









目录
一.外部排序
1.外部排序的原理
若想清楚外部排序的原理,还需要知道外存与内存之间数据交换的过程:
这里的外存是指磁盘(机械硬盘)。操作系统以“块”为单位对磁盘存储空间进行管理,如:每块大小1KB。各个磁盘块内存放着各种各样的数据。
若想修改磁盘中某个磁盘块的数据,就需要将数据读到内存中,也就是在内存中开辟一块内存空间(缓冲区)用于存放磁盘块的数据(缓冲区的大小和磁盘块的大小可以保持一致)。并将要修改的磁盘块的数据读到内存中相应位置。磁盘的读/写以"块"为单位,数据读入内存后才能被修改,修改完了再写回磁盘中。
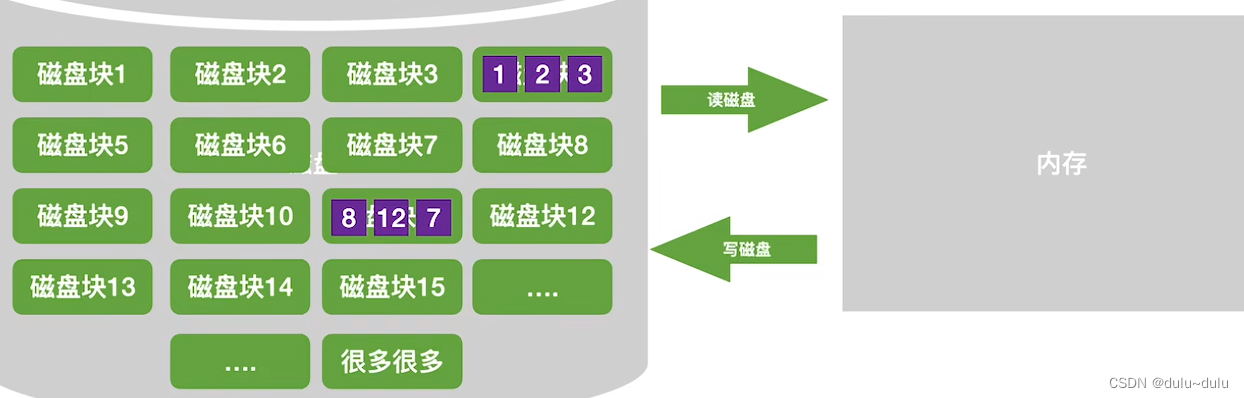
由于磁盘中存储的数据很多,容量很大,而内存的容量很小,如果想对存在外存的数据进行排序,就不能像之前博客:
中的排序算法那样,直接对数据元素进行排序,这就是为什么需要单独讲解外部排序。
外部排序算法的原理:
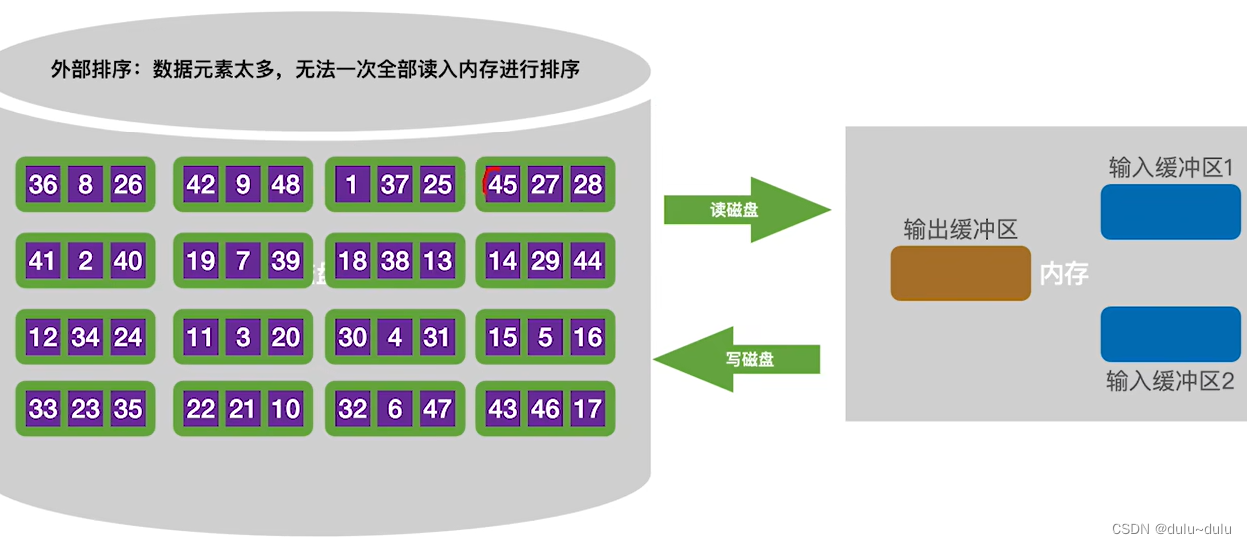
外部排序算法使用了“归并排序”的方法,最少只需在内存中分配3块大小的缓冲区即可对任意一个大文件进行排序。
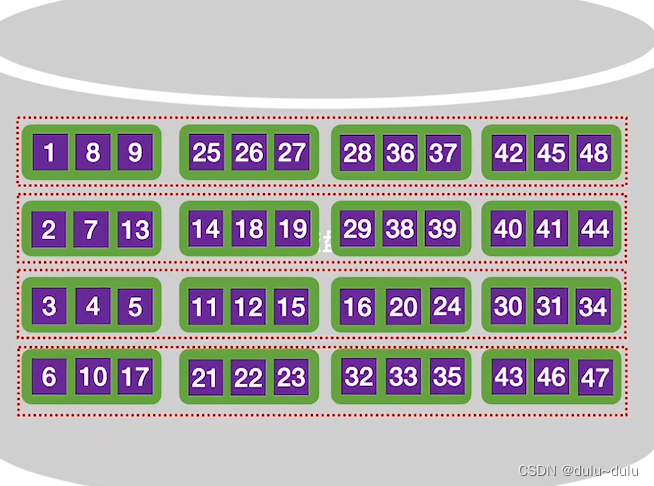
假设外存中有16个磁盘块,每个磁盘块中包含3个记录。现在想使用外部排序,将磁盘中的数据序列变为递增序列:
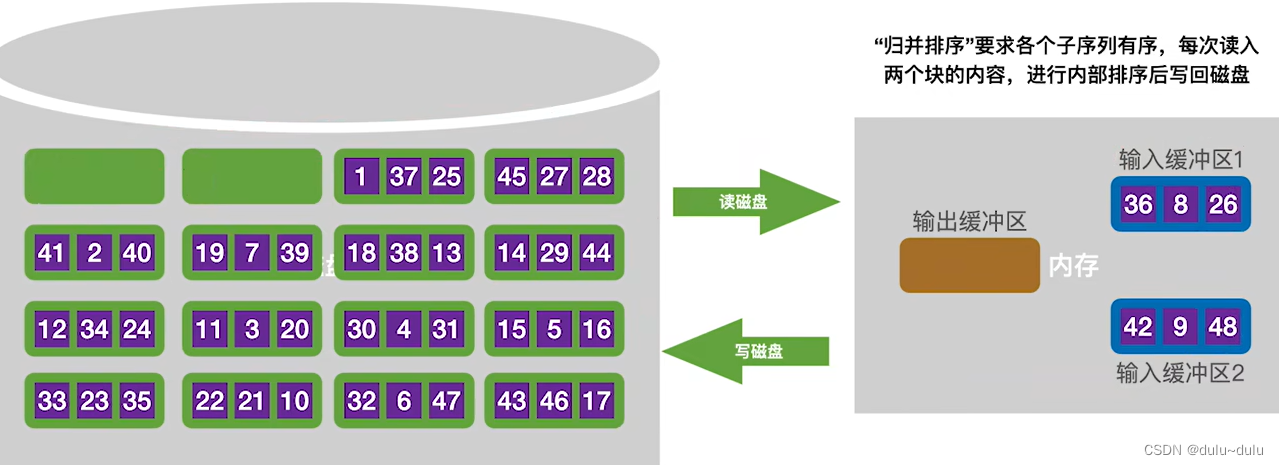
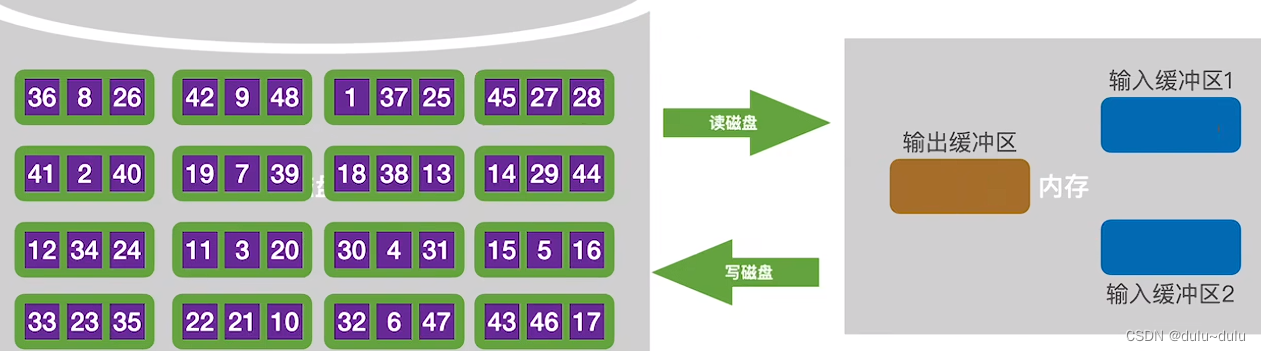
① 首先,将磁盘块中第一块与第二块的数据读入内存,将两块数据进行内部排序再写回磁盘。
内部排序的结果如下:两个内存块连起来是一个递增序列。
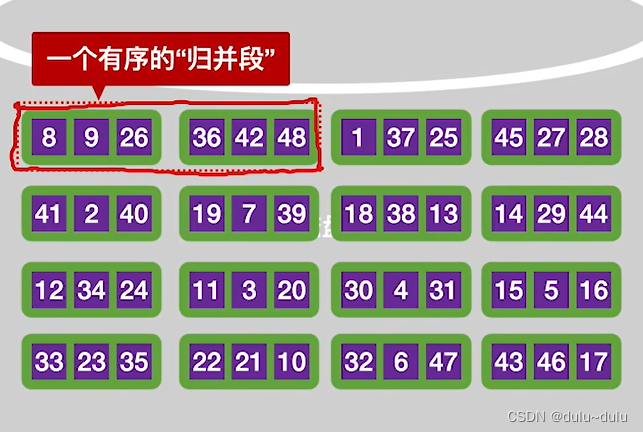
将输入缓冲区的数据通过输出缓冲区依次写回磁盘中。第一个磁盘块和第二个磁盘块的记录已经是有序的了,之后就可以使用有序的子序列进行归并排序了,这样的有序子序列被称为"归并段"。
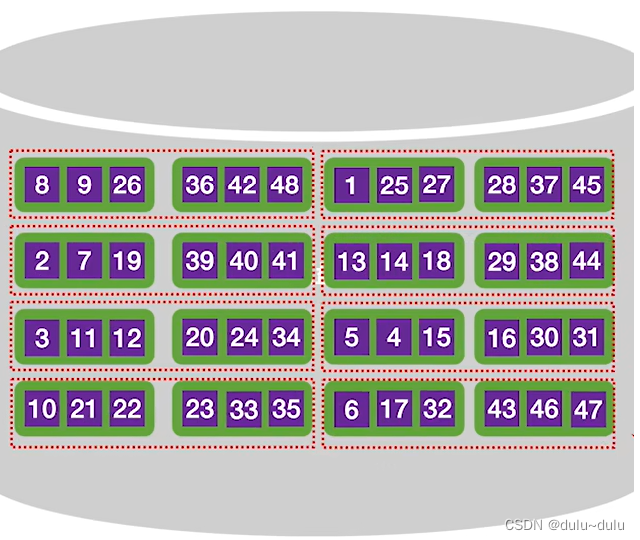
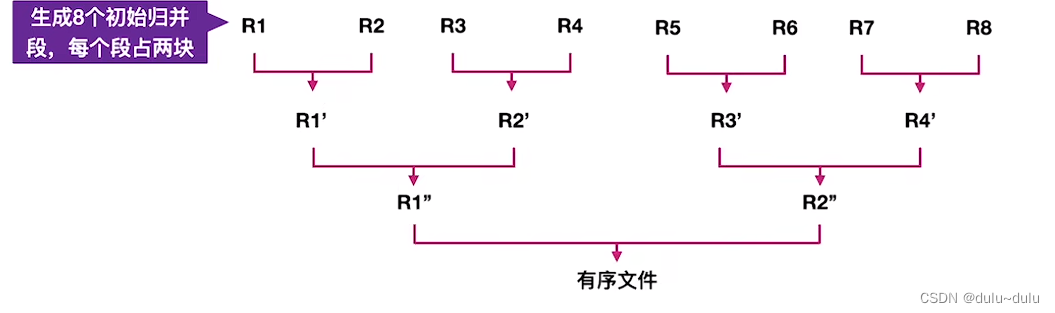
依次类推,就可以在外存中构造8个初始"归并段",每一个归并段需要"读/写"两次,所以8个归并段需要读/写16次。
接下来就可以使用有序的初始"归并段",进行归并排序了:
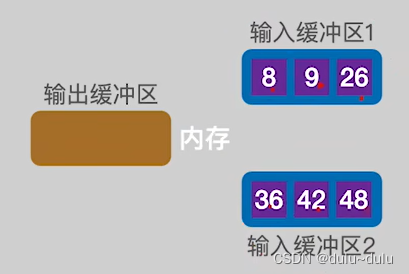
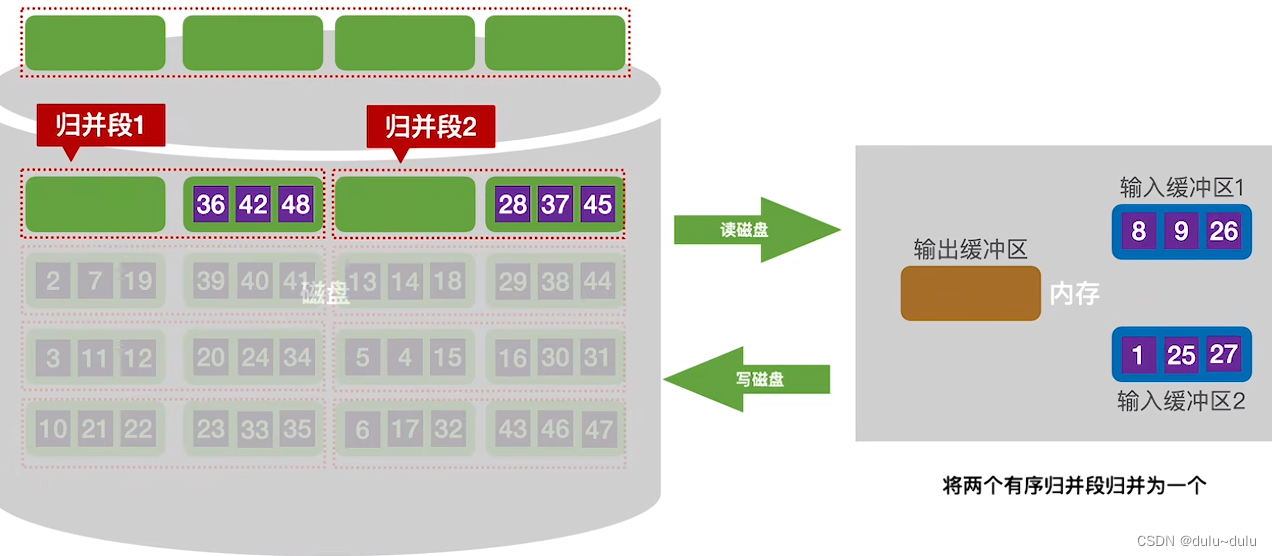
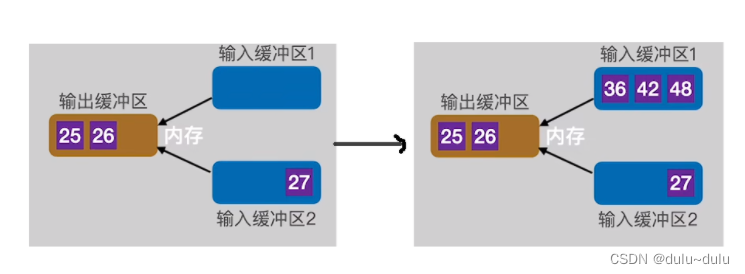
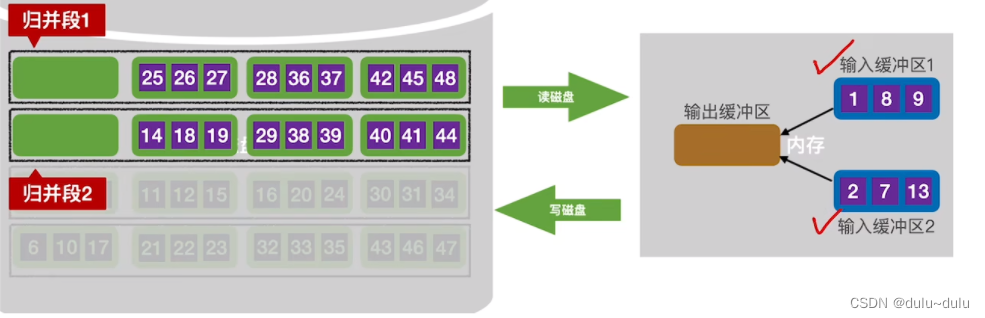
① 在第一趟归并中,会将"归并段1","归并段2"中更小的磁盘块读入内存:
读入内存后,这2份数据的归并就变为了内部的归并排序(归并排序上一篇博客讲过),由于磁盘的读写,都是以1KB为单位,所以输出缓冲区凑到1KB后就需要写回磁盘。
注:写回磁盘的数据被放到磁盘的另外一片空间中,以前磁盘中存储数据的空间会归还给系统。
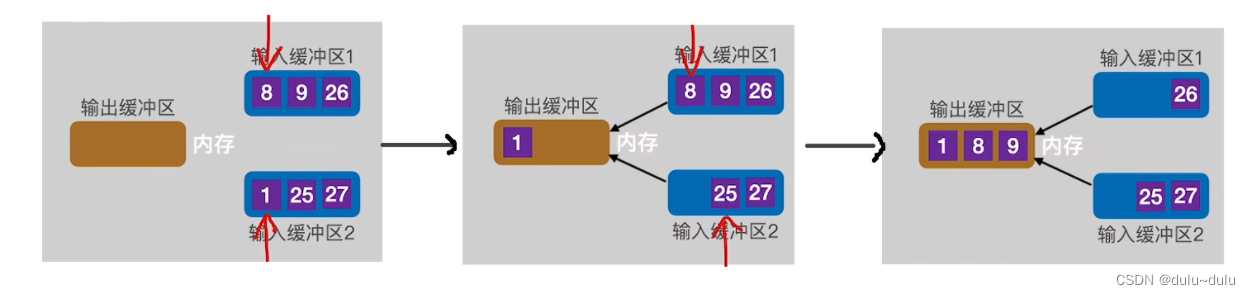
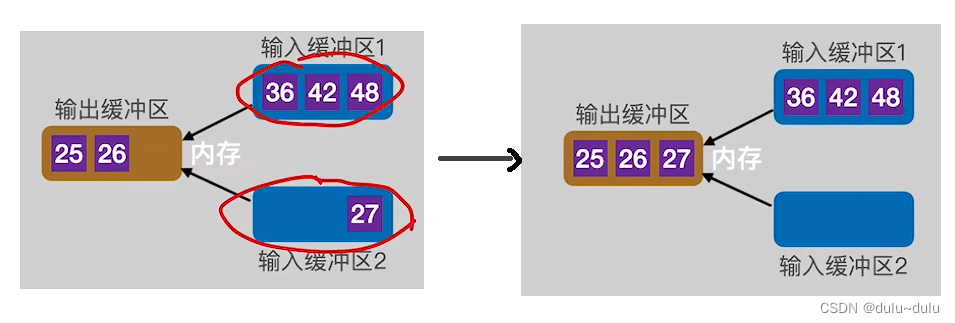
输出缓冲区的数据写回磁盘后,继续通过归并排序往里面写入剩下的数据。如下图所示,输入缓冲区1的数据会先空,当输入缓冲区1的最后一个数据写入输出缓冲区时,需要立即用"归并段1"的下一块补上。这样才能保证输入缓冲区1中包含 归并段1中暂时没有被归并,并且数值最小的记录。
一定要立即放入才能继续进行归并。下图中,若输入缓冲区1中补上的下一块数据第一个元素比27小,那么先被放进输出缓冲区的是输入缓冲区1的数据,而不是输入缓冲区2的数据。
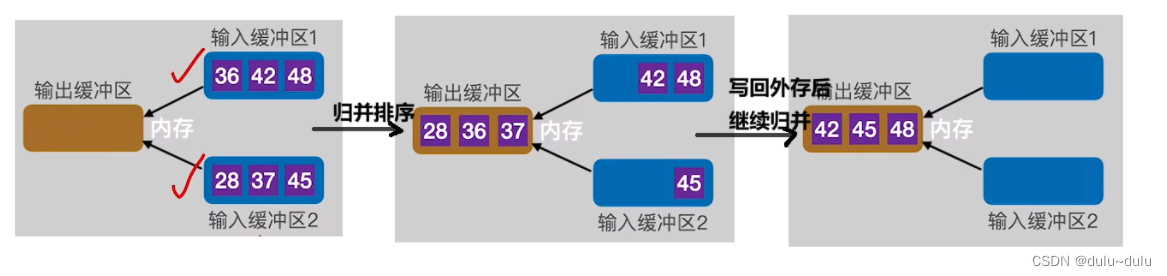
继续使用归并排序,将两个部分的数据进行归并,输出缓冲区写满,写回磁盘,输入缓冲区空,补上“归并段2”的下一块数据。
依次类推,继续进行下一轮归并:
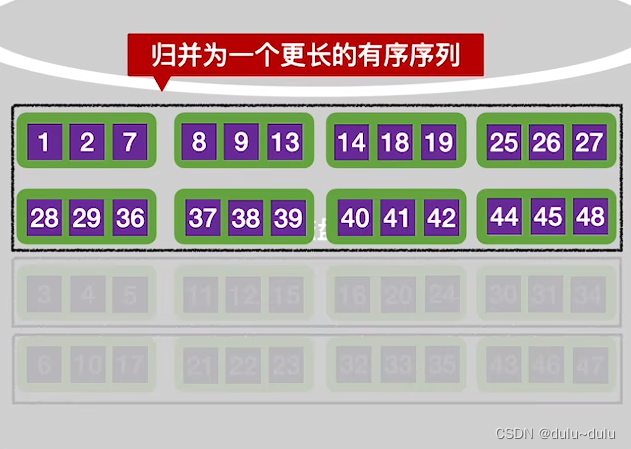
经过第一趟归并后,两个归并段并为了一个归并段:
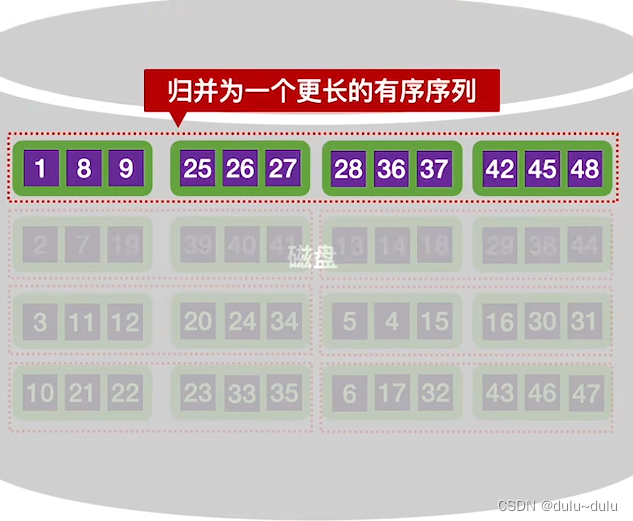
之后的"有序归并段"的操作也一样,两两进行归并,得到更长的有序序列:
②第二趟的归并中,会把上述的4个有序归并段两两归并。归并操作和 ① 是一样的。
经过归并排序后,可得到更长的有序序列。再次提醒这里数据存放的磁盘空间已经不是以前的磁盘空间了,以前的磁盘空间已经被系统回收了:
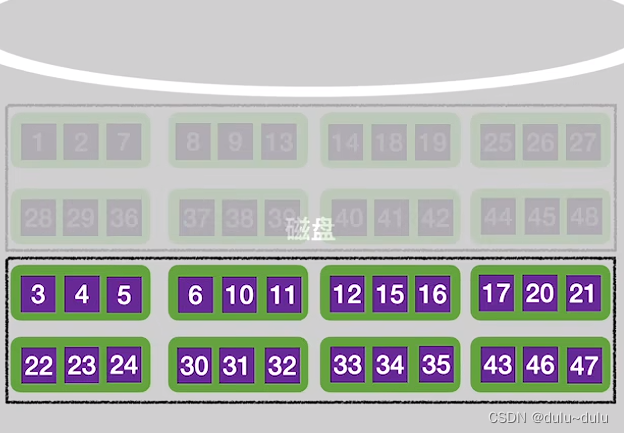
同理,下面两个归并段也归并为一个更长的归并段:
③第三趟的归并只需要再将两个有序“归并段”进行归并即可:
可以注意到输入/输出缓冲区的作用:
① 排序的内存工作区,例如m路平衡归并需要m个输入缓冲区和1个输出缓冲区,用以存放参加归并的和归并完成的记录。
② 在产生初始归并段时用作内部排序的工作区。
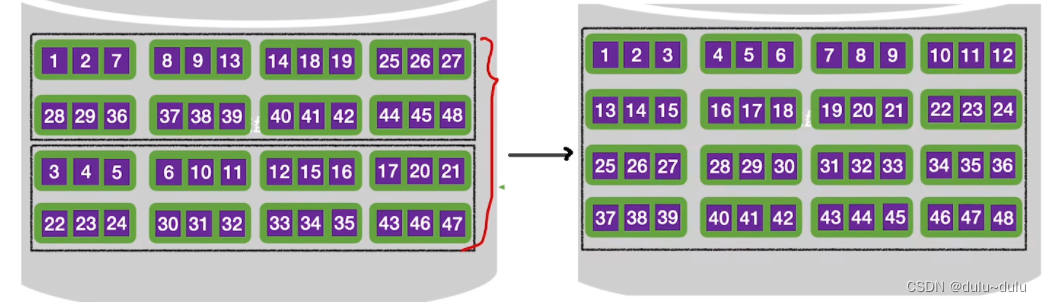
总结:
① 生成初始"归并段",在上面例子中,我们得到了8个初始归并段,每个归并段占两块,这是因为在例子中只分配了两块大小的输入缓冲区,所以每次只能读入2块的数据,对他们进行内部排序后,再放回磁盘。
如果分配的内存缓冲区更大的话,那么得到初始归并段的长度也会更长:
② 进行3趟归并,每一趟归并会根据上一趟归并的结果,将两个有序的归并段归并为更长的有序序列:
2.外部排序时间开销的分析
经过上面例子的演示可以发现,每一趟的归并都需要将16块数据都分别读入内存,归并完后再写回外存。所以每一趟归并,读/写磁盘块的次数都是16次。
所以外部排序的时间开销=读写外存的时间+内部排序的时间(生成初始归并段的时间)+内部归并的时间(对两块有序的"归并段"进行归并的时间)。
其中读写外存的时间是占大头的,因为外存是慢速设备,所以对外存的读写相比于内存中的处理慢很多。减少读写外存的时间可以有效提升外部排序的效率,那么怎么做呢?首先分析一下读写外存的时间:
读写外存的时间和读写磁盘的次数是成正比的。在进行内部排序时,读/写磁盘的次数分别为16次(总共16个磁盘块),总共32次读写;3趟归并中,每一次都要读/写磁盘16次(读入内存16次,写回磁盘16次)。所以:
读写磁盘的次数=32+32*3=128次。
若每次读/写磁盘都需要10ms的时间,那么读写磁盘的时间为1280ms,也就是1.28s
由分析可知,读写次数(32)是没有办法改变的,因为他和磁盘块的数量是直接相关的,所以只能改变归并的趟数,只要归并趟数减小,读写磁盘的次数就会减小,相应的外部排序时间开销也会减小。
3.外部排序的优化
上面讲到,减少归并的趟数,就能减少外部排序的时间开销。
(1)多路归并
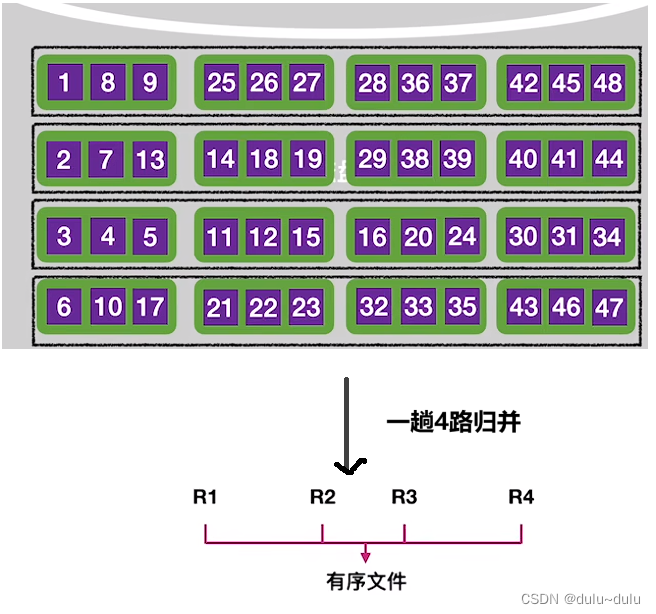
如下图所示,如果采用4路归并,就需要在内存中分配4个输入缓冲区,并把4个“归并段”的数据分别读入到4个输入缓冲区中。
注:这里采用的"初始归并段”仍然是两个磁盘块读入内存,进行内部排序,再放回磁盘的结果。当然可以将4个磁盘块一起放入内存,进行内部排序,形成“初始归并段”,后面会讲。
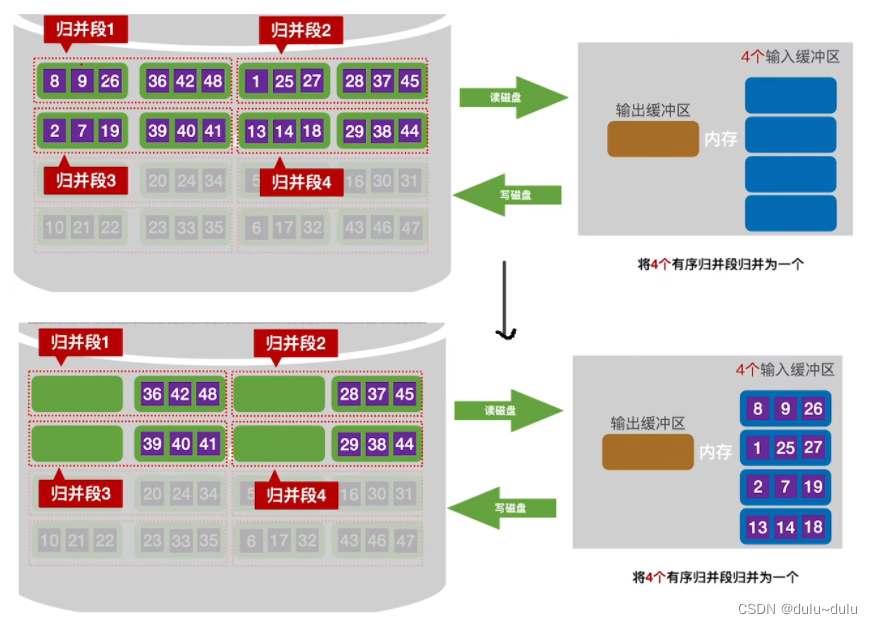
每一次从4个输入缓冲区中挑选最小的数据元素,放入到输出缓冲区中,以此类推。和二路归并的逻辑一摸一样。
注:写回外存一定是写到另一片存储空间中,以前的存储空间会被系统回收。
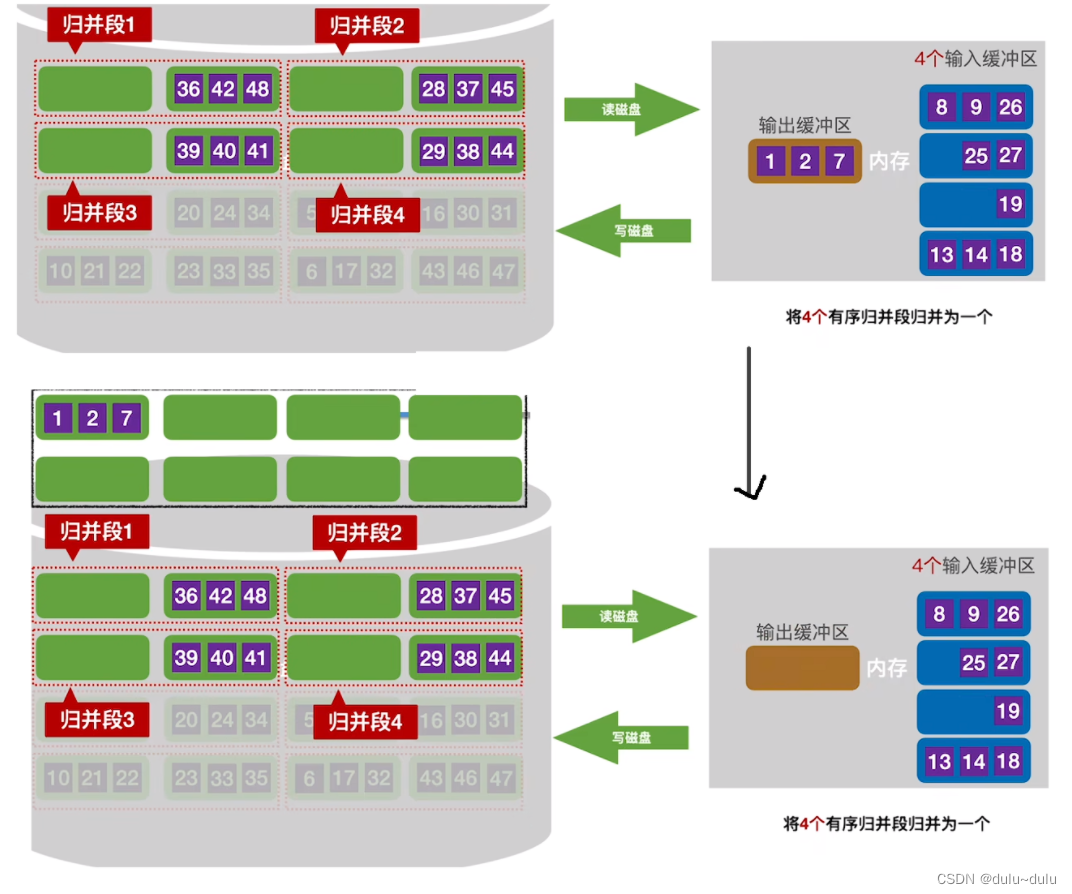
经过一次四路归并后,可以将上面4个归并段合并为更长的有序序列 :
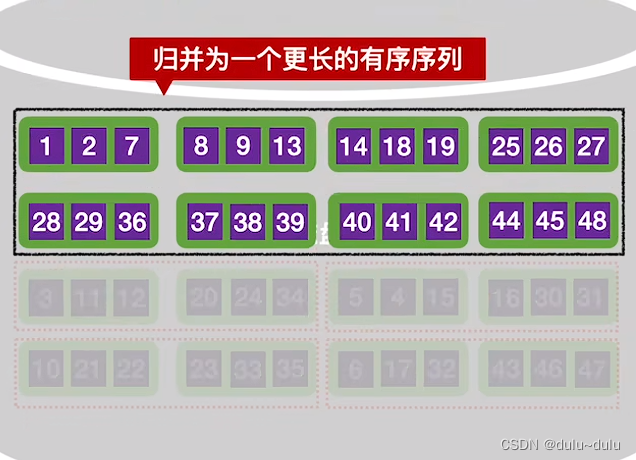
下面的4个归并段同理,在进行第一趟归并后,整个文件就只有两个归并段了。再对2个归并段进行二路归并就能得到整体有序的文件了。
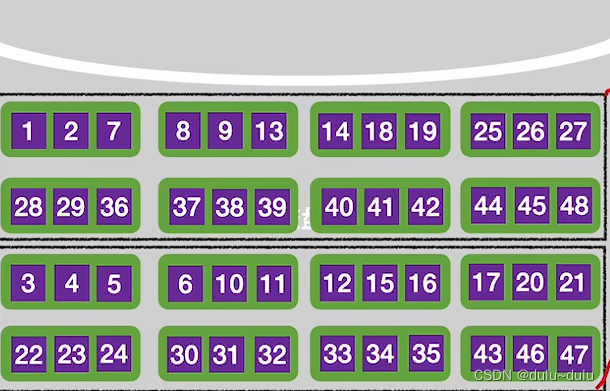
总结:
如果采用4路归并的话,归并趟数减少为2趟,这种情况下读写磁盘的次数:
32+32*2=96次
所以,采用多路归并可以减少归并趟数,从而减少磁盘I/O(读写)次数。
对r个初始归并段,做k路归并,则归并树可用k叉树表示:
k叉树第h层最多有个结点,则
,(h-1)最小=
(忘记了自己回顾一下树的性质喔)
若树高为h,则归并趟数=h-1=,k越大,r越小,归并趟数越少,读写磁盘次数越少。所以从这个公式可以看出,除了提高归并的路数k,还可以减少初始归并段r的数量。
但是并不是k越大越好,多路归并也会带来一些负面影响:
① k路归并时,需要开辟k个输入缓冲区,内存开销增加。(典型的空间换时间)
② 每挑选一个关键字需要对比关键字(k-1)次,内部归并所需时间增加。针对这个问题可以使用“败者树”减少关键字比较次数,后面会讲。
(2)减少初始归并段数量
在上面例子中,在构造“初始归并段”的阶段,我们完全可以将4个磁盘块分别读入4个输入缓冲区,进行内部排序后,再分别通过输出缓冲区写回外存。
也就是,若共 N 个记录,内存工作区可以容纳 L 个记录,则初始归并段数量 r= N/L。在这里 r 完全取决于内存工作区的大小,之后会讲到“置换-选择排序”可以突破这一限制。也就是生成更长的归并段,从而减少归并段的数量。
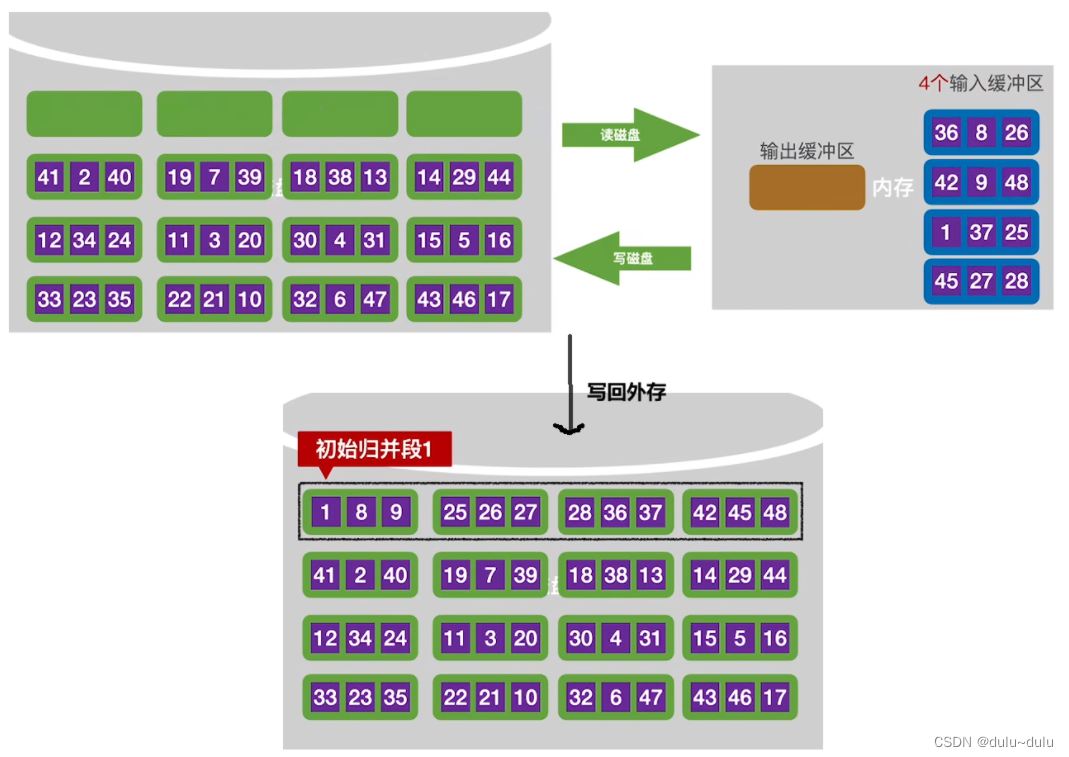
这样,一个"初始归并段"就包含了4块磁盘块的数据,初始归并段就只有4个。接下来只需要对这4个“初始归并段”进行1趟的4路归并即可。
所以生成“初始归并段”的“内存工作区”越大,初始归并段越长。归并段的长度越长,在磁盘块总数不变的情况下,归并段的总数r就会越少。由归并趟数=h-1=可知,r越小,归并趟数越少,外部排序的时间开销就越小。
补充:k路平衡归并
什么是k路平衡归并:
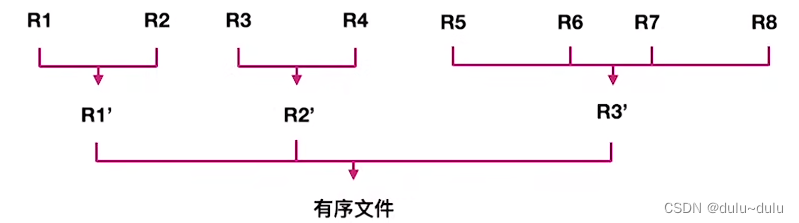
① 最多只能有k个段归并为一个;
② 每一趟归并中,若有 m 个归并段参与归并,则经过这一趟处理得到
个新的归并段。
例如上图,可以称为4路归并排序,但是不能称为4路平衡归并排序。因为在第一趟归并中有8个初始归并段参与归并,但在一趟处理后得到了3个新的归并段。
而对4路平衡归并排序而言,如果初始有8个归并段,经过一趟处理后应该只生成2个归并段,而不是3个归并段:

多路平衡归并的目的是减少归并趟数,因为当m个初始归并段采用k路平衡归并时,所需趟数s=
,若不采用多路平衡归并,则其归并趟数大于s。
二.败者树
外部排序时间开销= 读写外存的时间 + 内部排序所需时间 + 内部归并所需时间
上面说过,归并趟数S=,归并路数k增加,归并趟数S减少,读写磁盘的总次数就能减少,进而减少外部排序时间开销。
但是使用k路平衡归并策略,选出一个最小元素需要对比关键字 (k-1) 次,这就导致内部归并所需时间增加。
例如下图,采用8路平衡归并,从8个归并段中选出一个最小元素需要对比关键字7次。

对于上面的问题就可以使用败者树进行优化,败者树可以使k个归并段中挑出最小关键字所需要的关键字对比次数更少。
什么是败者树?
败者树----可视为一棵完全二叉树(比完全二叉树多了一个头)。k个叶结点分别是当前参加比较的元素,非叶子结点用来记忆左右子树中的“失败者”,而让胜者往上继续进行比较,一直到根结点。显然k个叶子结点需要进行7次比较。
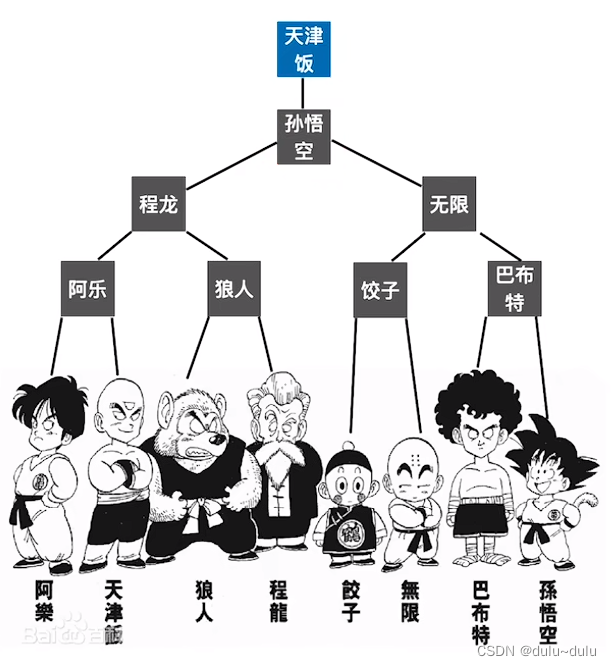
若此时“天津饭”退出比赛,由“派大星”顶替“天津饭”,是否又需要进行7次的比较呢?其实不用,右边部分已经比较过了所以不用再比了。只需要将"派大星VS阿乐",若"派大星"赢了,"派大星VS程龙",若"派大星"又赢了,那么"派大星VS孙悟空"即可。
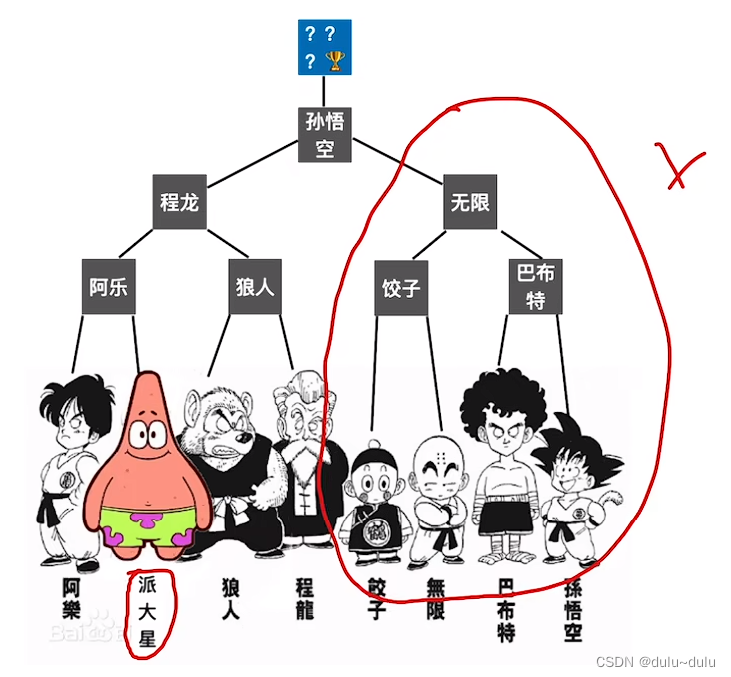
所以,基于已经构建好的败者树,选出新的胜者只需进行 3场比赛。
怎么用败者树再多路平衡归并中减少关键字的比较次数?
若按照以前的思路,每次从8个归并段中选出一个最小的关键字,都要进行7次关键字对比:

若使用败者树,如下图所示,败者树的每一个叶子节点对应每个归并段的第一个元素:
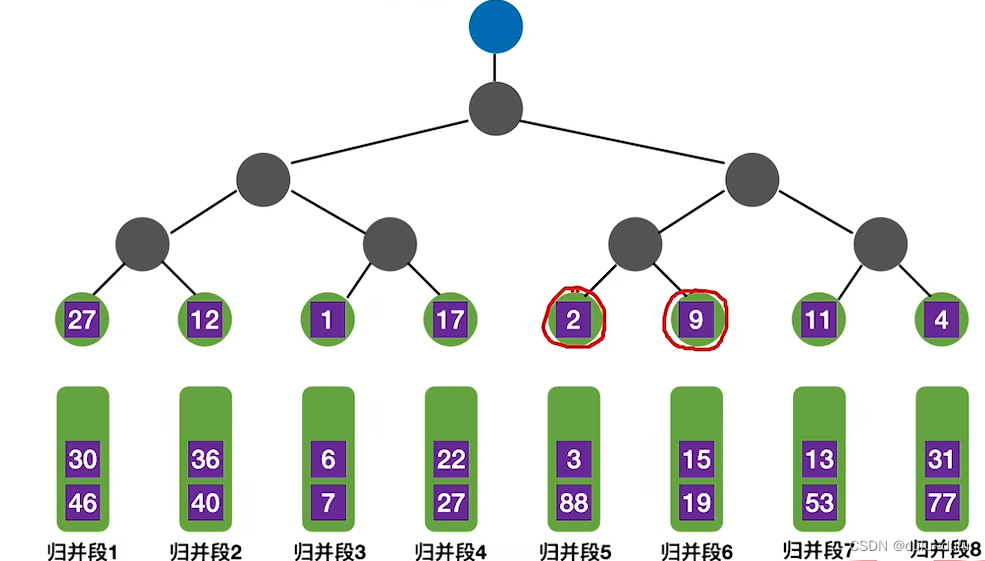
第一轮:
对败者树的节点进行两两比较,选出两者中关键字的值更小的一个:
如下图所示,① 27>12,所以27停留在了叶子节点的上一层,而更小的节点12则晋级到更上一层;② 1<17,所以17留在了叶子节点的上一层,而1则晋级到了更上一层;③ 1继续与12继续比较,1<12,所以12留在了这一层,1晋级到了更上一层,以此类推。
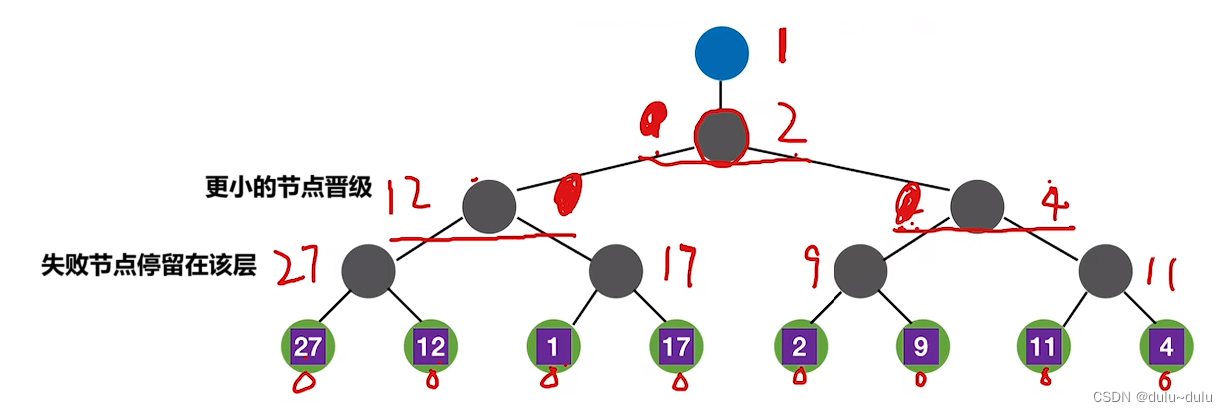
在败者树中,我们会记录节点来自于哪一个归并段,也就是只需要记录归并段的编号,不需要把实际的数据元素记录到节点中。
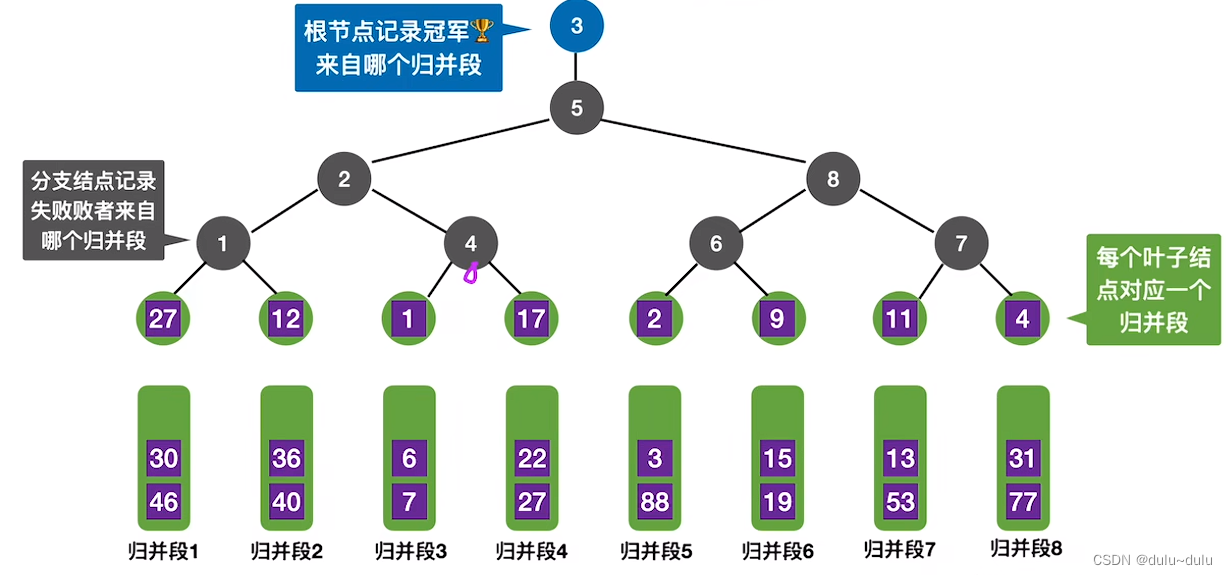
第一轮通过7次关键字对比后,找到了最小的关键字的值,即来自归并段3的第一个元素"1"
第二轮:
将归并段3的第二个元素“6”替代原本"1"元素的位置:
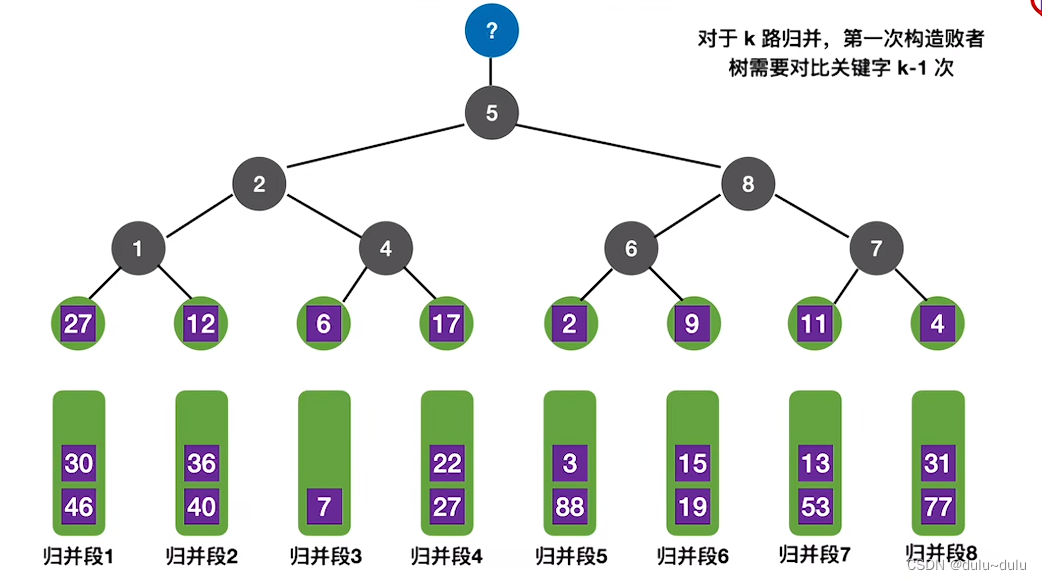
这时,若要选出更小的关键字的值,只需要① 将新元素"6"与归并段4的最小元素"17"进行对比,6<17,② 再让"6"与归并段2的最小元素"12"(最小元素看对应段的叶子节点)进行对比,6<12,③ 所以再将"6"与归并段5的最小元素"2"对比,6>2,所以归并段5的关键字的值更小。
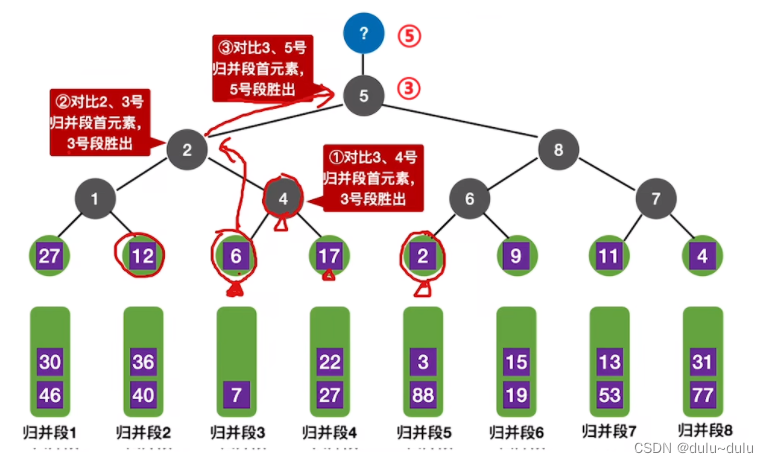
由此可以得到败者树的两个特性:
1.败者树从下往上维护,每上一层,只需和失败结点比较1次。
2.败者树的每次维护,必定要从叶结点一直走到根结点,不可能从中间停止。
这里可以和堆比较一下,堆的每次维护,不一定要走到叶结点,若某层无需调整,就停止了。
第二轮中,在剩余节点中继续选择最小的数据元素,只需要进行3次对比。刚好和灰色节点的层数相同。
所以:
对于k 路归并(第一次构造败者树需要对比关键字 k-1次;有了败者树,选出最小元素,只需对比关键字
次。
假设k路归并对应的败者树树高为h(这里的h不包括最上面的头),对于1棵完全二叉树,第h层最多有个节点,k路归并的败者树叶子节点为k,所以
。
所以h-1=,对比的次数刚好和分支结点(下面的灰色结点)的层数相同,分支节点的层数为h-1,所以关键字对比次数=
。

假设需要进行1024路归并,按照传统的方法,每次从1024个关键字中挑选最小的关键字,需要1023次对比,而采用败者树,只需要,也就是10次对比。很显然,大大减少了关键字对比的次数。
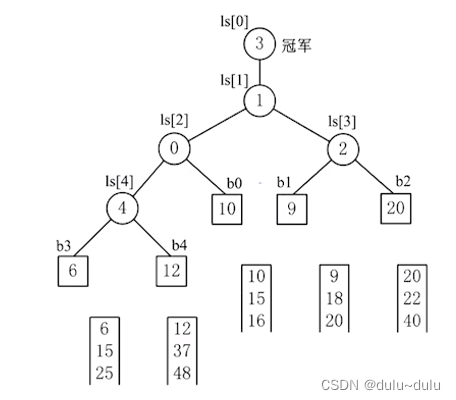
注意:其实是关键字对比的上限。在如下图所示的五路归并的败者树中:
但是,若填补的新元素在b0,b1,b2的位置,他们中间的分支节点只有2层,只需要对比2次,对于b3,b4位置填补的新元素,则需要对比3次。
三.置换-选择排序
上面讲过,若共 N 个记录,内存工作区可以容纳 L 个记录,则初始归并段数量 r= N/L。 r 完全取决于内存工作区的大小,可以用“置换-选择排序”可以突破这一限制。也就是生成更长的归并段,从而减少归并段的数量。
假设要构造递增的归并段,初始待排序的文件有24个记录,内存工作区只能容纳3个记录。若用之前的方法,那么生成的初始归并段有24/3=8个,每个归并段中有3个记录。
而使用”置换-选择排序“
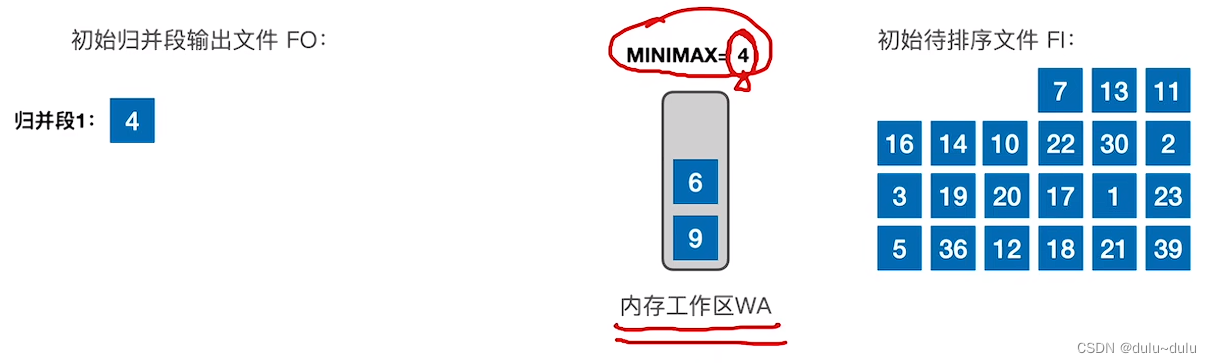
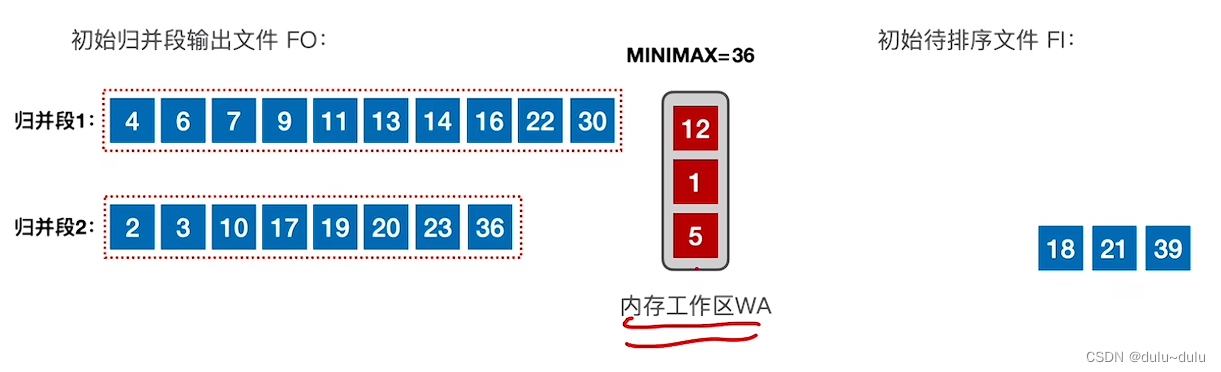
① 首先内存工作区中会读入3个记录,并把最小的元素“置换”出去,放到归并段1中。用MINMAX记录这个最小元素的值。
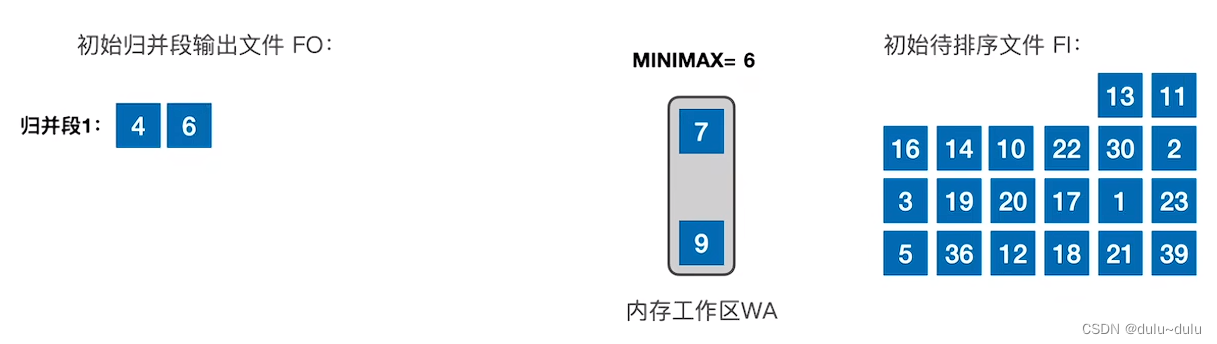
② 内存工作区有一个空位,所以会从待排序文件中读入一个记录7,对比三个记录,6的值最小,并且6>4,所以把6页放到归并段1中。
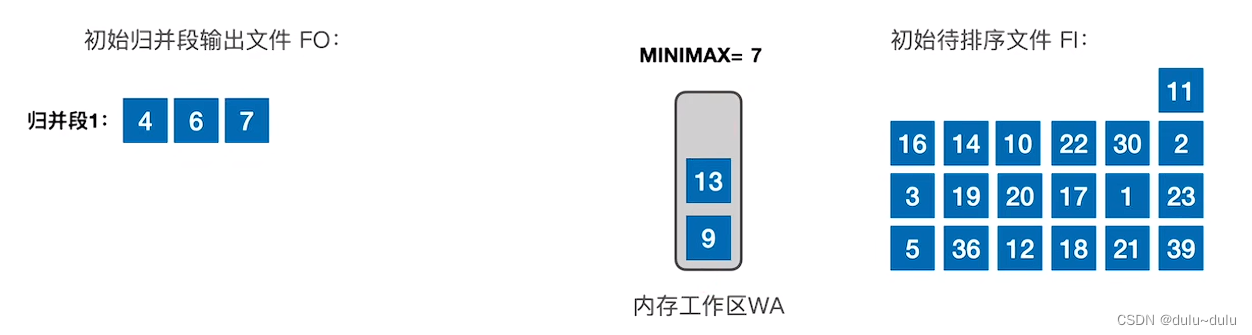
③ 以此类推,不断读入记录,并放到归并段1中。
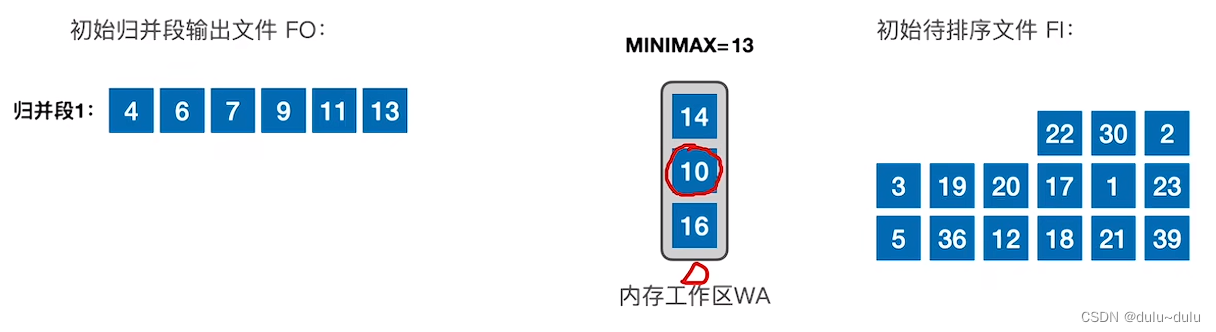
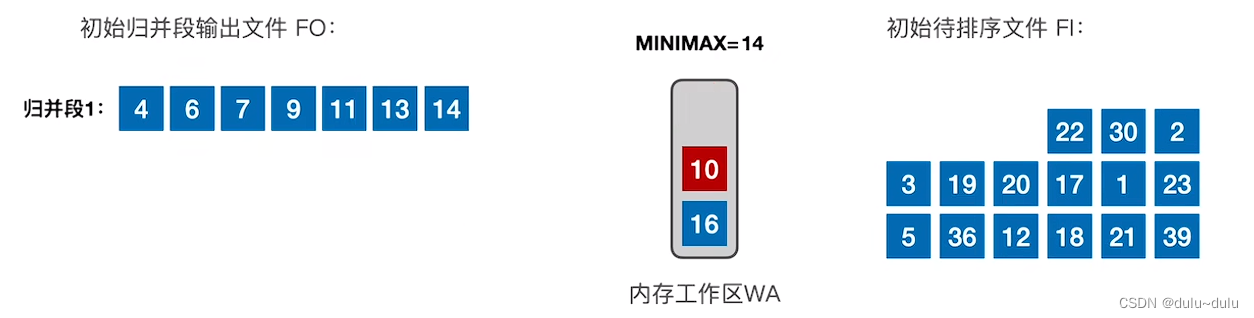
④ 放入记录10的时候,3个记录中最小的元素是10,但是通过MINIMAX的记录我们可以知道,之前放到归并段1中的记录是13,13>10,所以不能把10放到归并段1的末尾(归并段要求递增序列)。
⑤ 虽然10是最小的,但是不能置换出去。选择次小的记录14,14>13,所以可以放入归并段中。
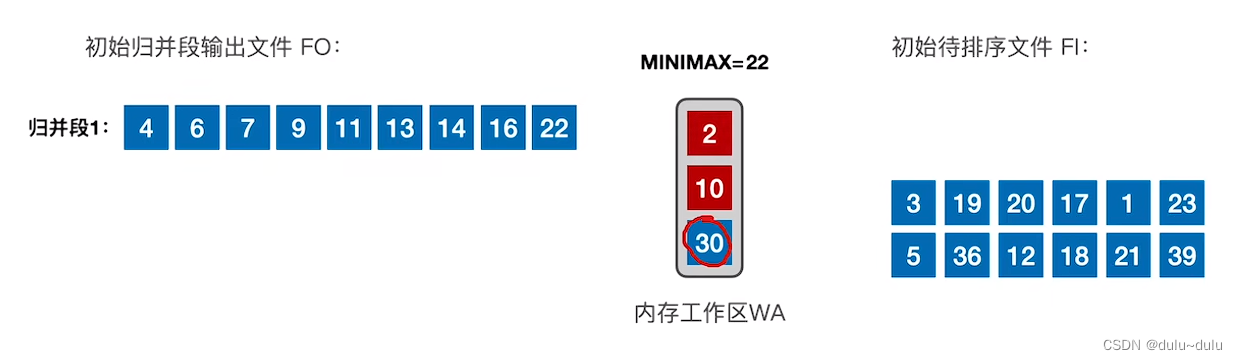
⑥ 同理,当读入记录2时,MINIMAX=14,2<22,所以不能置换出去。
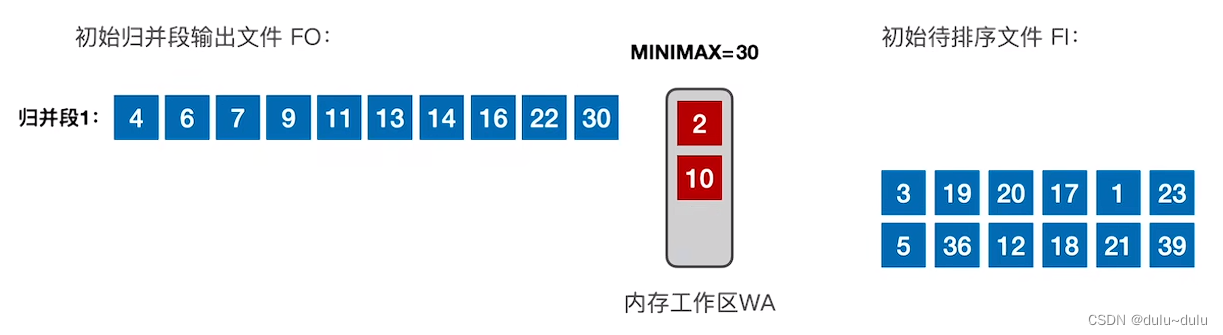
⑦ 内存工作区中,可以被置换出去的只有30,所以把30放到归并段1中。
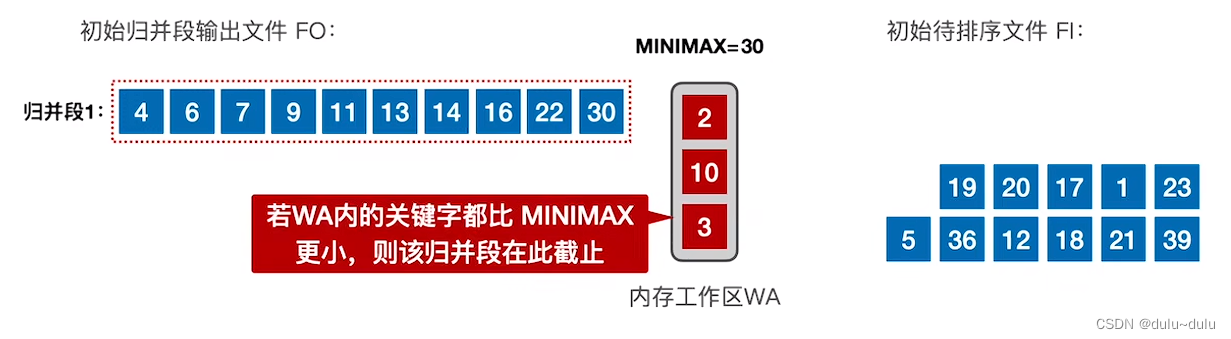
⑧ 接下来读入的记录是3,3<30,所以不能置换出去。若WA内的关键字都比 MINIMAX更小,则该归并段在此截止,也就是归并段1的生成到此结束。
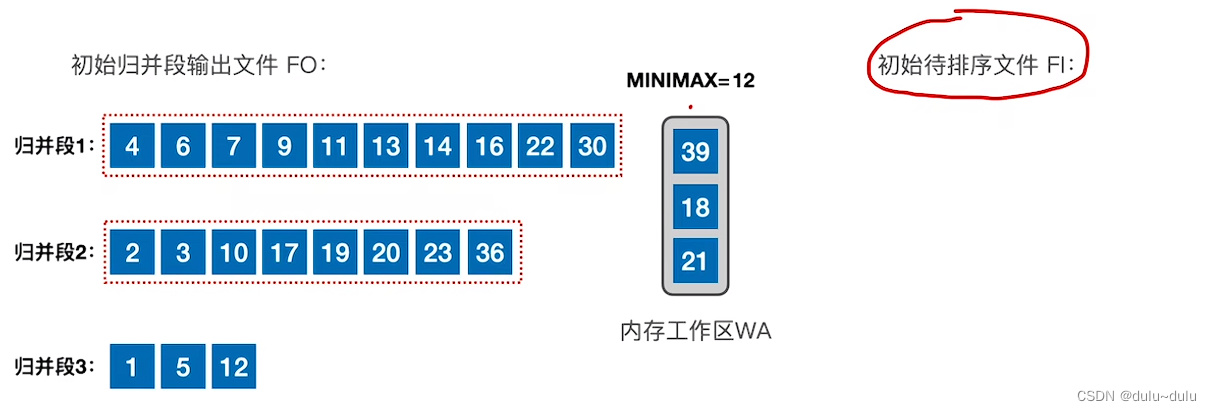
⑨ 归并段2的生成同理。
⑩ 在归并段3的生成中,如果初始的待排序序列为空,也就是记录都被读入,那么直接将内存工作区的记录全部放到归并段3的末尾即可。
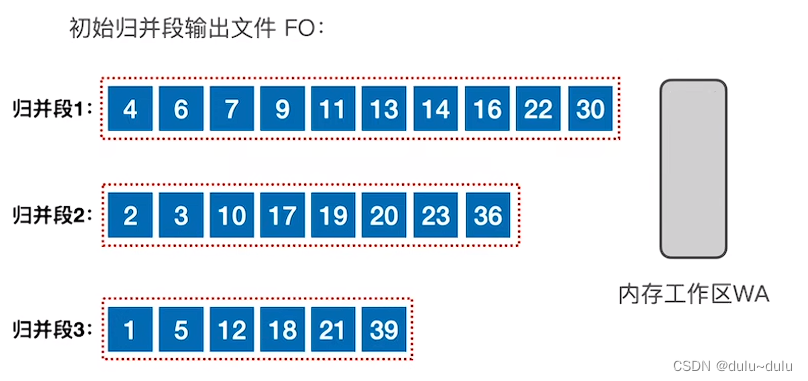
最终得到的三个归并段如下图所示:
注意:
① 这里的输出文件FO是存放在磁盘里面的,每一次从内存工作区选出的元素会依次放在输出缓冲区(队列形式)中,等输出缓冲区满,才会一次性写入磁盘中。所以虽然演示的时候是一个一个放入外存的,但是实际实现是由输出缓冲区作为中介的。
② 读待排序记录也是同理,一次会读一整块的记录,只是将记录一个一个挪到内存工作区进行比较而已。
通过上面的方法,归并段存储的记录数量可以超过内存工作区的能够存储的记录数,这样就突破了内存工作区大小的限制。并且,初始归并段的平均长度是传统等长初始归并段的2倍。在记录数不变的情况下,每个归并段包含的记录数越多,归并段的总数r就会更小,还记得这个公式吗?
归并趟数=
r越小,归并趟数就会越小,读写磁盘的次数就越少。
外部排序的时间开销=读写外存的时间+内部排序的时间+内部归并的时间
外部排序的时间开销就越小。这就是“置换-选择排序”的优势所在。
注:
设内存工作区 w=1,则文件{1,2,3,4,5}产生1个有序段,而文件{5,4,3,2,1}产生5个有序段。因此 有序段的个数 与待排文件n、内存工作区大小w都有关。
四.最佳归并树
如果我们选择"置换-选择排序"来构造初始归并段,那么初始归并段的长度可能是各不相同的。下图有5个归并段,其中的数值表示每个归并段占多少磁盘块:
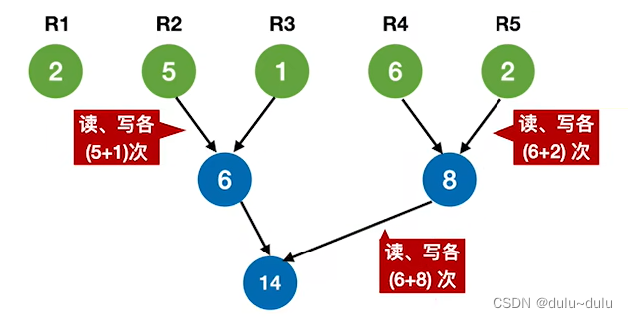
若对其进行二路归并,如下图所示,由于R2占5个磁盘块,R3占3个磁盘块,操作系统是以"块"为单位对磁盘进行读写的,所以R2与R3的归并总共需要读/写磁盘6次,其余以此类推:
再将R1与现在得到的归并段进行归并:
现在,将每个初始归并段看作一个叶子结点,归并段的长度作为结点权值,则上面这棵归并树的带权路径长度 WPL=2*1+(5+1+6+2)*3=44=读磁盘的次数=写磁盘的次数
结论:归并过程中的磁盘I/O次数=归并树的WPL*2
所以,要让磁盘I/O次数最少,就要使归并树WPL最小,也就是使归并树成为一棵哈夫曼树。

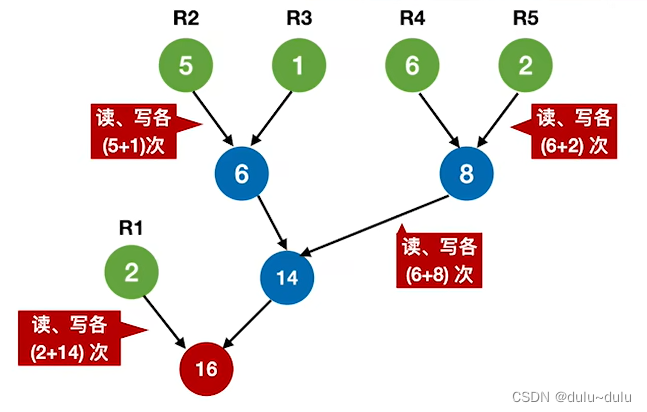
通过构造哈夫曼树优化初始归并段的二路归并:
哈夫曼树的构造之前的博客讲过了哟~
将初始归并段看作叶子节点构造哈夫曼树的结果如下:
最佳归并树 WPLmin=(1+2)*4+2*3+5*2+6*1 = 34
读磁盘次数=写磁盘次数=34次;总的磁盘I/O次数=68
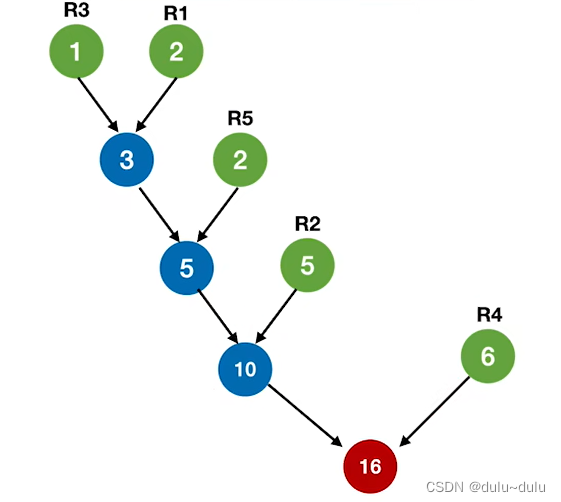
上面讲的是二路归并的情况,现在来看看多路归并的情况:
如下图所示,若将下面的初始归并段按原来的方法进行三路归并:
WPL=(9+30+12+18+3+17+2+6+24)*2=242
归并过程中 磁盘I/O总次数=484次
显然这不是一棵最佳的归并树,那三路归并的最佳归并树要怎么构造呢?和二路归并非常类似:
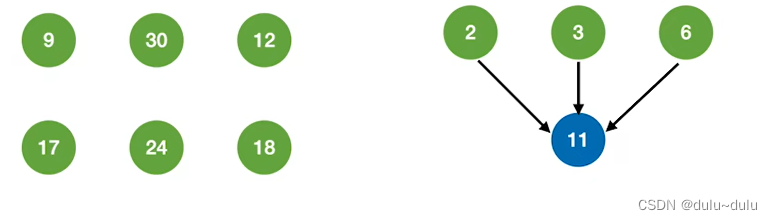
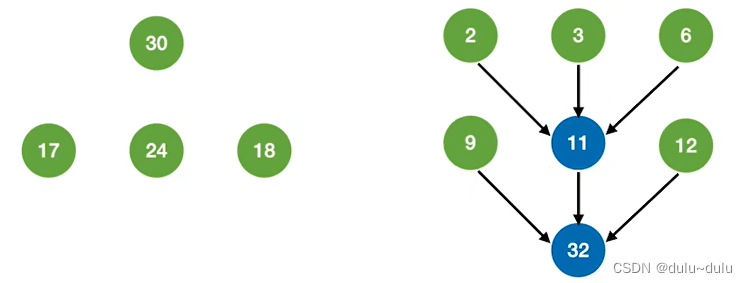
① 在初始归并段中选择权值最小的三个归并段进行三路归并:
② 将11看作新的归并段,从剩余归并段中继续选择三个最小归并段进行归并:
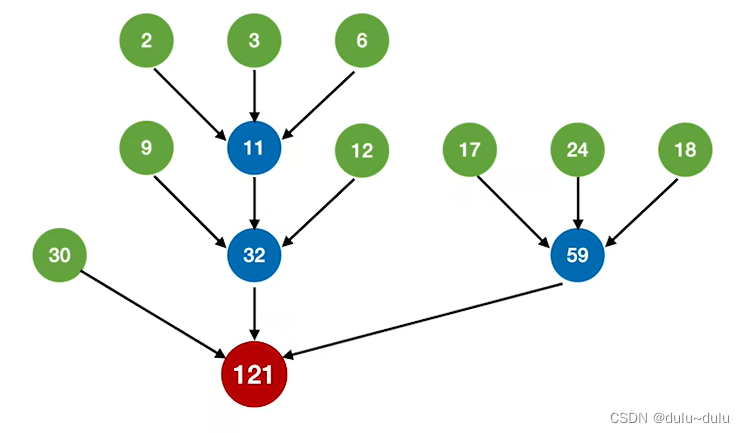
③ 依次类推,就可以得到最佳的三路归并树。如下图所示:
WPLmin=(2+3+6)*3+(9+12+17+24+18)*2+30*1=223
归并过程中 磁盘I/O总次数=446次
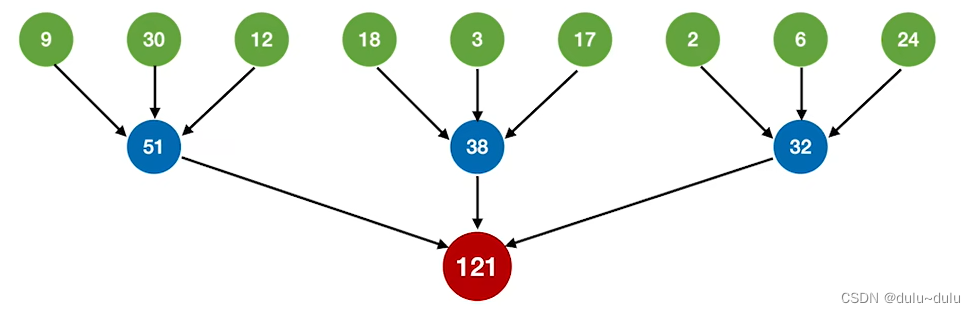
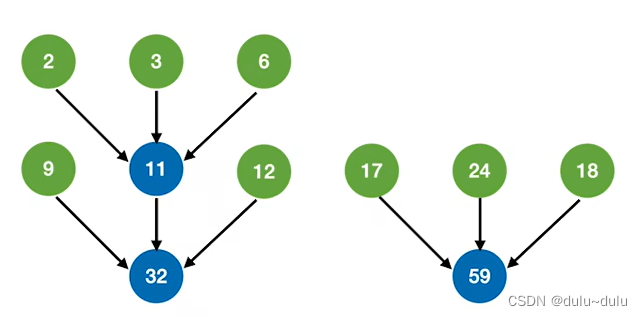
若将上面的初始归并段减少1个,也就是只有8个初始归并段:
① 前面的归并操作和上面讲的相同:
② 如上图所示,只有两棵树了,所以只能进行二路归并:
WPL =(2+3+6)*3+(9+12+17+24+18)*2=193
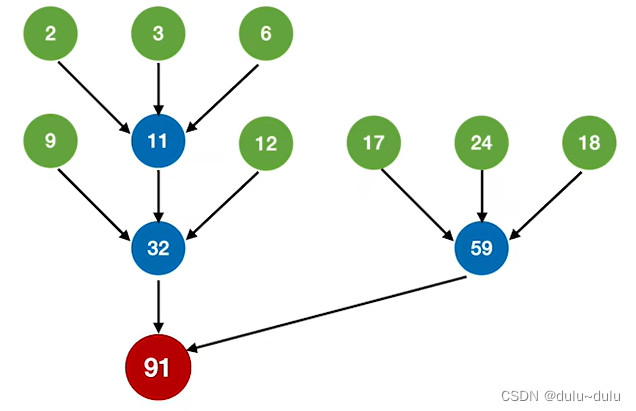
归并过程中 磁盘I/O总次数=386次但是上面得到的不是一棵最佳归并树,正确的做法是:补上一个长度为"0"的虚段,再进行三路归并。
得到的最佳三路归并树如下图所示。初始时,我们将长度为2的归并段放入输入缓冲区1,将长度为3的归并段放入输入缓冲区2,而输入缓冲区3中不放入任何归并段,将三个输入缓冲区的数据进行归并。可以将输入缓冲区3的归并段看作已经归并完的归并段:
WPLmin =(2+3+0)*3+(6+9+12+17+18)*2+24*1= 163
归并过程中 磁盘I/O总次数=326次总结:对于k叉归并,若初始归并段的数量无法构成严格的k叉归并树,则需要补充几个长度为 0 的“虚段”,再进行 k叉哈夫曼树的构造。
怎么看初始归并段要补几个虚段呢?
k叉的最佳归并树一定是一棵严格的 k 叉树,即树中只包含度为k、度为 0 的结点。
设度为k的结点有
个,度为0的结点有 n0 个,归并树总结点数=n 则:
① 初始归并段数量+虚段数量 = n0
根据k叉树的性质:
② n=n0+
③
(总共有
),除了根结点外,其余结点头上都会连一个分叉(n-1))
根据②,③:
------>
,
加入①式:
初始归并段数量+虚段数量-1/k-1是除得尽的,即:
(初始归并段数量-1)%(k-1)=0
若(初始归并段数量-1)%(k-1)=u ≠ 0,则需要补充(k-1)- u 个虚段
举个例子:
若初始归并段数量是19,要对初始归并段进行8路归并,运用上面的公式:
(19-1)%(8-1)=18%7=4,需要补充(8-1)- 4= 3个长度为0的虚段。















 6865
6865

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









