个数值相减后的值赋给前面的变量 | x-=5表示先将x的值减去5,然后再将得到的差赋给变量x,等价于x=x-5 |
| *= | 复合赋值运算,表示前后两个数的乘积赋给前面的变量 | 表示先将x的值乘以5,然后再将得到的乘积赋给变量x |
| /= | 复合赋值运算,表示前后两个数值的商赋给前面的变量 | 表示先将变量x除以5,再将商赋给变量x |
| %= | 复合赋值运算,表示将前面的数值除以后面的数值所得的余数赋给前面的变量 | 将变量x与5相除后的余数赋给变量x |
| ^= | 复合运算符,表示将前面的数值的后面数值次方赋给前面的变量 | x^=3表示将变量x的3次方赋给变量x |
需要注意的是,如果某模式为=号,此时使用/=/可能会有语法错误,应以/[=]/替代;
示例:
[root@localhost ~] awk 'BEGIN{x=2;y=x;printf "%-5s %i\n%-5s %i\n","++x=",++x,"--y=",--y}'
++x= 3
--y= 14) 布尔值
awk中,任何非0值或非空字符串都为真,反之就为假;
[root@localhost ~] awk 'BEGIN {if(0){ print "haha"}else print "xixi"}'
xixi
[root@localhost ~] awk 'BEGIN {if(0) print "haha";else print "xixi"}'
xixi5) 比较操作符
x < y True if x is less than y.
x <= y True if x is less than or equal to y.
x > y True if x is greater than y.
x >= y True if x is greater than or equal to y.
x == y True if x is equal to y.
x != y True if x is not equal to y.
x ~ y 如果字符串 x 匹配 y 表示的 regexp,则为 true
x !~ y True if the string x does not match the regexp denoted by y.
subscript in array True if the array array has an element with the subscript subscript.
| 运算符 | 说明 | 举例 |
|---|---|---|
| > | 大于 | 5>2的值为真 |
| >= | 大于或者等于 | 8>=8的值为真 |
| < | 小于 | 8<12的值为真 |
| <= | 小于或者等于 | 4<=7的值为真 |
| == | 等于 | 9==9的值为真 |
| != | 不等于 | 1!=3的值为真 |
| ~ | 匹配运算符 | $1 ~ /^T/表示匹配第一个字段以字符T开头的记录 |
| !~ | 不匹配运算符 | $1 !~ /a/表示匹配第一个字段不含有字符a的记录 |
6) 逻辑关系符
| 运算符 | 说明 | 举例 |
|---|---|---|
| && | 逻辑与,当前后两个表达式的值全部为真时,其运算结果才为真 | 1>2&&3>2的值为假 |
| || | 逻辑或,前后两个表达式只要有一个为真,则其运算结果为真。当两个表达式的值都为假时,其运算结果才为假 | 1>2&&3>2的值为真 |
| ! | 逻辑非,当表达式的值为真时,其运算结果为假;当表达式的值为假时,其运算结果为真 | !(1>2)的值为真 |
7) 条件表达式
selector?if-true-exp:if-false-exp
if selector; then
if-true-exp
else
if-false-exp
Fia=3
b=4
a>b?a is max:b is max (双目运算符)
cat num
5 8
7 2
1 9
6 4
7 2使用条件测试表达式打印出每行的最大值:(双目运算符)
awk '{max=$1>$2?$1:$2;print NR,"max =",max}' num
1 max = 8
2 max = 7
3 max = 9
4 max = 6
5 max = 7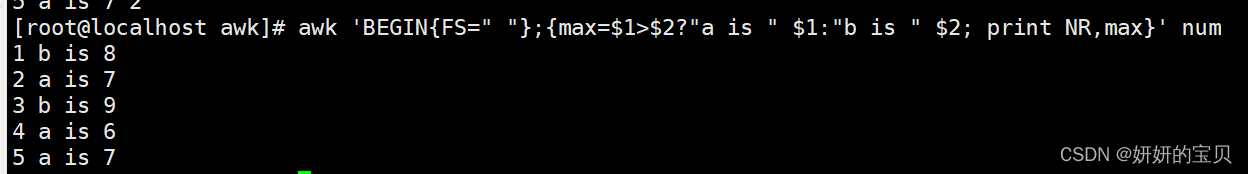
awk模式
awk -F: 'BEGIN{} //{} END{}' filename
awk 'program' input-file1 input-file2 …
其中的program为:
pattern { action }
pattern { action }
…
1) 常见的模式类型
1、Regexp: 正则表达式,格式为/regular expression/ /^root/
2、expresssion: 表达式,其值非0或为非空字符时满足条件,如:$1 ~ /foo/ 或 $1 == "uplook",用运算符~(匹配)和!~(不匹配)。
3、Ranges: 指定的匹配范围,格式为pat1,pat2
4、BEGIN/END:特殊模式,仅在awk命令执行前运行一次或结束前运行一次
5、Empty(空模式):匹配任意输入行
2) 常见的action
1、Expressions:
2、Control statements
3、Compound statements
4、Input statements
5、Output statements
/正则表达式/:使用通配符的扩展集。
+ : 匹配其前的单个字符一次以上,是awk自有的元字符,不适用于grep或sed等
? : 匹配其前的单个字符1次或0次,是awk自有的元字符,不适用于grep或sed等
关系表达式:可以用下面运算符表中的关系运算符进行操作,可以是字符串或数字的比较,如$2>$1选择第二个字段比第一个字段长的行。
模式匹配表达式:
模式,模式:指定一个行的范围。该语法不能包括BEGIN和END模式。
BEGIN:让用户指定在第一条输入记录被处理之前所发生的动作,通常可在这里设置全局变量。
END:让用户在最后一条输入记录被读取之后发生的动作。
#使用正则
[root@localhost ~] awk -F: '/^r/ {print $1}' /etc/passwd
root
rpc
rpcuser//匹配代码块
//纯字符匹配 !//纯字符不匹配 ~//字段值匹配 !~//字段值不匹配 ~/a1|a2/字段值匹配a1或a2
awk '/mysql/' /etc/passwd
awk '/mysql/{print }' /etc/passwd
awk '/mysql/{print $0}' /etc/passwd //三条指令结果一样
awk '!/mysql/{print $0}' /etc/passwd //输出不匹配mysql的行
awk -F : '/mysql|redhat/{print}' /etc/passwd
redhat:x:1000:1000:redhat:/home/redhat:/bin/bash
mysql:x:27:27:MySQL Server:/var/lib/mysql:/bin/falseawk '!/mysql|redhat/{print}' /etc/passwd // !取反,除去mysql或者redhat的行输出
awk -F : '/chrony/,/mysql/{print $0}' /etc/passwd //区间匹配
awk -F : '/chrony/,/mysql/{print $0}' /etc/passwd //区间匹配
chrony:x:986:981::/var/lib/chrony:/sbin/nologin
dnsmasq:x:985:980:Dnsmasq DHCP and DNS server:/var/lib/dnsmasq:/sbin/nologin
tcpdump:x:72:72::/:/sbin/nologin
systemd-oom:x:978:978:systemd Userspace OOM Killer:/:/usr/sbin/nologin
redhat:x:1000:1000:redhat:/home/redhat:/bin/bash
mysql:x:27:27:MySQL Server:/var/lib/mysql:/bin/false
awk '/[2][7][7]*/{print $0}' /etc/passwd //匹配包含27为数字开头的行,如27,277,2777...
awk -F: '$1~/mail/{print $1}' /etc/passwd //$1匹配指定内容才显示,并且使用:分割,输出第一个字段
$1 ~ /mail/表示匹配第一个字段以字符开头的记录
awk -F : '/mysql/{print}' /etc/passwd
mysql:x:27:27:MySQL Server:/var/lib/mysql:/bin/false
awk -F : '$1~/mysql/{print $1}' /etc/passwd
mysql
awk -F : '$3~/27/{print $1}' /etc/passwd
mysql
awk -F: '{if($1~/mail/) print $1}' /etc/passwd //与上面相同
awk 'BEGIN{FS=":"}{if($1~/mysql/) print $1}' /etc/passwd
mysql
awk -F: '$1!~/mail/{print $1}' /etc/passwd //不匹配
awk -F: '$1!~/mail|mysql/{print $1}' /etc/passwd
#使用BEGIN
[root@localhost ~] awk -F: 'BEGIN {printf "%-15s %-3s %-15s\n","user","uid","shell"} $3==0,$7~"nologin" {printf "%-15s %-3s %-15s\n",$1,$3,$7}' /etc/passwd
user uid shell
root 0 /bin/bash
bin 1 /sbin/nologin #使用END
[root@localhost ~] awk -F: 'BEGIN {printf "%-15s %-3s %-15s\n","user","uid","shell"} $3==0,$7~"nologin" {printf "%-15s %-3s %-15s\n",$1,$3,$7} END {print "-----End file-----"}' /etc/passwd
user uid shell
root 0 /bin/bash
bin 1 /sbin/nologin
-----End file-----awk控制语句
1)if-else
语法:awk 'BEGIN{if(){}}'
awk 'BEGIN{if(){}else{}}'
if(表达式) {语句1} else if(表达式) {语句2} else {语句3}
awk 'BEGIN{for(i=0;i<=1;i++){ }}'
awk 'BEGIN{while($3==0){}}'
示例:
[root@localhost ~] awk -F: '{if ($1=="root") printf "%-10s %-15s\n", $1, "Admin"; else {printf "%-10s %-15s\n",$1, "Common User"}}' /etc/passwd | head -n 3
root Admin
bin Common User
daemon Common User [root@localhost ~] awk 'BEGIN{FS=":"}{if($1=="root"){printf "%-15s %-15s\n",$1,"管理员用户"}else if($3>=1&&$3<=999){printf "%-15s %-15s\n",$1,"系统用户"}else if($3>=1000){printf "%-15s %-15s\n",$1,"普通用户"}}' /etc/passwd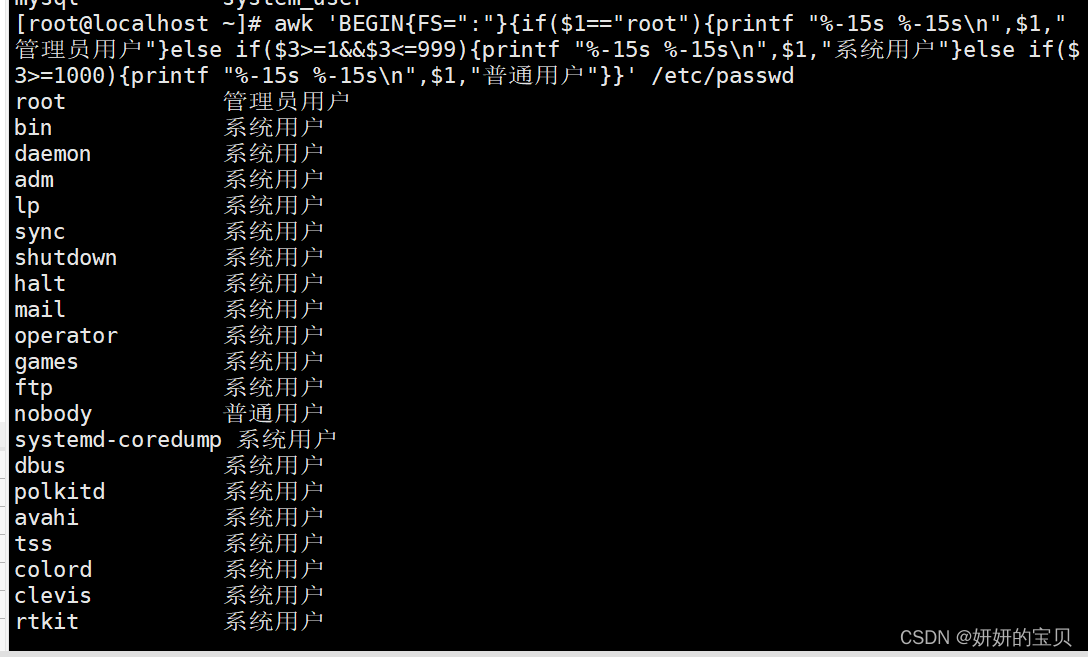
将上面的两个数比较,打印最大数的用if语句改写:
awk '{if ($1>$2) print NR,"max =",$1;else print NR,"max =",$2}' num
1 max = 8
2 max = 7
3 max = 9
4 max = 6
5 max = 7
awk 'BEGIN{a=3;b=4;c=a>b?a:b;print c}'
2)while
语法: while(表达式) {语句}
示例:
[root@localhost ~] awk -F: '{i=1;while (i<=3) {print $i;i++}}' /etc/passwd
[root@localhost ~] awk -F: '{i=1;while (i<=NF) { if (length($i)>=4) {print $i}; i++ }}' /etc/passwd
计算1+2+3+...+100累加和
awk 'BEGIN{while(i<=100){sum+=i;i++;}print "sum =",sum}'
sum = 50503)do-while
语法: do{语句}while(条件)
示例:
[root@localhost ~] awk -F: '{i=1;do {print $i;i++}while(i<=3)}' /etc/passwd | head -n 3
root
x
0计算1+2+3+...+100累加和
awk 'BEGIN{do{sum+=i;i++;}while(i<=100)print "sum =",sum}'
sum = 5050
4)for
格式1:
语法:for(变量;条件;表达式){语句}
示例:
[root@localhost ~] awk -F: '{for(i=1;i<=3;i++) print i}' /etc/passwd
[root@localhost ~] awk -F: '{for(i=1;i<=NF;i++) { if (length($i)>=4) {print $i}}}' /etc/passwd计算1+2+3+...+100累加和
awk 'BEGIN{for(i=1;i<=100;i++){sum+=i;}print "sum =",sum}'
sum = 5050
for循环还可以用来遍历数组元素:
格式2:
语法: for(变量 in 数组){语句}
示例:
#查看用户的shell BASH[0]BASH[1]
[root@ ~]awk -F: '$NF!~/^$/{BASH[$NF]++}END{for(A in BASH){printf "%15s:%i\n",A,BASH[A]}}' /etc/passwd
/sbin/shutdown:1
/bin/bash:1
/sbin/nologin:29
/sbin/halt:1
/bin/sync:1
5)case
语法:switch (expression) { case VALUE or /REGEXP/: statement1, statement2,... default: statement1, ...}
6)break 和 continue
常用于循环或case语句中
7)next
提前结束对本行文本的处理,并接着处理下一行;例如,下面的命令将显示其ID号为奇数的用户:
awk -F: '{if($3%2==0) next;print $1,$3}' /etc/passwd | head -n 3
bin 1
adm 3
sync 5
















 482
482

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











