









R语言教程网址如下
https://www.math.pku.edu.cn/teachers/lidf/docs/Rbook/html/_Rbook/index.html
目录
source()函数可以运行保存在一个文本文件中的源程序
如下内容保存在文件ssq.r中
sum.of.squares <- function(x){
sum(x^2)
}用source()命令运行
source("ssq.r")可以运用sum.of.squares(1:5)
sum.of.squares(1:5)R向量下标和子集
class.csv
name,sex,age,height,weight
Alice,F,13,56.5,84
Becka,F,13,65.3,98
Gail,F,14,64.3,90
Karen,F,12,56.3,77
Kathy,F,12,59.8,84.5
Mary,F,15,66.5,112
Sandy,F,11,51.3,50.5
Sharon,F,15,62.5,112.5
Tammy,F,14,62.8,102.5
Alfred,M,14,69,112.5
Duke,M,14,63.5,102.5
Guido,M,15,67,133
James,M,12,57.3,83
Jeffrey,M,13,62.5,84
John,M,12,59,99.5
Philip,M,16,72,150
Robert,M,12,64.8,128
Thomas,M,11,57.5,85
William,M,15,66.5,112#取出其中的name和age列到变量name和age中
d.class <- read.csv("class.csv", header=TRUE, stringsAsFactors=FALSE)
name <- d.class[,"name"]
age <- d.class[,"age"]1.求出age中第3, 5, 7号的值
age[c(3,5,7)]
输出 [1] 14 12 112.用变量age, 求出达到15岁及以上的那些值
age[age>=15]
输出 [1] 15 15 15 16 153.用变量name和age, 求出Mary与James的年龄
mary_age <- age[name == "Mary"]
james_age <- age[name == "James"]
> mary_age
[1] 15
> james_age
[1] 124.求age中除Mary与James这两人之外的那些人的年龄值,保存到变量age1中
age1<-age[name!="Mary" & name!="James"]
> age1
[1] 13 13 14 12 12 11 15 14 14 14 15 13 12 16 12 11 155.假设向量x长度为n, 其元素是{1,2,…,n}的一个重排。 可以把x看成一个i到x[i]的映射(i在{1,2,…,n}中取值)。 求向量y, 保存了上述映射的逆映射,即: 如果x[i]=j, 则y[j]=i
n <- length(x)
y <- vector("integer", length = n)
for (i in 1:n) {
j <- x[i]
y[j] <- i
}
数值型向量及其运算
显示1到100的整数的平方根和立方根
for (i in 1:100) {
sqrt_val <- sqrt(i)
cubert_val <- i^(1/3)
print(paste("整数:", i, " 平方根:", sqrt_val, " 立方根:", cubert_val))
}
生成[0,1]区间上等间隔的100个格子点存入变量x中
x <- seq(0, 1, length.out = 100)
print(x)
日期功能
#dates.csv中包含如下内容
"出生日期","发病日期"
"1941/3/8","2007/1/1"
"1972/1/24","2007/1/1"
"1932/6/1","2007/1/1"
"1947/5/17","2007/1/1"
"1943/3/10","2007/1/1"
"1940/1/8","2007/1/1"
"1947/8/5","2007/1/1"
"2005/4/14","2007/1/1"
"1961/6/23","2007/1/2"
"1949/1/10","2007/1/2"date1 <- dates.tab[,'出生日期']
date2 <- dates.tab[,'发病日期']1.把date1、date2转换为R的POSIXct日期型
dates_converted1 <- as.POSIXct(date1, format = "%Y/%m/%d")
> dates_converted
[1] "1941-03-08 CST" "1972-01-24 CST" "1932-06-01 CST" "1947-05-17 CDT"
[5] "1943-03-10 CDT" "1940-01-08 CST" "1947-08-05 CDT" "2005-04-14 CST"
[9] "1961-06-23 CST" "1949-01-10 CST"
dates_converted2 <- as.POSIXct(date2, format = "%Y/%m/%d")
> dates_converted
[1] "2007-01-01 CST" "2007-01-01 CST" "2007-01-01 CST" "2007-01-01 CST"
[5] "2007-01-01 CST" "2007-01-01 CST" "2007-01-01 CST" "2007-01-01 CST"
[9] "2007-01-02 CST" "2007-01-02 CST"2.date1中的各个出生年
library(lubridate)
date1 <- c("1941/3/8", "1972/1/24", "1932/6/1", "1947/5/17", "1943/3/10",
"1940/1/8", "1947/8/5", "2005/4/14", "1961/6/23", "1949/1/10")
birth_years1 <- year(as.Date(date1, format = "%Y/%m/%d"))
print(birth_years1)
birth_years2 <- year(as.Date(date2, format = "%Y/%m/%d"))
print(birth_years2)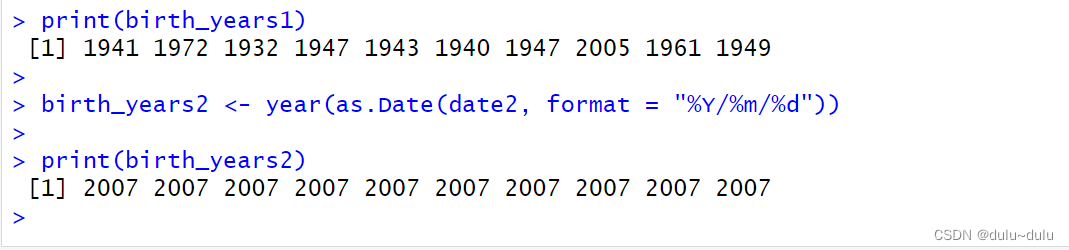 3. 计算发病时的年龄,以周岁论(过生日才算)
3. 计算发病时的年龄,以周岁论(过生日才算)
ages <- year(date2) - year(date1)
for (i in seq_along(ages)) {
if (month(date2[i]) < month(date1[i])) {
ages[i] <- ages[i] - 1
}
}
print(ages)
#输出
[1] 65 35 74 59 63 67 59 1 45 584.把date2中发病年月转换为’monyy’格式,这里mon是如FEB这样英文三字母缩写, yy是两数字的年份
> formatted_date <- format(as.Date(date2), "%b%y")
>
> formatted_date
[1] "1月07" "1月07" "1月07" "1月07" "1月07" "1月07" "1月07" "1月07" "1月07"
[10] "1月07"R因子类型
1.把sex变量转换为一个新的因子,F显示成“Female”,M显示成“Male”
factor(sex, levels = c("F", "M"), labels = c("Female", "Male")














 2697
2697

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









