






1.数据集的准备
参考这个博主的:数据集准备
2.生成train.json和test.json
由于我是用的命名方式是A后面是类别,R后面是次数,所以更改了两个地方。
注意:label 是从0开始的,所以需要-1。
我的代码都是在/root/pyskl下运行的。
import os
import json
import decord
def writeJson(path_train, jsonpath):
outpot_list = []
trainfile_list = os.listdir(path_train)
for train_name in trainfile_list:
traindit = {}
sp = train_name.split('A')
sp2 = sp[1].split('R')
traindit['vid_name'] = train_name.replace('.avi', '')
traindit['label'] = int(sp2[0])-1
traindit['start_frame'] = 0
video_path = os.path.join(path_train, train_name)
vid = decord.VideoReader(video_path)
traindit['end_frame'] = len(vid)
outpot_list.append(traindit.copy())
with open(jsonpath, 'w') as outfile:
json.dump(outpot_list, outfile)
def main():
path = './mydata/train'
j_path = './mydata/train.json'
writeJson(path,j_path)
if __name__ == '__main__':
main()路径是:~/pyskl/mydata/test和~/pyskl/mydata/train
上面的代码为create_json.py,路径是~/pyskl/json
终端在pyskl的环境下:
python json/create_json.py就能在 ~/pyskl/mydata路径下看到生成的test.js和train.js文件了
用记事本打开是这样的
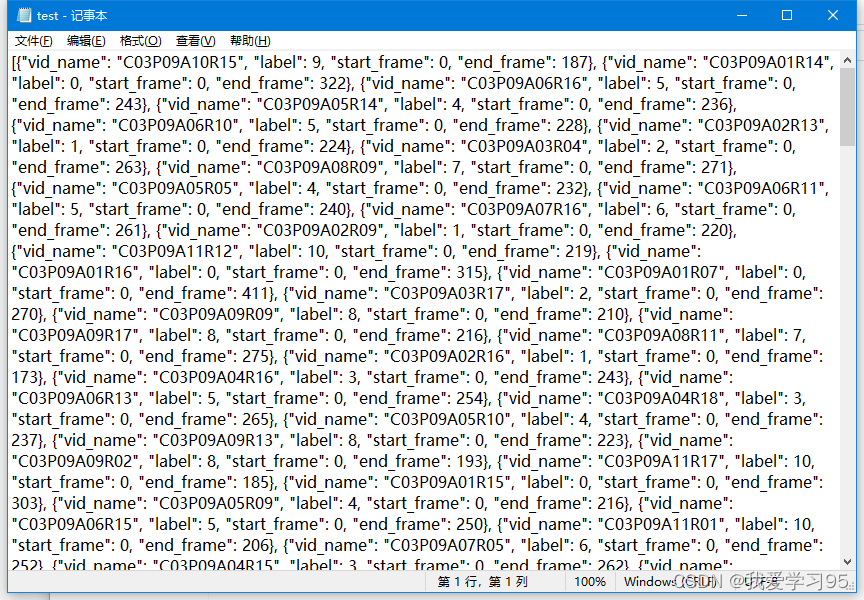
3.生成tools/data/custom_2d_skeleton.py需要的list文件
import os
def mwlines(lines, fname):
with open(fname, 'w') as fout:
fout.write('\n'.join(lines))
def writeList(dirpath, name):
path_train = os.path.join(dirpath, 'train')
path_test = os.path.join(dirpath, 'test')
trainfile_list = os.listdir(path_train)
testfile_list = os.listdir(path_test)
train = []
for train_name in trainfile_list:
traindit = {}
sp = train_name.split('A')
sp2 = sp[1].split('R')
traindit['vid_name'] = train_name
traindit['label'] = int(sp2[0])-1
train.append(traindit)
test = []
for test_name in testfile_list:
testdit = {}
sp3 = test_name.split('A')
sp4 = sp3[1].split('R')
testdit['vid_name'] = test_name
testdit['label'] = int(sp4[0])-1
test.append(testdit)
tmpl1 = os.path.join(path_train, '{}')
lines1 = [(tmpl1 + ' {}').format(x['vid_name'], x['label']) for x in train]
tmpl2 = os.path.join(path_test, '{}')
lines2 = [(tmpl2 + ' {}').format(x['vid_name'], x['label']) for x in test]
lines = lines1 + lines2
mwlines(lines, os.path.join(dirpath, name))
if __name__ == '__main__':
path = './mydata'
name = 'mydata.list'
writeList(path, name)
上面的代码为create_list.py,路径是~/pyskl/json
path是数据集的路径:我的是~/pyskl/mydata
name为生成的list文件名称,这里为 ‘mydata’,不要忘记加.list,不然生成的不是.list文件。
运行代码:
python json/create_list.py
记事本打开mydata.list
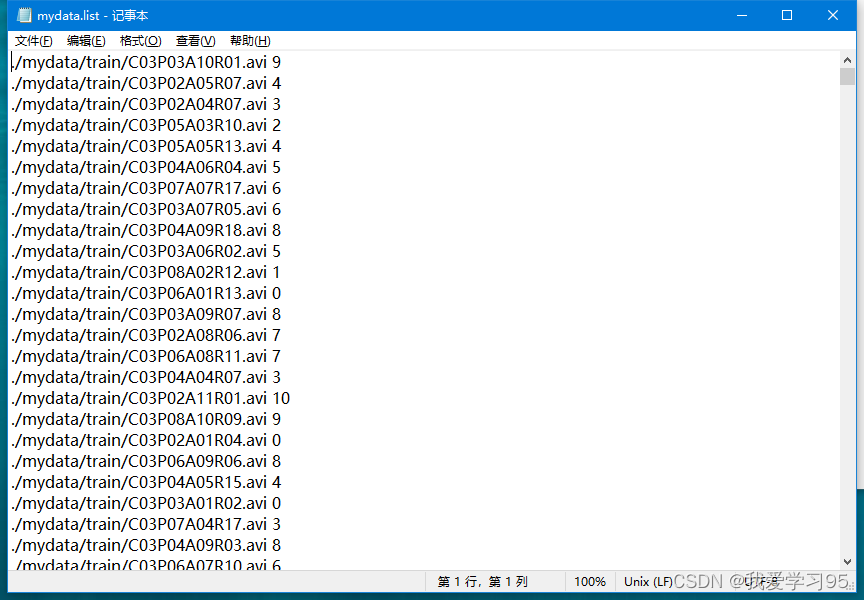
4.调用custom_2d_skeleton.py,生成训练模型要用的pkl文件
# Copyright (c) OpenMMLab. All rights reserved.
import argparse
import copy as cp
import decord
import mmcv
import numpy as np
import os
import os.path as osp
import torch.distributed as dist
from mmcv.runner import get_dist_info, init_dist
from tqdm import tqdm
import pyskl # noqa: F401
from pyskl.smp import mrlines
try:
import mmdet # noqa: F401
from mmdet.apis import inference_detector, init_detector
except (ImportError, ModuleNotFoundError):
raise ImportError('Failed to import `inference_detector` and '
'`init_detector` form `mmdet.apis`. These apis are '
'required in this script! ')
try:
import mmpose # noqa: F401
from mmpose.apis import inference_top_down_pose_model, init_pose_model
except (ImportError, ModuleNotFoundError):
raise ImportError('Failed to import `inference_top_down_pose_model` and '
'`init_pose_model` form `mmpose.apis`. These apis are '
'required in this script! ')
pyskl_root = osp.dirname(pyskl.__path__[0])
default_det_config = f'{pyskl_root}/demo/faster_rcnn_r50_fpn_1x_coco-person.py'
default_det_ckpt = ('./faster_rcnn_r50_fpn_1x_coco-person_20201216_175929-d022e227.pth')
# default_det_ckpt = (
# 'https://download.openmmlab.com/mmdetection/v2.0/faster_rcnn/faster_rcnn_r50_fpn_1x_coco-person/'
# 'faster_rcnn_r50_fpn_1x_coco-person_20201216_175929-d022e227.pth')
default_pose_config = f'{pyskl_root}/demo/hrnet_w32_coco_256x192.py'
default_pose_ckpt = ('./hrnet_w32_coco_256x192-c78dce93_20200708.pth')
# default_pose_ckpt = (
# 'https://download.openmmlab.com/mmpose/top_down/hrnet/'
# 'hrnet_w32_coco_256x192-c78dce93_20200708.pth')
def extract_frame(video_path):
vid = decord.VideoReader(video_path)
return [x.asnumpy() for x in vid]
def detection_inference(model, frames):
results = []
for frame in frames:
result = inference_detector(model, frame)
results.append(result)
return results
def pose_inference(anno_in, model, frames, det_results, compress=False):
anno = cp.deepcopy(anno_in)
assert len(frames) == len(det_results)
total_frames = len(frames)
num_person = max([len(x) for x in det_results])
anno['total_frames'] = total_frames
anno['num_person_raw'] = num_person
if compress:
kp, frame_inds = [], []
for i, (f, d) in enumerate(zip(frames, det_results)):
# Align input format
d = [dict(bbox=x) for x in list(d)]
pose = inference_top_down_pose_model(model, f, d, format='xyxy')[0]
for j, item in enumerate(pose):
kp.append(item['keypoints'])
frame_inds.append(i)
anno['keypoint'] = np.stack(kp).astype(np.float16)
anno['frame_inds'] = np.array(frame_inds, dtype=np.int16)
else:
kp = np.zeros((num_person, total_frames, 17, 3), dtype=np.float32)
for i, (f, d) in enumerate(zip(frames, det_results)):
# Align input format
d = [dict(bbox=x) for x in list(d)]
pose = inference_top_down_pose_model(model, f, d, format='xyxy')[0]
for j, item in enumerate(pose):
kp[j, i] = item['keypoints']
anno['keypoint'] = kp[..., :2].astype(np.float16)
anno['keypoint_score'] = kp[..., 2].astype(np.float16)
return anno
def parse_args():
parser = argparse.ArgumentParser(
description='Generate 2D pose annotations for a custom video dataset')
# * Both mmdet and mmpose should be installed from source
# parser.add_argument('--mmdet-root', type=str, default=default_mmdet_root)
# parser.add_argument('--mmpose-root', type=str, default=default_mmpose_root)
parser.add_argument('--det-config', type=str, default=default_det_config)
parser.add_argument('--det-ckpt', type=str, default=default_det_ckpt)
parser.add_argument('--pose-config', type=str, default=default_pose_config)
parser.add_argument('--pose-ckpt', type=str, default=default_pose_ckpt)
# * Only det boxes with score larger than det_score_thr will be kept
parser.add_argument('--det-score-thr', type=float, default=0.7)
# * Only det boxes with large enough sizes will be kept,
parser.add_argument('--det-area-thr', type=float, default=1600)
# * Accepted formats for each line in video_list are:
# * 1. "xxx.mp4" ('label' is missing, the dataset can be used for inference, but not training)
# * 2. "xxx.mp4 label" ('label' is an integer (category index),
# * the result can be used for both training & testing)
# * All lines should take the same format.
parser.add_argument('--video-list', type=str, help='the list of source videos')
# * out should ends with '.pkl'
parser.add_argument('--out', type=str, help='output pickle name')
parser.add_argument('--tmpdir', type=str, default='tmp')
parser.add_argument('--local_rank', type=int, default=0)
# * When non-dist is set, will only use 1 GPU
parser.add_argument('--non-dist', action='store_true', help='whether to use distributed skeleton extraction')
parser.add_argument('--compress', action='store_true', help='whether to do K400-style compression')
args = parser.parse_args()
# if 'LOCAL_RANK' not in os.environ:
# os.environ['LOCAL_RANK'] = str(args.local_rank)
args = parser.parse_args()
return args
def main():
args = parse_args()
assert args.out.endswith('.pkl')
lines = mrlines(args.video_list)
lines = [x.split() for x in lines]
# * We set 'frame_dir' as the base name (w/o. suffix) of each video
assert len(lines[0]) in [1, 2]
if len(lines[0]) == 1:
annos = [dict(frame_dir=osp.basename(x[0]).split('.')[0], filename=x[0]) for x in lines]
else:
annos = [dict(frame_dir=osp.basename(x[0]).split('.')[0], filename=x[0], label=int(x[1])) for x in lines]
if args.non_dist:
my_part = annos
os.makedirs(args.tmpdir, exist_ok=True)
else:
# init_dist('pytorch', backend='nccl')
# rank, world_size = get_dist_info()
# if rank == 0:
# os.makedirs(args.tmpdir, exist_ok=True)
# dist.barrier()
rank = 0 # 添加该
world_size = 1 # 添加
my_part = annos#[rank::world_size]
det_model = init_detector(args.det_config, args.det_ckpt, 'cuda')
assert det_model.CLASSES[0] == 'person', 'A detector trained on COCO is required'
pose_model = init_pose_model(args.pose_config, args.pose_ckpt, 'cuda')
results = []
for anno in tqdm(my_part):
frames = extract_frame(anno['filename'])
det_results = detection_inference(det_model, frames)
# * Get detection results for human
det_results = [x[0] for x in det_results]
for i, res in enumerate(det_results):
# * filter boxes with small scores
res = res[res[:, 4] >= args.det_score_thr]
# * filter boxes with small areas
box_areas = (res[:, 3] - res[:, 1]) * (res[:, 2] - res[:, 0])
assert np.all(box_areas >= 0)
res = res[box_areas >= args.det_area_thr]
det_results[i] = res
shape = frames[0].shape[:2]
anno['img_shape'] = shape
anno = pose_inference(anno, pose_model, frames, det_results, compress=args.compress)
anno.pop('filename')
results.append(anno)
if args.non_dist:
mmcv.dump(results, args.out)
else:
mmcv.dump(results, osp.join(args.tmpdir, f'part_{rank}.pkl'))
# dist.barrier()
if rank == 0:
parts = [mmcv.load(osp.join(args.tmpdir, f'part_{i}.pkl')) for i in range(world_size)]
rem = len(annos) % world_size
if rem:
for i in range(rem, world_size):
parts[i].append(None)
ordered_results = []
for res in zip(*parts):
ordered_results.extend(list(res))
ordered_results = ordered_results[:len(annos)]
mmcv.dump(ordered_results, args.out)
if __name__ == '__main__':
main()
参考了三个人的:做了一些修改,主要就是32-39行,可以本地下载好,也可以链接到官网下载。
Pyskl自定义数据集_墨末..的博客-CSDN博客
使用pyskl的stgcn++训练自己的数据集_大脸猫105的博客-CSDN博客
基于pyskl的poseC3D训练自己的数据集_骑走的小木马的博客-CSDN博客
因为我的 faster_rcnn_r50_fpn_1x_coco-person_20201216_175929-d022e227.pth和hrnet_w32_coco_256x192-c78dce93_20200708.pth文件是放在pyskl下面的,所以路径是./文件名
终端运行下面的命令:(这里我是将修改后的custom_2d_skeleton.py文件放在pyskl/json文件里的,如果不另存就是在tools/)
python json/custom_2d_skeleton.py --video-list ./mydata/mydata.list --out ./mydata/train.pkl
慢慢等。。。。

此时的mydata文件及下的文件
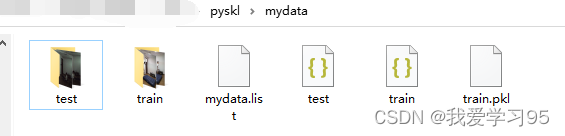
5.训练模型
根据上面生成的train.pkl和train.json、test.json文件,生成训练要用的pkl文件。
运行: create_final_pkl.py文件生成 My_xsub_stgn++.pkl
import os
from mmcv import load, dump
from pyskl.smp import *
def traintest(dirpath,pklname,newpklname):
os.chdir(dirpath)
train = load('train.json')
test = load('test.json')
annotations = load(pklname)
split = dict()
split['xsub_train'] = [x['vid_name'] for x in train]
split['xsub_val'] = [x['vid_name'] for x in test]
dump(dict(split=split, annotations=annotations), newpklname)
if __name__ == '__main__':
path = './mydata'
old_pklname = 'train.pkl'
new_pklname = 'My_xsub_stgn++.pkl'
traintest(path, old_pklname, new_pklname)
选择需要的模型,我选择了stgcn++,再打开\configs\stgcn++\stgcn++_ntu120_xsub_hrnet文件,打开j.py程序如下,做一些修改。
注意:ann_file的路径就是你上面生成的My_xsub_stgn++.pkl。
# num_classes=11 改成自己数据集的类别数量,我的是11
model = dict(
type='RecognizerGCN',
backbone=dict(
type='STGCN',
gcn_adaptive='init',
gcn_with_res=True,
tcn_type='mstcn',
graph_cfg=dict(layout='coco', mode='spatial')),
cls_head=dict(type='GCNHead', num_classes=11, in_channels=256))
dataset_type = 'PoseDataset'
# ann_file,改成上面存放pkl文件的路径
ann_file = './mydata/My_xsub_stgn++.pkl'
# 下面的train_pipeline、val_pipeline和test_pipeline中num_person可以改成1,我猜是视频中人的数
# 量,但是没有证据
train_pipeline = [
dict(type='PreNormalize2D'),
dict(type='GenSkeFeat', dataset='coco', feats=['j']),
dict(type='UniformSample', clip_len=100),
dict(type='PoseDecode'),
dict(type='FormatGCNInput', num_person=1),
dict(type='Collect', keys=['keypoint', 'label'], meta_keys=[]),
dict(type='ToTensor', keys=['keypoint'])
]
val_pipeline = [
dict(type='PreNormalize2D'),
dict(type='GenSkeFeat', dataset='coco', feats=['j']),
dict(type='UniformSample', clip_len=100, num_clips=1, test_mode=True),
dict(type='PoseDecode'),
dict(type='FormatGCNInput', num_person=1),
dict(type='Collect', keys=['keypoint', 'label'], meta_keys=[]),
dict(type='ToTensor', keys=['keypoint'])
]
test_pipeline = [
dict(type='PreNormalize2D'),
dict(type='GenSkeFeat', dataset='coco', feats=['j']),
dict(type='UniformSample', clip_len=100, num_clips=10, test_mode=True),
dict(type='PoseDecode'),
dict(type='FormatGCNInput', num_person=1),
dict(type='Collect', keys=['keypoint', 'label'], meta_keys=[]),
dict(type='ToTensor', keys=['keypoint'])
]
# 这里的split='xsub_train'、split='xsub_val'可以按照自己写入的时候的key键进行修改,但是要保证
# wei_xsub_stgn++_ch.pkl中的和这里的一致
data = dict(
videos_per_gpu=16,
workers_per_gpu=2,
test_dataloader=dict(videos_per_gpu=1),
train=dict(
type='RepeatDataset',
times=5,
dataset=dict(type=dataset_type, ann_file=ann_file, pipeline=train_pipeline, split='xsub_train')),
val=dict(type=dataset_type, ann_file=ann_file, pipeline=val_pipeline, split='xsub_val'),
test=dict(type=dataset_type, ann_file=ann_file, pipeline=test_pipeline, split='xsub_val'))
# optimizer
optimizer = dict(type='SGD', lr=0.1, momentum=0.9, weight_decay=0.0005, nesterov=True)
optimizer_config = dict(grad_clip=None)
# learning policy
lr_config = dict(policy='CosineAnnealing', min_lr=0, by_epoch=False)
# 可以修改训练的轮数total_epochs
total_epochs = 100
checkpoint_config = dict(interval=1)
evaluation = dict(interval=1, metrics=['top_k_accuracy'])
log_config = dict(interval=100, hooks=[dict(type='TextLoggerHook')])
# runtime settings
log_level = 'INFO'
# work_dir为保存训练结果文件的地方,可以自己修改
work_dir = './work_dirs/stgcn++/stgcn++_ntu120_xsub_hrnet/j_Wei5'
bash tools/dist_train.sh configs/stgcn++/stgcn++_ntu120_xsub_hrnet/j.py 1 --validate --test-last --test-best

6.跑demo
使用自己训练好的模型生成demo
需要在 ./tools/data/label_map文件夹下建立数据集标签名称,从小到大排列,这样得到的输出视频画面中的标签才不会错。
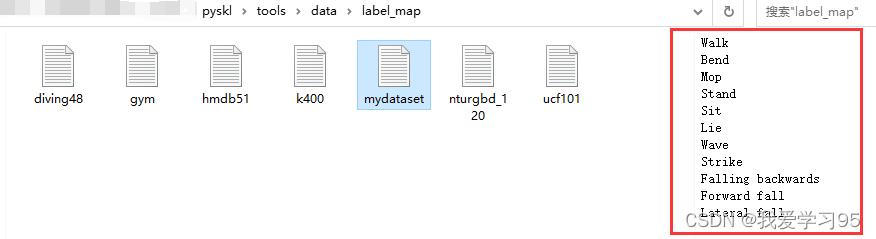
这里的--checkpoint根据自己生成的文件定我的是best_top1_acc_epoch_26.pth。
python demo/demo_skeleton.py Video/C03P09A10R17.avi Video/C03P09A10R17_demo.mp4
--config ./configs/stgcn++/stgcn++_ntu120_xsub_hrnet/j.py
--checkpoint ./work_dirs/stgcn++/stgcn++_ntu120_xsub_hrnet/j_Wei5/best_top1_acc_epoch_26.pth
--label-map ./tools/data/label_map/mydataset.txt
最后我测试向前摔倒的视频就输出了!!!!

第一次跑代码跑模型太不容易了,起步很难,大家一起加油。

















 1794
1794

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









