









1.将变量加入列表中
> mydata<-data.frame(x1=c(2,3,4,5),x2=c(2,5,7,9))
> mydata
x1 x2
1 2 2
2 3 5
3 4 7
4 5 9
> sumx<-x1+x2
Error: object 'x1' not found
> sumx<-mydata$x1+mydata$x2
> sumx
[1] 4 8 11 14
> ls()
[1] "mydata" "sumx"
#这里是两个列表
> mydata$sumx<-mydata$x1+mydata$x2
> mydata
x1 x2 sumx
1 2 2 4
2 3 5 8
3 4 7 11
4 5 9 14
#这里是一个列表
2.变量编码
managers<-c(1,2,3,4,5)
date<-c("10/24/08","10/28/08","10/1/08","10/12/08","5/1/09")
> country<-c("US","US","UK","UK","UK")
> gender<-c("M","F","F","M","F")
> age<-c(32,45,25,39,99)
> q1<-c(5,3,3,3,2)
> q2<-c(4,5,5,3,2)
> q3<-c(5,2,5,4,1)
> q4<-c(5,5,5,NA,2)
> q5<-c(5,5,2,NA,1)
> survey<-data.frame(managers,date,country,gender,age,q1,q2,q3,q4,q5,stringAsFactors=FALSE)
> survey
managers date country gender age q1 q2 q3 q4 q5 stringAsFactors
1 1 10/24/08 US M 32 5 4 5 5 5 FALSE
2 2 10/28/08 US F 45 3 5 2 5 5 FALSE
3 3 10/1/08 UK F 25 3 5 5 5 2 FALSE
4 4 10/12/08 UK M 39 3 3 4 NA NA FALSE
5 5 5/1/09 UK F 99 2 2 1 2 1 FALSE
> #更改变量中的数据
> survey$age[survey$age==99]<-NA
> survey
managers date country gender age q1 q2 q3 q4 q5 stringAsFactors
1 1 10/24/08 US M 32 5 4 5 5 5 FALSE
2 2 10/28/08 US F 45 3 5 2 5 5 FALSE
3 3 10/1/08 UK F 25 3 5 5 5 2 FALSE
4 4 10/12/08 UK M 39 3 3 4 NA NA FALSE
5 5 5/1/09 UK F NA 2 2 1 2 1 FALSE
> #更改变量名
> names(survey)
[1] "managers" "date" "country" "gender"
[5] "age" "q1" "q2" "q3"
[9] "q4" "q5" "stringAsFactors"
> names(survey)[6]<-"question"
> survey
managers date country gender age question q2 q3 q4 q5 stringAsFactors
1 1 10/24/08 US M 32 5 4 5 5 5 FALSE
2 2 10/28/08 US F 45 3 5 2 5 5 FALSE
3 3 10/1/08 UK F 25 3 5 5 5 2 FALSE
4 4 10/12/08 UK M 39 3 3 4 NA NA FALSE
5 5 5/1/09 UK F NA 2 2 1 2 1 FALSE
> 3.判断是否为控制
> survey[,6:10]
question q2 q3 q4 q5
1 5 4 5 5 5
2 3 5 2 5 5
3 3 5 5 5 2
4 3 3 4 NA NA
5 2 2 1 2 1
> is.na(survey[,6:10])
question q2 q3 q4 q5
[1,] FALSE FALSE FALSE FALSE FALSE
[2,] FALSE FALSE FALSE FALSE FALSE
[3,] FALSE FALSE FALSE FALSE FALSE
[4,] FALSE FALSE FALSE TRUE TRUE
[5,] FALSE FALSE FALSE FALSE FALSE如果数值里面有空值,计算得到的也为空值
x<-c(1,2,NA,4)
y<-x[1]+x[2]+x[3]+x[4]
y
[1] NA
去空值
> survey
managers date country gender age question q2 q3 q4 q5 stringAsFactors
1 1 10/24/08 US M 32 5 4 5 5 5 FALSE
2 2 10/28/08 US F 45 3 5 2 5 5 FALSE
3 3 10/1/08 UK F 25 3 5 5 5 2 FALSE
4 4 10/12/08 UK M 39 3 3 4 NA NA FALSE
5 5 5/1/09 UK F NA 2 2 1 2 1 FALSE
> data<-na.omit(survey)
> data
managers date country gender age question q2 q3 q4 q5 stringAsFactors
1 1 10/24/08 US M 32 5 4 5 5 5 FALSE
2 2 10/28/08 US F 45 3 5 2 5 5 FALSE
3 3 10/1/08 UK F 25 3 5 5 5 2 FALSE
> 4.日期值:将字符串的日期转化为数值
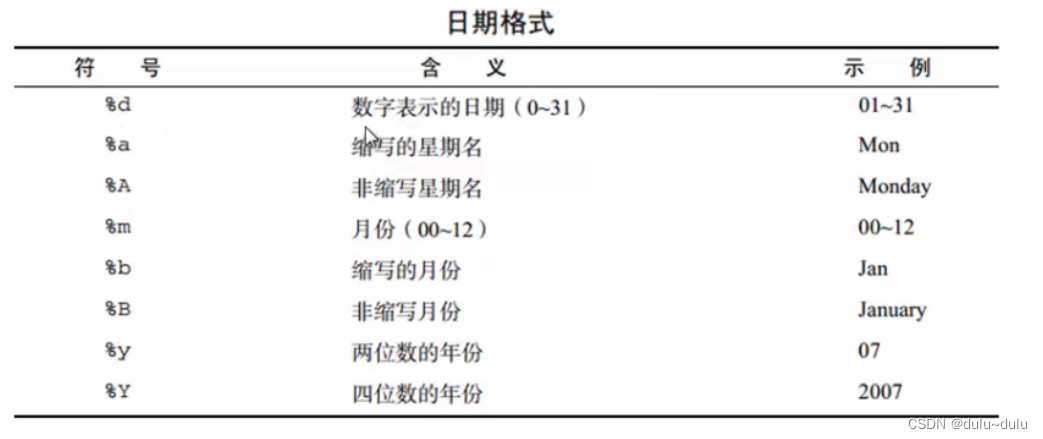
> mydata<-as.Date("2016-01-20")
> mydata
[1] "2016-01-20"
> mydata1<-c("01/05/2006","01/29/2007")
> date<-as.Date(mydata1,"%m/%d/%y")
> date
[1] "2020-01-05" "2020-01-29"
> Sys.Date()
[1] "2023-08-28"
> date()
[1] "Mon Aug 28 18:25:39 2023"
> today<-Sys.Date()
> today
[1] "2023-08-28"
> format(today,format="%B %d %Y")
[1] "八月 28 2023"
> format(today,format="%y")
[1] "23"
> startdate<-as.Date("2003-01-23")
> enddate<-as.Date("2011-09-18")
> startdate
[1] "2003-01-23"
> enddate
[1] "2011-09-18"
> days<-enddate-startdate
> days
Time difference of 3160 days5.类型转换函数
判断数值类型
is.integer()
is.numeric()
is.character()
is.vector()
is.matrix()
is.date.frame()
is.factor()
is.logical()
(1)as.integer()
x <- 3.14
y <- as.integer(x)
print(y)
# 输出结果为 3,小数部分被截断
(2)as.numeric()
x <- "3.14"
y <- as.numeric(x)
print(y)
# 输出结果为 3.14,字符型转换为数值型
(3)as.character()
x <- 42
y <- as.character(x)
print(y)
# 输出结果为 "42",整数型转换为字符型
(4)as.logical()
x <- 0
y <- as.logical(x)
print(y)
# 输出结果为 FALSE,数值 0 转换为逻辑型 FALSE
(5)as.vector()
# 示例1:将一个列表转换为向量
list_data <- list(1, 2, 3, 4)
vector_data <- as.vector(list_data)
print(vector_data)
# 输出结果为:1 2 3 4
# 示例2:将一个矩阵转换为向量(按列优先顺序)
matrix_data <- matrix(1:6, nrow = 2)
vector_data <- as.vector(matrix_data)
print(vector_data)
# 输出结果为:1 2 3 4 5 6
# 示例3:将一个数据框的列转换为向量
data <- data.frame(x = c(1, 2, 3), y = c(4, 5, 6))
vector_data <- as.vector(data$x)
print(vector_data)
# 输出结果为:1 2 3
(6)as.matrix()
# 示例1:将向量转换为矩阵
vector_data <- c(1, 2, 3, 4)
matrix_data <- as.matrix(vector_data)
print(matrix_data)
# 输出结果为:
# [,1]
# [1,] 1
# [2,] 2
# [3,] 3
# [4,] 4
# 示例2:将列表转换为矩阵
list_data <- list(1:3, 4:6, 7:9)
matrix_data <- as.matrix(list_data)
print(matrix_data)
# 输出结果为:
# [,1] [,2] [,3]
# [1,] 1 4 7
# [2,] 2 5 8
# [3,] 3 6 9
# 示例3:将数据框转换为矩阵
data <- data.frame(x = c(1, 2), y = c(3, 4))
matrix_data <- as.matrix(data)
print(matrix_data)
# 输出结果为:
# x y
# [1,] 1 3
# [2,] 2 4
(7)as.data.frame()
# 示例1:将向量转换为数据框
vector_data <- c(1, 2, 3, 4)
data_frame <- as.data.frame(vector_data)
print(data_frame)
# 输出结果为:
# vector_data
# 1 1
# 2 2
# 3 3
# 4 4
# 示例2:将矩阵转换为数据框
matrix_data <- matrix(1:6, nrow = 2)
data_frame <- as.data.frame(matrix_data)
print(data_frame)
# 输出结果为:
# V1 V2 V3
# 1 1 3 5
# 2 2 4 6
# 示例3:将列表转换为数据框
list_data <- list(x = 1:3, y = 4:6)
data_frame <- as.data.frame(list_data)
print(data_frame)
# 输出结果为:
# x y
# 1 1 4
# 2 2 5
# 3 3 6
(8)as.factor()
# 示例1:将向量转换为因子
vector_data <- c("Male", "Female", "Male", "Male", "Female")
factor_data <- as.factor(vector_data)
print(factor_data)
# 输出结果为:
# [1] Male Female Male Male Female
# Levels: Female Male
# 示例2:将变量转换为因子
data <- data.frame(x = c("A", "B", "A"), y = c(1, 2, 3))
data$x <- as.factor(data$x)
print(data)
# 输出结果为:
# x y
# 1 A 1
# 2 B 2
# 3 A 3
# Levels: A B
# 示例3:将数值型变量转换为有序因子
numeric_data <- c(1, 2, 3, 2, 1, 3)
factor_data <- as.factor(numeric_data)
ordered_factor_data <- ordered(factor_data, levels = c(1, 2, 3), labels = c("Low", "Medium", "High"))
print(ordered_factor_data)
# 输出结果为:
# [1] Low Medium High Medium Low High
# Levels: Low < Medium < High
(9)format()
x <- 3.14159
y <- format(x, digits = 2)
print(y)
# 输出结果为 "3.14",数值格式化为指定小数位数
(10)trunc()
x <- 3.14159
y <- round(x, digits = 2)
print(y)
# 输出结果为 3.14,数值四舍五入到指定小数位数
6.排序
> data<-survey[order(survey$age),]
> data
managers date country gender age question q2 q3 q4 q5 stringAsFactors
3 3 10/1/08 UK F 25 3 5 5 5 2 FALSE
1 1 10/24/08 US M 32 5 4 5 5 5 FALSE
4 4 10/12/08 UK M 39 3 3 4 NA NA FALSE
2 2 10/28/08 US F 45 3 5 2 5 5 FALSE
5 5 5/1/09 UK F NA 2 2 1 2 1 FALSE
#先按性别进行排序,再按年龄进行排序
> data2<-survey[order(survey$gender,survey$age),]
> data2
managers date country gender age question q2 q3 q4 q5 stringAsFactors
3 3 10/1/08 UK F 25 3 5 5 5 2 FALSE
2 2 10/28/08 US F 45 3 5 2 5 5 FALSE
5 5 5/1/09 UK F NA 2 2 1 2 1 FALSE
1 1 10/24/08 US M 32 5 4 5 5 5 FALSE
4 4 10/12/08 UK M 39 3 3 4 NA NA FALSE
> 7.数据集的合并
(1)cbind
> x<-matrix(c(1,2,3,4,5,6,7,8,9),nrow=3,ncol=3)
> x
[,1] [,2] [,3]
[1,] 1 4 7
[2,] 2 5 8
[3,] 3 6 9
> y<-x
> y
[,1] [,2] [,3]
[1,] 1 4 7
[2,] 2 5 8
[3,] 3 6 9
#cbind
> z<-cbind(x,y)
> z
[,1] [,2] [,3] [,4] [,5] [,6]
[1,] 1 4 7 1 4 7
[2,] 2 5 8 2 5 8
[3,] 3 6 9 3 6 9
#rbind
> z<-rbind(x,y)
> z
k1 k2 data
1 NA 1 1
2 NA NA 2
3 3 NA 3
4 4 4 4
5 5 5 5
6 NA NA 1
7 2 NA 2
8 NA 3 3
9 4 4 4
10 5 5 5
>(2)merge
> x<-data.frame(k1=c(NA,NA,3,4,5),k2=c(1,NA,NA,4,5),data=1:5)
> y<-data.frame(k1=c(NA,2,NA,4,5),k2=c(NA,NA,3,4,5),data=1:5)
> x
k1 k2 data
1 NA 1 1
2 NA NA 2
3 3 NA 3
4 4 4 4
5 5 5 5
> y
k1 k2 data
1 NA NA 1
2 2 NA 2
3 NA 3 3
4 4 4 4
5 5 5 5
> z<-merge(x,y,by="k1")
> z
k1 k2.x data.x k2.y data.y
1 4 4 4 4 4
2 5 5 5 5 5
3 NA 1 1 NA 1
4 NA 1 1 3 3
5 NA NA 2 NA 1
6 NA NA 2 3 3
#by="k1",第一个中的NA,对应第二个中的第(1)个NA和第(3)个NA
相当于
for(x){
for(y)
}
循环> newdata <- subset(survey,age>=35 | age<24,select=c(q1,q2,q3,q4))
> newdata
q1 q2 q3 q4
2 3 5 2 5
4 3 3 4 NA
5 2 2 1 2(3)reshape2
这里使用的是airquality数据集----纽约1973年5月~9月空气质量情况
不知道Rstudio内置数据集的可以看
BiocManager::install("reshape2")
library(reshape2)
> melt(airquality)
> head(aql)
variable value
1 Ozone 41
2 Ozone 36
3 Ozone 12
4 Ozone 18
5 Ozone NA
6 Ozone 28
> head(airquality)
Ozone Solar.R Wind Temp Month Day
1 41 190 7.4 67 5 1
2 36 118 8.0 72 5 2
3 12 149 12.6 74 5 3
4 18 313 11.5 62 5 4
5 NA NA 14.3 56 5 5
6 28 NA 14.9 66 5 6
#用于指定数据重塑(reshaping)操作中要保留的标识变量(identifier variables)
> aql<-melt(airquality,id.vars = c("Month","Day"))
> head(aql)
Month Day variable value
1 5 1 Ozone 41
2 5 2 Ozone 36
3 5 3 Ozone 12
4 5 4 Ozone 18
5 5 5 Ozone NA
6 5 6 Ozone 28
#以平均值作为聚合函数
> aqw<-dcast(aql,Month~variable,fun.aggregate = mean,na.rm=TRUE)
> head(aqw)
Month Ozone Solar.R Wind Temp
1 5 23.61538 181.2963 11.622581 65.54839
2 6 29.44444 190.1667 10.266667 79.10000
3 7 59.11538 216.4839 8.941935 83.90323
4 8 59.96154 171.8571 8.793548 83.96774
5 9 31.44828 167.4333 10.180000 76.90000
> head(airquality)
Ozone Solar.R Wind Temp Month Day
1 41 190 7.4 67 5 1
2 36 118 8.0 72 5 2
3 12 149 12.6 74 5 3
4 18 313 11.5 62 5 4
5 NA NA 14.3 56 5 5
6 28 NA 14.9 66 5 6(4)gather
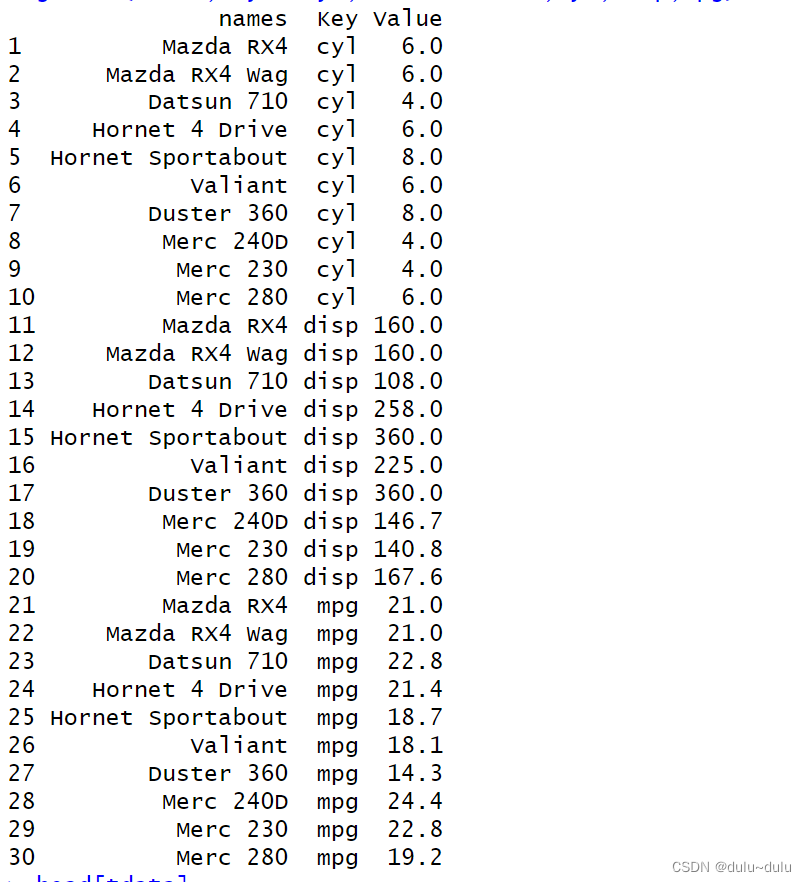
#cyl、disp 和 mpg 则是原始数据框中的列名,将被转换为 Key 和 Value 两列
> tdata<-mtcars[1:10,1:3]
> tdata<-data.frame(names=rownames(tdata),tdata)
> tdata
names mpg cyl disp
Mazda RX4 Mazda RX4 21.0 6 160.0
Mazda RX4 Wag Mazda RX4 Wag 21.0 6 160.0
Datsun 710 Datsun 710 22.8 4 108.0
Hornet 4 Drive Hornet 4 Drive 21.4 6 258.0
Hornet Sportabout Hornet Sportabout 18.7 8 360.0
Valiant Valiant 18.1 6 225.0
Duster 360 Duster 360 14.3 8 360.0
Merc 240D Merc 240D 24.4 4 146.7
Merc 230 Merc 230 22.8 4 140.8
Merc 280 Merc 280 19.2 6 167.6
> gather(tdata,key="Key",value="Value",cyl,disp,mpg)
也可以用列号表示
gather(tdata,key="Key",value="Value",2:4) 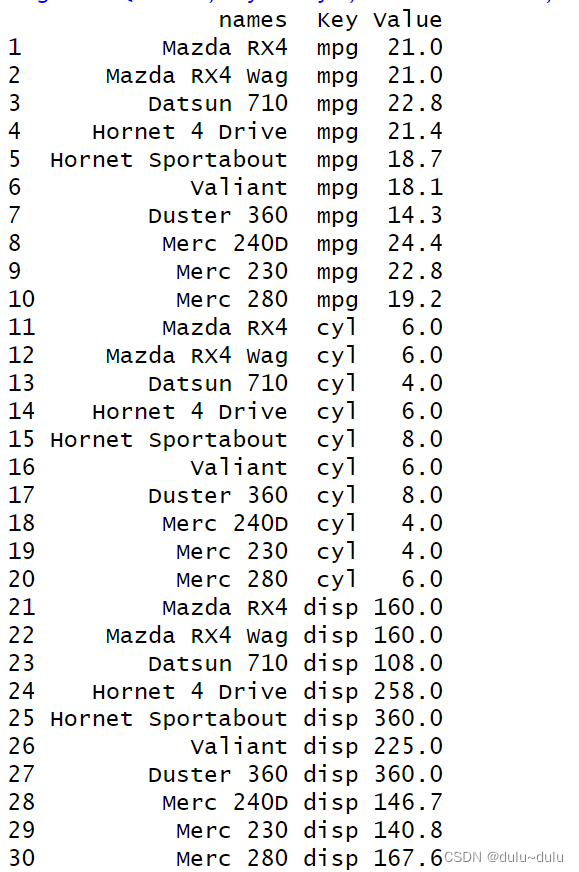
(5)spread
> gdata<- gather(tdata,key="Key",value="Value",2:4)
> spread(gdata,key="Key",value="Value")
names cyl disp mpg
1 Datsun 710 4 108.0 22.8
2 Duster 360 8 360.0 14.3
3 Hornet 4 Drive 6 258.0 21.4
4 Hornet Sportabout 8 360.0 18.7
5 Mazda RX4 6 160.0 21.0
6 Mazda RX4 Wag 6 160.0 21.0
7 Merc 230 4 140.8 22.8
8 Merc 240D 4 146.7 24.4
9 Merc 280 6 167.6 19.2
10 Valiant 6 225.0 18.1(6)separate与unite
> df<-data.frame(x=c(NA,"a.b","a.d","b.c"))
> df
x
1 <NA>
2 a.b
3 a.d
4 b.c
> separate(df,col=x,into=c("A","B"))
A B
1 <NA> <NA>
2 a b
3 a d
4 b c
> df<-data.frame(x=c(NA,"a.b-c","a-d","b-c"))
> separate(df,col=x,into=c("A","B"),sep="-")
A B
1 <NA> <NA>
2 a.b c
3 a d
4 b c
> x<-separate(df,col=x,into=c("A","B"),sep="-")
> x
A B
1 <NA> <NA>
2 a.b c
3 a d
4 b c
> unite(x,col="AB",A,B,sep="-")
AB
1 NA-NA
2 a.b-c
3 a-d
4 b-c(7)dplyr
#过滤iris数据中Sepal.Length<7的数据
dplyr::filter(iris,Sepal.Length>7)
#将合并后的数据框进行去重操作
dplyr::distinct(rbind(iris[1:10,],iris[1:15,]))
#选择 iris 数据框中的第 10 到 15 行,并将结果存储在 sliced_data 中
dplyr::slice(iris,10:15)
#从 iris 数据框中随机选择 10 行数据
dplyr::sample_n(iris,10)
#frac:表示要选择的行数占原始数据框总行数的比例
dplyr::sample_frac(iris,0.1)
#按照 Sepal.Length 列对 iris 数据框进行排序
dplyr::arrange(iris,Sepal.Length)
#按照相反方向排序
dplyr::arrange(iris,desc(Sepal.Length))
#使用 group_by() 函数对数据框 iris 按照 Species 列进行分组
dplyr::group_by(iris,Species)
补充 %>%
管道运算符 %>% 的作用是将前一个表达式的结果作为参数传递给下一个表达式的第一个参数
#对分组统计结果进行排序
iris %>% group_by(Species) %>% summaries(avg=mean(Sepal,Width) %>% arrange(ave))
#添加新的一列
dplyr::mutate(iris,new=Sepal.Length+Petal.Length)
#连接相关
a=data.frame(x1=c("A","B","C"),x2=c(1,2,3))
b=data.frame(x1=c("A","B","D"),x3=c(T,F,T))
#左连接
dplyr::left_join(a,b,by="x1")
#全连接
dplyr::full_join(a,b,by="x1")
#半连接
dplyr::semi_join(a,b,by="x1")
#反向连接:将a,b补集输出来
dplyr::anti_join(a,b,by="x1")
#取交集
intersect
#取并集
union_all
#非冗余的并集
union
#取first补集
setdiff(first,second)
#取second补集
setdiff(second,first)(8)select
library(dplyr)
# 选择 iris 数据框中的两列:Sepal.Length 和 Sepal.Width
selected_data <- select(iris, Sepal.Length, Sepal.Width)
# 查看选择后的结果
selected_data(9)summarise
library(dplyr)
# 计算 iris 数据框中 Sepal.Length 列的均值和标准差
summary_data <- iris %>%
summarise(mean = mean(Sepal.Length), sd = sd(Sepal.Length))
# 查看汇总结果
summary_data
dplyr还有许多功能,可以使用help(dplyr)进行查看
(10)sample(x,size,replace=FALSE)
size:取出的样品量 replace:是否放回,若为false则不放回,若为true则放回
> mysample<-survey[sample(5,3,replace = FALSE),]
> mysample
managers date country gender age q1 q2 q3 q4 q5 stringAsFactors
4 4 10/12/08 UK M 39 3 3 4 NA NA FALSE
5 5 5/1/09 UK F 99 2 2 1 2 1 FALSE
2 2 10/28/08 US F 45 3 5 2 5 5 FALSE
每一次执行都不同8.数据集的调整
t():能使行变为列,使列变为行
> survey
managers date country gender age q1 q2 q3 q4 q5 stringAsFactors
1 1 10/24/08 US M 32 5 4 5 5 5 FALSE
2 2 10/28/08 US F 45 3 5 2 5 5 FALSE
3 3 10/1/08 UK F 25 3 5 5 5 2 FALSE
4 4 10/12/08 UK M 39 3 3 4 NA NA FALSE
5 5 5/1/09 UK F 99 2 2 1 2 1 FALSE
> t(survey)
[,1] [,2] [,3] [,4] [,5]
managers "1" "2" "3" "4" "5"
date "10/24/08" "10/28/08" "10/1/08" "10/12/08" "5/1/09"
country "US" "US" "UK" "UK" "UK"
gender "M" "F" "F" "M" "F"
age "32" "45" "25" "39" "99"
q1 "5" "3" "3" "3" "2"
q2 "4" "5" "5" "3" "2"
q3 "5" "2" "5" "4" "1"
q4 " 5" " 5" " 5" NA " 2"
q5 " 5" " 5" " 2" NA " 1"
stringAsFactors "FALSE" "FALSE" "FALSE" "FALSE" "FALSE"9.数学函数
这一篇已经涵盖大部分数学函数,这里进行补充
(1)pretty
#30个-3~3的数
> x<-pretty(c(-3,3),30)
> x
[1] -3.0 -2.8 -2.6 -2.4 -2.2 -2.0 -1.8 -1.6 -1.4 -1.2 -1.0 -0.8
[13] -0.6 -0.4 -0.2 0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 1.6
[25] 1.8 2.0 2.2 2.4 2.6 2.8 3.0
(2)dnorm
> y<-dnorm(x)
> plot(x,y)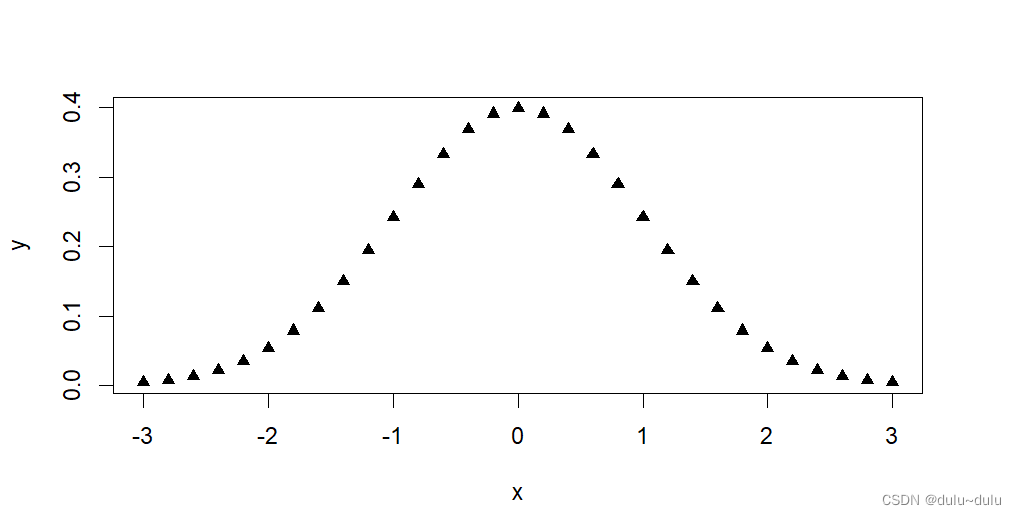
除了dnorm,还有其他计算正态分布的函数
dnorm(x, mean, sd):dnorm()函数用于计算正态分布(或称为高斯分布)的概率密度函数(PDF)。给定一个值 x,均值 mean 和标准差 sd,该函数返回在给定值处的概率密度。例如,dnorm(0, 0, 1)返回标准正态分布在 x=0 处的概率密度。
rnorm(n, mean, sd):rnorm()函数用于生成服从正态分布的随机数。给定样本数 n、均值 mean 和标准差 sd,函数会生成一个长度为 n 的随机数向量,其中的随机数符合给定的正态分布。
pnorm(q, mean, sd):pnorm()函数用于计算正态分布的累积分布函数(CDF)。给定一个值 q、均值 mean 和标准差 sd,该函数返回随机变量小于等于 q 的概率。例如,pnorm(0, 0, 1)返回标准正态分布中小于等于 0 的概率。
qnorm(p, mean, sd):qnorm()函数用于计算正态分布的分位数函数。给定一个概率值 p、均值 mean 和标准差 sd,该函数返回对应于给定概率的分位数。例如,qnorm(0.5, 0, 1)返回标准正态分布的中位数。
rnorm(50,mean=20,sd=8)
(3)runif(5):随机生成5个服从正态分布的数
> runif(5)
[1] 0.1326900 0.4600964 0.9429571 0.7619739 0.9329098set.seed(12)
runif(5)
[1] 0.1326900 0.4600964 0.9429571 0.7619739 0.9329098就会得到之前得到的随机数















 3630
3630











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









