







文章目录
摘要
在本文中,我们致力于探索更快、更准确的语义分割方法。提高性能的一种常见做法是获得具有强语义表示的高分辨率特征映射。两种策略被广泛使用:属性卷积和特征金字塔融合,但这两种策略要么计算量大,要么效率低下。受相邻视频帧之间运动对齐的光流的启发,我们提出了一个流对齐模块(Flow Alignment Module,FAM)来学习相邻级别特征映射之间的语义流,并有效地将高级别特征广播到高分辨率特征。此外,将我们的FAM集成到标准特征金字塔结构中,即使在ResNet-18和DFNet等轻量级骨干网络上,也比其他实时方法具有更好的性能。然后,为了进一步加快推理过程,我们还提出了一种新的门控双流对齐模块,用于直接对齐高分辨率特征图和低分辨率特征图,我们将改进的版本网络称为SFNet-Lite。在几个具有挑战性的数据集上进行了大量实验,结果表明SFNet(所有包含FAM但具有不同主干的网络)和SFNet- lite都是有效的。特别是,当使用cityscape测试集时,SFNet-Lite系列在使用ResNet-18骨干网时以60 FPS运行时达到80.1 mIoU,在RTX-3090上使用STDC骨干网时以120 FPS运行时达到78.8 mIoU。此外,我们将四个具有挑战性的驾驶数据集(即cityscape, Mapillary, IDD和BDD)统一为一个大型数据集,我们将其命名为统一驾驶分割(Unified Driving Segmentation,UDS)数据集。它包含不同的领域和样式信息。我们在UDS上对几个有代表性的作品进行了基准测试。SFNet和SFNet- lite仍然在UDS上实现了最佳的速度和精度权衡,这在这种具有挑战性的环境中可以作为一个强有力的基线。代码和模型可在https://github.com/ lxtGH/SFSegNets上公开获得。
1 介绍
语义分割是一项基本的视觉任务,其目的是对图像中的每个像素进行正确分类。它涉及许多现实世界的应用,包括自动驾驶、机器人导航和图像编辑。Long等人的开创性工作构建了一个深度全卷积网络(FCN),该网络主要由卷积层组成,以雕刻强语义表示。然而,由于使用下采样层,通常会丢失对性能至关重要的详细目标边界信息。
为了缓解这一问题,最先进的方法(17金字塔场景解析网络;18PSANET:用于场景解析的逐点空间注意网络;19场景分割的双注意网络;19通过视频传播和标签松弛改进语义分割;)在其网络的最后几个阶段应用属性卷积(16扩展卷积的多尺度上下文聚合),以产生具有强语义表示的特征图,同时保持高分辨率。同时,几种最先进的方法(18用于场景理解的统一感知解析;18基于可分离卷积的语义图像分割编解码器;GFF:门控完全融合语义分割;)采用多尺度特征表示来增强最终分割结果。最近,几种方法(21逐像素分类并不是语义分割所需要的全部;21Max-deeplab:端到端全光分割与掩模变压器;21用变形器从序列到序列的角度重新思考语义分割)采用视觉转换器架构,并将语义分割建模为逐段预测问题。特别是,由于更强的预训练模型(21Swin变压器:使用移位窗口的分层视觉变压器)和基于查询的掩码表示(20端到端目标检测与变压器),它们在长尾数据集(包括ADE-20k (16通过ADE20K数据集对场景进行语义理解)和COCOstuff (18Coco-stuff:上下文中的Thing和stuff类)上实现了更强的性能。
尽管这些方法在各种基准测试中取得了最先进的结果,但一个基本问题是实时推理速度,特别是对于高分辨率图像输入。考虑到使用ResNet-18 (16图像识别的深度残差学习)作为骨干网络的FCN对于1024 × 2048图像的帧率为57.2 FPS,在Zhao 等人(17金字塔场景解析网络;18PSANET:用于场景解析的逐点空间注意网络)对网络应用空洞卷积(atrous convolutions,dilated convolution,膨胀卷积,扩张卷积)(16扩展卷积的多尺度上下文聚合)后,修改后的网络帧率仅为8.7 FPS。此外,在没有其他正在进行的程序的单个GTX 1080Ti GPU下,以前最先进的模型PSPNet (17金字塔场景解析网络)对于1024 × 2048输入图像的帧率仅为1.6 FPS。因此,这对于许多先进的现实应用来说是有问题的,比如自动驾驶汽车和机器人导航,它们迫切需要实时在线数据处理。
为了既保持详细的分辨率信息,又获得表现出强语义表示的特征,另一个方向是构建类似FPN(Feature Pyramid Networks,特征金字塔网络)的特征(17特征金字塔网络用于目标检测;19Panoptic的特点是金字塔网络;15U-net:生物医学图像分割的卷积网络;)利用横向路径以自上而下的方式融合特征地图的模型。这样,最后几层的深层特征以高分辨率加强了浅层特征,因此,细化后的特征可以满足上述两个因素,有利于精度的提高。这种设计主要被实时语义分割模型所采用。然而,这些方法的准确性(15U-net:生物医学图像分割的卷积网络;17Segnet:用于图像分割的深度卷积编码器-解码器架构;19用于道路驾驶图像实时语义分割的预训练图像网络体系结构;22Pp-liteseg:一种卓越的实时语义分割模型;)与那些在最后几个阶段拥有大型特征地图的网络相比,仍然需要改进。是否有一个更好的解决方案,高精度和高速语义分割?我们怀疑低精度问题是由于语义从深层到浅层的无效传播引起的,在浅层中,语义在不同阶段之间没有很好地对齐。
为了缓解这个问题,我们建议明确学习不同分辨率的两个网络层之间的语义流(Semantic Flow)。语义流的灵感来自于光流,光流广泛用于视频处理任务(17用于视频识别的深度特征流;),用于表示视觉场景中由相对运动引起的物体、表面和边缘的表观运动模式。灵光一闪,我们发现来自同一图像的任意分辨率的两个特征映射之间的关系也可以用每个像素从一个特征映射到另一个特征映射的“运动”来表示。在这种情况下,一旦获得精确的语义流,网络就能够以最小的信息损失传播语义特征。需要注意的是,语义流和光流不同,语义流将不同层次的特征图作为输入,并评估它们之间的差异,以找到合适的流场,该流场将动态指示如何有效地对齐这两个特征图。
基于语义流的概念,我们设计了一种新的网络模块——流对齐模块(Flow Alignment module, FAM)来利用语义流进行语义分割。FAM后的特征图具有丰富的语义和丰富的空间信息。由于FAM可以通过基本运算有效地将语义信息从深层传递到浅层,因此在提高精度和保持较高效率方面表现出优异的效果。此外,FAM是端到端可训练的,可以插入任何骨干网络,以较小的计算开销改善结果。为简单起见,我们将所有包含FAM但具有不同主干的网络称为SFNet。如图1所示,在相同的速度下,具有不同骨干网的SFNets的性能大大优于竞争对手。特别是我们采用ResNet18作为主干的方法,在cityscape测试服务器上实现了79.8%的mIoU,帧率为33 FPS。当采用DF2 (19Partial order pruning(偏序剪枝):在神经结构搜索中获得最佳的速度/精度权衡;)作为骨干网时,我们的方法在配备DF1骨干网时达到77.8%的mIoU和103 FPS,达到74.5%的mIoU和134 FPS (19Partial order pruning(偏序剪枝):在神经结构搜索中获得最佳的速度/精度权衡)。结果如**图1(绿色节点)**所示。
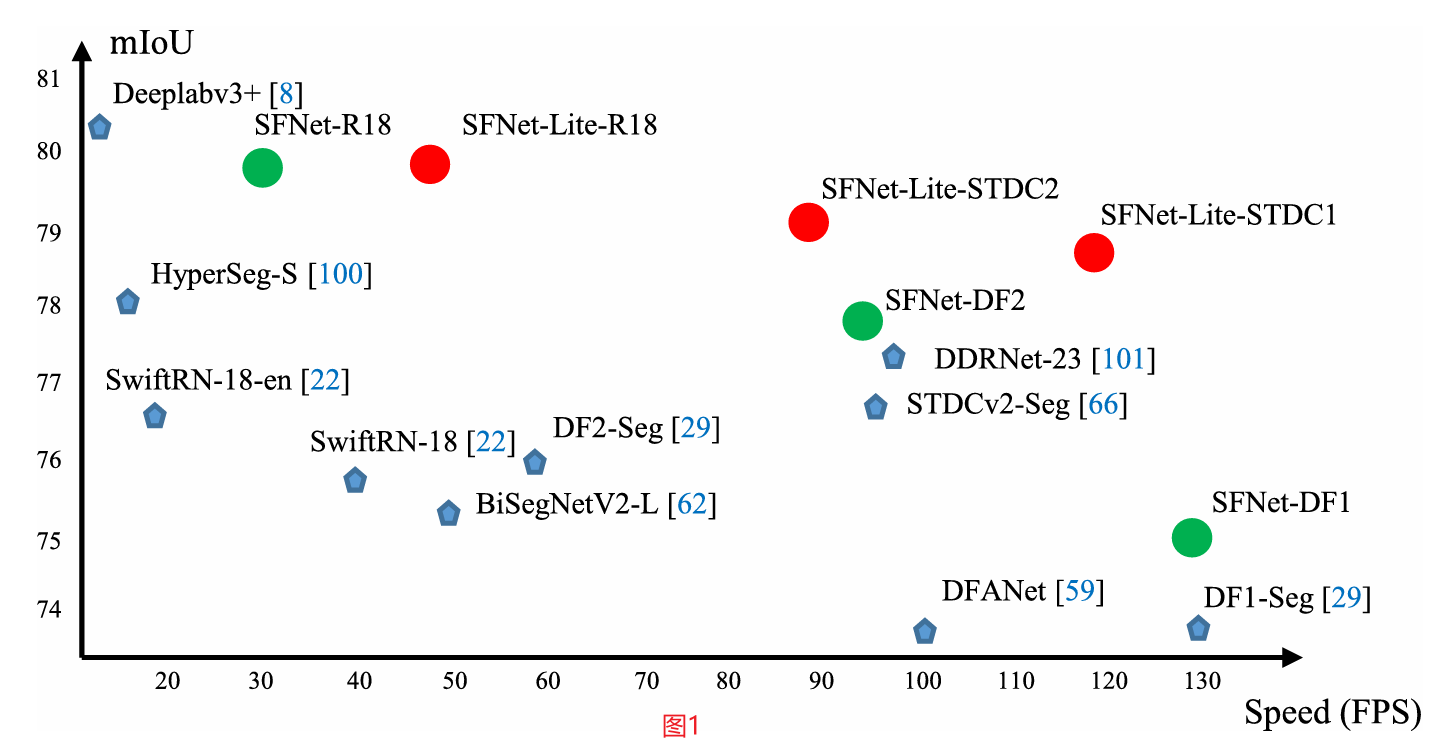
图1在cityscape测试集上推理速度与mIoU性能的关系。以前的模型被标记为蓝色点,我们的模型被显示为红色和绿色点,达到了最佳的速度/精度权衡。请注意,我们以ResNet-18为主干的方法甚至以更快的速度实现了与所有精确模型相当的精度。SFNet方法为绿色节点,SFNet- lite方法为红色节点(在线色图)
最初的SFNet (20语义流用于快速和准确的场景解析;)在速度和精度权衡上取得了令人满意的结果,随后的几部作品(21FAPN:用于密集图像预测的特征重新排列金字塔网络;)将SFNet的思想推广到其他领域。然而,由于涉及到多阶段的特征,SFNet的推理速度仍然需要更快。为了加快SFNet的速度,同时保持准确性,我们提出了一个新的SFNet版本,命名为SFNet-Lite。我们特别设计了一种新的流对齐模块,称为门控双流对齐模块(Gated Dual Flow Aligned Module,GD-FAM)。继FAM之后,GD-FAM以两个特征作为输入,学习两个语义流,同时细化高分辨率和低分辨率特征。同时,我们还生成了一个共享门映射来动态控制最终添加前的流翘曲处理。新提出的GD-FAM只需在SFNet骨干网末端追加一次,直接细化最高和最低分辨率特征。这种设计避免了多尺度特征融合,大大提高了SFNet的速度。此外,为了保持原始数据的准确性,我们通过引入更平衡的数据集训练,对cityscape进行了广泛的实验(19通过视频传播和标签松弛改进语义分割;)。因此,我们的带有ResNet18主干的SFNet- lite在cityscape测试集上达到了80.1 %mIoU,但速度为49 FPS(比原始SFNet提高了16 FPS,性能略好(20语义流用于快速和准确的场景解析;)。此外,当采用STDCv1骨干网时,我们的方法可以达到78.7% mIoU,运行速度为120 FPS。结果如**图1(红色节点)**所示。
由于各种驾驶数据集(20Bdd100k:异构多任务学习的多元驱动数据集;19IDD:一个用于探索无约束环境下自主导航问题的数据集;16用于语义城市场景理解的城市景观数据集;)来自不同的领域,以往的实时语义分割方法在不同的数据集上训练不同的模型,导致训练出的模型对训练域很敏感,不能很好地泛化到未知领域(21鲁棒网络Robustnet:通过实例选择性白化提高城市场景分割的领域泛化;)。最近,M-Seg提出了一种用于多数据集语义的混合数据集,以实现多数据集训练和测试的一个模型。综上所述,我们验证了SFNet系列在统一的数据集基准测试中是否更有效。首先,我们在各种驾驶数据集上对SFNet和SFNet- lite进行基准测试(20Bdd100k:异构多任务学习的多元驱动数据集;17用于街景语义理解的mapillary远景数据集;19IDD:一个用于探索无约束环境下自主导航问题的数据集;)在实验部分。其次,我们通过混合四个具有挑战性的驾驶数据集,包括cityscape, Mapillary, BDD和IDD,创建了一个具有挑战性的基准。我们将合并的数据集称为统一驱动分割(UDS)。如图2所示,我们的目标是训练一个统一的模型,对各种场景进行语义分割。据我们所知,UDS是针对驾驶场景的最大的公共语义分割数据集。特别是,我们提取了由cityscape和BDD定义的具有19个类标签的典型语义类,并在Mapillary中合并了几个类。我们进一步对我们的UDS上的代表性作品进行基准测试。我们的SFNet还实现了最佳的准确率和速度权衡,这表明了语义流的泛化能力。特别是,使用DFNet (19偏序剪枝:在神经结构搜索中获得最佳的速度/精度权衡;)作为骨干,我们的SFNet和SFNet- lite在UDS上实现了7%—9%的mIoU改进。这表明我们提出的FAM和GD-FAM在多数据集训练中更加实用。
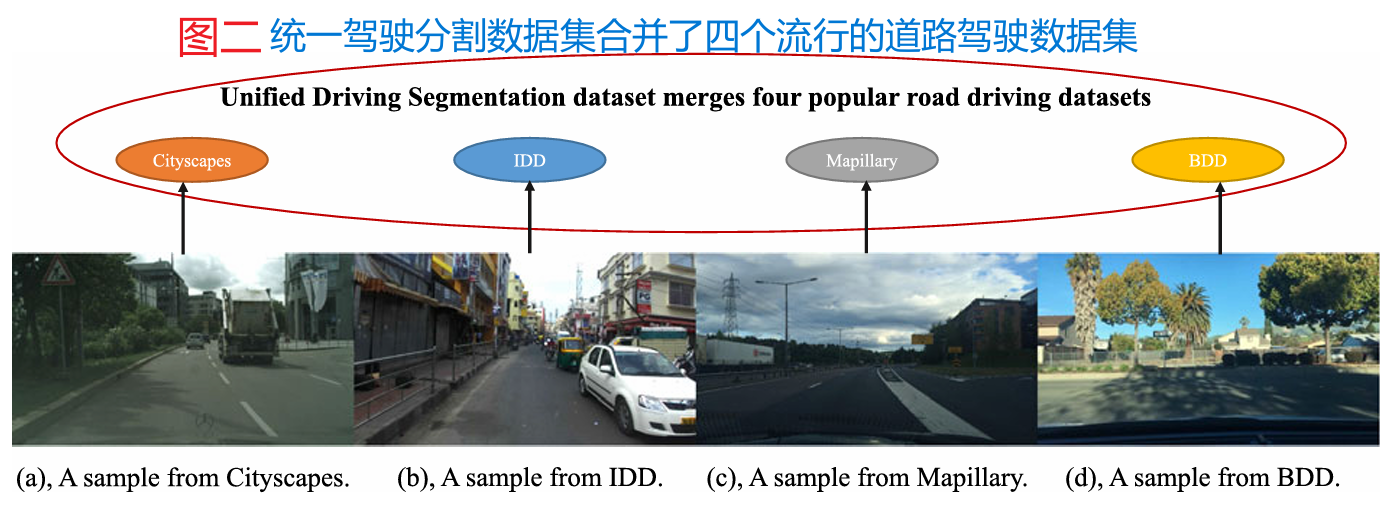
图2:合并后的统一驾驶分割(UDS)基准图。它包含四个数据集,包括城市景观(16用于语义城市场景理解的城市景观数据集;)a、IDD (19IDD:一个用于探索无约束环境下自主导航问题的数据集;)b、Mapillary (17用于街景语义理解的mapillary远景数据集;)c和BDD (20Bdd100k:异构多任务学习的多元驱动数据集;)d。这些数据集具有不同的样式和纹理信息,这使得合并后的UDS数据集更具挑战性
综上所述,Li等人(20语义流用于快速和准确的场景解析;)发表了这项工作的初步版本。在本文中,我们做了以下重要的扩展:
- (1)我们引入了一个新的流量对准模块(GD-FAM)来提高SFNet的速度,同时保持原有的性能。实验表明,新设计的推理效率始终优于原有的推理模块。
- (2)我们进行了更全面的消融研究来验证所提出的方法,包括对基线的定量改进和可视化分析。
- (3)我们将SFNet扩展到全景分割中,在三个强大的基线上实现了1.0% - 1.5%的PQ改进。
- (4)我们进一步在两个更具挑战性的数据集上对SFNet和几种最近的代表性方法进行基准测试,包括Mapillary (17用于街景语义理解的mapillary远景数据集;)和IDD (19IDD:一个用于探索无约束环境下自主导航问题的数据集;)。我们的SFNet系列在不同的基线上显著提高,并实现了最佳的速度和精度权衡。特别是,我们提出了一种新的设置,通过合并现有的驾驶数据集(UDS)来训练统一的实时语义分割模型。我们的SFNet系列还实现了最佳的准确性和速度权衡,这可以成为混合驾驶分割的坚实基线。在ADE20k数据集上进一步证明了SFNet和SFNet- lite在变压器架构上的有效性。此外,在RobustNet的帮助下(21鲁棒网络Robustnet:通过实例选择性白化提高城市场景分割的领域泛化;),我们进一步证明了SFNet在域泛化设置方面的有效性。
2 相关工作
通用语义分割
目前最先进的语义分割方法是基于FCN框架的,该框架将语义分割视为密集像素分类问题。许多方法侧重于扩展主干的全局上下文建模。Liu等人(15Parsenet:看得更宽才能看得更清楚;)将全球平均池化特征连接到现有的特征映射中。在PSPNet (17金字塔场景解析网络;)中,包括全局平均池化在内的多个窗口大小的平均池化特征被上采样到相同的大小并连接在一起,以丰富全局信息。DeepLab变体(15基于深度卷积网络和全连接CDF的语义图像分割;17语义图像分割中属性卷积的再思考;18基于可分离卷积的语义图像分割编解码器;)提出了空洞或扩张卷积和空间金字塔池(atrous spatial pyramid pooling,ASPP)来增加有效接受场。DenseASPP (18DenseASPP用于街景的语义分割;)在Chen等人(18DeepLab:语义图像分割与深度卷积网络,空洞卷积,和完全连接的crfs;)的基础上进行了改进,以不同的扩张率密集连接卷积层,进一步增加网络的接受野。除了将全局信息拼接到特征图中,将全局信息相乘到特征图中也表现出更好的性能(18语义分割的上下文编码;18CBAM:卷积块注意模块;18紧致广义非局部网络;)。此外,有几部作品采用了自注意力(self-attention)设计来编码场景的全局信息。使用非本地算子(18非局部神经网络;), Yuan和Wang(21OCNET:用于场景解析的对象上下文网络;)取得了令人印象深刻的结果;Zhang等(19语义分割中的共现特征;);Jun 等人(19场景分割的双注意网络;)。CCNet (19CCNe:语义分割的交叉关注;)通过循环的方式考虑其周围像素在交叉路径上的长期依赖关系,以节省计算和内存成本。同时,几部作品(15U-net:生物医学图像分割的卷积网络;2018用于场景理解的统一感知解析;19Panoptic的特点是金字塔网络;21Pointflow:通过航拍图像分割点的流动语义;21增强了玻璃样物体分割的边界学习;)采用编解码器架构学习多层次特征表示。RefineNet (17Refinenet:用于高分辨率语义分割的多路径细化网络;)和DFN (18学习语义分割的判别特征网络;)采用了融合低层和高层信息的编解码器结构,得到密集的预测结果。遵循这样的架构设计,GFFNet (20GFF:门控完全融合语义分割;)、CCLNet (18背景对比特征和门控多尺度聚合用于场景分割;)和G-SCNN (19gate -scnn:用于语义分割的门控形状CNN;)使用门进行特征融合,以避免噪声和特征冗余。AlignSeg (21Alignseg:特征对齐分割网络;)提出通过自下而上的设计来细化多尺度特征。IFA (22学习语义分割的隐式特征对齐函数;)提出了一种隐式特征对齐函数来改进多尺度特征表示。相比之下,我们的方法是自顶向下传递语义信息,注重实时应用。然而,这些工作中只有一部分可以实时进行推理,这使得在实际应用中很难应用。
基于Vision Transformer的语义分割
最近,基于transformer的方法(21一张图像值16×16 words:用于大规模图像识别的变形金刚;21Swin transformer:使用移位窗口的分层视觉变压器;21用transformer从序列到序列的角度重新思考语义分割;22Polyphonicformer:用于深度感知视频全景分割的统一查询学习;)用视觉transformer代替CNN主干,获得了更加鲁棒的结果。几部作品(21Swin transformer:使用移位窗口的分层视觉变压器;21用transformer从序列到序列的角度重新思考语义分割;21Segformer:简单有效的语义分割设计与变压器;21Segmenter:用于语义分割的转换器)表明,vision transformer backbone在长尾数据集上的效果更好,因为它具有更好的特征表示和更强的ImageNet分类预训练(pre-training)。SETR (21用transformer从序列到序列的角度重新思考语义分割;)用基于标记的建模取代了像素级建模,而Segformer (21Segformer:简单有效的语义分割设计与变压器;)提出了一种新的高效分割主干。此外,几部作品(21Max-deeplab:端到端全光分割与掩模变压器;21逐像素分类并不是语义分割所需要的全部;21K-net:迈向统一的图像分割;)采用检测变压器(Detection Transformer ,DETR) (20端到端目标检测与变压器;)将逐像素预测视为准掩膜预测。特别是,Maskformer (21逐像素分类并不是语义分割所需要的全部;)将像素级密集预测视为集合预测问题。然而,由于计算成本巨大,这些工作仍然无法实时进行推理。
快速语义分割
快速(实时)语义分割算法在需要快速推理和响应的实际应用中受到关注。有几件作品是为这种环境而设计的。ICNet(images cascade network,图片级联网络) (18用于高分辨率图像的实时语义分割;)使用多尺度图像作为输入,并使用级联网络来提高效率。DFANet (19Dfanet:实时语义分割的深度特征聚合;)利用轻量级主干来加速其网络,并提出跨层特征聚合来提高准确性,而SwiftNet (19用于道路驾驶图像实时语义分割的预训练图像网络体系结构;)使用横向连接作为经济有效的解决方案,在保持速度的同时恢复预测分辨率。ICNet 将高分辨率特征降低到不同尺度,以加快推理时间。ESPNets (18Espnet:扩展卷积的高效空间金字塔语义分割;19Espnetv2:一个轻量级、高效、通用的卷积神经网络;)通过将标准卷积分解为逐点卷积和空间金字塔卷积来节省计算量。BiSeNets (18Bisenet:用于实时语义分割的双边分割网络;21Bisenet v2:带引导聚合的双边网络,用于实时语义分割;)引入空间路径和语义路径来减少计算量。最近,几种方法(19基于辅助单元的紧凑语义分割模型快速神经结构搜索;语义分割中的共现特征;19偏序剪枝:在神经结构搜索中获得最佳的速度/精度权衡;)使用AutoML(Automated Machine Learning,自动化机器学习)技术来搜索高效的场景解析架构。此外,还有几部作品(21对双元组实时语义分割的再思考;19基于多重空间融合网络的实时语义分割;)使用多分支架构来改善实时分割结果。然而,与cityscape (16用于语义城市场景理解的城市景观数据集;)和Mapillary (17用于街景语义理解的mapillary远景数据集)等多个基准上的一般方法相比,这些工作导致了较差的分割结果。我们之前的工作SFNet (语义流用于快速和准确的场景解析)在实时运行时通过学习多尺度特征之间的语义流实现了高精度。然而,由于涉及的特征较多,其推理速度仍然有限。此外,需要通过更强的数据增强和预训练来更好地探索多尺度特征的能力。因此,同时实现高速和高精度仍然具有挑战性,对实时应用具有重要意义。
全景分割
早期作品(Kirillov et al, 2019;Li et al ., 2019;Chen et al ., 2020;Porzi et al, 2019;Yang et al ., 2020)提出在一个具有不同任务头的模型中对stuff分割和thing分割进行建模。基于检测的方法(Xiong et al ., 2019;Kirillov et al, 2019;乔等,2021;Hou et al, 2020)通常用框式预测来表示事物,而一些自下而上的模型(Cheng et al, 2020;Wang等人,2020)通过语义分割结果的像素级亲和力或中心热图执行分组实例。前者引入了复杂的过程,而后者在复杂的场景下会导致性能下降。近期,几部作品(Wang et al, 2021;Zhang等,2021;Cheng等,2021)提出直接获取分割掩码,不需要盒子监督。然而,所有这些工作都忽略了速度问题。在实验中,我们进一步证明了我们的方法也可以得到更好的全视分割结果。
轻量级架构设计
另一个重要的研究方向是通过各种方法为下游任务设计更高效的主干(Howard等人,2017;Sandler等人,2018;Ma等人,2018;Fan et al, 2021)。这些方法侧重于利用各种网络搜索方法进行高效的表示学习。我们的工作与那些工作是正交的,因为我们的目标是设计一个轻量级和对齐的分割头。
Multi-dataset分割
MSeg (Lambert et al ., 2020)首先提出将大多数现有数据集合并到一个统一的分类中,并针对不同的场景训练统一的分割模型。同时,以下几部作品(Zhou et al ., 2022;Li et al ., 2022)探索多数据集分割或检测。与MSeg相比,我们的UDS数据集主要集中在驾驶场景,只有19个类,而MSeg有100多个类。输入图像是高分辨率的,用于自动驾驶应用。
分割中的领域泛化
目标域泛化(DG) (Wang et al ., 2022)方法假设模型在训练过程中无法进入目标域,旨在提高模型在未知目标域的泛化能力。DG与多数据分割略有不同。在分割方面,几部作品(Pan et al ., 2018;Yue等人,2019;Kim et al, 2022;Choi et al ., 2021)采用GTAV等合成数据进行训练,采用城市景观等真实数据进行测试。最近,RobustNet (Choi等人,2021)解开了高阶统计编码的领域特定样式和领域不变内容。通过结合RobustNet (Choi等人,2021),我们的方法也可以应用于DG分割设置,我们也发现了各种基线的显着改进。
3 方法
在本节中,我们将首先提供一些关于实时语义分割的初步知识,并介绍其中的不对齐问题。然后,我们提出了Flow Alignment Module (FAM),通过学习语义流和相应的翘曲顶层特征映射来解决不对齐问题。本文还介绍了SFNet的设计。接下来,我们介绍了SFNet- lite和改进的GD-FAM,以提高SFNet的速度。最后,我们描述了我们的UDS数据集的构建过程和SFNet-Lite训练的几个改进细节。
3.1 初步

图片解释:场景解析的任务是将RGB图像X∈RH×W×3映射到具有相同空间分辨率H×W的语义地图Y∈RH×W×C,其中C为预定义语义类别的数量。在FPN设置之后(Lin et al, 2017),首先将输入图像X映射到一组特征映射{Fl}l=2,…5,每个网络阶段,其中Fl∈RHl×Wl×Cl是在大小为Hl×Wl, Hl = H /2l, Wl = W /2l的空间网格Ωl上定义的cl维特征图。
最粗糙的特征图F5来自具有最强语义的最深层。FCN - 32s直接对F5进行预测,在没有精细细节的情况下获得过度平滑的结果。然而,通过融合来自较低水平的预测可以实现一些改进(Long et al, 2015)。FPN进一步通过2x双线性上采样,在自上而下的路径中逐渐融合高级特征映射和低级特征映射,该上采样最初是用于目标检测(Lin等人,2017),最近被引入场景解析(Xiao等人,2018;Kirillov et al, 2019)。整个FPN框架高度依赖上采样算子对空间较小但语义较强的特征映射进行上采样,使其空间尺寸更大。然而,双线性上采样通过插值一组均匀采样的位置来恢复下采样特征图的分辨率(即只能处理一种固定的和预定义的不对齐),而残差连接、重复的下采样和上采样操作导致的特征图之间的不对齐则要复杂得多。因此,需要明确地、动态地建立特征映射之间的位置对应关系,以解决它们之间的实际不对齐问题。
3.2 原始流对齐模块和SFNet
设计动机
为了更加灵活和动态的对齐,我们深入研究了光流的思想,它在视频处理任务中非常有效和灵活地对齐两个相邻的视频帧特征(Brox等,2004;Zhu et al ., 2017)。光流的思想促使我们设计一个基于流的对齐模块(FAM),通过预测网络内部的流场来对齐两个相邻层的特征图。我们将这种流场定义为语义流,它是在特征金字塔的不同层次之间产生的。
模块的细节
FAM是使用FPN框架构建的,其中包括在将其传递到下一层之前,使用两个1×1卷积层将每个层的特征映射压缩到相同的通道深度。给定两个相邻的特征映射Fl和Fl−1具有相同的通道数,我们通过双线性插值层将Fl上采样到与Fl−1相同的大小。然后,我们将它们连接在一起,并将连接的特征映射作为包含两个卷积层的子网络的输入,内核大小为3 × 3。

图片解释:子网的输出是对语义流场的预测Δl−1∈RHl−1×Wl−1×2。数学上,上述步骤可以写成如上图的公式;其中cat(·)表示连接操作,convl(·)表示3 × 3卷积层。
由于我们的网络采用了跨行卷积(strided convolutions),这可能会导致非常低的分辨率,在大多数情况下,3×3卷积足以覆盖该特征映射(feature map,特征图)中的大多数大型对象。请注意,我们抛弃了FlowNet-C中提出的相关层(Dosovitskiy等人,2015),其中明确计算了位置对应。由于高层和低层之间存在巨大的语义差距,对这些特征进行显式对应计算比较困难,往往无法进行偏移量预测。此外,包括一个相关层来解决这个问题将大大增加计算成本,这与我们开发一个快速准确的网络的目标相矛盾。

图片解释:在计算完Δl−1之后,通过简单的加法运算,将空间网格Ωl−1上的每个位置pl−1映射到上层l上的一个点pl。由于特征与流场之间存在如图4b所示的分辨率差距,因此翘曲网格及其偏移量应减半,如式2所示:
然后,我们使用空间变压器网络中提出的可微双线性采样机制(differentiable bi-linear sampling mechanism)(Jaderberg等人,2015),该机制线性插值pl的4个领域(左上、右上、左下和右下)的值,以近似FAM的最终输出,表示为Fl(pl−1)。数学上,
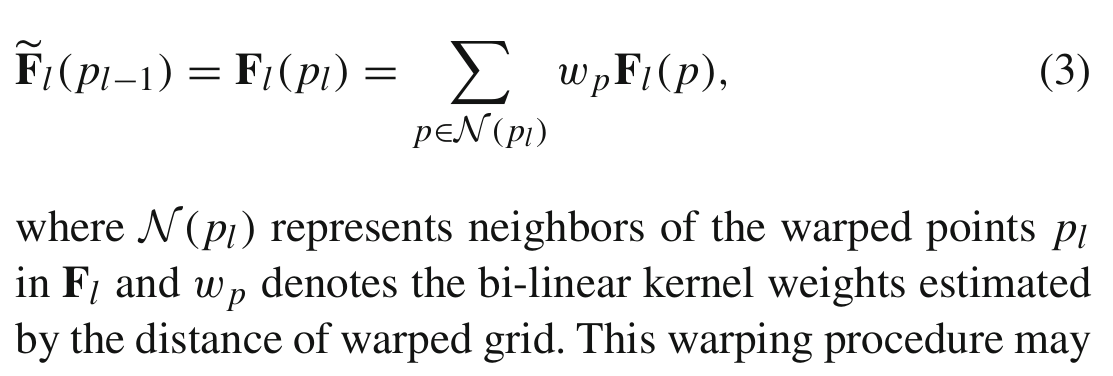
其中N (pl)表示Fl中弯曲点pl的四个邻域,wp表示弯曲网格距离估计的双线性核权值。
这种翘曲过程可能看起来类似于可变形卷积网络(DCN)中可变形核的卷积操作(Dai et al ., 2017)。然而,我们的方法与DCN有很多明显的区别。首先,我们的预测偏移域结合了高级和低级特征来对齐高级和低级特征映射之间的位置,而DCN的偏移域根据预测的位置偏移移动核的位置,从而拥有更大和更自适应的各自域。其次,我们的模块专注于对齐特征,而DCN更像是一种关注对象突出部分的注意机制。在实验部分可以找到更详细的对比。
总的来说,所提出的FAM模块是轻量级的,端到端可训练的,因为它只包含一个3×3卷积层和一个无参数的翘曲操作。除了这些优点之外,它还可以多次插入网络,而只需要很少的额外计算开销。图4a给出了所提出模块的详细设置,图4b给出了翘曲过程。图3可视化了两个相邻级别的特征图,它们学习到的语义流和最终扭曲的特征图。如图3所示,扭曲的特征在结构上比正常的双线性上采样特征更整洁,并导致对物体(如公交车和汽车)的更一致的表示。
图4c展示了整个网络架构,其中包含一个自底向上的路径作为编码器,一个自顶向下的路径作为解码器。虽然编码器具有提供不同级别特征表示的骨干网络,但解码器可以被视为配备了几个FAM的FPN。
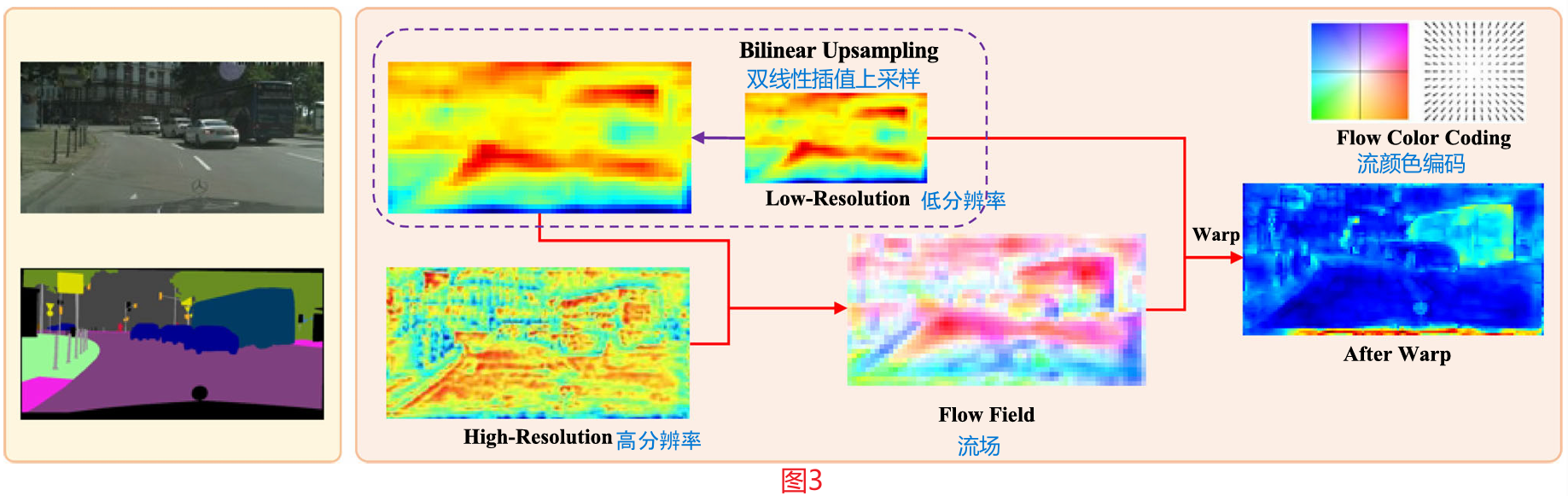
图3 FAM中特征图和语义流场的可视化。特征映射是通过沿通道维度平均来可视化的。较大的值用热颜色表示,反之亦然。我们使用Baker等人(2011)提出的颜色代码来可视化语义流场。流矢量的方向和大小分别用色相和饱和度表示。如图所示,使用我们提出的语义流可以得到更结构化的特征表示。
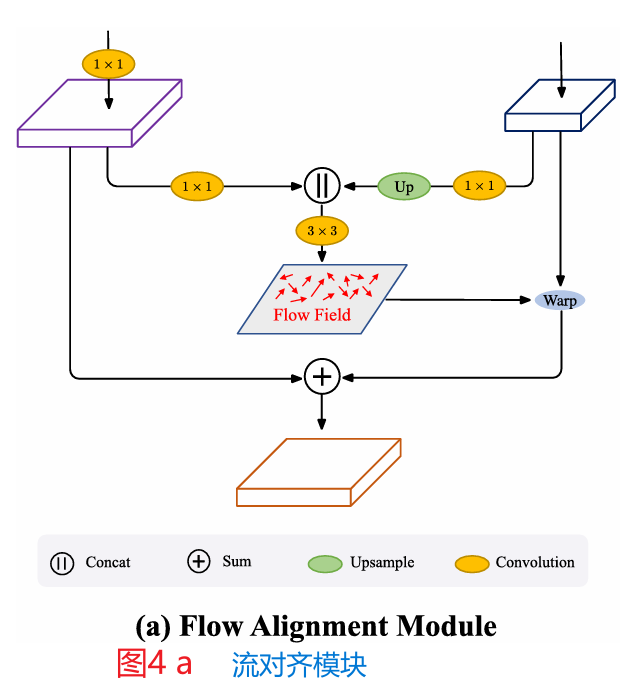
图4a 流量对准模块详细图。将变换后的高分辨率特征图与低分辨率特征图结合生成语义流场,利用语义流场将低分辨率特征图变形为高分辨率特征图。
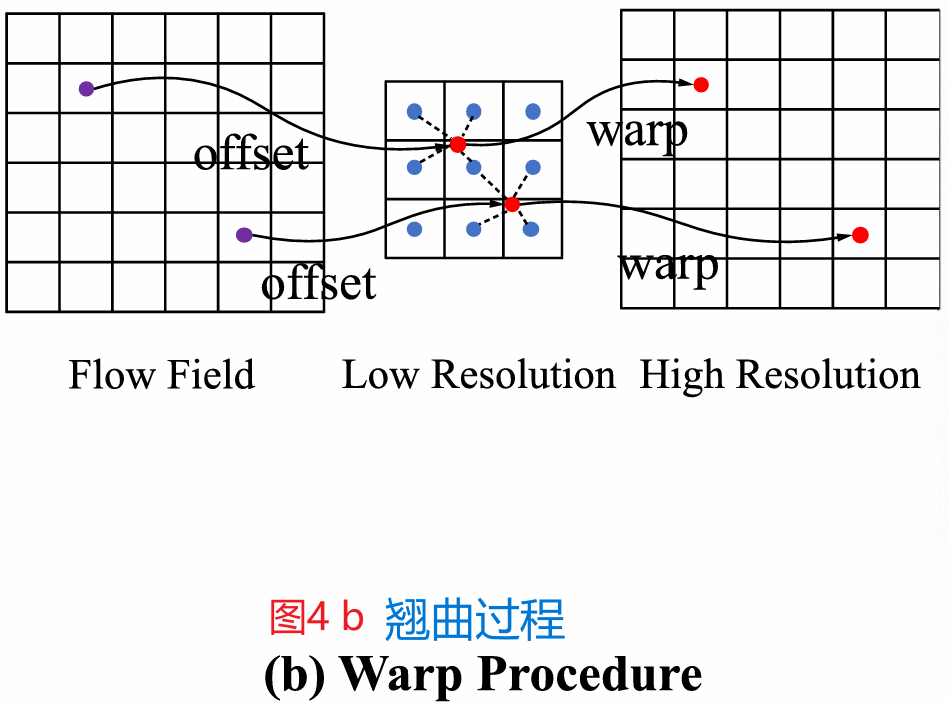
图4 b流动对齐模块的翘曲过程。高分辨率特征图的值是对低分辨率特征图中相邻像素的双线性插值,其中邻域是根据学习到的语义流场定义的。
图4 b流动对齐模块的翘曲过程。高分辨率特征图的值是对低分辨率特征图中相邻像素的双线性插值,其中邻域是根据学习到的语义流场定义的。
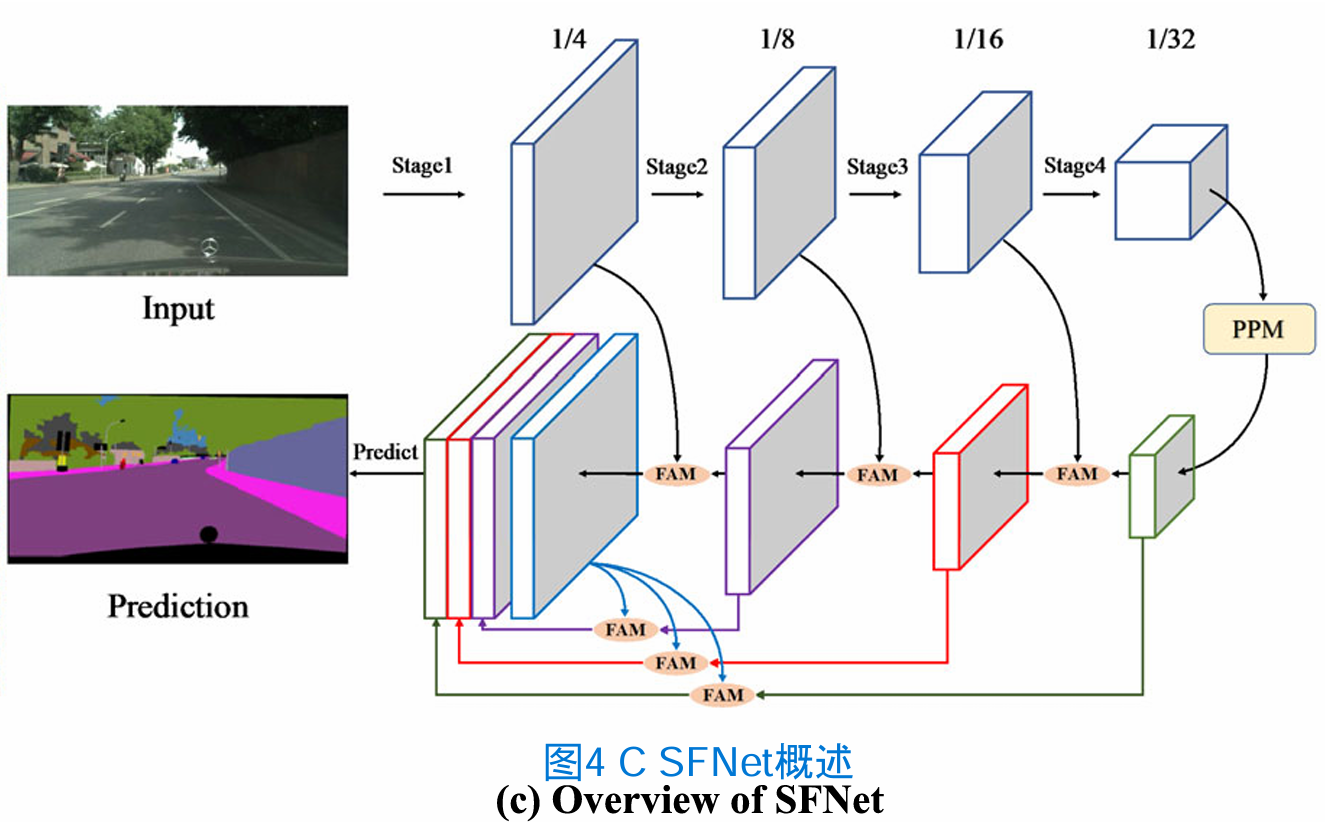
图4 C 我们提出的SFNet概述。采用ResNet-18四级骨干网作为示例说明。FAM:流量对准模块。PPM:金字塔池模型(Zhao et, 2017)。最好看它的彩色和放大
编码器部分
我们选择在ImageNet (Russakovsky et al ., 2015)上进行图像分类预训练的标准网络作为骨干网络,去掉最后一个完全连接层。具体来说,我们的实验使用并比较了ResNet系列(He et al, 2016)和DF系列(Li et al, 2019)。所有主干由4段和剩余区块组成。为了实现计算效率和更大的接受域,我们在每个阶段包括一个步幅为2的卷积层作为第一层,它对特征映射进行下采样。我们还采用了金字塔池模块(PPM) (Zhao et al ., 2017),因为它具有捕获上下文信息的优越能力。在我们的设置中,PPM的输出与最后一个剩余模块的输出具有相同的分辨率。在这种情况下,我们将PPM和最后剩余模块一起视为即将到来的FPN的最后阶段。其他模块如ASPP (Chen et al ., 2017)也可以插入到我们的网络中,在实验部分也进行了实验消融。
对准FPN解码器
我们的SFNet解码器从编码器获取特征映射,并使用对齐的特征金字塔进行最终的场景解析。

图片解释:通过在FPN的自顶向下路径中用FAM代替正常的双线性上采样(Lin et al, 2017), {Fl}4 l=2被细化为{Fl}4 l=2,其中顶层特征映射通过元素加法对齐并融合到底层,l表示特征金字塔级别的范围。对于场景解析,{Fl}4 l=2∪{F5}被上采样到相同的分辨率(即输入图像的1/4)并连接在一起进行预测。
考虑到在前一步中仍然存在不对准,我们也将这些上采样操作替换为所提出的FAM。值得注意的是,我们只在消融研究中验证了这种设计的有效性。我们实时应用程序的最终模型不包含这样的替换,以便更好地权衡速度和准确性。
3.3 门控双流对准模块和SFNet-Lite
动机
原始SFNet采用基于多阶段流的对齐过程,导致其速度比BiSegNet等几个代表性网络慢(Changqian et al ., 2018;Zhao et al ., 2018)。由于轻量级骨干设计不是我们的主要焦点,我们探索更紧凑的解码器,只有一个流对齐模块。减少FAM数量导致结果较差(实验部分见表9(d))。为了弥补这一差距,受到最近在分割中门控设计成功的激励(Takikawa等人,2019;Li et al ., 2020),我们提出了一种新的FAM变体,称为门控双流对齐模块(GD-FAM),用于直接对齐和融合最高分辨率特征和最低分辨率特征。由于只有一次对齐,这意味着较少的算子,我们可以加快推理时间。
门控双流量对准模块
GD-FAM与FAM一样,以F4和F1两个特征为输入,直接输出一个精细的高分辨率特征。我们通过双线性插值层将样本F4提升到与F1相同的大小。然后,我们将它们连接在一起,并将连接的特征映射作为包含两个卷积层的子网络convF的输入,该子网络的核大小为3 × 3。

图片解释:该网络直接输出一个新的流程图ΔF∈RH4×W4×4。我们将这样的地图ΔF拆分为ΔF1和ΔF4,共同对齐F1和F4。
此外,我们提出了一个共享门图,以突出两个对齐特征上最重要的区域。我们的关键观点是充分利用高层次的语义特征,让低级特征作为高层次特征的补充。特别地,我们采用另一个包含一个卷积层和一个Sigmoid层的子网来生成这样的门映射,卷积层的核大小为1 × 1。为了突出两个特征的最重要区域,我们在两个特征上采用了最大池化(Maxpool)和平均池化(Avepool)。然后我们将所有四个映射连接起来以生成这种可学习的门控映射。这个过程如下所示:
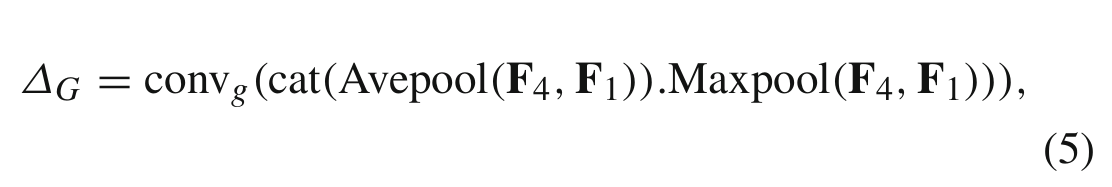
然后采用ΔG对对齐后的高语义特征进行加权,利用ΔG的反演对对齐后的低语义特征进行加权作为融合过程。关键的见解有两个方面。首先,共享相同的门可以更好地突出最突出的区域。其次,采用减法门控弥补了低分辨率特征中缺失的细节。这一过程如下:
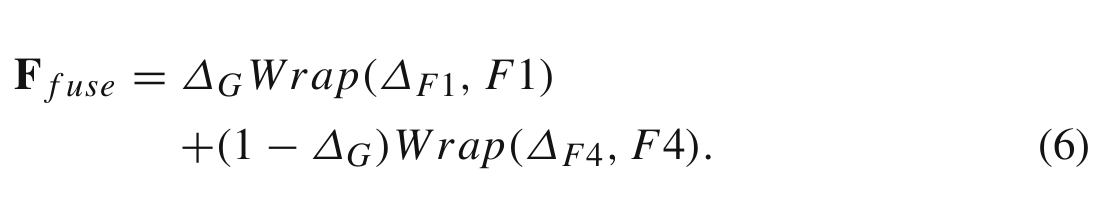
其中Wrap过程与公式3相同。我们的关键观点是,更好地融合这两种特征可以产生更细粒度的特征表示:丰富的语义和高分辨率的特征映射。整个过程如图5a所示。
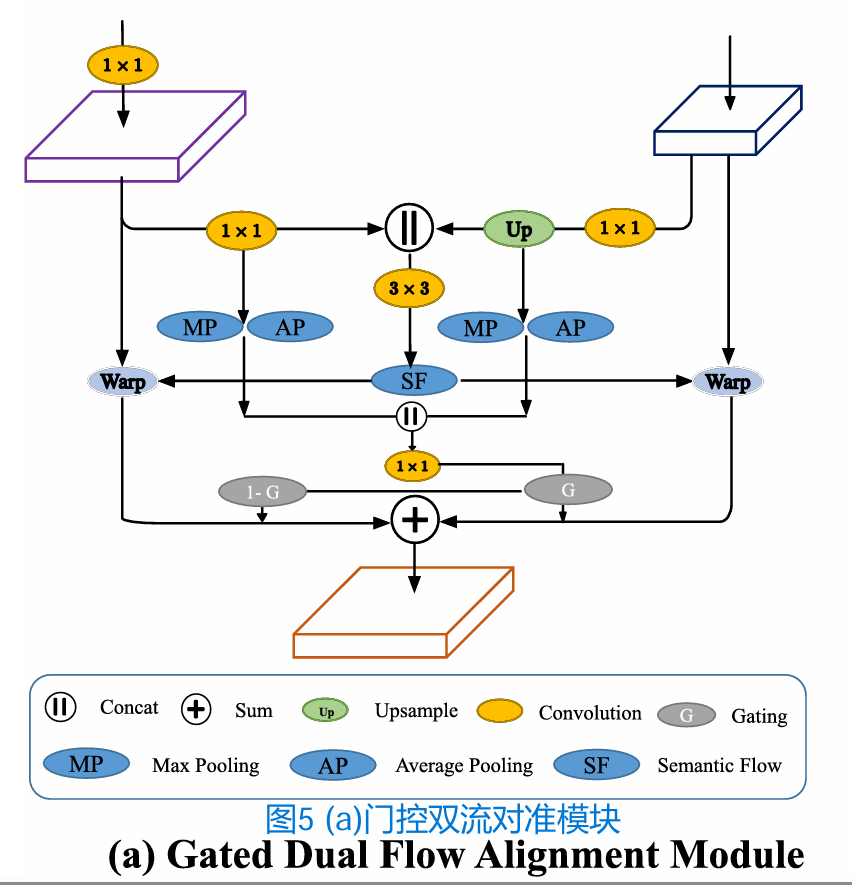
图5a GD-FAM(门控双流对准模块)的详细信息。我们将变换后的高分辨率特征图和低分辨率特征图结合,生成两个语义流场和一个共享门图。利用语义流对低分辨率特征图和高分辨率特征图进行翘曲。门控制着聚变过程。
Lite对齐解码器
Lite对齐解码器是对齐解码器的简化版本,其中包含一个GD-FAM和一个PPM。如图5b所示,最终分割头以F fuse的输出和最后阶段的上采样深度特征作为输入,通过对组合输入进行一次1×1卷积输出最终的分割图。Lite对齐解码器通过涉及较少的多尺度特征(只有两个尺度)来加快对齐解码器的速度。避免快捷设计还可以在将模型部署到设备上进行实际使用时提高速度。在实验部分可以找到更多的结果。
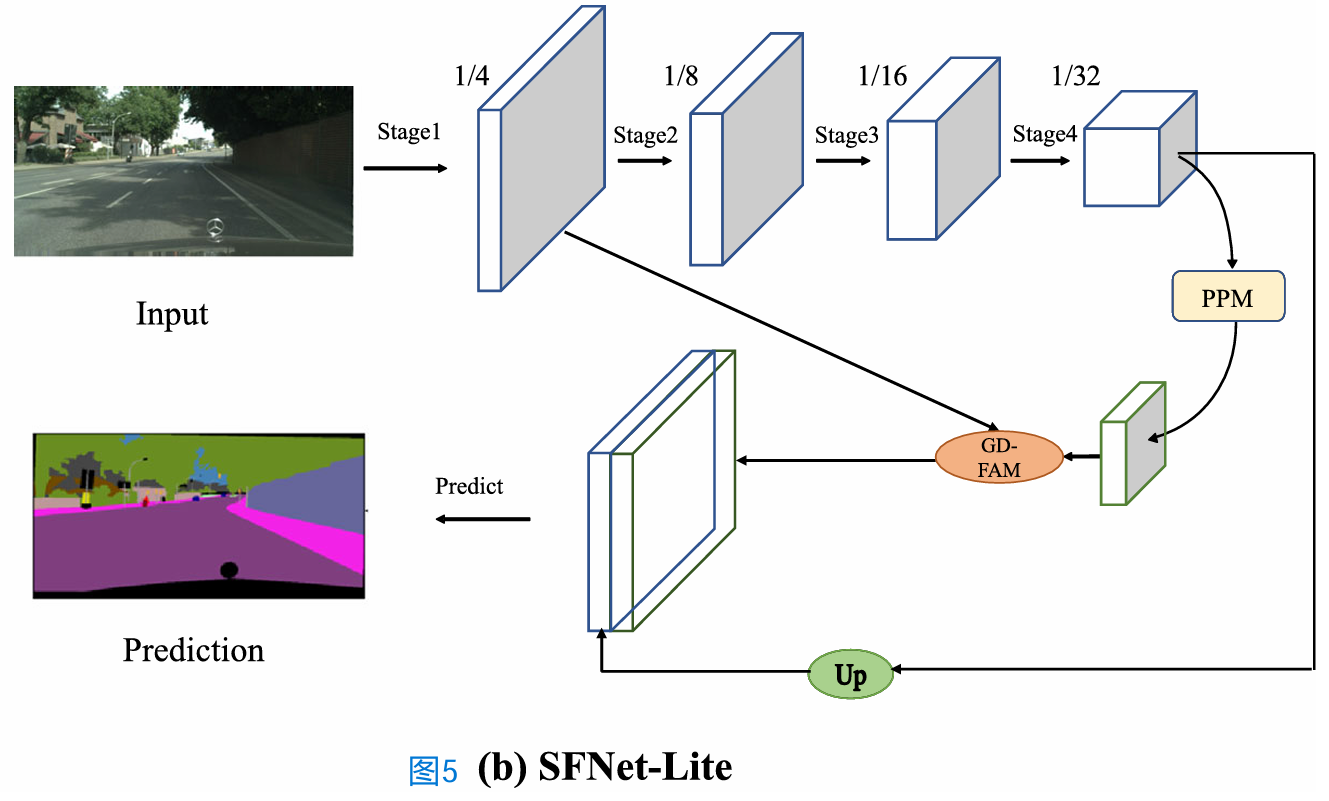
图5b 我们提议的SFNet-Lite概述。采用ResNet-18四级骨干网作为示例说明。GD-FAM:门控双流量对准模块。PPM:金字塔池模型(Zhao et, 2017)。最好看它的彩色和放大
速度对比分析
在表1中,我们比较了SFNet和SFNet- lite在不同设备上的速度。SFNetLite在各种设备上运行速度更快。特别是,当在TensorRT上部署时,SFNet- lite甚至比SFNet快得多,因为它涉及更少的跨规模分支,并导致更好的加速优化。

3.4 统一的驾驶分割数据集
动机
学习一个统一的驾驶目标分割模型是有用的,因为在自动驾驶汽车的移动过程中,环境可能会发生很大的变化。MSeg (Lambert et al, 2020)提出了一个更具挑战性的设置,而我们只关注高分辨率的户外驾驶场景。由于道路场景的概念有限,与M-Seg相比,我们只有很小的标签空间,它有几个常见的场景(COCO (Lin et al ., 2014), ADE20k (Zhou et al ., 2016))。
在不引入领域感知学习的情况下,我们验证了SFNet系列在不同领域特征对齐新设置上的有效性(Choi等人,2021)。UDS的目标是在驾驶场景分割上提供更公平的比较。据我们所知,我们是第一个使用一个模型对这种大规模驾驶数据集进行基准测试的人。
数据处理及结果
我们合并了四个具有挑战性的数据集,包括Mapillary (Neuhold等人,2017)、cityscape (Cordts等人,2016)、IDD (Varma等人,2019)和BDD (Fisher等人,2020)。由于emapillary有65个类标签,我们将几个语义标签合并为一个标签。合并过程遵循之前的工作(Choi et al ., 2021)。我们将其他标签设置为忽略区域。这样,我们就保持了与cityscape和IDD相同的标签定义。对于IDD数据集,我们使用与cityscape和BDD相同的类定义。对于BDD和cityscape数据集,我们保持原始设置。合并后的数据集UDS总共有34,968张用于训练的图像和6,500张用于测试的图像。UDS数据集的详细信息如表2所示。此外,我们发现最近几种基于自我关注的方法(Jun et al, 2019;Yuan等,2020;Li et al ., 2019)不能比以前的方法DeeplabV3+ (Chen et al ., 2018)表现得好。这意味着需要一种更好的广义方法来实现这种设置。我们在github页面上提供了代码和模型。
讨论
请注意,尽管设计更平衡的采样方法或包含基于域泛化的方法可以改善UDS上的结果,但本工作的目标只是验证我们的SFNet和SFNetLite在这种具有挑战性的设置上的有效性。GD-GAM和FAM都执行图像特征级对齐,对域变化不敏感。此外,我们还使用RobustNet展示了SFNet在域生成设置上的有效性(Choi等人,2021)。更多的细节可以在实验部分找到。
3.5 改进细节及扩展
改进的细节
我们使用深度监督损失(deeply supervised loss)(Zhao et al ., 2017)来监督解码器的中间输出,以便于优化。此外,继(Changqian et al ., 2018)之后,在线硬例挖掘(online hard example mining)(Shrivastava et al ., 2016)也被使用,仅对交叉熵损失(cross-entropy loss)排序的10%最硬像素进行训练。在推理过程中,我们只使用主头部的结果。我们还使用统一的抽样方法来平衡所有基准测试中训练期间的罕见类。对于cityscape数据集,我们还使用粗增强训练技巧(coarse boosting training tricks )(Zhu et al ., 2019)来增强cityscape上的稀有类。对于骨干网设计,我们还部署了最新的先进骨干网STDC (Fan et al ., 2021),以加快设备上的推理速度。
将SFNet扩展到全视分割
全景分割是语义分割和实例分割的统一,是一项具有挑战性的任务。我们还通过提出的全经分割基线K-Net探索了在此类任务上提出的SFNet (Zhang et al ., 2021)。K-Net是一种最先进的全视分割方法,其中每个东西都由解码器头部的核表示。特别是,我们用我们提出的SFNet骨干网和对齐解码器取代了K-Net的骨干部分。然后我们使用与K-Net相同的设置来训练修改后的模型。
4 实验
4.1 实验设置
概述
我们首先回顾SFNet的数据集和训练设置。然后,比较了SFNet和新提出的SFNet-lite五种道路驾驶数据集的结果。然后,我们在SFNet上进行了详细的消融研究和分析。最后,我们展示了SFNet在城市景观全景分割数据集上的泛化能力。
数据集
我们主要在道路驾驶数据集上进行实验,包括cityscape、Mapillary、IDD、BDD以及我们提出的合并驾驶数据集。我们还报告了在cityscape验证集上的全景分割结果。城市景观是对19类城市场景进行密集标注的基准,共包含5000张精细标注的图像,分别分为2975张、500张和1525张进行训练、验证和测试。此外,还提供了2万张粗标记图像,以丰富训练数据。在道路驾驶场景中,图像都是相同的高分辨率,即1024 × 2048。注意,我们使用精细注释的数据集进行消融研究并与先前的方法进行比较。我们还使用粗数据来提高SFNet-Lite的最终结果。Mapillary 是一个大规模的道路驾驶数据集,它比cityscape更具挑战性,因为它包含更多的类和各种场景。它包含18,000张用于训练的图像和2000张用于验证的图像。IDD 是另一个主要包含印度场景的道路驾驶数据集。它包含比城市景观更多的图像。它有6,993个训练图像和981个验证图像。据我们所知,我们是第一个在Mapillary和IDD数据集上对实时分割模型进行基准测试的人。另一个研究小组开发了BDD数据集,主要包含美国地区的各种场景。它有7000个训练图像和1000个验证图像。所有数据集(包括UDS数据集)在线可用。
实现细节
我们使用PyTorch (Paszke et al ., 2017)框架来执行所有实验。所有网络都使用相同的设置进行训练,其中使用批大小为16的随机梯度下降(stochastic gradient descent,SGD)作为优化器,动量为0.9,权值衰减为5e-4。所有模型都训练了50K次迭代,初始学习率为0.01。作为一种常见的做法,采用“多”学习率策略,在训练期间通过乘以(1 - iter/total_iter)的0.9次方 来衰减初始学习率。对于cityscape、Mapillary、BDD、IDD和UDS数据集,数据增强包括随机水平翻转、随机调整大小(尺度范围为[0.75,2.0])和随机裁剪(裁剪大小为1024 × 1024)。为了进行定量评价,采用类间交叉比均值(每个类交并比的平均, mIoU)进行精确比较,采用每秒浮点运算(Floating-point Operations Per Second, FLOPs)和每秒帧数(Frames Per Second,FPS)进行速度比较。此外,为了获得更强的基线,我们还采用了Zhu等人(2019)提出的类平衡抽样策略(the class-balanced sampling strategy),该策略获得了更强的基线。对于cityscape数据集,我们还采用了粗标注数据增强方法来提高稀有类分割质量。我们的代码和模型可供参考。还要注意,Mapillary、BDD、IDD和USD数据集中的几种非真实分割方法是使用我们的代码库实现的,并在相同的设置下进行训练。
TensorRT部署设备
测试环境是在单个TITAN-RTX GPU上使用TensorRT 8.2.0和CUDA 11.2。此外,我们通过CUDA重新实现网格采样算子,与TensorRT一起使用。该操作符由PyTorch提供,用于流对齐模块中的翘曲操作。我们报告了推断100张图像的平均时间。此外,我们还将SFNet和SFNet- lite部署在不同的设备上,包括1080-TI和RTX-3090。我们将在下一部分报道结果。
4.2 主要结果
城市景观测试集的结果
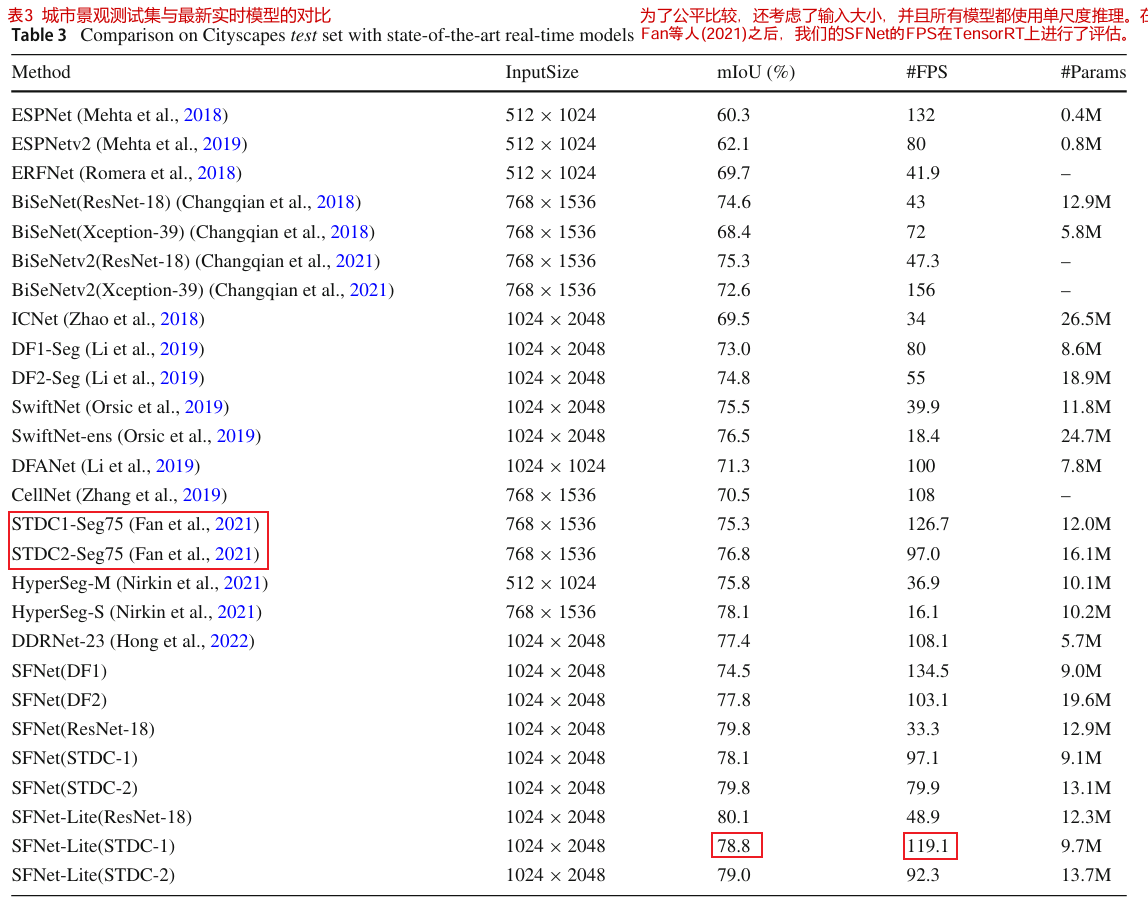
我们首先在表3中报告了cityscape数据集上的SFNet。以ResNet-18为骨干,我们的方法达到了79.8%的mIoU,甚至达到了精确模型的性能,这将在下文中讨论。该方法以STDC网络为骨干,在全分辨率输入下以80 FPS运行,mIoU达到79.8%。这表明我们的方法可以受益于一个精心设计的脊柱。对于改进后的SFNet- lite,使用ResNet-18作为骨干,我们的方法可以获得比原始SFNet更好的结果,同时运行速度更快。对于STDC骨干网,我们的方法在保持相同精度的同时实现了更快的速度。特别是,使用STDC-v1,我们的方法在以120 FPS运行的情况下实现了78.8%的mIoU,这是平衡速度和精度的最新结果。这表明我们提出的GD-FAM的有效性。
请注意,为了公平比较,在表3中,继之前的工作(Fan et al ., 2021;Changqian等人,2021),我们使用Tensor-RT设备报告速度。对于剩余数据集的结果,我们只报告GPU的平均推理时间。使用ResNet-18的原始SFNet实现了78.9%的mIoU,我们采用均匀采样、粗提升和长时间训练,使测试集的增益增加了0.9%。详细信息可以在以下部分中找到。
Mapillary 验证集的结果
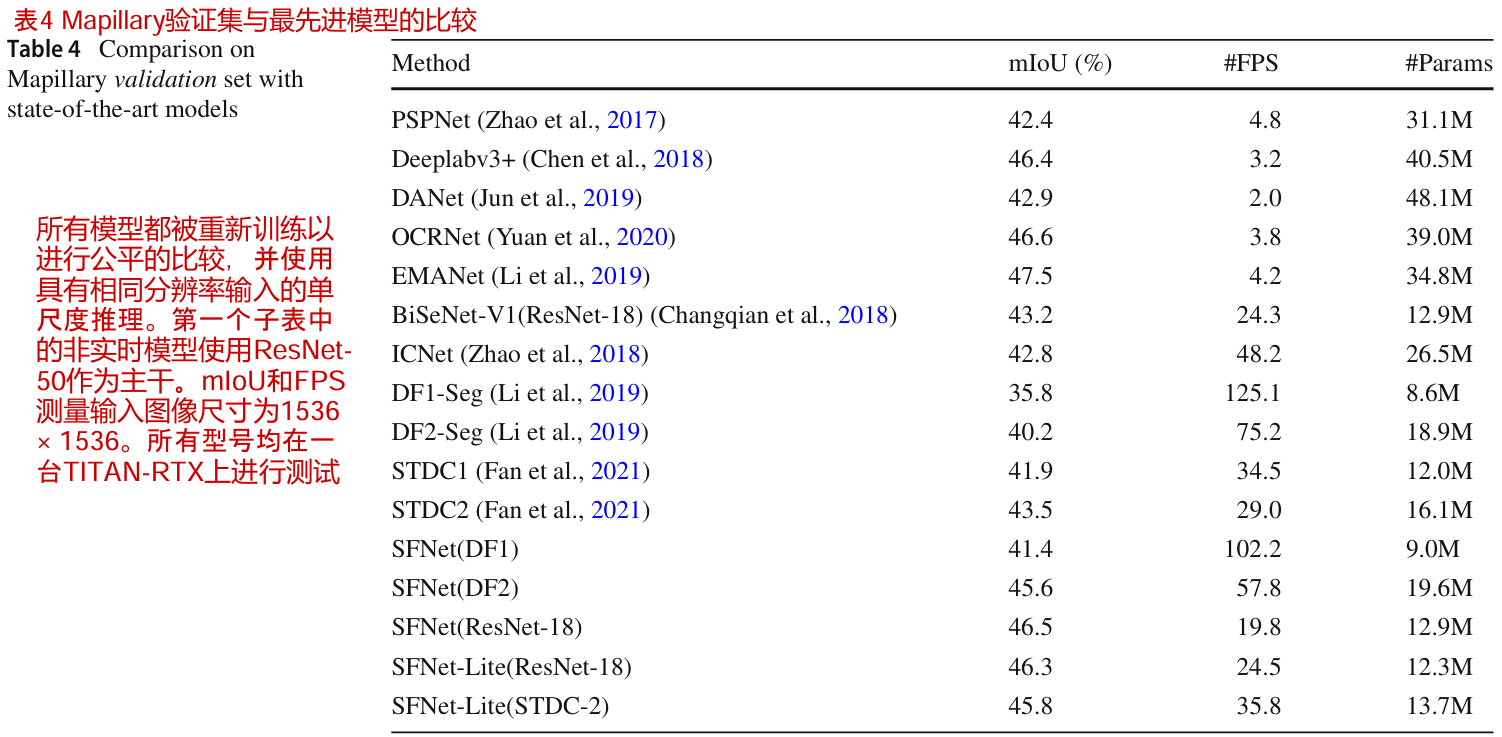
在表4中,我们报告了在更具挑战性的Mapillary数据集上的速度和准确性结果。由于该数据集包含高分辨率图像,直接推断可能会引发内存不足问题,我们将图像的短尺寸调整为1536,并根据Zhu等人(2019)裁剪图像和地面真相中心。
如表4所示,我们的方法还实现了各种骨干网的最佳速度和精度权衡。尽管Deeplabv3+ (Chen et al, 2018)和EMANet (Li et al, 2019)实现了更高的精度,但它们的速度无法达到实时标准。特别是,对于基于DFNet的骨干网(Li et al ., 2019),我们的SFNet实现了近5-6%的mIoU改进。对于SFNet-Lite,我们的方法在运行速度更快的同时也取得了可观的结果。
IDD 验证集的结果
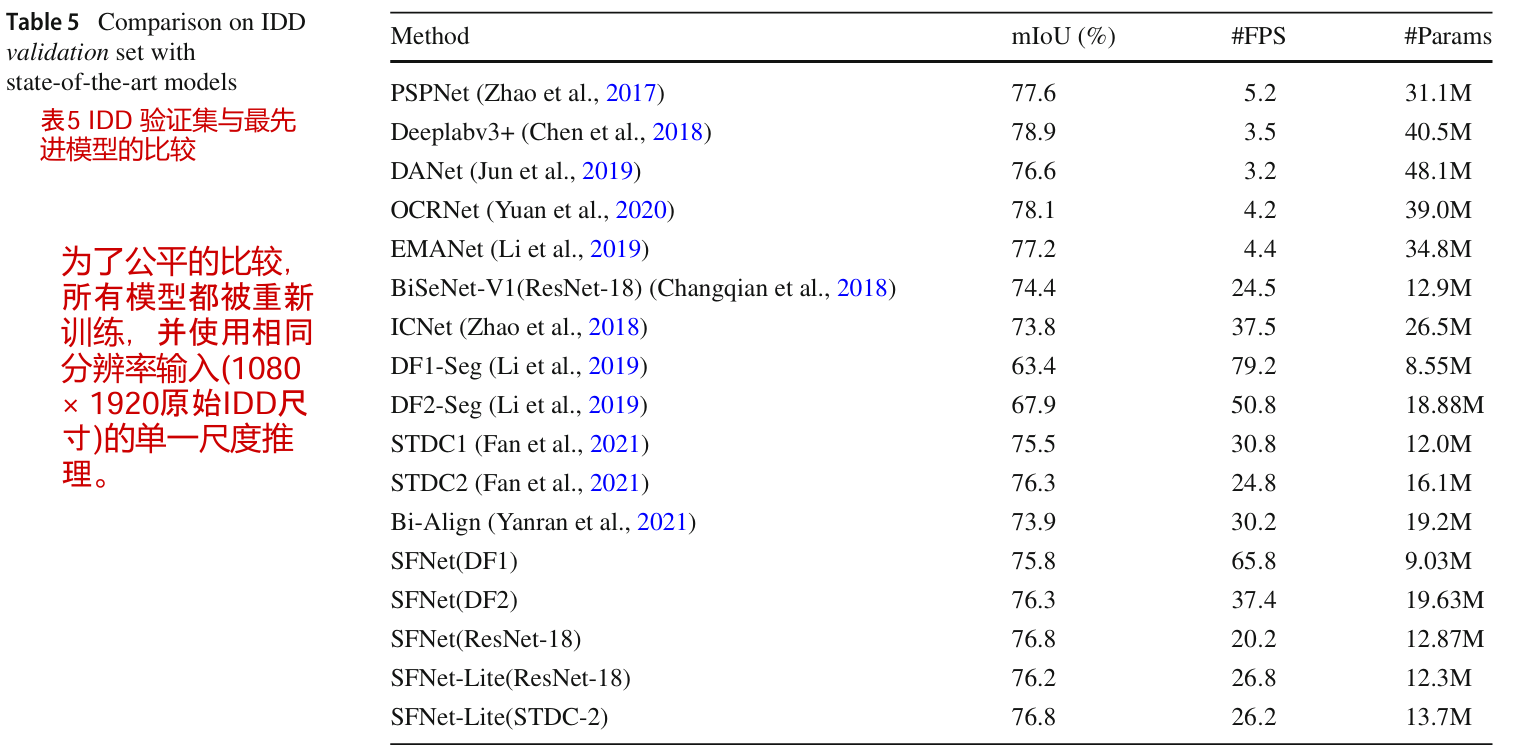
在表5中,我们的方法实现了速度和精度的最佳权衡。与之前的工作STDCNet相比,我们的方法准确率更高,速度更快,如表5最后一行所示。对于DFNet骨干网,我们的方法也实现了近12% mIoU的相对改进。这些结果表明,所提出的FAM和GD-FAM可以准确地将低分辨率特征对齐到更精确的高分辨率和高语义特征图中。
BDD 验证集的结果
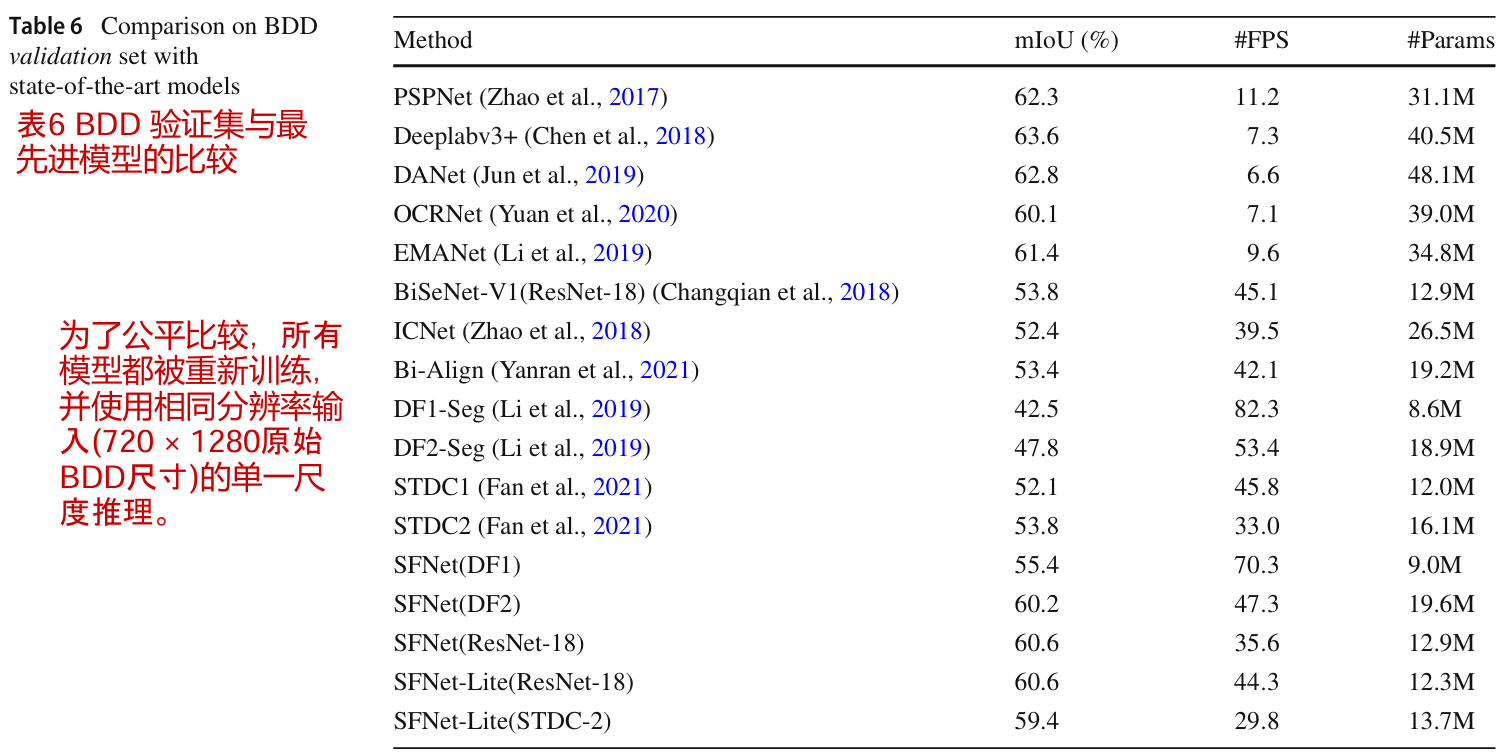
在表6中,我们进一步对BDD数据集上的代表性作品进行基准测试。从这个表中,Deeplabv3+ (Chen et al, 2018)达到了最高的性能,但速度要慢得多。同样,我们的方法,包括原始的SFNet和改进的SFNet- lite,都实现了最佳的速度和精度权衡。对于最新的最先进的STDCNet方法(Fan et al, 2021),我们的SFNet-Lite在运行速度较慢的情况下实现了5%的mIoU改进。当采用ResNet-18骨干网时,我们的SFNet-Lite在没有TensorRT加速的情况下以44.5 FPS运行时实现了60.6%的mIoU。
USD 测试集的结果
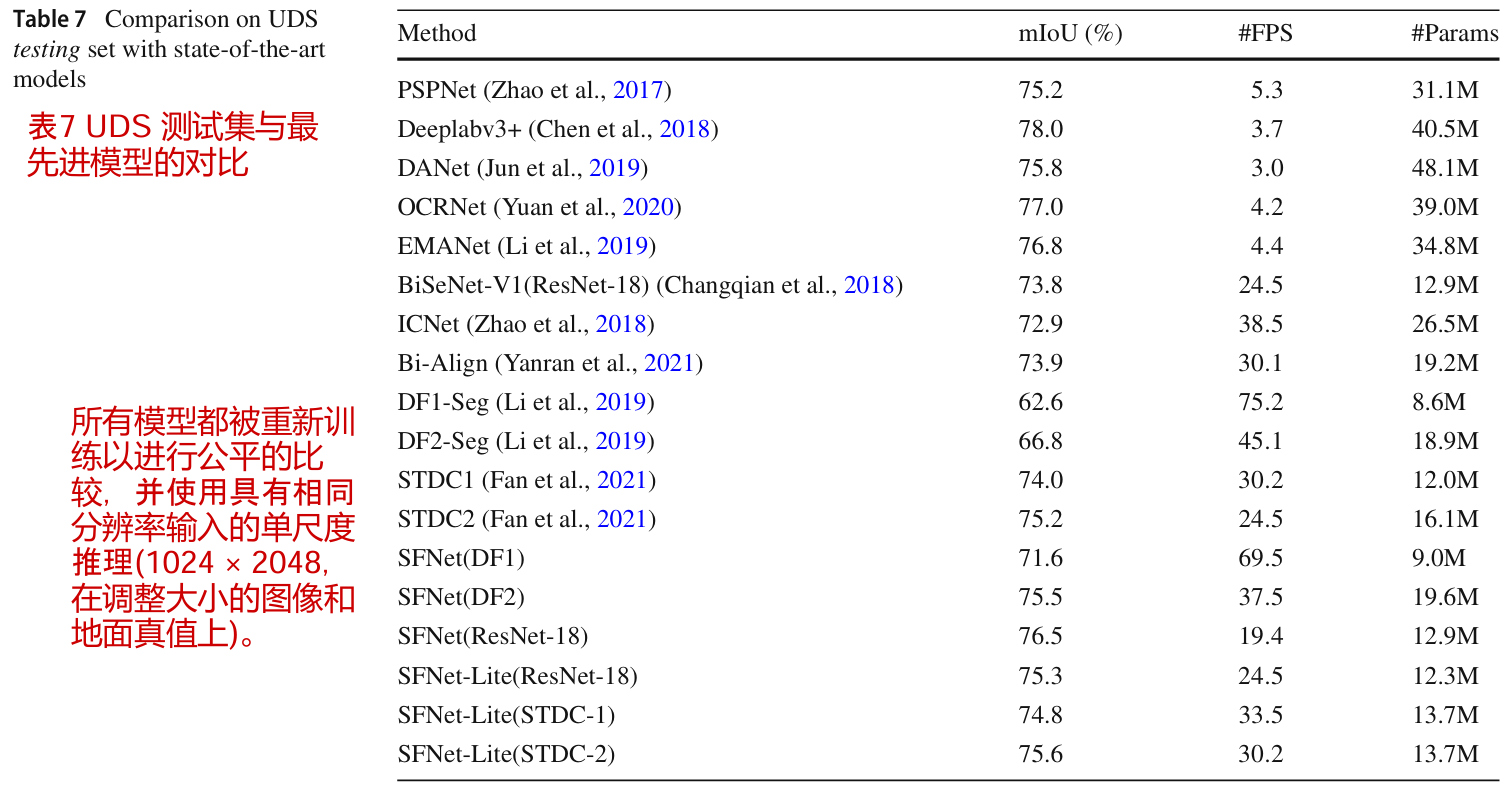
最后,我们在表7中合并的美元数据集上对最近的工作进行基准测试。为了适应GPU内存,我们将图像和真实图像的大小都调整为1024 × 2048。从该表中,我们发现Deeplabv3+ (Chen et al ., 2018)实现了最佳性能。几种基于自我注意的模型(Li et al ., 2019;Yuan等,2020;Jun等人,2019)在这些领域变异数据集上取得的结果甚至比以前的Deeplabv3+更差。这表明USD数据集仍有很大的改进空间。
如表7所示,我们使用DFNet骨干网的方法比DF-Seg基线实现了相对10%的mIoU改进。当配备ResNet-18骨干网时,我们的SFNet在以20 FPS运行时达到76.5% mIoU。当采用STDC-V2骨干网时,我们的SFNet-Lite实现了最佳的速度和精度权衡。
4.3 消融研究
FAM和GD-FAM的有效性

表8(a)报告了cityscape验证集与基线的比较结果(Cordts等人,2016),其中ResNet-18 (He等人,2016)作为主干。与初始FCN相比,扩展后的FCN使mIoU提高了1.1%。通过将FPN解码器附加到原始FCN上,我们获得了74.8%的mIoU,提高了3.2%。通过用FAM代替双线性上采样,mIoU提高到77.2%,分别将原始FCN和FPN解码器提高5.7%和2.4%。最后,我们附加了PPM(金字塔池模块)(Zhao et al ., 2017)来捕获全局上下文信息,这与FAM一起实现了78.7%的最佳mIoU。同时,FAM与PPM是互补的,观察到FAM将PPM从76.6提高到78.7%。在表10(a)中,我们比较了GD-FAM和FAM的有效性。如该表所示,在相同设置下,我们新提出的GD-FAM在运行速度上比原来的FAM有更好的性能(0.4%)。
插入FAM或GD-FAM的位置
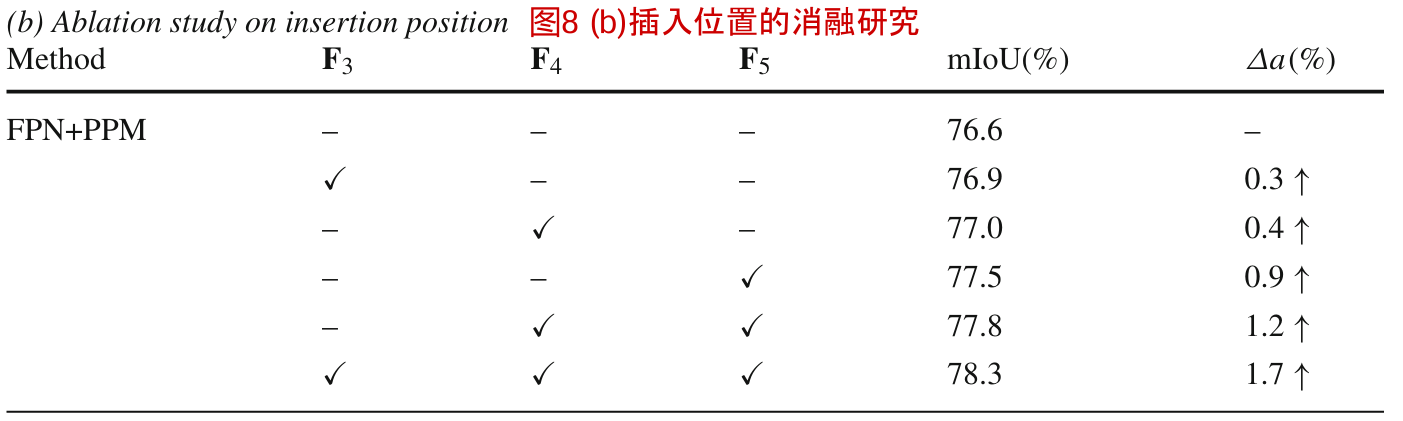
我们将FAM插入FPN解码器的不同阶段位置,并在表8(b)中报告结果。从前三行来看,FAM改善了所有阶段,最后阶段改善最大,说明FPN的所有阶段都存在不对准,在粗层中更严重。这与粗层包含更强的语义但分辨率较低的事实是一致的,当它们被适当地上采样到高分辨率时,可以极大地提高分割性能。最好的结果是在最后一行的所有阶段添加FAM。对于GD-FAM,我们的目标是将高分辨率特征和低分辨率特征直接对齐。默认情况下,我们选择将F3和PPM的输出对齐。
网络架构设计的消融研究
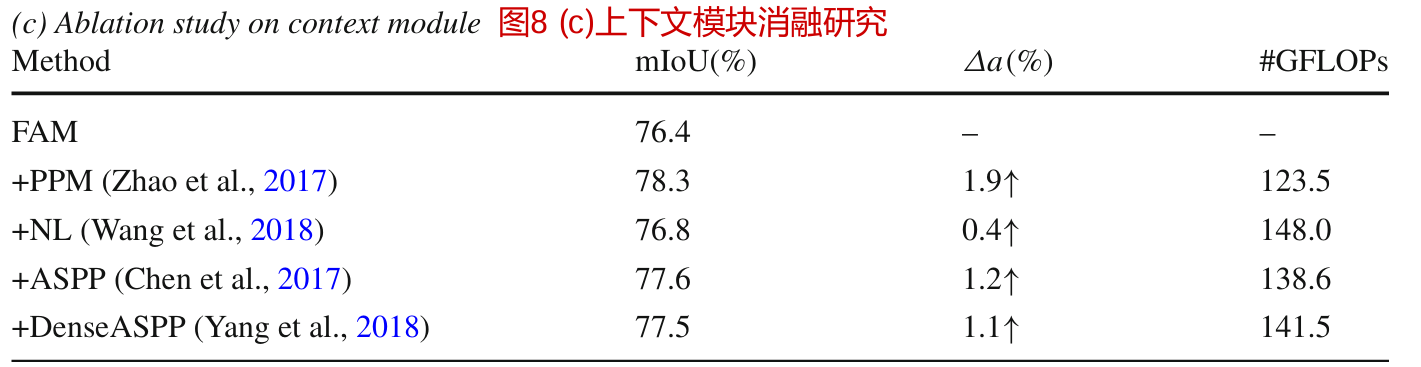
考虑到当前最先进的上下文模块被用作扩展骨干网的头(Chen等人,2017;Yang等人,2018),我们在使用粗特征映射进行上下文建模的方法中进一步尝试不同的上下文头。表8©报告了比较结果,其中PPM (Zhao et al ., 2017)提供了最好的结果,而最近提出的方法,如非基于本地的磁头(Wang et al ., 2018)表现更差。因此,我们选择PPM作为上下文头,因为它具有更好的性能和更低的计算成本。
FAM设计的消融
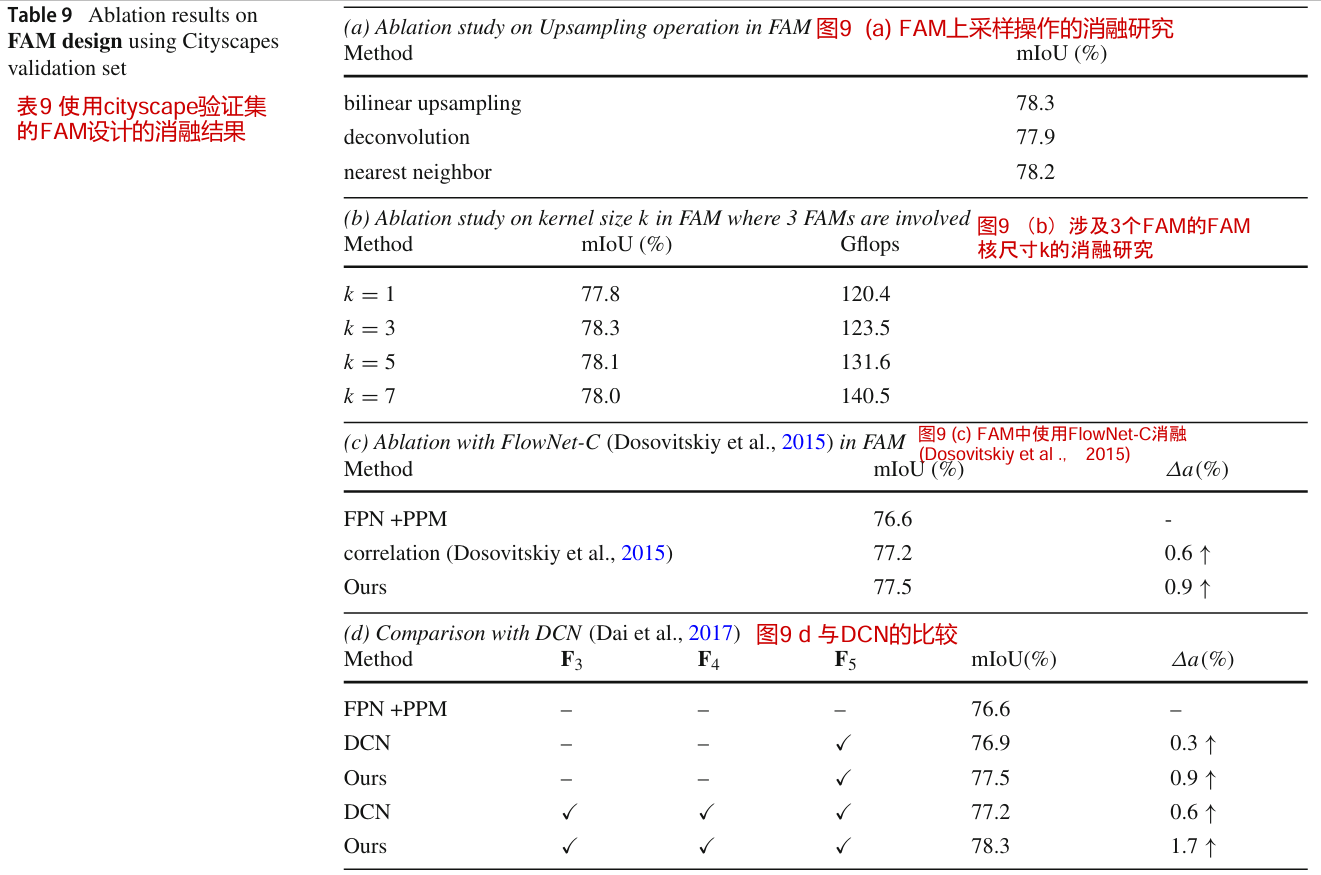
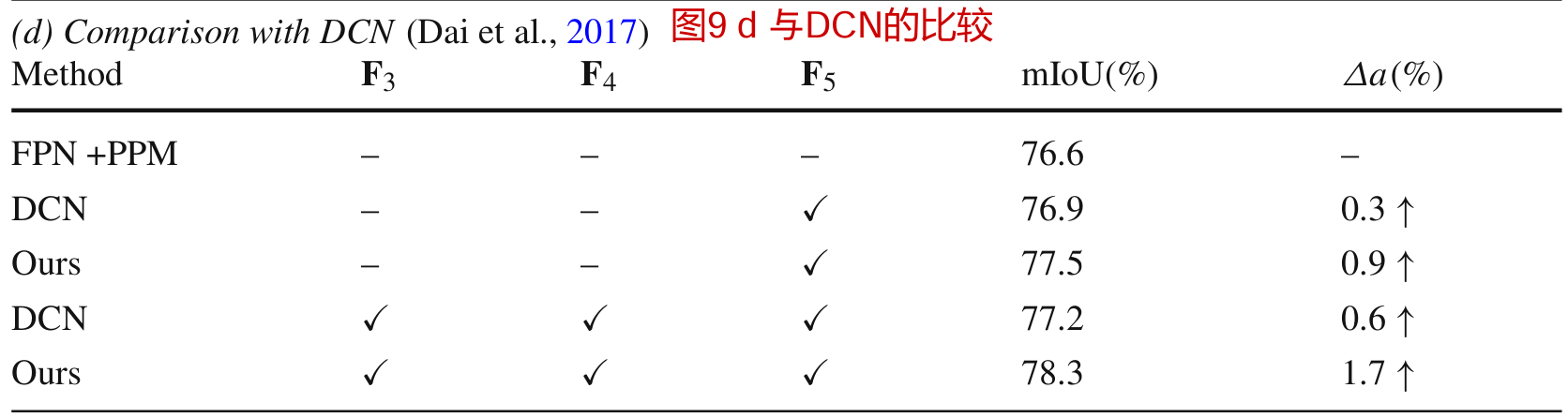
我们首先在表9(a)中探讨了FAM中上采样的影响。用反卷积和最近邻上采样代替双线性上采样,分别获得77.9% mIoU和78.2% mIoU,与双线性上采样获得的78.3% mIoU相似。我们还尝试了表9(b)中的各种内核大小。我们还尝试了更大的5 × 5内核大小,得到了类似的结果(78.2%),但引入了更多的计算成本。在表9©中,用FlowNet-C中的correlation替换FlowNet-S也会导致稍差的结果(77.2%),但会增加推理时间。结果表明,使用轻量级的FlowNet-S对FPN中的特征图进行对齐是足够的。在表9(d)中,我们将我们的结果与DCN (Dai et al ., 2017)进行了比较。我们将DCN应用于双线性上采样特征映射和下一级特征映射的连接特征映射上。我们首先在更高的层F5中插入一个DCN,因为我们的FAM比它更好。在对所有层应用DCN后,性能差距要大得多。这表明我们的方法还可以对齐低层边缘以获得更好的边界和低层边缘,这些将在可视化部分中显示。
消融GD-FAM设计
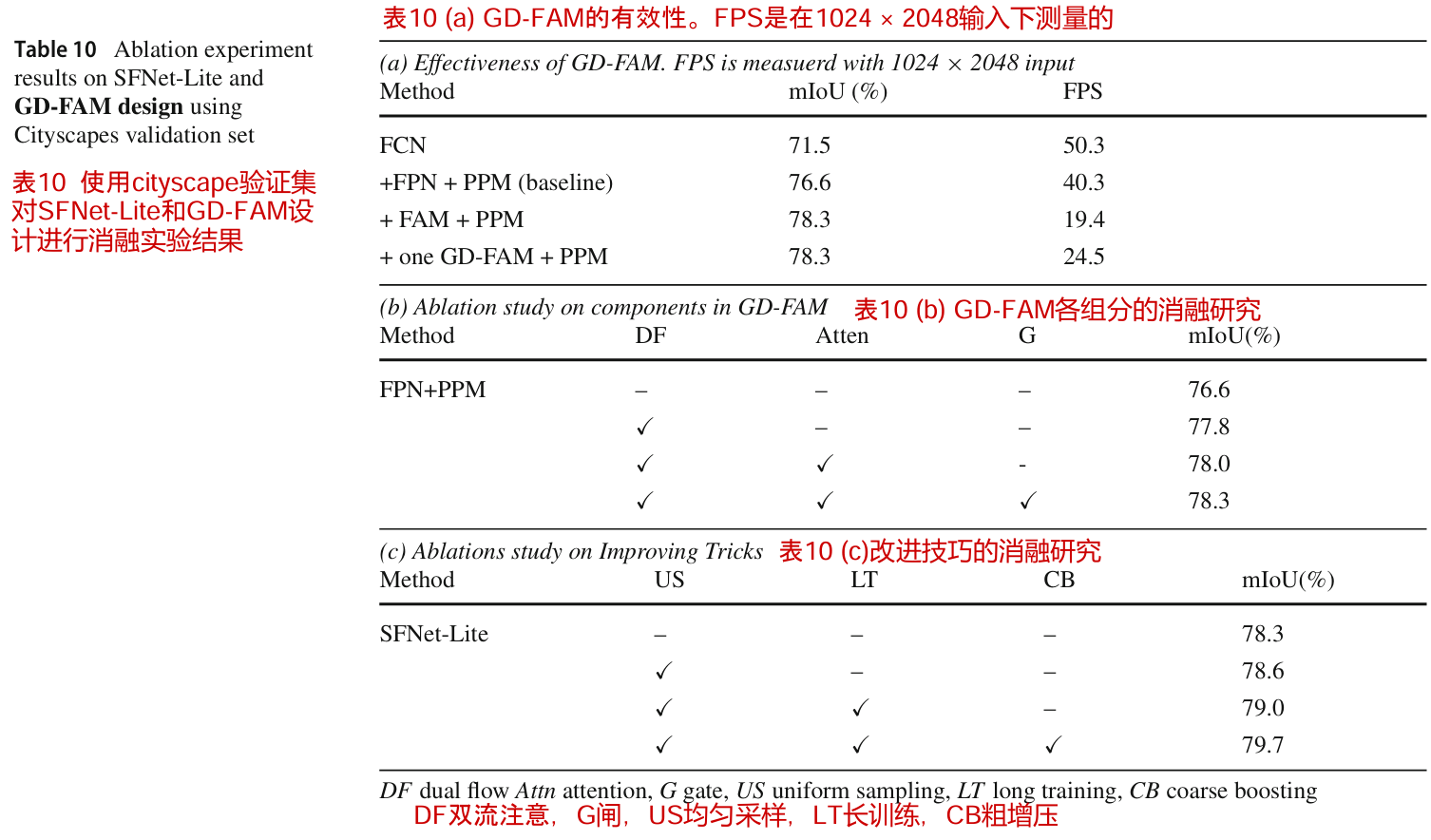
在表10(b)font>中,我们探讨了GD-FAM中各成分的作用。特别是,增加双流(DF)设计,提高了约1.2%的改善。使用注意力生成门而不是使用卷积导致0.2%的改进。最后,使用共享栅极设计也将强基线提高了0.3%。
改善细节的消融
在表10©中,我们探讨了训练技巧,包括均匀采样(Uniform Sampling,US)、长训练(Long Training,LT)和粗提升(Coarse Boosting,CB)。执行US导致我们的SFNet-Lite改进0.3%。使用LT(1000次训练)而不是短期训练(300次训练)可以再提高0.4% mIoU。最后,在几个罕见的类上采用粗数据提升可以再提高0.7%。
各种主干网的泛化
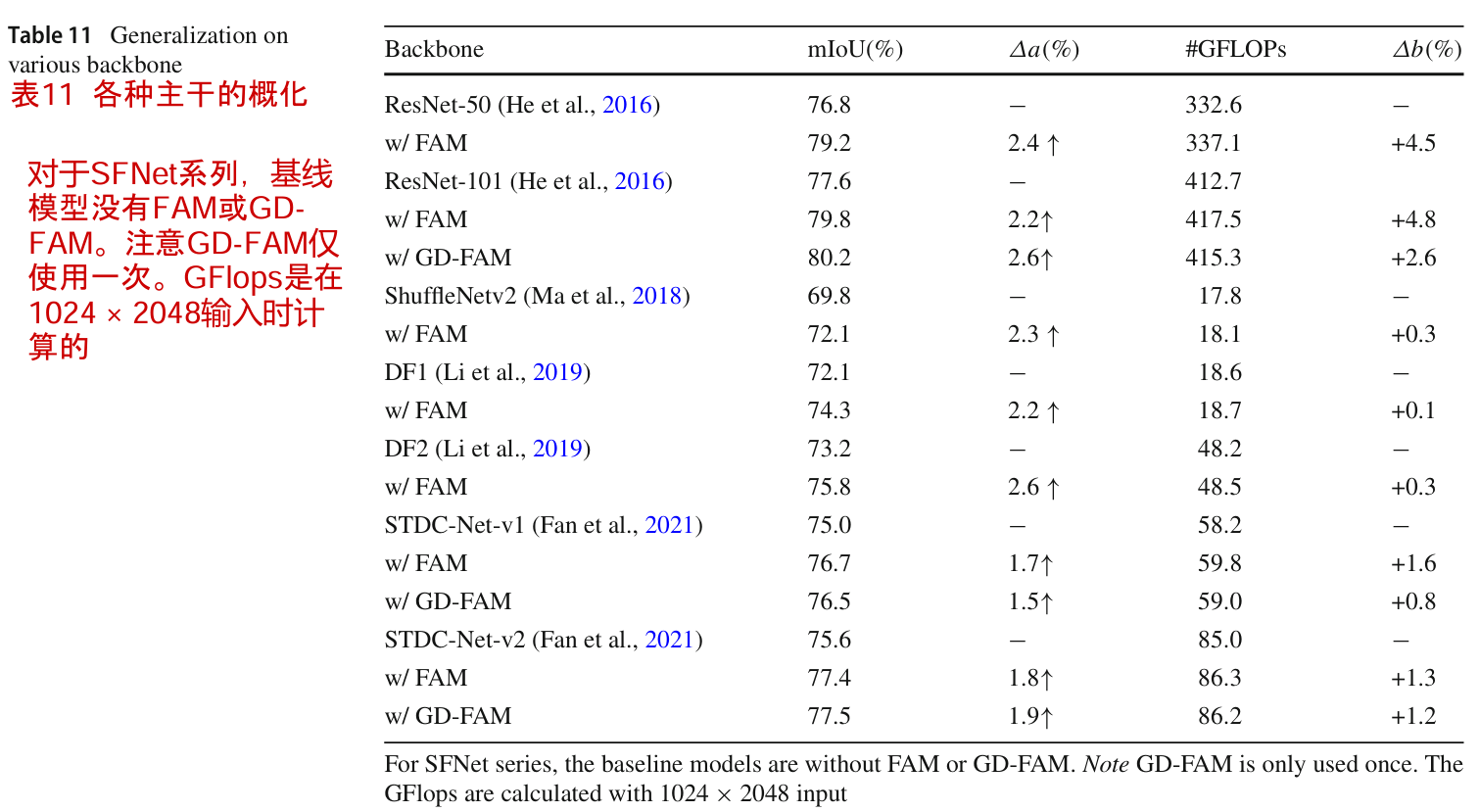
我们进一步对不同的骨干网进行了实验,包括深度和轻量级网络,其中使用带有PPM头的FPN解码器作为表11中的强基线。对于重网络,我们选择ResNet-50和ResNet-101 (He et al, 2016)来提取表示。对于轻量级网络,采用ShuffleNetv2 (Ma等人,2018)、DF1/DF2 (Li等人,2019)和STDC-Net (Fan等人,2021)。FAM在所有主干网上显著地实现了更好的mIoU,并且只需要稍微额外的计算成本。GD-FAM和FAM都能显著提高不同骨干网的计算结果,而额外的计算成本很小。
对齐特征表示
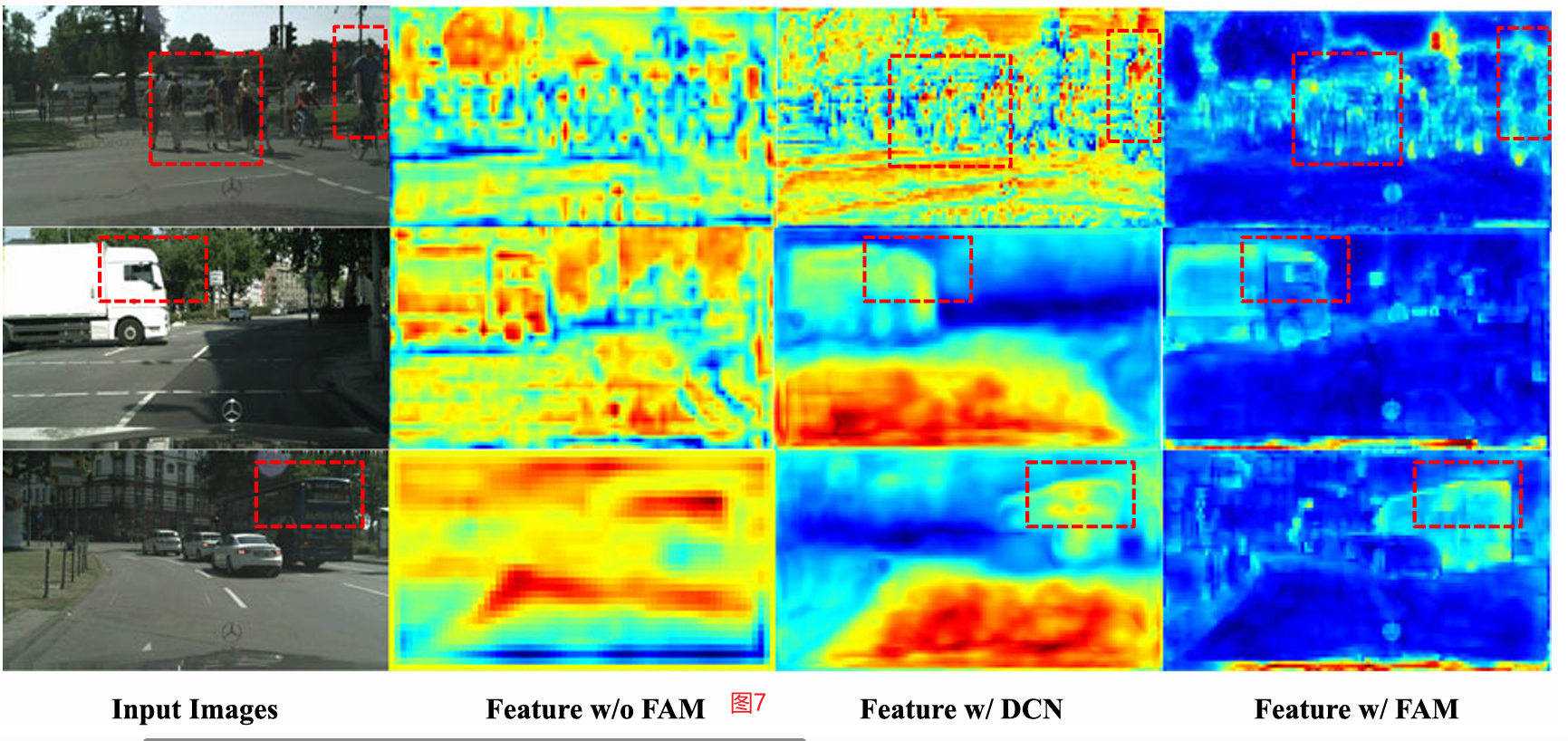
图7对齐特征的可视化。与DCN相比,我们的模块输出了更多的结构特征表示
在这一部分中,我们对对齐特征表示进行了更多的可视化,如图7所示。我们在ResNet-18的最后阶段可视化上采样特征。可以看出,与DCN (Dai et al ., 2017)相比,我们的FAM特征更具结构性,并且具有更精确的目标边界,这与表9(d)的结果一致。这表明FAM并不是对类似DCN的特征的注意效应,而是将特征对齐到比红框更精确的形状。
4.4 更详细的分析
详细的改进

表12font>比较了验证集中每个类别的详细结果,其中使用ResNet101作为主干,使用PPM头的FPN解码器作为基线。SFNet改进了几乎所有类别,特别是“卡车”,mIoU改进超过19%。采用GD-FAM可以在每个类上实现比FAM更一致的改进。
语义流可视化

图6 学习到的语义流场可视化。a列列出了三个示例图像。b-d列为三种FAM在解码过程中的语义流,按分辨率升序排列,采用与图3相同的颜色编码。e列为d列流场的箭头可视化,f列为分割结果
图6显示了FAM在不同阶段的语义流。与光流类似,语义流通过颜色编码可视化,并根据图像大小进行双线性插值,以便快速概述。此外,还将矢量场可视化,以便进行详细检查。从可视化中,我们观察到语义流倾向于从对象内部的某些位置扩散出去。这些位置通常靠近对象中心,有更好的接受野来激活具有纯粹和强语义的顶层特征。然后在语义流的指导下,将这些位置的顶级特征传播到适当的高分辨率位置。此外,语义流还具有从顶层到底层从粗到细的趋势。这种现象与语义流逐渐描述逐渐变小的模式之间的偏移的事实是一致的。
城市景观数据集的视觉改进

图8 a在预测误差方面的定性比较,其中正确预测的像素显示为黑色背景,而错误预测的像素使用其地面真值标签颜色代码着色。
图8a显示了两种方法的预测误差,FAM在很大程度上解决了大物体(如卡车)内部的模糊性,并为小而薄的物体(如杆子、墙的边缘)产生了更精确的边界。图8b显示,由于底层的对齐,我们的模型可以更好地处理具有更清晰边界的小对象。
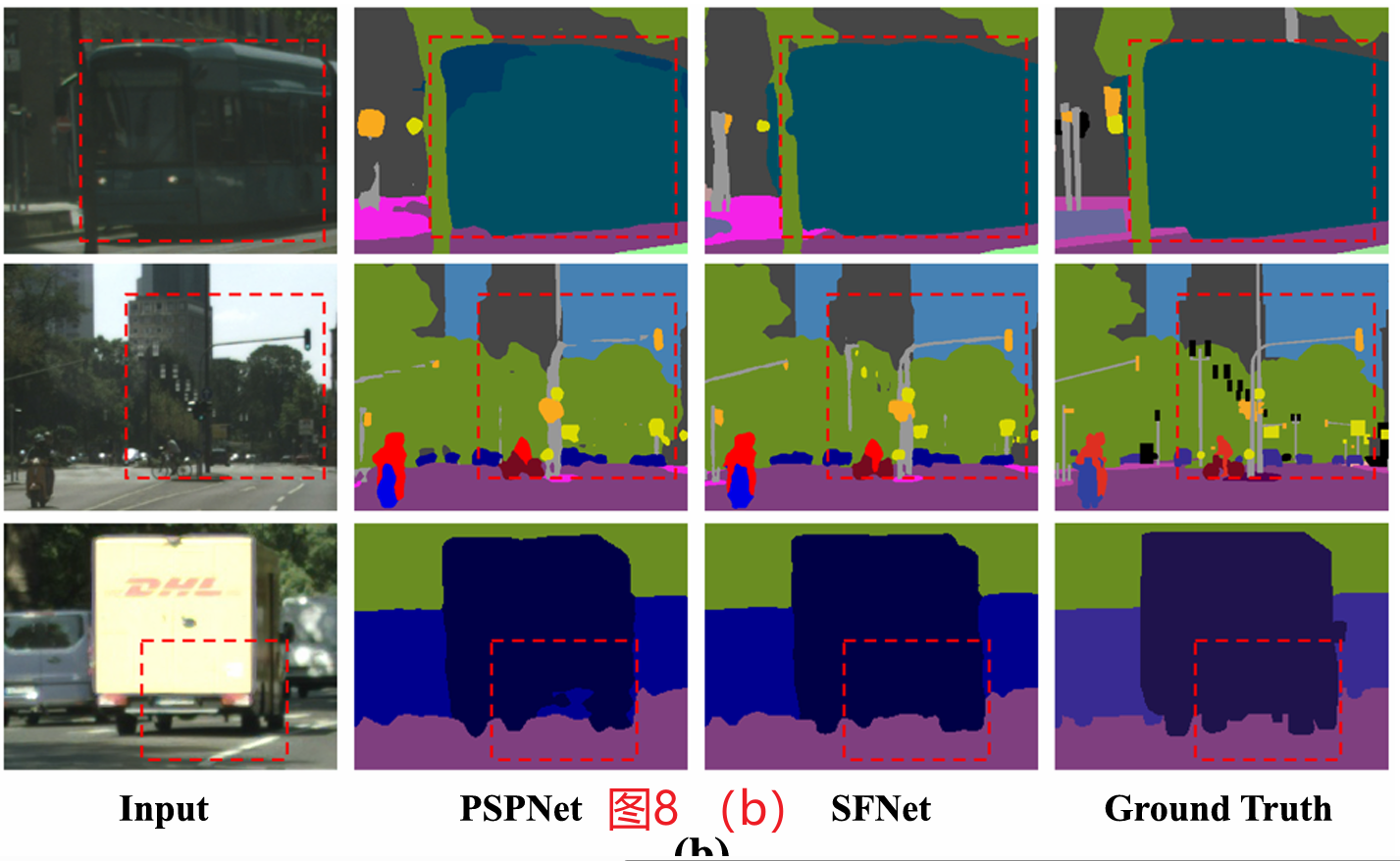
图8 b 与PSPNet (Zhao et al ., 2017)的场景解析结果比较,其中改进的区域用红色虚线框标记。我们的方法在小尺度和大尺度对象上都表现得更好
Mapillary数据集的可视化比较

图9 Mapillary数据集的定性对比。左上:原点图像。左上:BiSegNet的结果(Changqian et al ., 2018)。左下:ICNet的结果(Zhao et al ., 2018)。右下:我们SFNet-Lite的结果。改进区域用黄色方框表示。最佳彩色视图(联机彩色图)
在图9中,我们展示了Mapillary数据集上的视觉比较结果。如图所示,与之前的ICNet和BiSegNet相比,我们使用ResNet-18作为主干的SFNet-Lite在更准确的分割分类和结构输出的情况下,具有更好的分割效果。
提议的USD数据集的视觉比较

图10包括BDD、mailal、IDD和cityscape在内的UDS验证数据集的可视化结果。我们的方法在物体边界清晰、物体内部一致性和结构输出较好的情况下取得了较好的视觉效果。我们采用单尺度推理,所有模型都在相同的设置下训练。最好在屏幕上查看并放大
在图10中,我们展示了来自不同数据集的几个示例。与原来的DFNet基线相比,我们的方法在清晰的目标边界和内部目标一致性方面取得了更好的分割效果。我们还在第四行显示了带有ResNet-18主干的SFNet-Lite,在最后一行显示了重叠的图像。从图中可以看出,我们的方法(采用DFV2骨干网的SFNet和采用ResNet-18骨干网的SFNet- lite)对不同的域实现了很好的分割质量。
不同设备上的速度效应
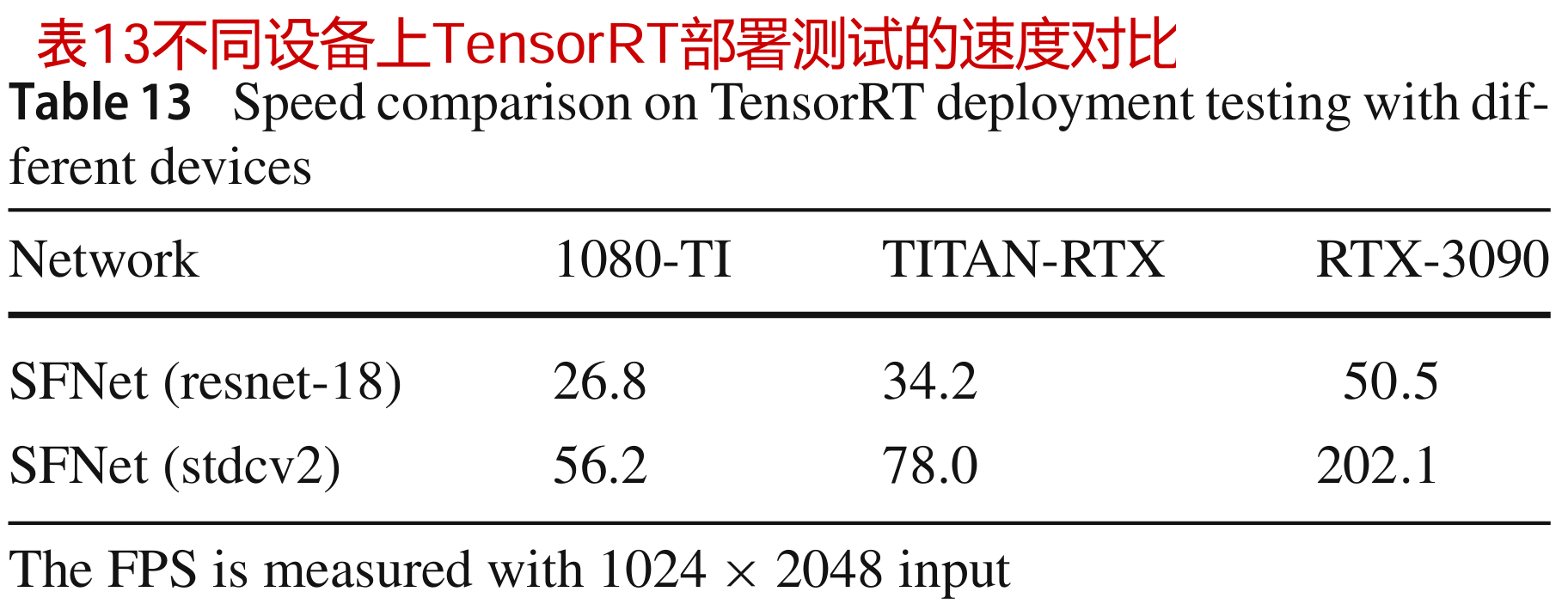
在表13中,我们探讨了部署设备的影响。特别是,与使用1080-TI作为器件的原始SFNet (Li et al, 2020)相比,使用更先进的器件可以获得更高的速度。例如,RTX-3090使用ResNet-18比1080-TI快两倍,使用STDCNet比1080-TI快四倍。此外,我们还发现具有STDCNet (Fan et al ., 2021)骨干网的SFNet对TensorRT部署更友好。
UDS用于预训练

我们在表14中进一步展示了UDS数据集的有效性。与ImageNet (Russakovsky et al ., 2015)相比,采用UDS数据集的预训练可以显著提高Camvid数据集(Brostow et al ., 2008)上的SFNet结果,这导致了显著的差距(3-4% mIoU)。这意味着UDS数据集可以作为一个很好的预训练源来提高模型的性能。
4.5 高效全视分割的扩展
实验设置
在本节中,我们将展示语义流在更具挑战性的任务Panoptic Segmentation中的泛化能力。我们选择K-Net (Zhang et al, 2021)作为预测头部,而我们的SFNet是特征提取器的主干和颈部。所有的网络首先在COCO数据集上进行训练,然后在cityscape数据集上进行训练。对于COCO (Lin et al ., 2014)数据集预训练,所有模型都按照detectron2设置进行训练(Wu et al ., 2019)。我们通过调整输入图像的大小来采用多尺度训练,最短的边至少是480和800像素,最长的边最多是1333像素。我们还在训练期间应用随机裁剪增强,其中训练图像以0.5的概率裁剪到随机矩形补丁,然后再次调整大小为800-1333像素。所有的模型都经过了36个时代的训练。对于Cityscape微调,我们用0.5到2.0的比例调整图像的大小,并在训练期间随机裁剪整个图像,批处理大小为16。所有结果都是通过单尺度推理得到的。我们还使用ResNet50骨干网报告结果以供参考。我们通过平均100个输入图像来报告V100设备上的FPS。对于FPS测量,我们还包括全景后处理时间。
城市景观全景分割中不同基线的结果
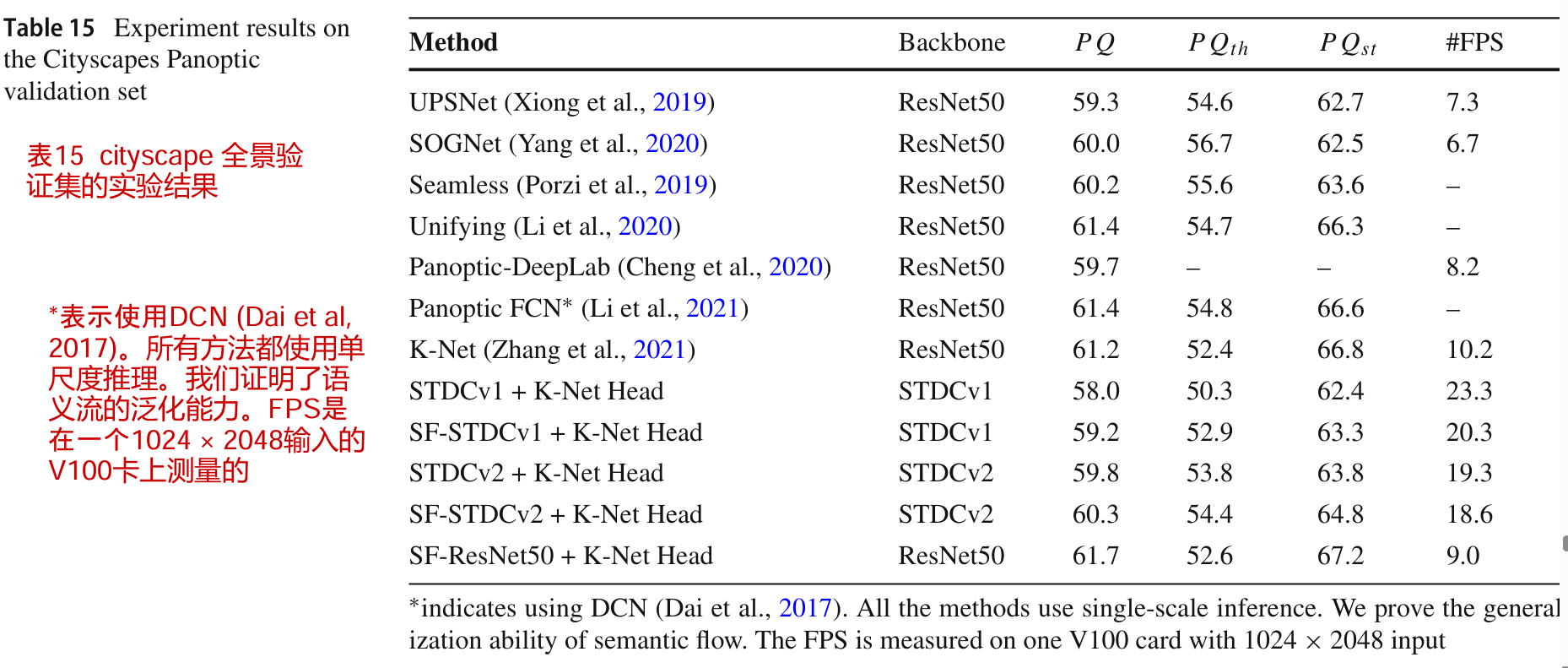
如表15所示,我们的SFNet骨干网在Panoptic Quality度量方面提高了大约0.5 - 1.0%的基线模型。结果表明,由于我们的对齐特征表示保留了更多的细粒度信息,因此语义流具有泛化能力。此外,我们使用更强的ResNet50骨干来比较我们的方法。与K-Net (Zhang et al ., 2021)相比,我们的方法在FPS下降1.2的情况下仍能实现0.5%的PQ改进。采用STDCv2骨干网的方法实现了良好的速度和精度折衷(60.3 PQ和18.6 FPS)。
4.6 SFNet和SFNet- lite的更多分析
实验设置
在本节中,我们将使用SFNets进行更广泛的实验。(1)我们首先使用cityscape和UDS,通过添加一个DCN层和一个GD-FAM,对DCN进行了更多的实验(Dai et al ., 2017)。(2)然后,利用不同SFNet基线的RobustNet进行领域泛化实验,在cityscape数据集上训练模型,并在BDD和IDD数据集上对模型进行测试。(3)接下来,我们展示了使用不同基线的ADE20k数据集的结果,包括Semantic FPN (Kirillov等人,2019)和SegFormer (Xie等人,2021)。对于ADE20k数据集的实验,我们遵循OCRNet (Yuan et al ., 2020)的默认设置,其中裁剪大小设置为512,进行160k次迭代训练。GFlops以512 × 512输入计算。
与DCN更详细的比较
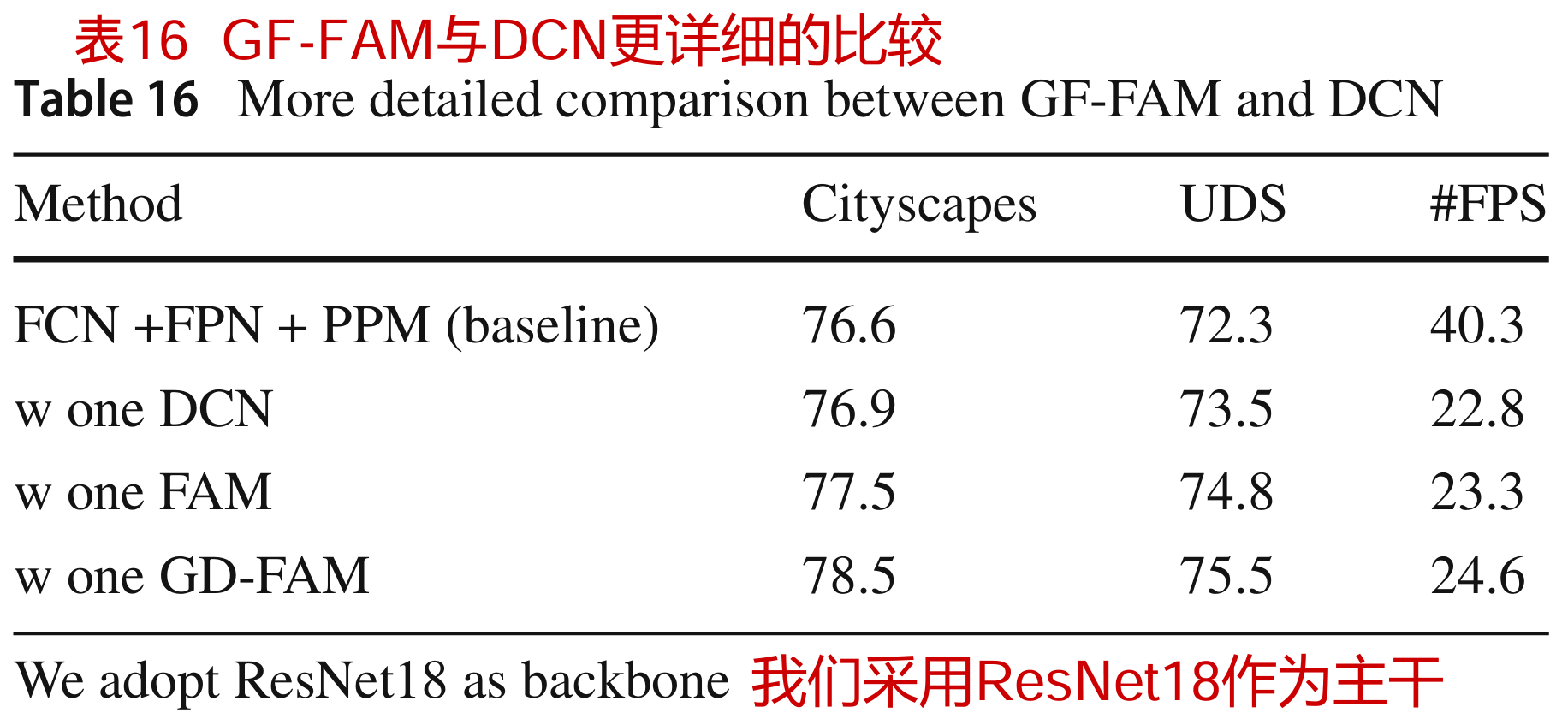
我们对DCN和我们提出的GDFAM进行了更详细的比较。特别是,我们用简单的串联替换GD-FAM或FAM,然后进行可变形卷积,其中在最后阶段插入GD-FAM和FAM以对齐最后两个特征以进行比较。DCN直接替代FAM或GD-FAM。如表16所示,我们的方法在Cityscape数据集和UDS数据集上都获得了更好的结果(1.0 - 2.0% mIoU增益),这与表9(d)的结论相同。
基于RobustNet的领域泛化测试

(Choi et al, 2021)。进一步证明了SFNet和SFNet- lite的域泛化能力。我们的方法基于之前的工作RobustNet (Choi等人,2021)和Semantic-FPN (Kirillov等人,2019)。特别是,我们遵循原始的开源RobustNet代码( https://github.com/shachoi/RobustNet)和设置,通过在不同的主干上进行白化操作来构建基线。如表17所示,我们的方法在IDD和BDD数据集上比RobustNet基线实现了一致的2-3% mIoU改进。
ADE20k数据集上的实验结果
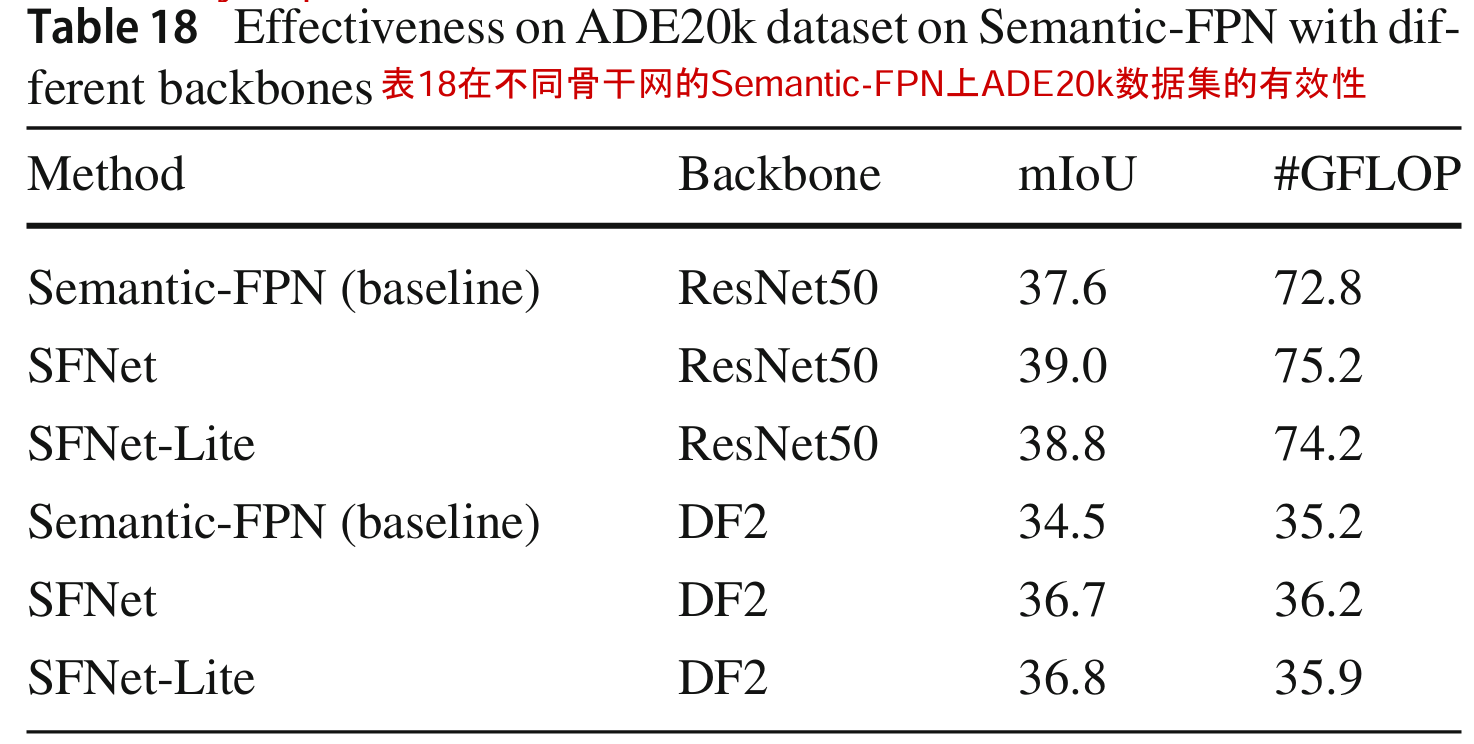
在表18中,我们在更具挑战性的数据集ADE20k上验证了FAM和GD-FAM的有效性。为了公平的比较,我们在相同的代码库中重新实现基线,并报告我们对Semantic-FPN的再现结果。如该表所示,我们发现在不同基线上的改进约为1.2% - 2.2%。特别是,我们发现实时模型的改进更强,这意味着小模型的语义缺口更大。这一发现与道路驾驶场景数据集相似(见表6,7)。
基于变压器模型的ADE20k实验结果
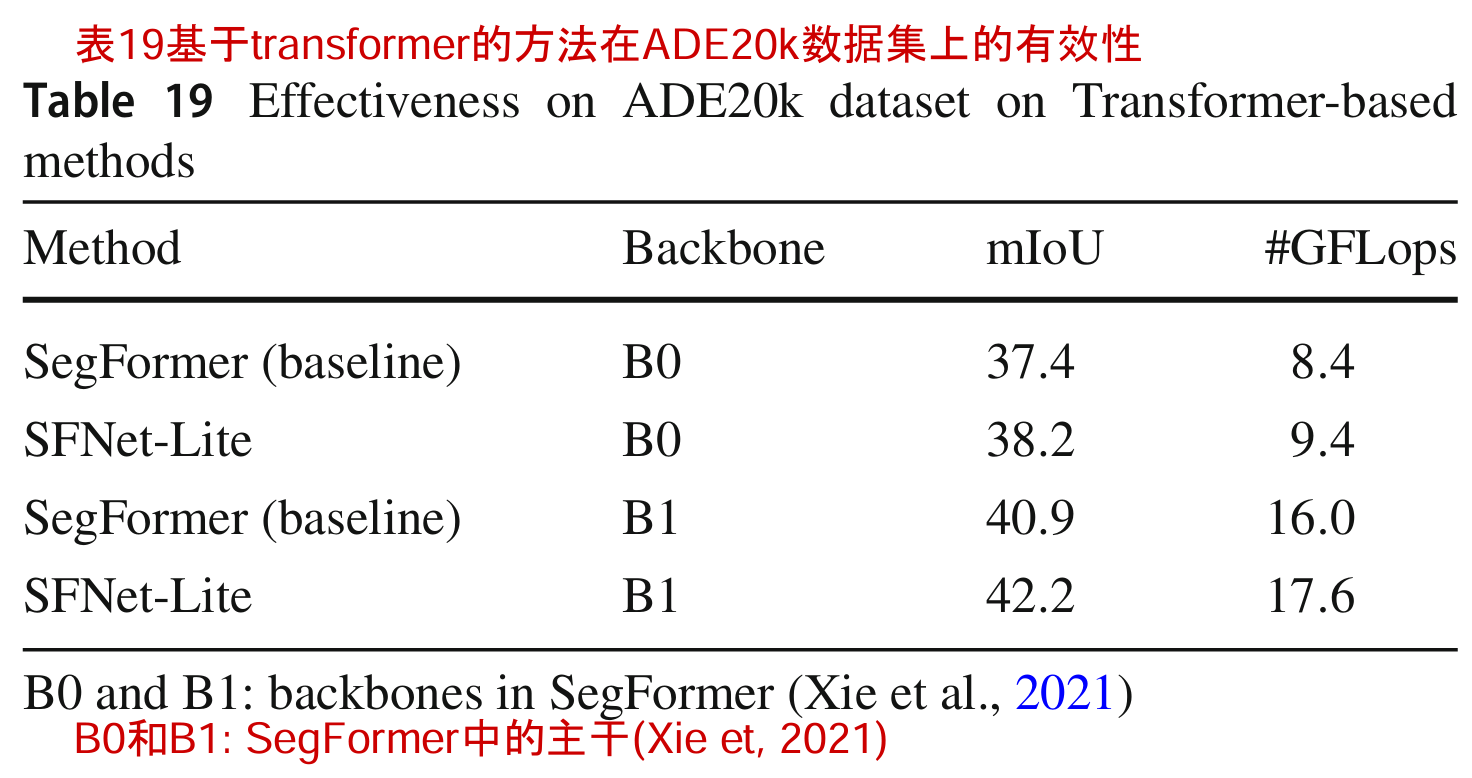
在表19中,我们还报告了使用基于变压器的模型SegFormer的结果(Xie et al ., 2021)。我们还发现在不同的主干上大约有0.8 - 1.3% mIoU的改进。这些结果表明,我们提出的方法也可以用于基于变压器的分割。
5 结论
在本文中,我们提出使用学习到的语义流来对齐由对齐特征金字塔生成的多层次特征图,用于语义分割。我们提出了一个流对齐模块来融合高级特征映射和低级特征映射。此外,为了加快推理过程,我们提出了一种新的门控双流对齐模块来直接对齐高分辨率和低分辨率的特征映射。我们的网络通过丢弃属性卷积来减少计算开销,并使用流对齐模块来丰富底层特征的语义表示,从而实现语义分割精度和运行时间效率之间的最佳权衡。在多个具有挑战性的数据集上的实验证明了该方法的有效性。此外,我们将四个具有挑战性的驾驶数据集合并到一个统一的驾驶分割数据集(UDS)中,该数据集包含各种域。我们在合并的数据集上对几个作品进行了基准测试。实验结果表明,SFNet系列可以实现速度和精度的最佳平衡。特别是,我们的SFNet在UDS数据集上大大改进了原来的DFNet (9.0% mIoU)。这些结果表明,我们的SFNet可以作为一个更快、更准确的语义分割基线。
数据可用性
本文中使用的所有数据集都可以在线获得。cityscape (https://www.cityscapes-dataset.com/benchmarks/)、BDD (https://bdd-data.berkeley.edu/)、IDD (https://idd.insaan.iiit.ac.in/)、Mapillary (https://www.mapillary.com/dataset/vistas)、Camvid (http://mi.eng.cam.ac.uk/research/projects/VideoRec/CamVid/)可在其官方网站下载。UDS数据集由这些数据集合并而成。

















 1042
1042

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









