







一、粒子群算法的概念particle swarm optinmization
粒子群算法的思想源于对鸟/鱼群捕食行为的研究,模拟鸟集群飞行觅食的行为,鸟之间通过集体的协作使群体达到最优目的,简单的说,就是一群鸟在随机搜索食物。已知在这块区域里只有一块食物;所有的鸟都不知道食物在哪里;但它们能感受到当前的位置离食物还有多远。那么找到食物的最优策略是什么呢?
-
1.搜寻目前离食物最近的鸟的周围区域
-
2.根据自己飞行的经验判断食物的所在
-
粒子群算法通过设计一种无质量的粒子来模拟鸟群中的鸟,粒子仅具有两个属性:速度和位置,速度代表移动的快慢,位置代表移动的方向。每个粒子在搜索空间中单独的搜寻最优解,并将其记为当前个体极值,并将个体极值与整个粒子群里的其他粒子共享,找到最优的那个个体极值作为整个粒子群的当前全局最优解,粒子群中的所有粒子根据自己找到的当前个体极值和整个粒子群共享的当前全局最优解来调整自己的速度和位置。
PSO的优势:参数少、原理简单好实现
PSO的缺点:容易陷入局部最优,前期w,c1应该大,后期c2大,但由于参数固定,导致收敛速度慢。
二、算法介绍
粒子速度更新公式包含三部分: 第一部分为“惯性部分”,即对粒子先前速度的记忆;第二部分为“自我认知”部分,可理解为粒子i当前位置与自己最好位置之间的距离;第三部分为“社会经验”部分,表示粒子间的信息共享与合作,可理解为粒子i当前位置与群体最好位置之间的距离。


其中w:0.5-0.8,c1,c2:0.1-2,Vmax,Xmax往往取决于优化函数
三、算法流程
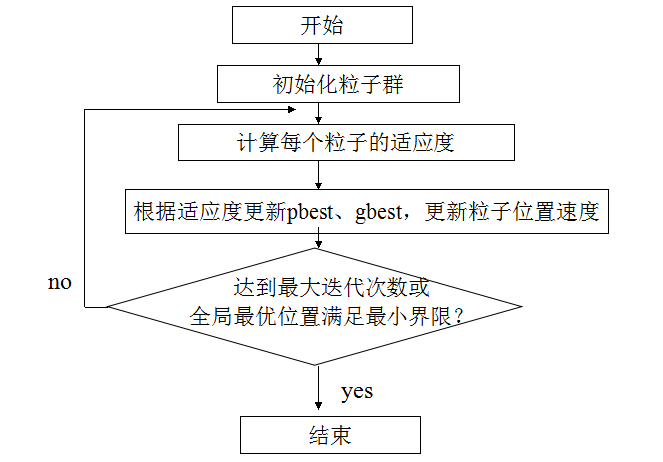
其中适应度的解释为:我们优化目标往往是最小化一个函数值,所以个体计算出的函数值越小,适应度越高,如果我们是优化目标是最大化一个函数值,则max f=min -f
step1 在初始化范围内,对粒子群进行随机初始化,包括随机位置和速度
step2 计算每个粒子的适应度
step3 粒子个体的历史最优位置
step4 更新粒子群体的历史最优位置
step5 更新粒子的速度和位置
step6 若未达到终止条件,则转第2步,终止条件为迭代次数或者适应度不再变化
四、代码实现
以Ras函数(Rastrigin's Function)为目标函数,求其在x1,x2∈[-5,5]上的最小值。这个函数对模拟退火、进化计算等算法具有很强的欺骗性,因为它有非常多的局部最小值点和局部最大值点,很容易使算法陷入局部最优,而不能得到全局最优解。如下图所示,该函数只在(0,0)处存在全局最小值0。
# -*- coding: utf-8 -*-
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
import numpy as np
import matplotlib.pyplot as plt
# 目标函数定义
def ras(x):
y = 20 + x[0]**2 + x[1]**2 - 10*(np.cos(2*np.pi*x[0])+np.cos(2*np.pi*x[1]))
return y
# 参数初始化
w = 1.0
c1 = 1.49445
c2 = 1.49445
maxgen = 200 # 进化次数
sizepop = 20 # 种群规模
# 粒子速度和位置的范围
Vmax = 1
Vmin = -1
popmax = 5
popmin = -5
# 产生初始粒子和速度
pop = 5 * np.random.uniform(-1,1,(2,sizepop))
v = np.random.uniform(-1,1,(2,sizepop))
fitness = ras(pop) # 计算适应度
i = np.argmin(fitness) # 找最好的个体
gbest = pop # 记录个体最优位置
zbest = pop[:,i] # 记录群体最优位置
fitnessgbest = fitness # 个体最佳适应度值
fitnesszbest = fitness[i] # 全局最佳适应度值
# 迭代寻优
t = 0
record = np.zeros(maxgen)
while t < maxgen:
# 速度更新
v = w * v + c1 * np.random.random() * (gbest - pop) + c2 * np.random.random() * (zbest.reshape(2,1) - pop)
v[v > Vmax] = Vmax # 限制速度
v[v < Vmin] = Vmin
# 位置更新
pop = pop + 0.5 * v;
pop[pop > popmax] = popmax # 限制位置
pop[pop < popmin] = popmin
'''
# 自适应变异
p = np.random.random() # 随机生成一个0~1内的数
if p > 0.8: # 如果这个数落在变异概率区间内,则进行变异处理
k = np.random.randint(0,2) # 在[0,2)之间随机选一个整数
pop[:,k] = np.random.random() # 在选定的位置进行变异
'''
# 计算适应度值
fitness = ras(pop)
# 个体最优位置更新
index = fitness < fitnessgbest
fitnessgbest[index] = fitness[index]
gbest[:,index] = pop[:,index]
# 群体最优更新
j = np.argmin(fitness)
if fitness[j] < fitnesszbest:
zbest = pop[:,j]
fitnesszbest = fitness[j]
record[t] = fitnesszbest # 记录群体最优位置的变化
t = t + 1
# 结果分析
print(zbest)
plt.plot(record,'b-')
plt.xlabel('generation')
plt.ylabel('fitness')
plt.title('fitness curve')
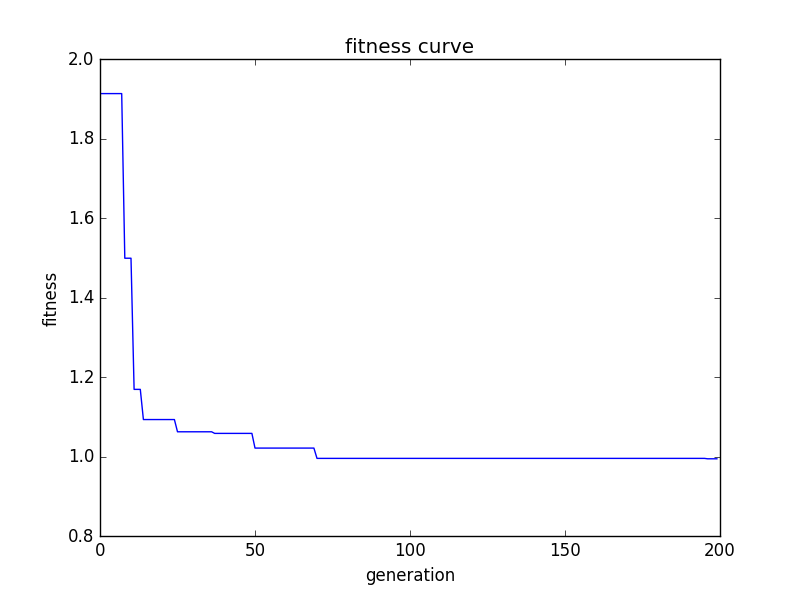
plt.show()输出结果为如下,可以看到它陷入了局部最优解
[-9.95932740e-01 2.82240596e-04]
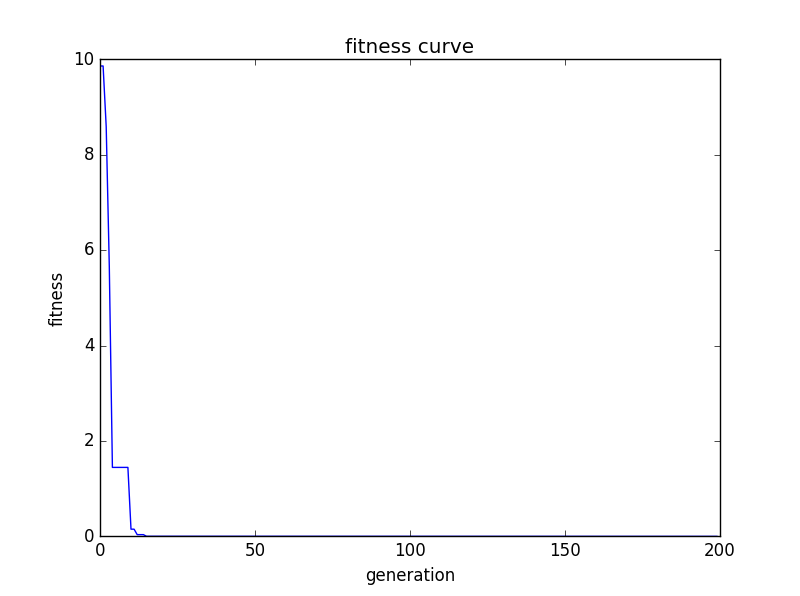
删除自适应变异部分的注释,运行后结果如下,可以看出收敛到全局最优解。
[0.00081551 -0.00011209]
五、参数选择
- 参数选择与优化
参数w,c1,c2的选择分别关系粒子速度的3个部分:惯性部分、社会部分和自身部分在搜索中的作用。如何选择、优化和调整参数,使得算法既能避免早熟又能比较快的收敛,对工程实践有着重要意义。
1. 惯性权重w描述粒子上一代速度对当前代速度的影响。w值较大,全局寻优能力强,局部寻优能力弱;反之,则局部寻优能力强。当问题空间较大时,为了在搜索速度和搜索精度之间达到平衡,通常做法是使算法在前期有较高的全局搜索能力以得到合适的种子,而在后期有较高的局部搜索能力以提高收敛精度。所以w不宜为一个固定的常数。
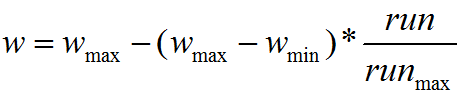
wmax最大惯性权重,wmin最小惯性权重,run当前迭代次数,runmax为算法迭代总次数。较大的w有较好的全局收敛能力,较小的w则有较强的局部收敛能力。因此,随着迭代次数的增加,惯性权重w应不断减少,从而使得粒子群算法在初期具有较强的全局收敛能力,而晚期具有较强的局部收敛能力。
2. 学习因子c2=0称为自我认识型粒子群算法,即“只有自我,没有社会”,完全没有信息的社会共享,导致算法收敛速度缓慢;学习因子c1=0称为无私型粒子群算法,即“只有社会,没有自我”,会迅速丧失群体多样性,容易陷入局部最优解而无法跳出;c1,c2都不为0,称为完全型粒子群算法,完全型粒子群算法更容易保持收敛速度和搜索效果的均衡,是较好的选择。
3. 群体大小m是一个整数,m很小时陷入局部最优解的可能性很大;m很大时PSO的优化能力很好,但是当群体数目增长至一定水平时,再增长将不再有显著作用,而且数目越大计算量也越大。群体规模m 一般取20~40,对较难或特定类别的问题 可以取到100~200。
4. 粒子群的最大速度Vmax对维护算法的探索能力与开发能力的平衡很重要,Vmax较大时,探索能力强,但粒子容易飞过最优解;Vmax较小时,开发能力强,但是容易陷入局部最优解。Vmax一般设为每维变量变化范围的10%-20%















 1077
1077











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









