







Operation on data

C++ Standard library:
C++ 标准库(library)包含了多个头文件和命名空间
header files
- 头文件是 C++ 中用来包含函数声明、类声明、常量声明等的文本文件。
- 头文件通常包含了程序中需要用到的声明和定义,而具体的实现通常在源文件(.cpp 文件)中。
- 头文件的目的是实现模块化、提高代码可读性和可维护性,同时也是一种重用代码的方式。
- 在使用头文件时,通常使用 #include 预处理指令将头文件包含进来,以便编译器能够识别其中的声明和定义,并在编译时将其编译成相应的代码。
头文件用于包含声明和定义,以便在程序中进行使用。
头文件是一种约定,用于提供声明和定义的接口
- 输入输出(I/O):包括 <iostream>、<fstream>、<iomanip> 等头文件,提供了对标准输入输出、文件输入输出、格式化输出等功能的支持。
- 容器和算法:包括 <vector>、<list>、<map>、<algorithm> 等头文件,提供了各种容器(如动态数组、链表、映射等)和算法(如排序、查找、变换等)的实现。
- 字符串和文本处理:包括 <string>、<regex>、<sstream> 等头文件,提供了对字符串和正则表达式的支持。
- 时间和日期处理:包括 <chrono>、<ctime> 等头文件,提供了对时间和日期的支持。
- 数学库:包括 <cmath>、<random> 等头文件,提供了数学计算和随机数生成的支持。
- 内存管理和智能指针:包括 <memory>、<new> 等头文件,提供了对内存管理和智能指针的支持。
- 多线程支持:包括 <thread>、<mutex>、<future> 等头文件,提供了对多线程编程的支持。
- 标准异常处理:包括 <exception> 头文件,提供了标准的异常类和异常处理机制。
- 标准模板库(STL):包括 <algorithm>、<iterator>、<functional> 等头文件,提供了通用的数据结构和算法支持。
<iostream>
iostream既是库也是头文件
作为库:
是 C++ 标准库的一部分,它提供了用于输入输出的基本功能。具体来说,iostream 主要包含了 cin、cout、cerr、clog 等对象以及相应的流操作符(<<、>>),用于标准输入、标准输出、标准错误输出和日志输出等。
作为头文件:
也是一个头文件,位于 C++ 标准库中,并用于包含相关的类和函数的声明。当我们在 C++ 程序中需要使用输入输出功能时,通常会在代码中包含 iostream 头文件,以便能够使用其中定义的类和函数。
包含许多类和函数,比如cin,cout,cerr,clog
<unordered_map>
<unordered_map> 是 C++ 标准库中提供的头文件之一,用于包含无序映射(std::unordered_map)的相关定义和功能。头文件 <unordered_map> 包含了对 std::unordered_map 类型的声明以及与之相关的函数和类的定义。
namespace
命名空间用于组织和限制代码的作用域
命名空间是一种语言特性,用于组织代码结构
- 命名空间是 C++ 中用来组织代码和避免命名冲突的一种机制。
- 命名空间可以包含类、函数、变量等,用来将一组相关的实体封装在一起,并限制它们的作用域。
- 通过命名空间,可以避免不同模块之间的命名冲突,使得代码更加清晰和易于维护。
- 声明命名空间使用 namespace 关键字,例如 namespace mynamespace { ... }。
- 在代码中访问命名空间中的实体时,需要使用命名空间限定符 ::,例如 mynamespace::function()。
这些命名空间包含了标准库中定义的各种类、函数、对象等:
- td:这是 C++ 标准库中最常见的命名空间,包含了大部分标准库中的内容,如输入输出流、容器、算法等。
- chrono:包含了时间和日期相关的类和函数,如 std::chrono::system_clock、std::chrono::duration 等。
- filesystem:包含了文件系统操作相关的类和函数,如 std::filesystem::path、std::filesystem::directory_iterator 等。
- regex:包含了正则表达式相关的类和函数,如 std::regex、std::regex_match、std::smatch 等。
- thread:包含了多线程相关的类和函数,如 std::thread、std::mutex、std::condition_variable 等。
- atomic:包含了原子操作相关的类和函数,如 std::atomic、std::atomic_flag 等。
- future:包含了异步操作相关的类和函数,如 std::future、std::promise、std::async 等。
- random:包含了随机数生成相关的类和函数,如 std::random_device、std::uniform_int_distribution、std::mt19937 等。
- tuple:包含了元组相关的类和函数,如 std::tuple、std::get、std::make_tuple 等。
- numeric:包含了数值操作相关的函数,如 std::accumulate、std::inner_product、std::partial_sum 等。
std
是 C++ 标准库中的命名空间(namespace)
包含了 C++ 标准库中定义的所有内容,包括容器、算法、迭代器、输入输出、智能指针等等
#include<stdio.h>
是C标准库(C standard library)中的一个头文件,它包含了对输入输出(I/O)操作相关的函数、宏和类型的声明。例如,printf、scanf、FILE、fopen 等函数和类型都在 stdio.h 中定义。
int main()
c++程序的入口点(起始点):运行一个c++程序时,操作系统会调用”main“函数来启动程序的执行
返回值:int 表示 main 函数运行后返回值的类型(即整数)
接受命令行参数:ex:int main(int argc, char* argv[]){}可以用来接受命令行参数,其 中‘argc’表示参数的个数,argv是一个指向 参数字符串数组 的指针
其中argv[a] a<argc 是一个指向参数字符串数组
最后一行的 return 0;
1:返回 0表示成功运行完(运行到最后一行代码即statement)
也可以返回其他值
2:运行完会使整个程序退出
定义int类型变量 并确定他的值
ex:int age{21};
Comment
one line comment
//
a block comment
/*
content
*/
Statements
statements must end with the semicolon
ex:
int main(int argc,char **argv)
{
int firstNumber = 12;
int secondNumber = 9;
int sum = firstNumber + secondNumber;
std::cout << "The sum of the two numbers is :<< sum << std::endl;
return 0;
}
Function
define a function(out of int main):
ex:
int addNumbers(int first_number, int second number){
int sum = first_number + second number;
return sum;
}
use a function:
ex:
int main(int argc, char **argv)
{
int firstNumber = 12;int secondNumber = 9;
int sum = firstNumber + secondNumber;
sum = addNumbers(firstNumber,secondNumber);
sum = addNumbers(34,7);
std::cout << "The sum of the two numbers is :<< sum << std::endl;
std::cout<< "The sum of the two numbers is :<< addNumbers(23,8) << std::end1;
return ;
}
Output
- std::cout:这部分代表了标准输出流对象
- std 是C++标准库(Standard Library)的命名空间,它包含了许多标准的C++函数、类和对象
- 命名空间:允许将相关的函数、类和对象放在一个特定的命名空间中
- cout std 命名空间中的一个对象,用于标准输出(通常是控制台)打印文本数据
- <<:这个操作符用于将数据插入到输出流中。在这里,它被用于连接不同的数据,以便一起输出
- "The sum of the two numbers is :":这是一个字符串,它会被输出到标准输出
- sum:这是一个变量,它的值将被输出到标准输出
- std::endl:这是一个用于输出换行符的特殊标志。它的作用是在输出完成后添加一个换行符,以使输出的内容在终端上显示在不同的行上

std::cout
highway to bring data out of program
std::cin
highway to bring data in program
std::cerr
highway to bring errors information out of program
std::clog
highway to bring log out of program
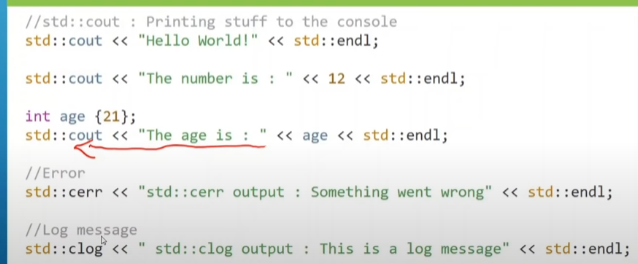
output text and int together
std::cout<<'' text1"<<int <<"text2"<<std::endl;


Input
#include <iostream>
#include <string>
int main(){
int age1;
std::string name;
std::cout<<"Please type your name age:"<<std::endl;
std::cin>>name>>age1; % input name firstly, age1 secondly
return 0;
}
Bring in data with spaces
#include <iostream>
#include <string>
int main(){
int age1;
std::string name;
std::cout<<"Please type your name age:"<<std::endl;
std::getline(std::cin,name);
std::cin>>age1;
return 0;
}
Complement:
std::string 是 C++ 标准库中提供的用于处理字符串的类。在 C++ 中,字符串通常是以 char 数组的形式表示的,但是使用 std::string 类可以更方便地处理字符串,而不需要手动管理内存分配和释放,同时提供了丰富的字符串操作功能。
std::string 类提供了一系列成员函数来进行字符串操作,比如连接字符串、查找子串、获取字符串长度等等。使用 std::string 类可以简化字符串操作的代码,提高代码的可读性和可维护性。
C++ execution model:
mechanism of C++ Program
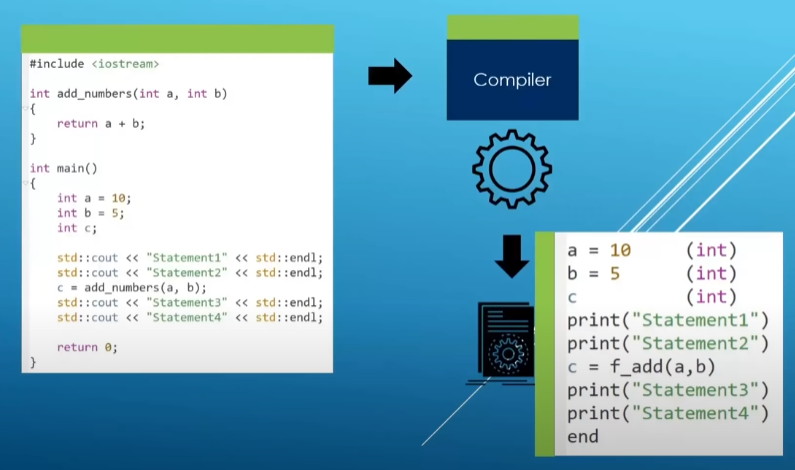
code(statement)>>compile into exe>>binery file(not readiable or opened by ides only machine or cpu can read)
double click to run (or run in vs code terminal)
cpu allocated special memory location for function


Core Language VS Standard Library VS STL
Core langugae:
include basic c++ code rules
ex:rule of define a function
Standard library:
ex: iostream provide components like cout cin clong cerr
string
stl
1.a part of standard library
2.a collection of container types
Varaibles
a named piece of memory that use to store specific types of data
1.variable name rule:
first element of variable name must be letter
no space or spatial charactes in variable name
2.intialization variables:
examplify with integer
(1)braced initialization
![]()
use {} curly braces to intialize variable (lion_count) to zero by fault
otherwize variable may contain random value
![]()
---elephant_cout is random value
put a value in {} to intial variable to the value
![]()
if the value is fractional number ,it will give a compiler erro
use variables (which have been intialized) to do operations in {} to intalize another variable

(2)functional initialization

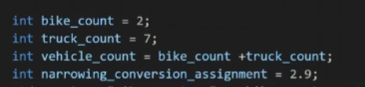
![]()
Information loss:if the value is fractional number ,it will lose fractional part
because fractional number need more than 4 types
integer variable usually only store 4 bytes
so functional initialization is less safe than braced intialization
(3)assignment initialization
Information loss:if the value is fractional number ,it will lose fractional part
because fractional number need more than 4 types
integer variable usually only store 4 bytes
so assignment initialization is less safe than braced intialization
注:
After initialize a variable a value
The variable can be assigned a new value
ex:

3.general rule to initialize variable

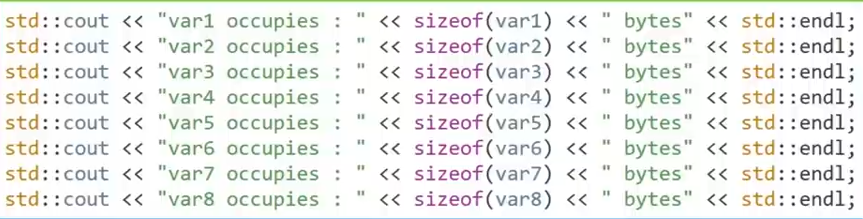
4.query for the size of variable with sizeof:
tell us how much memory an integer occupies in our program
![]()
tell us how much memory the variable occupies in our program
![]()
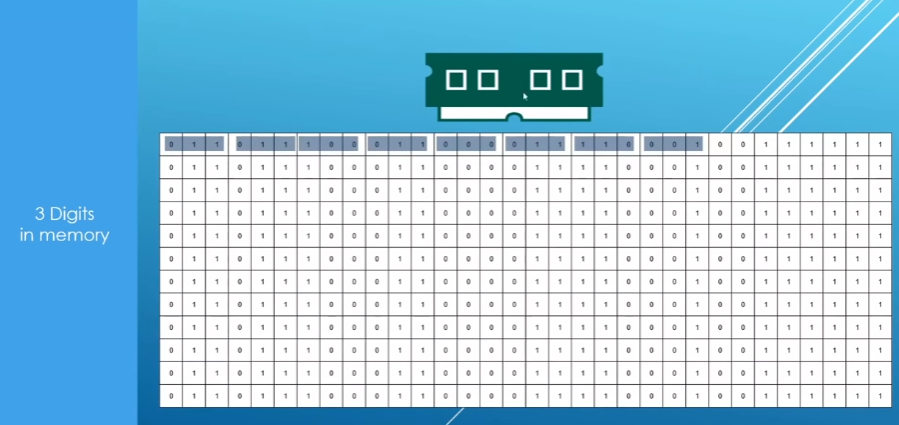
Data storing form:

Bit:
one or zero in ram(random acess memory)
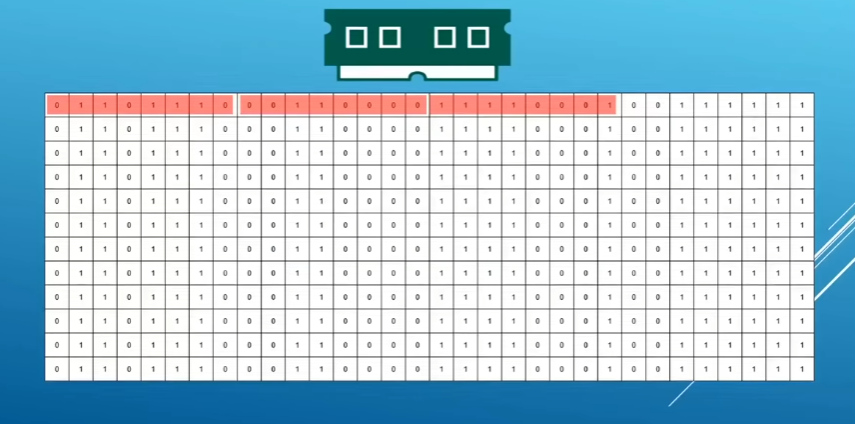
Byte:
group eight bits together
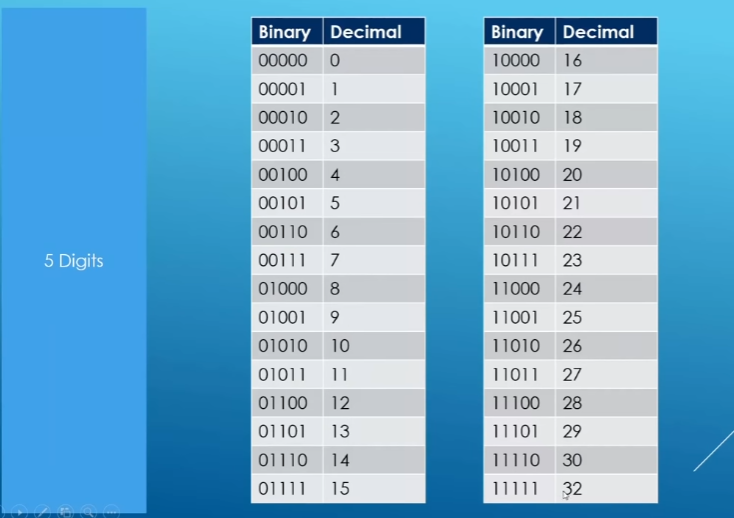
Number systems:
1.transform data
from
the form that is convient for human
to
the form (ones and zeros)that is convient for coumpters

2.we can use different number system to store data
binary(二进制)
binary>>decimal
Add 0b front mean number (next 0b ) is present in hexadecimal system
First 0b mean no number
but next 0b mean octal
![]()
![]()
come out with 15

octal(八进制)
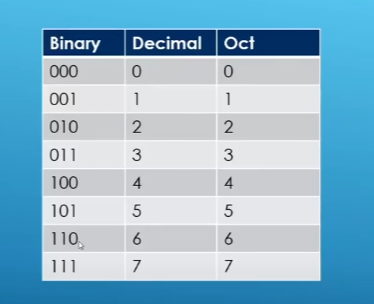
Add 0 front mean number (next 0) is present in octal system
First 0 mean no number
but next zero mean octal
ex:
![]()
![]()
come out with 15
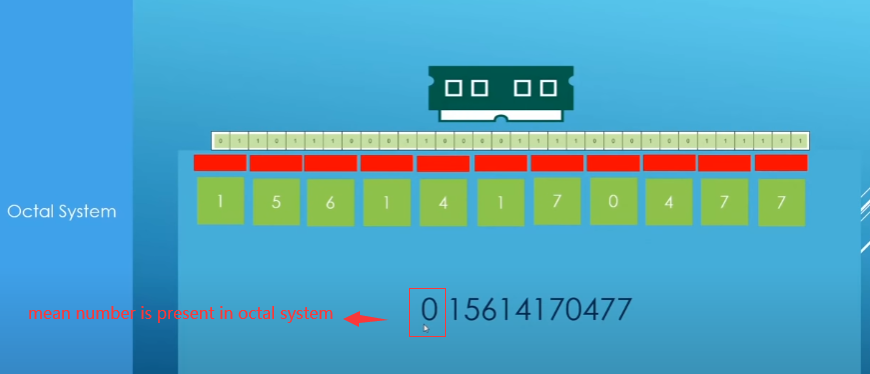
decimal(十进制)

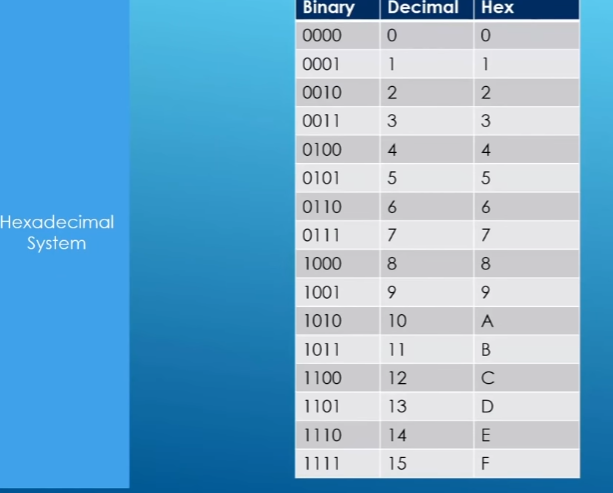
hexadecimal(十六进制)
use to shorten the length of how we represent a binary number in memory
Add 0x front mean number (next 0x) is present in hexadecimal system
First 0x mean no number
but next 0x mean octal
ex:
![]()
![]()
come out with 15

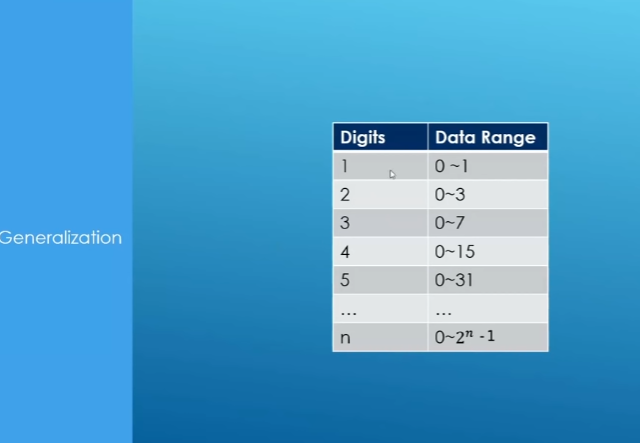
32进制

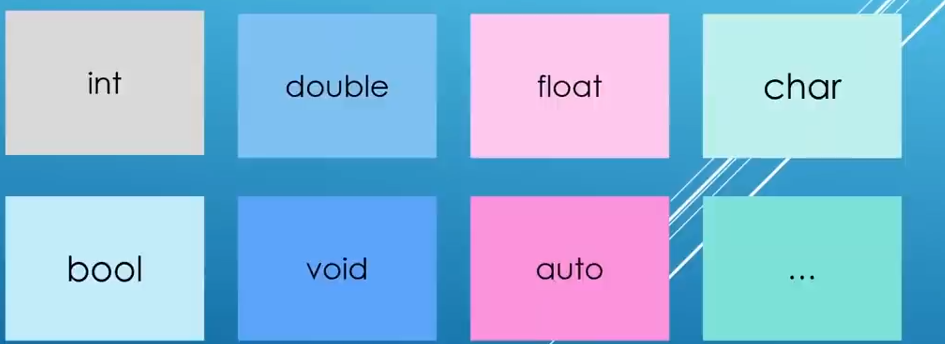
Date type
int(integers):
double and float:
used to represent fractional number(numbers that have decimal)
char :
represent characters(字母 a b c) in memory
bool:
store two possible states(ture or false)
void :
represents a typeless type
auto:
not a type it is a keyword to deduce other types
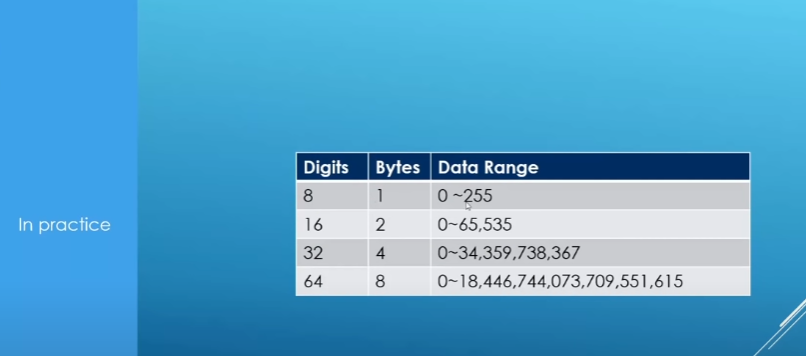
Integer(int):
integer variable usually only store 4 bytes
Integer modifiers
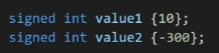
signed integer modifier(4 bytes):can store negative and positive numbers
unsigned integer modifier(4 bytes):only store positive numbers
if try to put in a negative number ,it will get a compiler error

short integer modifiers(2 bytes):
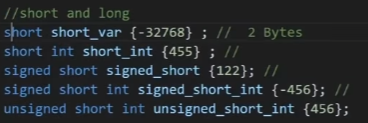
long integer modifiers(4 bytes):
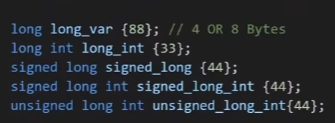
long long integer modifiers(8 bytes):
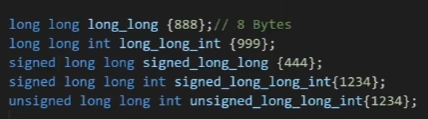
补:
unsigned integer modifier(4 bytes): only store positive numbers
if try to put in a negative number ,it will get a compiler error

Fractional numbers
Floating point types include float , double and long double
The difference is in the size they occupy in memory
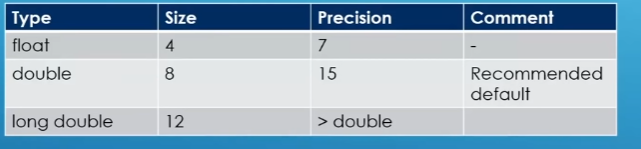

Precision: the numer of bits (that can present with that type) starting from the number in the right of the decimal point
Scientific notation:


ex: age--a named piece of memory

--- store in binary format
Float
store fractional number with certain precision(7)
float variable usually only store 4 bytes
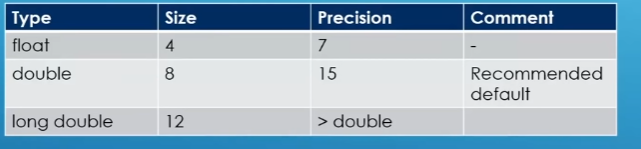
Double
store fractional number with certain precision(15 or >15)
double variable usually only store 8 bytes
long double variable usually only store 12 bytes
Boolean(bool):
store two states (either ture or false)
occupy 8 bits(1 byte) in memory

ex:
in if statement
boolean == ture
boolean
都可以是判断语句,其值都为该boolean的值

print out a bool
(1)only print out 0 or 1

(2) print out ture or false
std::cout << std::boolalpha; ----force the output format to ture/false
std::cout << std::noboolalpha; -------cancel the output format to
ture/false to 1/0
Characters and text (char)
store characters or text
each character occupy 8 bits(1 byte) in memory
in the mechanism of coding and encoding character
so it can be 2^8 (256 ASCII decimal numbers) possible values to be macth to some specific meanings
downside even numbers means character if combine together

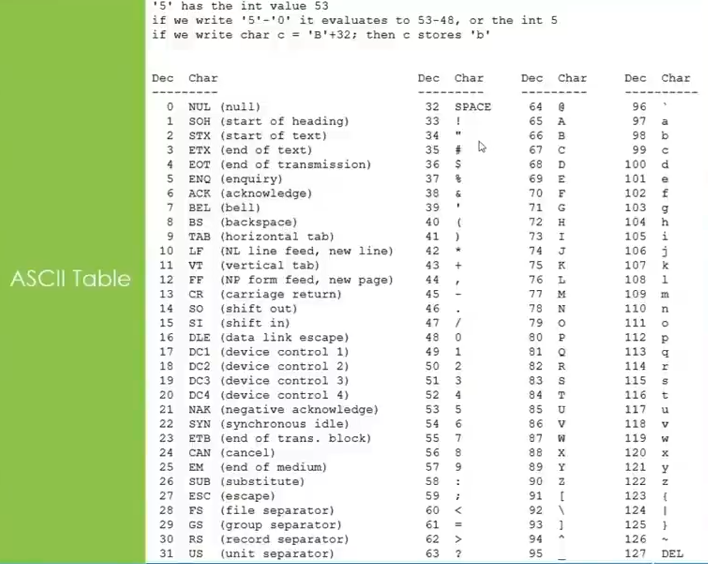
other language character is not feasible

Initialize chararcters:
(1) Braced initialization

(2)ASCII decimal number initialization


注:static_cast<int>(char_variable): transfer char to int
static_cast<char>(int_variable): transfer int to char
Print out char

char/int
可以把char视作整数 进行一些运算
#include <iostream>
int main() {
char ch = 'A'; // 字符'A'的ASCII码值是65
// 将 char 视为整数,进行算术运算
int result = ch + 5; // 65 + 5 = 70,字符'A'后面第五个字符是'E'
std::cout << "Character: " << ch << std::endl;
std::cout << "ASCII value of ch: " << static_cast<int>(ch) << std::endl;
std::cout << "Result after adding 5: " << static_cast<char>(result) << std::endl;
// 将 char 与整数进行比较
if (ch == 65) { // 比较字符'A'的ASCII码值是否等于65
std::cout << "ch is equal to 65" << std::endl;
} else {
std::cout << "ch is not equal to 65" << std::endl;
}
return 0;
}

Auto
Let the compiler deduce the type
ex:

ex:
int
double
fluid
long double
char
usigned int
usigned long int
long long int

Pointer
复合数据类型
- 数组:包括一维数组、多维数组
- 结构体(struct):通过组合不同类型的数据成员来创建的用户定义类型
- 枚举(enum):用于定义用户定义的枚举类型
- 指针(pointer):用于存储内存地址的特殊数据类型
- 类(class):用于创建用户定义的数据类型,包括类的成员变量和成员函数
自定义的数据类型别名
typedef 和 using 都可以用来创建自定义的数据类型别名,两者的功能基本相同,只是使用语法上稍有不同
#include <iostream>
// 定义一个 typedef 别名
typedef int Integer;
int main() {
// 使用 Integer 别名声明变量
Integer num = 10;
// 输出变量值
std::cout << "Value of num: " << num << std::endl;
return 0;
}
#include <iostream>
// 使用 using 创建别名
using Integer = int;
int main() {
// 使用 Integer 别名声明变量
Integer num = 10;
// 输出变量值
std::cout << "Value of num: " << num << std::endl;
return 0;
}函数指针
function pointer
在C++中,定义函数指针类型的语法如下:
cpptypedef 返回类型 (*指针名称)(参数列表);其中:
- 返回类型表示函数返回的数据类型。
- 指针名称是你给函数指针类型起的名字。
- 参数列表是函数所接受的参数类型和数量。
举个例子,假设有一个函数原型如下:
cppint add(int a, int b);你可以定义一个指向这个函数的函数指针类型,如下所示:
cpptypedef int (*AddFunctionPtr)(int, int);现在 AddFunctionPtr 是一个指向 add 函数的函数指针类型。你可以使用这个类型声明函数指针变量,并将其指向 add 函数:
cppAddFunctionPtr ptr = add;然后,你可以通过该指针调用 add 函数:
cppint result = ptr(3, 4); // 调用 add 函数,将 3 和 4 作为参数传递这样,函数指针类型就允许你在代码中动态地选择和调用不同的函数。
Void
void:表示无类型,通常用于函数返回类型或指针类型。
void function_name(); // 声明一个不返回任何值的函数
void* pointer_name; // 定义一个空指针注:
Reference is not data type ,it is just alias of other varible
Reference don't store data
void* 是 C 和 C++ 中的一种特殊指针类型,通常被称为“无类型指针”。它可以指向任意类型的数据,因为它没有指定指向的数据类型。
由于 void* 指针没有类型信息,所以它通常用于在程序中以通用的方式处理内存地址,而不关心该地址指向的具体类型。例如,在动态内存分配中,void* 常用于指向 malloc 或 new 返回的内存块,然后根据需要将其转换为特定类型的指针。在某些情况下,它也用于在函数中传递任意类型的指针参数。
使用 void* 指针时要格外小心,因为由于它没有类型信息,编译器无法在编译时检查它的正确性,因此可能导致类型错误或未定义的行为。
Enumeration Types
- enum:用于定义枚举类型的关键字。
#include <iostream>
// 定义一个枚举类型 Weekday,包括星期一到星期日
enum Weekday {
Monday,
Tuesday,
Wednesday,
Thursday,
Friday,
Saturday,
Sunday
};
int main() {
// 声明一个 Weekday 类型的变量
Weekday today = Tuesday;
// 输出今天是星期几
std::cout << "Today is ";
switch (today) {
case Monday:
std::cout << "Monday";
break;
case Tuesday:
std::cout << "Tuesday";
break;
case Wednesday:
std::cout << "Wednesday";
break;
case Thursday:
std::cout << "Thursday";
break;
case Friday:
std::cout << "Friday";
break;
case Saturday:
std::cout << "Saturday";
break;
case Sunday:
std::cout << "Sunday";
break;
}
std::cout << std::endl;
return 0;
}
Data operation:
Addition

Subtraction:

Miltiplication:

Division
if the result contain fractional numbers ,it wil hide them


modulus operater
using %
计算结果是余数


Precedence and Associativity

Prefix or posfix increment/decrement
regular increment/decrement:

![]()
postfix increment/decrement:
variable++ :means variable increase by one
but not increase directly
only hapen after the statement variable++ was done
(same to variable--)

prefix increment/decrement
variable++ :means variable increase by one directly
(same to variable--)
diffenerce to variable+1:
the result is same
but variable++ make variable increase
variable+1 don't

Compound operators
format:
variable 运算符=value
variable = variable 运算符 value

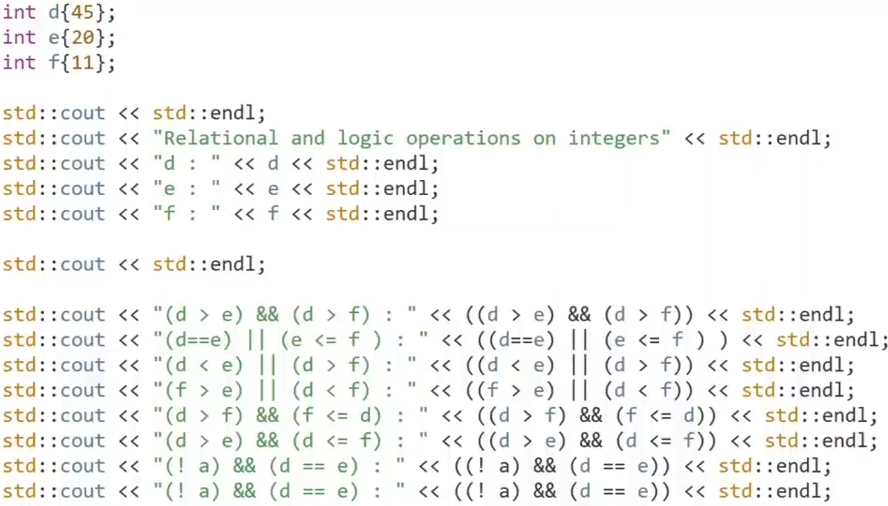
Relational Operators : comparing stuff
wrap comparison expression into parentheses()
else a compiler error happens
( comparison)--- become a boolean value

Logical Operators
Logical Operators always work with booleans
" and " operation
use two ampersand symbols (&&)


" or "operation
use two bar()

"not "operation

combined logical operator

combined relational and logical operator
Output formatting

two libraries to be used

manipulators (functions) in these two libraries

Input/output manipulators - cppreference.com
std::endl
used to seperate a new line

![]()

![]()
used \n to seperate a new line
but std::endl and \n are two different thing

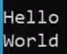
std::flush

send whatever is in the output buffer to the terminal
std::flush 是 C++ 标准库中的输出流操纵符,用于强制刷新输出缓冲区,把缓冲区的东西 发到 终端上(强制将缓冲区中的数据立即写入到输出设备)
what is output buffer(输出缓冲区)
在 C++ 中,std::cout 和其他输出流(如文件输出流)通常都具有一个输出缓冲区。当你使用 << 运算符向流中写入数据时,数据实际上被存储在输出缓冲区中,而不是立即写入到输出设备(如屏幕或文件)中。这是为了提高程序的性能,因为逐个字符地写入数据到输出设备可能会变得很慢。
std::flush 的作用是强制将缓冲区中的数据立即写入到输出设备中,而不等待缓冲区满或程序结束。这可以用于以下情况:
- 实时输出: 当你需要立即将数据显示在屏幕上时,可以使用 std::flush 来清空缓冲区,以确保数据立即可见。例如,如果你正在执行一个需要长时间计算的操作,而希望显示进度条或中间结果,可以使用 std::flush 来强制刷新输出。
- 与错误处理结合使用: 在某些情况下,当程序遇到错误时,你可能希望立即将错误消息输出到屏幕,而不是等待程序正常结束后才显示。这可以通过使用 std::flush 来实现。
cppCopy code
std::cout << "Processing... " << std::flush;
// 执行一些耗时操作
// ...
std::cout << "Done!" << std::endl;cppCopy code
if (errorCondition) {
std::cerr << "Error occurred!" << std::flush;
// 处理错误
// ...
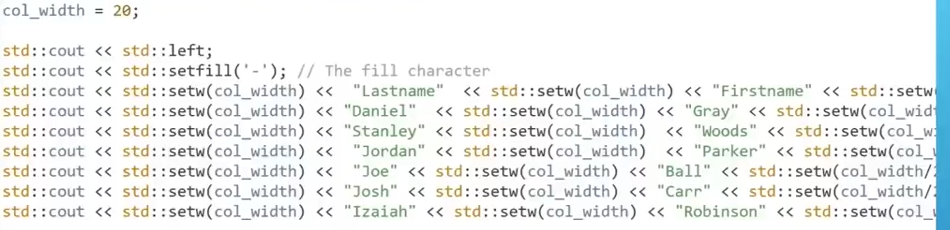
}std::setw(n):
specifiy a width for whatever text you want to print
format:
std::cout<<std::setw(n):<<"the text"<<std:endl;
(1)n----n characters wide (the width that the text occupied)
(2) the text ioccupies in the mid of width by default
(3) "the text"(char) can be replaced to number(int or double)
ex:
no format

format:

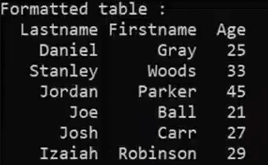
std::right
(1)right justification for text(char)
used before std::out and std::setw(n)
make the text occupying in the right of width

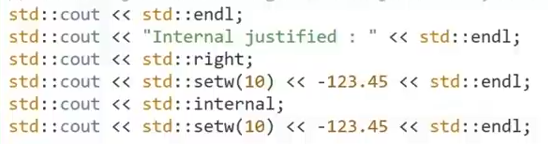
(2)internal justification for number(int or double)
used before std::out and std::setw(n)
make the negative sign occupying in the left of width
make the number(without negative sign) occupying in the left of width
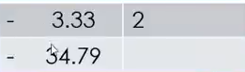
std::setfill( data )
fill the rest of the width with data repeatedly
(the data can be any data type)

std::boolapha
std::cout << std::boolalpha; ----force the output format to ture/false
std::cout << std::noboolalpha; -------cancel the output format to
ture/false to 1/0
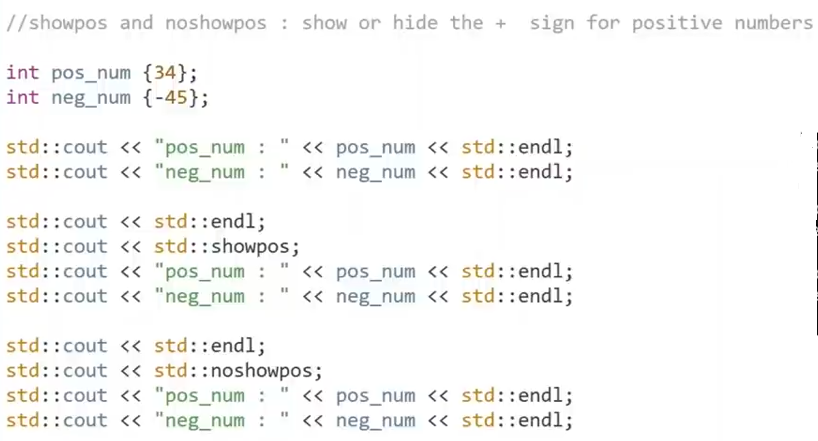
std::showpos
std::cout << std::showpos; ------show the + sign for positive numbers
std::cout << std::noshowpos;--------hide the + sign for positive numbers
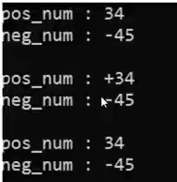
std::dec std::oct std::hex
used before integer
std::cout<<std::dec<<integer; -----show the integer in decimal
std::cout<<std::oct<<integer; -----show the integer in octal
std::cout<<std::hex<<integer; -----show the integer in hexadecimal

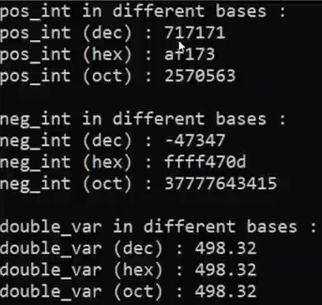
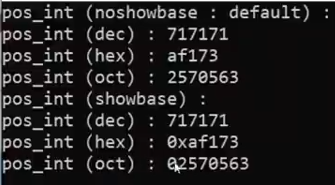
std::showbase
std::cout << std::showbase; ----------show the base(octal , decimal , hexadecimal) of integers
the base of decimal number is none
the base of octal number is 0 before octal nubmber
the base of hexadecimal number is 0x before hexadecimal nubmber

std::upperbase
std::cout << std::upperbase; --------data to be printed will be shown in uppercase(大写)
std::cout << std::noupperbase;------data to be printed will be shown in nouppercase

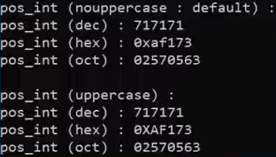
std::fixed
std::cout << std::fixed; --------force the output to be in fixed format

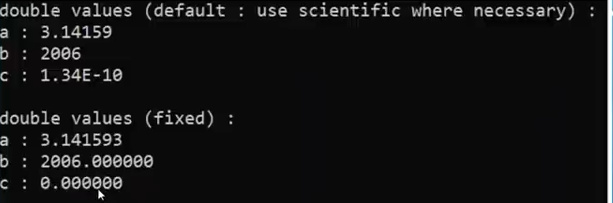
std::scientific
std::cout << std::scientific; --------data to be printed will be shown in scientific

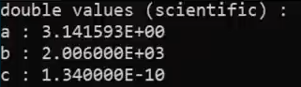
std::cout.unsetf(std::ios::scientific std::ios::fixed); ------back to defualts

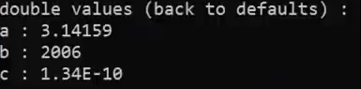
std::setprecision
std::cout << std::setprecision(n); -----the number of digits (n) printed out for a fractional number
n --means totally number of digits (include the number before and after the point)


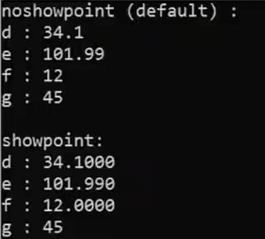
std::showpoint
std::cout << std::showpoint; -------force output showing the decimal point for a float
show trainling zero if necessary

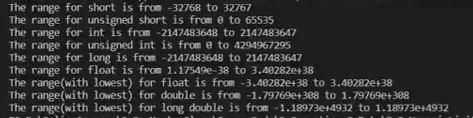
Numeric Limits function
library to be used
is helpful in getting a sense of what we can represent with a type of data

manuplators (functions)

T is a placeholder for the type for which you want to know the min max lowest
for floating point

for signed interger

for signed short interger
occupy two bytes

Math function

Standard library header <cmath> - cppreference.com

![]()






Weird integral types

ex:

char occupy 1 byte
short int occupy 2 bytes
if integer value is stored in char or short int , it can't do arithmetic operations
why?
has to do with processor design , the processor design choose int type for which they can do this arithmetic operation
the processor design choose int type
If two integer values is stored in chars , add them togther , it will become/be converted into int type

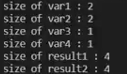
the result shows that it become int















 85
85











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









