






1、网络爬虫的简介:
什么是网络爬虫?
网络爬虫又(Web Crawler)称为网络蜘蛛(Web Spider)或Web信息采集器,按照特定的规则,自动抓取或下载网络资源的计算机程序或自动化脚本。
狭义上:通过利用标准协议,根据网络超链接和信息检索方法遍历网络数据的软件程序。
广义上:确定采取的URL队列获取每个URL对应的网页内容,根据需求解析网页中的字段并存储解析得到的数据。
2、网络爬虫的分类:
大致分为四类分别是通用网络爬虫、聚焦网络爬虫、增量网络爬虫、深度网络爬虫。
通用网络爬虫:也称为全网网络爬虫,顾名思义就是由部分的种子URL拓展到整个网络的全部页面。
聚焦网络爬虫:也称为主题网络爬虫,选择性地采集与主题相关的页面。
增量网页爬虫:对已经下载的网页进行增量式更新,避免重复采集数据。
深度网络爬虫:不能通过静态链接获取,需要提交表单才能获取。
3、网络爬虫的流程:
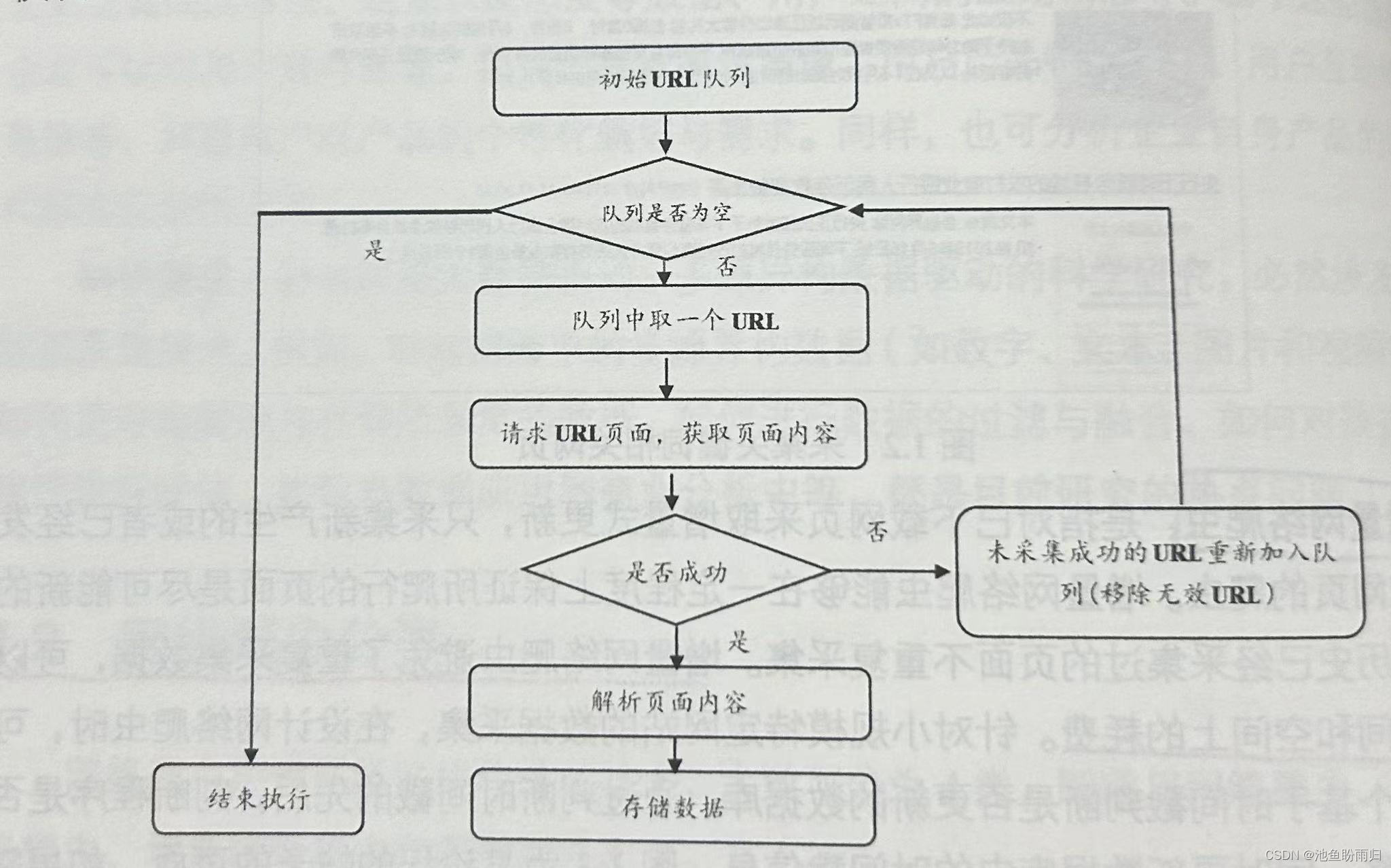
4、网络爬虫采集策略:
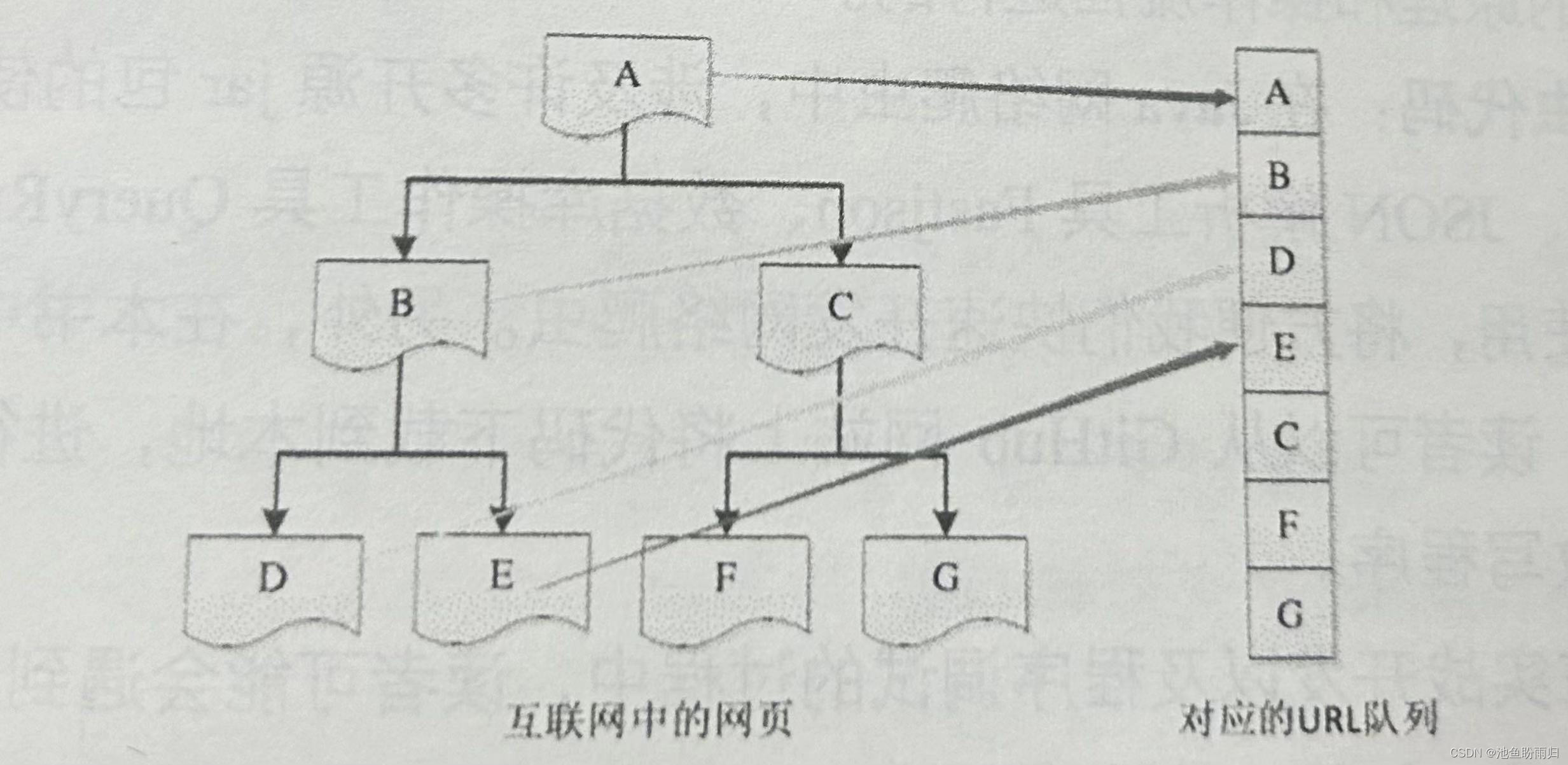
深度优先搜索策略:采用前序遍历(先左后右),根节点开始,向下遍历到对应的子节点,以该子节点为入口,继续向下遍历直到没有新子节点可以继续访问,回溯未被访问到的节点。
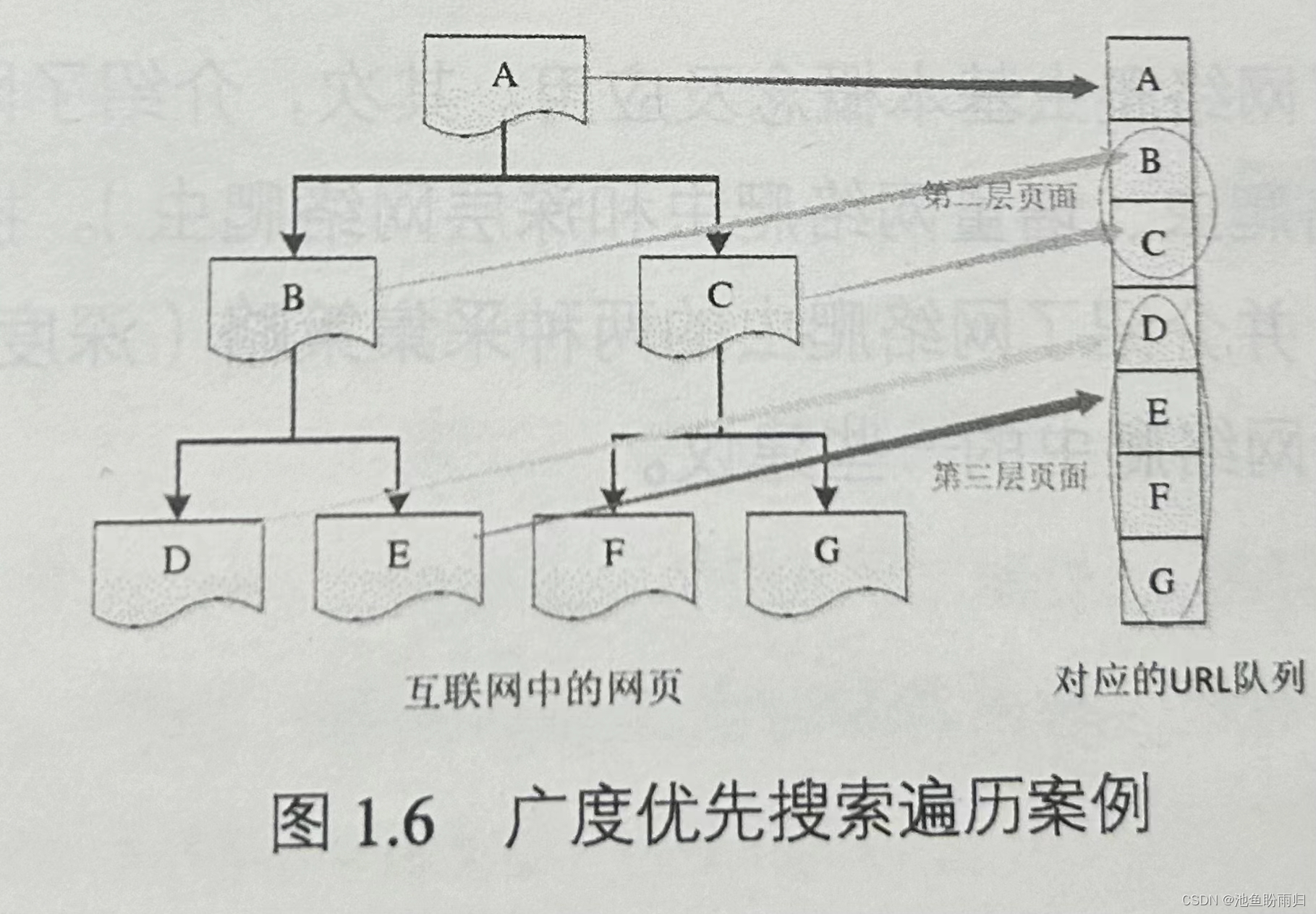
广度优先搜索策略:根节点开始,沿着网络的宽度遍历每层节点,所以节点均被访问,则终止程序。















 1478
1478











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









