






第一章 回归Regression
1.1线性回归
(1)选择模型:该例选择一元线性回归模型

(2)通过trianing set去训练w,b参数不同的这个模型,选择Loss funciton最小值最优当前最优模型。

w,b的参数更新通过梯度下降的方法更新。
(3)评估结果:
算出训练集的平均误差(average error on testing set)和测试集的平均误差(average error on testing set),得到训练集平均误差=31.9,测试集平均误差=35,得知测试效果并不好,如何去优化该模型?接下来我们选择加入一个二次项,构建出一个新模型。再用training data去训练,得到的效果如下:

可以看出,不管是测试集平均误差还是训练集平均误差,都变小了,模型更好,那有没有可能是更复杂的模型?接下俩我们加入三次项:

可以看出引入效果不大,再引入四次项:

通过模型结果可以看出模型更加糟糕了,再引入五次项:

结果更加糟糕!!!我们综合来看一下这五个模型:

随着模型复杂度的增加,确实能够使测试集的平均误差越来越低,但是会让训练集的平均误差先变低再变高。这种在训练集的平均误差低,在测试集的平均差高的情况就是overffting过拟合。
我们再来看如何优化?
可能选取多个函数分段拼接效果更好

重复步骤(1),选择模型:

效果如下:

如何更加优化?y的值可能与多种变量(特征)x有关,因此可以将一元线性回归模型改成多元线性回归模型:

可以看出,虽然训练集平均误差确实越来越低,但是测试集误差越来越高了,因此,出现了过拟合。
我们可以加入正则化Regularizition项,让函数更加平滑。


可以看出当λ越大(即正则项权重越大),测试集平均误差越小,但训练集平均误差变大
error的来源:variance+bias

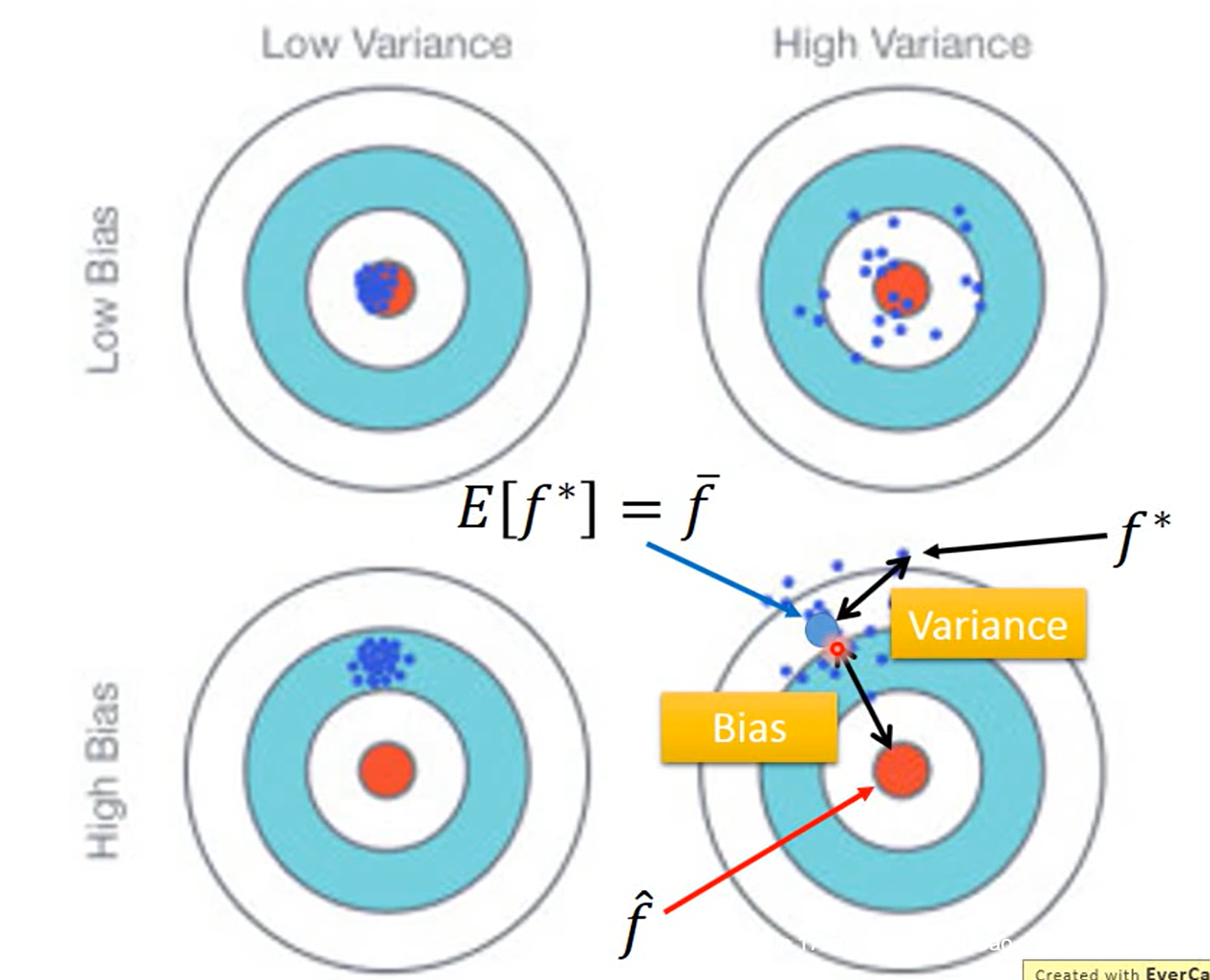
下图将训练集分成N个等分,每个等份训练一次,得到的综合结果如下:


简单的模型y被x影响的波动小
简单的模型variance小,复杂的模型variance大


如果模型连训练集都不能拟合,说明有大的bias,出现underfitting
如果模型能拟合训练集,但是不能拟合测试集,说明出现overffting
出现较大的variance怎么办?
①选择更多的数据 ②正则化
交叉验证(Cross Validation):在给定的建模样本中,拿出大部分样本进行建模型,留小部分样本用刚建好的模型进行预报,并求这一小部分样本的预报误差,记录它们的平方加和。


1.2梯度下降法
1.2.1梯度下降法的步骤
目标:通过梯度下降法求loss function取最小值时的参数b,w
计算步骤:
(1)随机取两个参数。

(2)计算偏导数,更新参数。


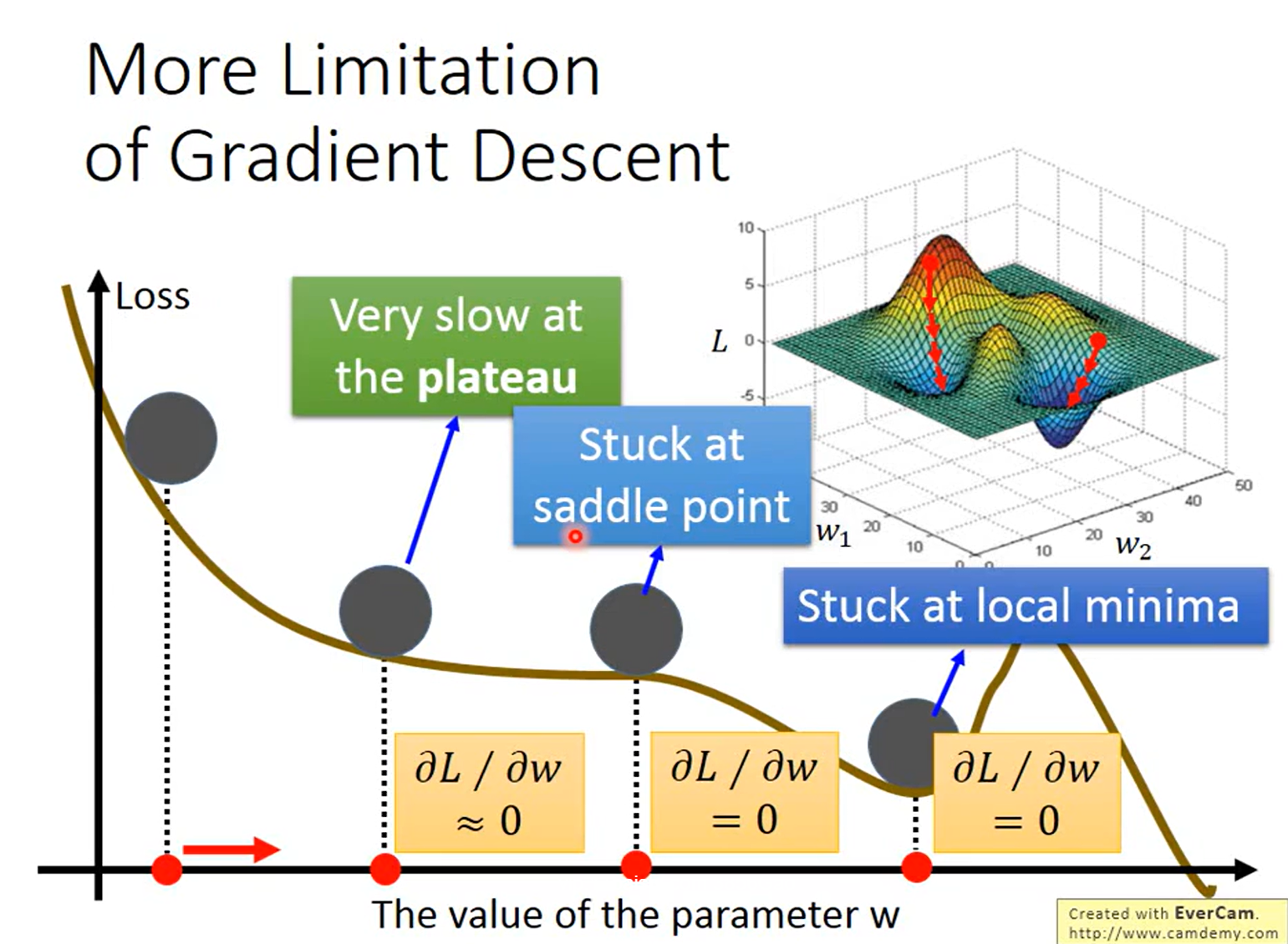
1.2.2梯度下降法的注意要点
(1)调整学习率
学习率调的太小走的会很慢,调的太大可能无法走到最低的地方

改进办法:Adaptive Learning Rates自适应学习率:让学习率以及更新权重动态更新
自适应学习率包括Adagrad、Adam等算法
Adagrad算法:
①学习率的更新:t当前总共更新次数

②权重的更新:Adagrad,每次更新都要考虑之前所有的梯度

①+②结合之后:

(2)每次更新取一些样本
Gradient Denscent:每一次更新要用到全部数据
Stochastic Gradient Denscent(随机梯度下降SGD):每一次更新取一些样本

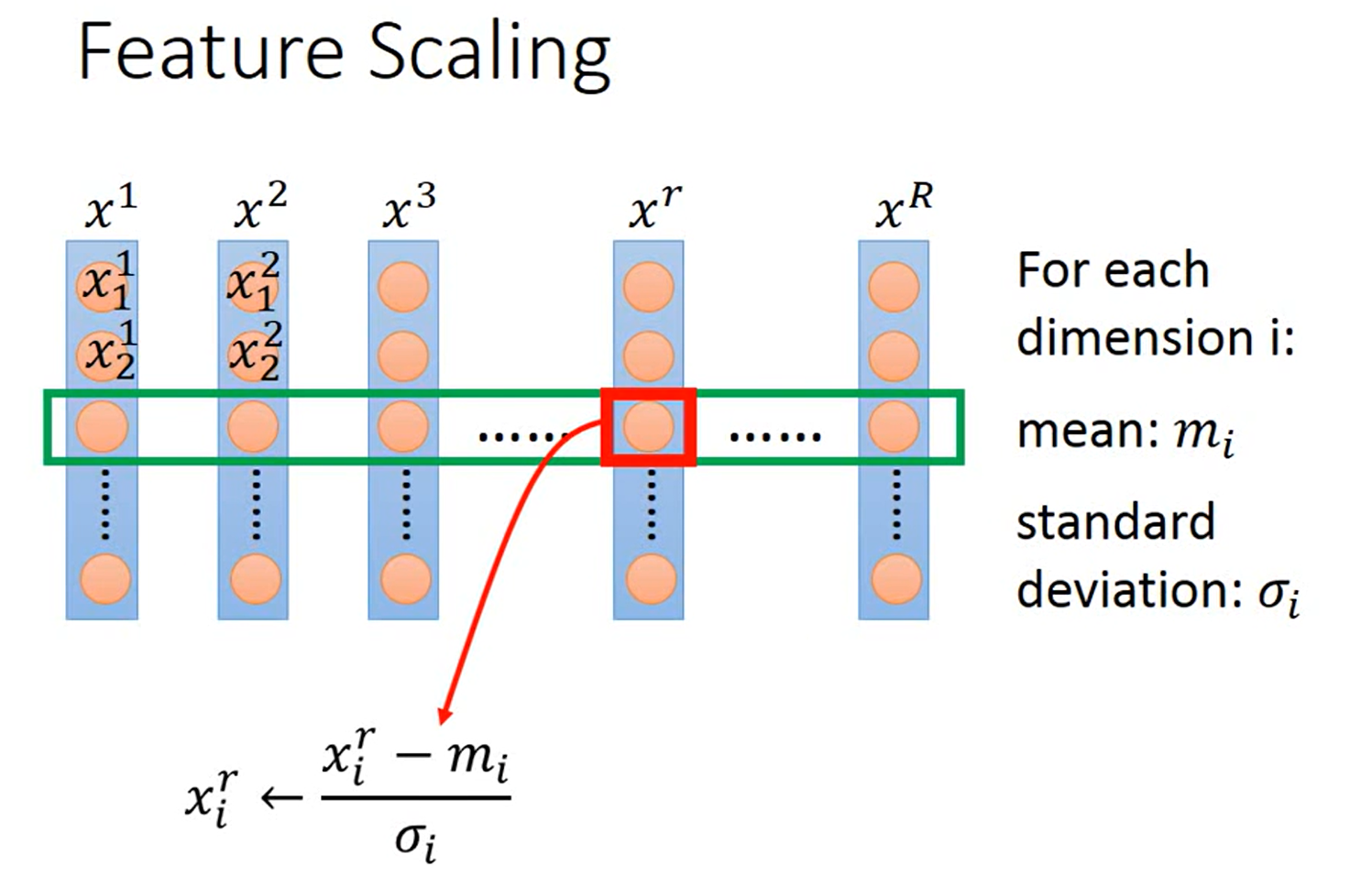
(3)Feature scaling特征缩放

方法:数据归一化、标准化
1.2.3New Optimization
梯度下降算法优化:
(1)SGD → SGD with Momentum(SGDM),即更新参数时考虑之前的参数。

(2)Adagrad → RMSProp

Adagrad缺陷:如果刚开始梯度很大的话,学习率太小会卡住,引入RMSProp

(3)Adam=SGDM+RMSProp
Adam训练出来的东西:

SGDM训练:

1.2.4 Adam VS SGDM
Adam训练的快但不稳,SDGM训练的慢但是稳

改进:用SWATS,即先用Adam训练,再用SGDM

如何改进Adam?2018年提出了AMSGrad、2019年提出了AdaBound


如何改进SGDM? 2017年提出LR range test、Cyclical LR、SGDR、One-cycle LR





1.2.5Adam需要warm-up吗?





第二章 分类Classification
2.1classification介绍
理论基础:正态分布(Normal distribution)=高斯分布(Gaussian distribution)


2.2Classfication步骤
(1)收集data

当做回归问题处理,以二分类为例子:目标值为1或-1

这样处理的缺陷是:

理想的做法是:

2.3生成式模型(generative model)
2.3.1理论基础

Generative Model P(x)


2.4 判别式模型(discriminative model)
生成式模型的输入:x带入sigmoid function
输出结果:p>0.5属于一个类别,p<0.5是一个类别




2.5多类别分类Muti-class Classification
2.6逻辑回归的局限

如上图,无法通过一条直线,将这两组数据分类
解决办法:通过多个logistic regression模型,最后ren


第三章 深度学习介绍
3.1深度学习发展


3.2Backpropagation
backpropagation要做的事:为了更有效率地计算梯度。
从本质上看,bp是一种快速求导的技术,想象一个拥有百万个输入和一个输出的函数。前向微分需要百万次遍历计算图才能得到最终的导数,而反向微分仅仅需要遍历一次就能得到所有的导数!速度极快!


3.3深度学习的几个tips
如果深度学习网络的training set表现得正确率不好该怎么办?


(1)Early Stopping(过早的暂停)
在训练集表现好,测试集表现不好。通过验证集确定最小的training set位置。

(2)Regularization(正则化)
重新定义了loss function,在loss function后面加入了正则项,分为L1正则项和L2正则项。


(3)Dropout
Dropout的应用场景是在testing set结果不好的时候使用该方法。

如何dropout?在训练时,做dropout;在测试时,不做dropout



(4)New activation function(选新的激活函数)
如果training set结果表现得不好,可以考虑更换激活函数,sigmoid函数值趋近于0或1时,ouput的变化很小,network越深,sigmoid函数越平滑,参数的改变对output的影响很小。
此时我们可以考虑将sigmoid函数换成ReLU函数,选择理由是:运算很快、能够处理梯度消失的问题


ReLU函数能够消除output为0的特征变量
(5)Adaptive Learning Rate
自适应更新学习率:随着情况的不同,学习率也不同。
①Adagrad:每一次更新w都考虑之前所有的梯度。

②RMSProp:当loss function变化平缓时,换用较大的学习率,当loss function变化陡峭时,换较小的学习率。

③Adam=RMSProp+Momentum

④SGDM随机梯度下降+Momentum:每次移动要考虑现在的梯度和前一个时间点的梯度,然后将两个梯度向量相加作为新的梯度下降方向。


3.4Why deep?

为什么横向增加神经元反而使训练误差变大?
因为deep能够共用data,训练的效果更好,而fat是将数据分为不同的部分,每个数据集只用一次,数据集的利用率太小。

长发男生的训练数据太少,采用modularization模块化后,可以训练更多的数据。(更有有效率地使用参数)

第四章 CNN
4.1为什么CNN用于图片处理?
一个图片像素100*100,每个像素点有三维,一张图片共三万维的数据,如果用1000个神经元训练,需要3000万次计算,计算量太大,因此CNN用于简化neural network,去掉不需要的特征。CNN的模型比DNN的模型更简单。
在分辨图片时,不需要用掉整张图片。因此每个神经元连接一小部分即可。

还可以通过subsampling将图片变小,但并不影响对图片的分辨,以减少需要的参数。

CNN处理流程:

4.2CNN-Convolution

Convolution VS Fully-connected

参数更少,convolution时的weight共享
4.3CNN-Max-Pooling
根据每个filter能得到一个matrix,选matrix的最大值即是Max-Pooling


一次卷积、池化之后,能得到一个小的image

如果CNN要处理彩色图片呢?

Filter分成三层,每层处理一个R、G或B

经过一次convolution以及一次pooling之后,能得到一个新的小的image

4.4Deep Dream&&Deep Style
Deep Dream:增强某部分特征


Deep Style:相同的内容,不同的形式

第五章 RNN
5.1 RNN(recurrent neural network)循环神经网络
RNN是根据人的认知是基于过往的经验和记忆这一观点提出的,与DNN、CNN它不仅考虑了前一时刻的输出,而且赋予了对前面网络内容的一种“记忆”功能。
RNN的训练也采用梯度下降法来更新权重,RNN因为有“记忆功能”,因此在NLP领域有着比较好的应用。
例子:判断Taipei属于Destiination,November 2nd属于time of arrival。

输入Taipei,输出Destination,可用通过0 of N encoding的方式将Taipei转换为数字向量。




这种有记忆功能的循环网络就是RNN。
下图是循环神经网络训练过程,注意,下面是一个神经元的三个不同时刻,而不是三个神经元。

5.2 LSTM(Long short-term Memory)
LSTM注重当前重要信息,现在一般都用LSTM二步用传统的RNN,因为LSTM能够消除gradient vanishing 的问题。


5.3RNN更多应用
(1)Many to one:输入一个vector sequence,输出一个vector

(2)Many to Many
输入和输出都是sequence,但是输出的sequence比较短
比如:语言辨识


机器翻译

(3)Attention-based Model
第六章 Semi-supervised learning
6.1半监督学习介绍
不带标签的数据集>>带标签的数据集
为什么需要半监督学习?因为能收集到的带有标签的数据集很有限。
第七章 Explainable ML
7.1可解释机器学习介绍
机器不仅给出图片的分类,机器还要解释分类的原因依据

local explaination

修改x,造成较大的y扰动,说明该x很重要

上图白色的亮度最大,表示越重要。
global explanation

第八章 Attack And Defence
8.1介绍
把machine learning用在日常生活中。
攻击要做的事:


攻击方法:

防御:
第九章 Transformer
9.1 Self-attention layer
CNN的缺陷在于不能基于过去的结果对当前结果修正,RNN的缺陷在于不能并行的计算,Self-attention layer相当于一个RNN中间层,但是它可以并行的计算。















 2426
2426











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









