






秦医如毒,无药可解。
话不多说,为了方便各位理解,我先建一张表。
表名:TEST。
表字段:ID,NAMES

可以看出,两者的类型都是VARCHAR2。
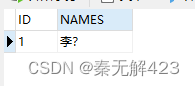
这时候我存入一个带有生僻字的名字进表,比如——李䶮(yǎn),就会出现如👇下图的乱码问题。
而要解决这样的问题,只需要三步:
第一步:将表字段:NAMES 的类型,改为NVARCHAR2,毕竟相比较VARCHAR2,NVARCHAR2所能存储的字符更丰富
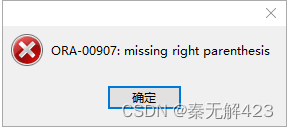
(⭐注意:如果此刻你的表中有数据,那么最好根据我👇下方的sql去修改,因为直接通过设计表修改会报异常①)
ALTER TABLE 你的表名 MODIFY 需要修改的表字段名 NVARCHAR2(64);
异常①:
第二步:将要存储的数据转为Unicode编码,转换链接在下方👇
比如我将李䶮转为Unicode编码,它们就变成了——

将里面的 \u 统一去掉,得出——李的Unicode编码 = 674e,䶮的Unicode编码 = 4dae
第三步:通过他们的Unicode编码进行数据的修改或添加操作
修改sql操作(下面的编码1和编码2就是上面的李、䶮Unicode编码,不懂没关系,下面有举例):
UPDATE 你的表名
SET 表字段名 = utl_raw.cast_to_nvarchar2(hextoraw('编码1') || hextoraw('编码2'))
WHERE 表字段名 = "xxxx";
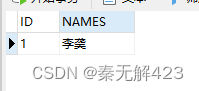
以TEST表修改举例:

修改完后,刷新一下表,已经可以展示了:
添加sql原理一样:
INSERT INTO 你的表名 (表字段名1,表字段名2)
VALUES ('XXX', utl_raw.cast_to_nvarchar2(hextoraw('编码1') || hextoraw('编码2')));
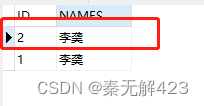
以TEST表添加举例:

刷新表,看看效果:
成功!
《此章暂时完结,撒花》

















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









