







 文章介绍了SQL中的UNION,EXCEPT,和INTERSECT三个关键字,它们用于合并和比较两个结果集。UNION用于合并结果并移除重复行,EXCEPT返回只在第一个结果集中出现的行,INTERSECT则找出两个结果集的交集。通过创建和操作两个示例表格,展示了这些操作的实际应用。
文章介绍了SQL中的UNION,EXCEPT,和INTERSECT三个关键字,它们用于合并和比较两个结果集。UNION用于合并结果并移除重复行,EXCEPT返回只在第一个结果集中出现的行,INTERSECT则找出两个结果集的交集。通过创建和操作两个示例表格,展示了这些操作的实际应用。
SQL中union,except,intersect使用方法
这三个放在一起是有理由的,因为它们都是操作两个或者多个结果集,并且这些结果集有如下限制:
所有查询中的列数和列的顺序必须相同;
数据类型必须兼容;
并且它们都是处理于多个结果集中的重复数据的问题;
下面多这三个做一下演示:
首先创建测试环境
create table temptable1(id int primary key,price int)
create table temptable2(id int primary key,price int)
insert into temptable1(1,3);
insert into temptable1(2,1);
insert into temptable1(3,2);
insert into temptable1(4,3);
insert into temptable2(1,3);
insert into temptable2(2,4);
insert into temptable2(3,1);
insert into temptable2(4,2);
两张表的初始结果:
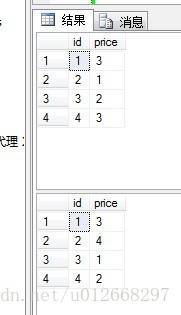
非常简单的两张表,列数和列顺序一样,而数据中有一条数据相同,这里的相同是完全相同,包括主键。
1、先来看看union和union all
select * from temptable1 union select * from temptable2
select * from temptable1 union all select * from temptable2
union all是完全整合两个结果集,而union会去掉重复的,所以第一个查询语句中{id:1,price:3}只显示一条,
结果如图:
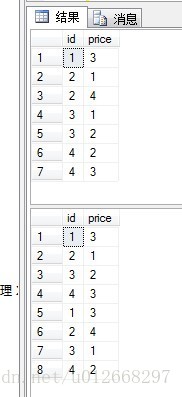
2、再来看看except
select * from temptable1 except select * from temptable2
也是去重的,但是它是在去掉两个或者多个结合中重复数据之后,只会保留第一个结果集中的数据;
其实就是查询表A,看表A中的数据在表B中是否存在,如果存在就删除
结果如图:
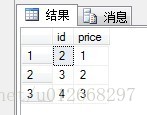
3、intersect就是查询两个结果集的交集,利用上面的数据查询到的结果只有一条,就是{id:1,price:3}
select * from temptable1 intersect select * from temptable2
结果如图:

















 1143
1143

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









