







- 哈希表是一个通过哈希函数来计算数据存储位置的数据结构,通常支持如下操作:
insert(key,value): 插入键值对(key,value)
get(key): 如果存在键为key的键值对则返回其value,否则返回空值
delete(key): 删除键对key的键值对
直接寻址表:key为k为元素放在k位置上
- 当关键字的全域U比较小时,直接寻址是一种简单而有效的方法
![![[v2-3380c9b472c6f0fc3313cab0f4e95ffc_r.png]]](https://img-blog.csdnimg.cn/direct/d8037141f0af4c3d845680909371b68e.png)
缺点
- 当域U很大时,需要消耗大量内存,很不实际
- 如果域U很大而实际出现的key很少,则大量空间被浪费
- 无法处理关键字不是数字的情况
改进直接寻址表:哈希(Hashing)
- 构建大小为m的寻址表T
- key为kl的元素放在h(k)位置上
- h(k)是一个函数,其将域U映射到表T[0,1,···,m-1]
![![[20200422071636599.png]]](https://img-blog.csdnimg.cn/direct/bfb64e1ce55d478aafa7b221248593a1.png)
but 很有可能有两个元素同时对应一个位置——哈希冲突
解决哈希冲突——开放寻址法
- 开放寻址发:如果哈希函数返回的位置已经有值,则可以向后探查新的位置来存储这个值
- 线性探查:如果位置i被占用,则探查i+1,i+2,······
- 二次探查:如果位置被占用,则探查 i + 1 2 , i − 1 2 , i + 2 2 , i − 2 2 , i+1^2,i-1^2,i+2^2,i-2^2, i+12,i−12,i+22,i−22,······
- 二度哈希:有n个哈希函数,当使用第一个哈希函数h1发生冲突时,则尝试使用h2,h3,······
解决哈希冲突——拉链法
- 哈希表每个位置都连接一个链表,当冲突发生时,冲突的元素将被加到该位置链表的最后。
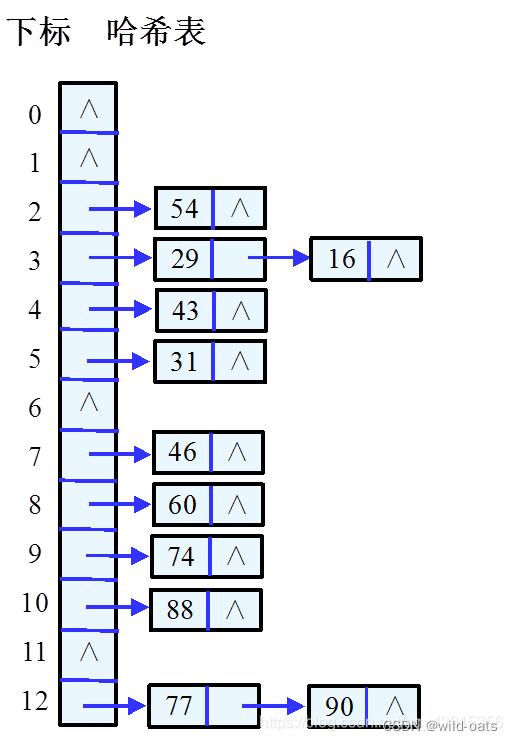
常见哈希函数
- 除法哈希法:
- h ( k ) = k % m h(k) = k \% m h(k)=k%m
- 乘法哈希法:
- h ( k ) = f l o o r ( m ∗ ( A ∗ k e y % 1 ) ) h(k) = floor(m*(A*key\%1)) h(k)=floor(m∗(A∗key%1))
- floor:向下取整
- 全域哈希法:
- h a , b ( k ) = ( ( a ∗ k e y + b ) % p ) % m h_a,_b(k) = ((a*key + b)\%p)\%m ha,b(k)=((a∗key+b)%p)%m
哈希表的应用——集合与字典
- 字典与集合都是通过哈希表来实现的
a = {‘name':'Alex','age':18,'gender':'Man'}
- 使用哈希表存储字典,通过哈希函数将字典的键应射为下标。假设
h
(
′
n
a
m
e
′
)
=
3
,
h
(
′
a
g
e
′
)
=
1
,
h
(
′
g
e
n
d
e
r
′
)
=
4
h('name')=3,h('age')=1,h('gender')=4
h(′name′)=3,h(′age′)=1,h(′gender′)=4,则哈希表存储为
[None,18,None,'Alex','Man'] - 如果发生哈希冲突,则通过拉链法或开发寻址法解决















 361
361











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









