






水下目标探测在海洋资源开发、环境监测和生态保护等方面具有重要意义。然而,水下图像的退化限制了目标探测器的性能。现有方案大多将水下图像增强(UIE)和水下图像分解(UOD)作为两个独立的任务,将UIE作为预处理步骤来减少图像的退化问题,无法有效提高检测精度。因此,在本文中,我们提出了一种双分支联合学习网络(DJL-Net),通过多任务联合学习将图像处理和目标检测结合起来,构建一个端到端的水下检测模型。采用双分支结构,DJL-Net可以利用图像处理模块生成的增强图像来补充由于原始水下图像退化而丢失的特征。具体而言,DJL-Net首先采用由检测损耗控制的图像脱色模块,生成灰度图像,消除水下光吸收和散射效应带来的色彩干扰。利用改进的边缘增强模块增强灰度图像中的形状和纹理表达,提高对目标边界特征的识别。然后,将生成的边缘增强灰度图像及其原始水下图像输入到两个分支中,学习不同类型的特征。最后,提出了三维自适应门控特征融合模块,有效地融合了从两个分支中学习到的互补特征。在四个UOD数据集上的综合实验,包括一些具有挑战性的水下环境场景,证明了所提出的DJL-Net的有效性和鲁棒性。
1.介绍
水下目标探测(UOD)技术在水下资源勘探、海洋环境监测与生态研究、智能水产养殖、海上安全、国防等方面具有重要的应用价值[1-3]。然而,由于水下环境复杂,水下光学图像经常出现物体轮廓模糊、雾状效果、亮度不均匀、颜色偏移等问题(如图1所示),这限制了检测算法的性能[4-8]。因此,减轻水下图像退化对目标检测的负面影响已成为UOD领域的一个关键挑战
为了解决这些问题,一种思路是改进检测算法框架,增强检测器对水下退化图像的适应性。另一种直观的方案是利用图像增强技术对水下光学图像进行预处理,从而减少图像的退化问题,提高整体可视性。然后将增强后的图像用作目标检测器的输入,以提高水下环境中的检测精度[9 - 11]。然而,最近的一些研究[3,12 - 15]探讨了水下图像增强(UIE)与UOD之间的关系。这些研究表明,简单地使用图像增强技术作为预处理步骤来生成增强图像并不能有效地提高UOD任务的准确性。相比之下,对于大多数UIE算法,检测器对增强图像的检测精度甚至低于对原始图像的检测精度。这种现象可以用UIE和UOD的优化目标不同来解释[3]。前者旨在改善退化图像以满足人类视觉感知[16],后者侧重于目标定位和识别。由于这种差异,在增强图像数据上训练的模型可能不令人满意。此外,过度增强可能会导致局部细节的丢失,对目标检测精度产生不利影响。
为此,一些研究[12,17]提出将UIE和UOD结合起来实现端到端的联合学习,从而利用图像增强来帮助检测复杂水下环境中的物体。然而,目前可用的水下检测数据集缺乏更适合检测任务的真实图像标签,从而限制了图像增强网络在联合学习中的训练效果。此外,现有的UOD算法倾向于使用单一类别的水下图像(如只有原始图像或只有增强图像)作为输入。我们认为,通过将不同类别的水下图像输入到特征提取网络中,然后对这些不同图像中的特征进行选择性匹配和融合,可以显著提高水下目标检测器的性能。
提出了一种用于水下目标检测任务的双分支联合学习网络(DJL-Net)。该模型增加了一个分支,将处理后的边缘增强灰度图像作为输入。特征提取网络对不同分支提取的特征进行选择性匹配和融合,然后输入到后续的检测网络中完成UOD任务。该方法显著减轻了由于原始水下图像退化而导致的特征丢失现象,有助于更准确地完成UOD任务。为此,本文提出了两种由检测损失控制的图像处理模块。首先,设计图像脱色模块(IDM),生成适合检测任务的灰度图像,去除原始图像中由于水下光吸收和散射效应而产生的颜色干扰。其次,改进的边缘增强模块(IEEM)旨在增强灰度图像中的形状和纹理表达,从而提供更有效的目标边界和纹理信息。此外,本文还提出了三维自适应门控特征融合模块(TAGFFM)。该模块通过通道、宽度和高度三个维度对两个分支提取的特征进行编码,实现了特征的更精确匹配和融合。
总的来说,我们的贡献可以概括为以下四个主要方面:
(i)我们提出了一个用于水下目标检测的DJL-Net模型,该模型通过联合学习策略控制图像处理模块,生成适合检测任务的边缘增强灰度图像。DJL-Net利用其独特的双分支结构,将从边缘增强灰度图像中学习到的特征与其原始图像进行匹配融合,实现特征互补。
(ii)我们开发了两个由检测损失控制的图像处理模块:IDM和IEEM。IDM的目的是将原始图像转换为适合检测任务的灰度图像,而IEEM的目的是进一步细化灰度图像的边缘,从而清晰地区分检测对象。
(iii)设计TAGFFM,有效融合不同分支提取的特征。该模块通过三个不同的维度对特征进行编码,充分利用不同特征之间的通道和空间信息来控制整个融合过程。
(iv)我们在四个公共UOD数据集(DUO、UODD、RUOD和UDD)以及一些具有挑战性的水下环境场景上进行了大量的实验。综合结果证明了所提出的DJL-Net的有效性和鲁棒性。
2. 相关工作
2.1目标检测
物体检测的主要目标是识别指定区域内所有感兴趣的物体,并准确确定其对应的类别和空间位置[18,19]。目前,主流的目标检测算法大致可以分为基于锚点和无锚点两大类
基于锚点的目标检测算法通常会提前生成多个候选框,然后对这些候选框进行处理以确定最终的检测结果。Faster R-CNN[20]和YOLO[21]是经典的基于锚的方法。RetinaNet[22]通过采用单分支结构和更有效的焦点损失来改变正、负样本对损失函数的影响权重,提高了算法性能。Cascade R-CNN[23]通过级联多个分类和回归模块对检测器进行细化,提高了对多尺度和被遮挡物体的检测效率。检测器[24]利用递归特征金字塔和可切换的亚属性卷积构建了新的骨干网络,显著提高了目标检测性能。DDOD[25]通过分离用于分类和回归的标签分配,以及实现独特的特征和监督解纠缠技术,提高了对密集对象的检测性能。GFL[26]引入了分类和定位质量的统一表示,通过更准确地捕获具有质量焦损失和分布焦损失的边界盒分布,提高了检测性能
与基于锚点的方法不同,无锚点目标检测算法通常直接预测检测盒的位置和大小。FCOS[27]是一种代表性的无锚法。NAS-FCOS[28]是一种用于目标检测的高效神经结构搜索方法,它使用定制的强化学习范式来有效搜索特征金字塔网络的预测头部。可变形DETR[29]引入了基于DETR[30]的可变形卷积和位置编码等技术,提高了非刚性形状和尺度变化对象的定位精度。TOOD[31]通过新颖的任务对准头设计和任务对准学习,解决了目标分类与定位预测不一致的问题,显著提高了性能和效率。VFNet[32]通过其创新的iou感知分类评分、用于精确训练的可变损失以及用于评分预测和边界盒细化的星形边界盒特征表示来提高检测性能。DW[33]引入了一种新的自适应标签分配方法,通过关注分类和回归预测之间的一致性和不一致性,动态地为每个锚分配唯一的正、负权重。
2.2. 水下目标探测
目标检测器已经成功地应用于许多场景[34 - 37]。然而,在UOD方面仍有很大的改进潜力。目前,大多数现有的方法是基于改进通用目标探测器,加入特定的功能模块,或引入先进的技术策略,使通用目标探测器适应水下环境。FERNet[38]采用由语义细化模块和位置细化模块组成的双重细化框架来提高UOD的精度。SWIPENet[39]引入了一个多类AdaBoost训练范式和一个样本加权损失函数。充分利用骨干网生成高分辨率、语义丰富的特征图,提高了噪声干扰下水下小型目标的检测性能。Boosting R-CNN[40]采用一种新的RetinaRPN提供方案,提出了一种概率推理管道和硬例挖掘方法,在水下数据集上实现良好的性能和鲁棒性。Dai等人[41]提出了ERL-Net,这是一种用于水下目标检测的边缘引导表示学习框架。该框架通过将边缘信息与多层次特征聚合相结合,显著提高了低对比度水下环境和小目标的检测性能。此外,最近的一些研究侧重于设计专门的关注模块,将其集成到通用的检测框架中,从而提高水下检测性能[42,43]。例如,Liang等[44]将外部关注模块应用于感兴趣区域(RoI)特征,以提高水下环境中通用检测器的精度。Shen等[45]提出了多维、多功能、多层次的注意模块,通过三种创新策略显著增强了注意机制的鲁棒性、灵活性和多样性,从而提高了模型在水下背景下的抗干扰能力
另一种策略是在数据层面进行改进,可以通过对训练数据进行特殊处理或增强训练数据来提高模型在水下环境中的学习效率和检测精度。RoIMix[46]是一种RoI级数据增强模块,通过融合图像RoI区域来模拟水下目标的重叠和遮挡,从而提高通用检测器在UOD任务中的泛化能力。泊松GAN和AquaNet[47]采用结合区域和语义信息的多分支结构,并利用泊松GAN增强的数据集进行训练,以获得更好的结果。一些研究人员致力于改进UIE方法,将其作为预处理步骤来生成增强图像,从而减轻图像退化对检测任务的不利影响。例如,Liu等[12]提出了一种基于目标引导的双对抗性对比学习的水下图像增强方法,以解决水下图像失真影响目标检测精度的挑战。Fu等[48]提出了残差特征转移模块(RFTM),该模块通过学习对探测器友好的水下图像的先验知识,改善水下图像中严重退化区域的特征分布,从而提高水下环境下探测器的性能。
2.3. 多任务学习
多任务学习,有时也被称为联合学习[49],是一种高效的机器学习方法。其核心原理是在一个统一的框架内同时处理多个相关任务,利用不同任务之间共享的知识和特征来提高学习效率和模型的泛化能力[50,51]。多任务学习在自然语言处理[52]、计算机视觉[53,54]、生物医学成像[55]、多模态数据分析[56]等领域显示出强大的应用潜力。特别是在水下目标检测领域,利用UIE和UOD之间的任务相关性来提高水下目标检测的精度已成为一个重要的研究热点
在水下环境中,由于光的吸收和散射等独特的光学特性,图像往往会出现严重的退化,导致对比度低、颜色偏移和模糊,严重影响目标检测的准确性和可靠性[57]。最近的研究[3,12 - 15]表明,使用UIE预处理的增强图像并不能有效提高UOD任务的准确性。将UIE和UOD视为两个独立的学习任务的方法通常有效性有限,因为这种单任务模型不能同时有效地满足图像质量和目标检测的优化目标。因此,有研究探索利用多任务联合学习,将UIE和UOD整合到一个统一的框架中进行端到端训练,通过相关任务的联合优化来提升水下目标检测性能。Yeh等[17]提出了一种新的轻型深水目标检测网络,通过多任务学习将颜色转换网络和目标检测网络相结合,提高了水下环境下的检测性能。GCC-Net[58]从跨域数据交互和融合的角度,将UIE和UOD相结合,构建了水下检测的端到端模型,有效提高了低光、低对比度条件下的检测性能。
以上方法大多使用单一类别的水下图像(如只有原始图像或只有增强图像)作为学习特征的输入。然而,单一类别的图像特征可能无法满足复杂水下环境的检测需求。此外,目前用于检测任务的水下数据集缺乏更适合于检测任务的真实图像标签,这限制了图像增强网络在联合学习中的训练效果。与上述研究不同,我们提出了一种端到端双分支联合学习网络,利用原始图像及其处理后的边缘增强灰度图像补充学习特征信息,有效解决了水下图像退化导致的特征丢失问题,提高了模型在复杂水下环境下的检测性能。
3.方法
3.1概述
提出的DJL-Net的总体框架如图2所示。DJL-Net采用双分支网络结构,分支1以原始RGB水下图像𝑟为输入,分支2以经过图像脱色模块(IDM)和改进的边缘增强模块(IEEM)处理后的边缘增强灰度图像𝑔为输入。我们使用两个权值不共享的ResNet-50[59]网络作为DJL-Net的特征提取网络。从两个分支中提取的特征分别表示为{𝑭𝑟1,𝑭𝑟2,𝑭𝑟3,𝑭𝑟4}和{𝑭𝑔1,𝑭𝑔2,𝑭𝑔3,𝑭𝑔4},通过三维自适应门控特征融合模块(TAGFFM)进行匹配和融合。该过程产生一组融合的特征{𝑭1,𝑭2,𝑭3,𝑭4},然后将其输入特征金字塔网络(FPN)[60],以获得用于后续检测任务的特征映射。我们使用tod[31]算法作为DJL-Net的检测网络,完成最终的分类和回归任务,最终输出目标标签和定位结果。
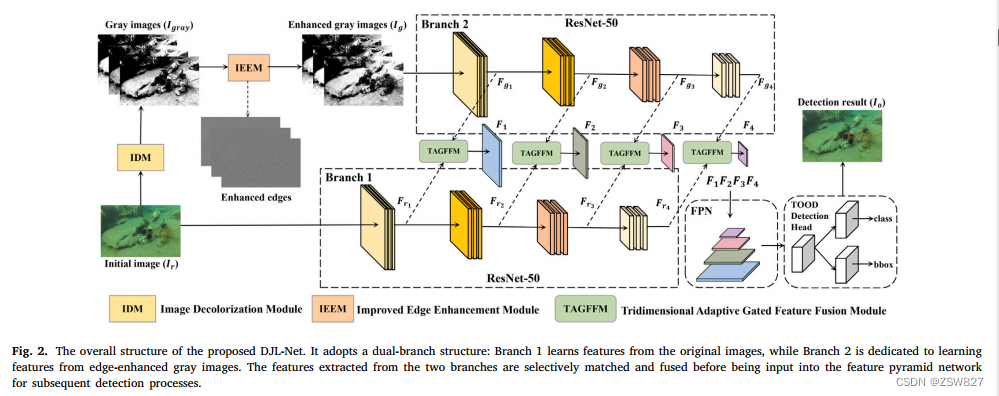
图2所示。建议的DJL-Net的总体结构。它采用双分支结构:分支1从原始图像中学习特征,分支2从边缘增强的灰度图像中学习特征。从两个分支中提取的特征被选择性地匹配和融合,然后输入到特征金字塔网络中用于后续的检测过程。
值得注意的是,我们的方法的主要目标是提高探测器对水下目标的检测能力,因此所提出的DJL-Net不需要额外的损失函数,只使用目标检测损失来优化和更新网络参数。损失函数的详细描述见3.5节。
3.2. 图像脱色模块
图像退化模块(IDM)的主要作用是将输入的RGB水下图像转换为相应的灰度图像。在以往的研究[17]中,将一幅灰度图像沿通道维度复制三次,并拼接成三通道输出的灰度图像。然后使用三通道灰度图像代替原始图像作为目标检测网络的输入,用于后续的检测任务。上述研究表明,这种转换有利于消除水下图像色移对检测器的不利影响,以较低的计算复杂度提高检测性能。受此方案思想的启发,我们在提出的DJL-Net模型中使用灰色图像作为新分支的输入。
然而,与上述方案不同的是,本文提出的IDM模块预测了三个不同尺度的特征层,并生成了三个不同的灰度图像,从而缓解了重复单个灰度图像所带来的信息丢失问题。在烧蚀研究(章节4.4)中,我们报告了不同方案的实验结果。
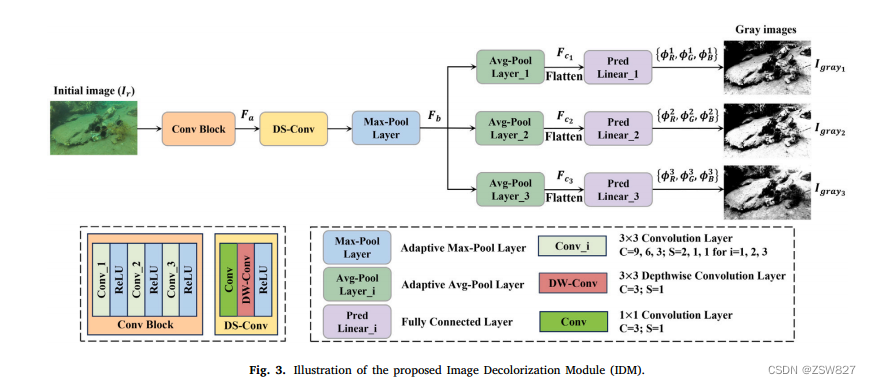
所提出的IDM结构如图3所示。该模块接受三通道RGB彩色水下图像作为输入,并产生三组预测参数作为输出。每一组包括三个通道变换参数,用于将彩色图像转换为相应的灰度图像。转换过程可描述为:
![]()
式中,𝑅,𝐺,和是通过网络自适应学习得到的一组通道变换参数,分别对输入RGB图像的红、绿、蓝通道进行编码。分别表示输入RGB彩色图像的红、绿、蓝通道的值:𝑅,𝐺,和 。𝐺𝑟𝑎>为最终输出的灰度图像
其中,IDM要处理的输入图像表示为:𝑟∈r 3x𝐻×𝑊,其中3为通道数,𝐻×𝑊为空间大小。𝑟首先通过由3× 3核大小的三个卷积层组成的Conv Block进行特征提取和降维,得到浅特征𝑭𝑎∈R 3×𝐻/2 ×𝑊/2。该过程可表示为:

其中𝑆∗𝑗𝑐表示顺序Conv操作,即将操作序列(𝑜𝑛𝑣3×3(⋅))重复𝑗次。其中,𝑜𝑛𝑣3×3(⋅)表示3×3卷积层,而φ(⋅)为ReLU激活函数。然后,使用深度可分卷积层重建特征的空间维度和通道维度𝑭𝑎,同时使用自适应最大池化层减少特征提取和重建过程中可能出现的噪声干扰,得到𝑭𝑏∈R 3×𝐻/2 ×𝑊/2。详细计算过程可表示为:
![]()
式中𝐿𝑚𝑝(⋅)为最大池化层,𝐷𝑊(𝑜𝑛𝑣3×3)(⋅)为3×3深度卷积层,并称1×1卷积层,并称1(⋅)为ReLU激活函数。接下来,利用三个不同尺度的自适应平均池化层提取特征𝑭𝑏中的多尺度颜色信息,得到三个不同的特征{𝑭𝑐1∈r3x𝑙1×𝑙1,𝑭𝑐2∈r3x𝑙2×𝑙2,𝑭𝑐3∈r3x𝑙3×𝑙3}。其中,𝑙1、𝑙2、𝑙3分别等于8、16、32。这些功能融合颜色信息在不同的渠道通过完全连接层,并在三个不同的组的预测转换参数{(𝜙1𝑅𝜙1𝐺,𝜙1𝐵),(𝜙2𝑅𝜙2𝐺,𝜙2𝐵),(𝜙3𝑅𝜙3𝐺,𝜙3𝐵)}。以上过程可以用数学方法定义为:
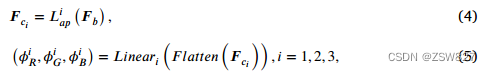
其中,代表对应的𝑖th参数集,𝐿𝑎𝑝(⋅)表示平均池化层,𝑙𝑎𝑡𝑡𝑒𝑛表示平坦化 操作,𝐿𝑛𝑒𝑎𝑟(⋅)表示全连接层。
最后,通过Eq.(1)定义的变换,IDM生成三个不同的灰度图像,表示为{𝑔𝑟𝑎𝑦1,𝑔𝑟𝑎𝑦2,𝑔𝑟𝑎𝑦3}∈r1x𝐻×𝑊,每个图像对应输入的RGB水下图像。这些图像被送入IEEM进行进一步处理。
3.3. 改进的边缘增强模块
改进的边缘增强模块(IEEM)采用拉比等人提出的边缘增强网络(EEN)[61]作为基本结构。EEN最初由Jiang等人提出,通过残差-残差密集块(RRDB)代替传统的密集块来提高边缘增强子网的性能[62]。此外,为了更好地融入所提出的DJL-Net, IEEM基于EEN进行了一系列优化和改进,其结构如图4所示。
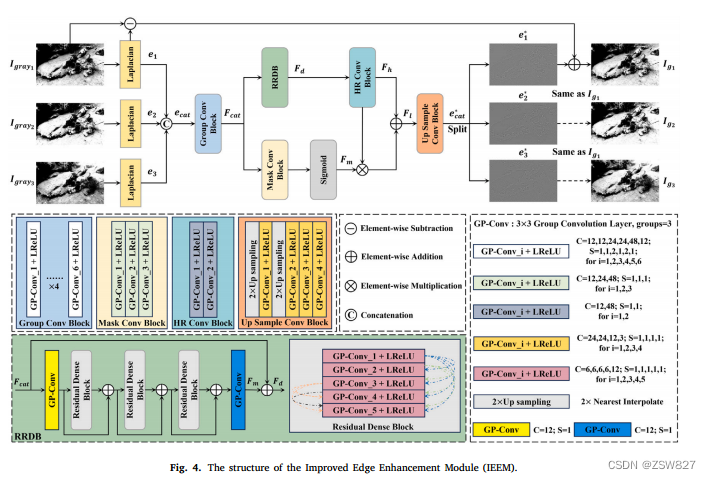
首先,考虑到DJL-Net中IEEM的增强对象是灰度图像而不是RGB彩色图像,IEEM相应地在EEN的基础上减少了卷积通道和RRDB模块的数量。该策略的出发点是灰度图像的像素只包含单一维度的信息,过多的参数可能导致网络学习过程中的过拟合问题。因此,这种优化不仅保证了边缘增强的有效性,而且显著降低了模块的复杂度和计算成本。
其次,考虑到单幅灰度图像所包含的信息有限,传统的增强方法可能会导致边缘特征的丢失。为了解决这个问题,IEEM引入了一种创新的增强范例。IEEM利用IDM生成的三幅不同的灰度图像作为输入,并应用拉普拉斯算子[63]分别提取它们的边缘。然后沿着通道维度将这些边缘图像连接起来,以丰富可用于进一步增强的边缘信息,从而抵消边缘特征的潜在损失。此外,为了有效地提取各种边缘特征,IEEM用群卷积全面取代了原始EEN中的标准卷积。这种调整允许IEEM通过群卷积构造三条平行路径,从而分别增强三幅灰度图像的边缘,更好地捕获和丰富边缘特征。
具体来说,首先通过拉普拉斯算子提取三幅灰度图像{𝑔𝑟𝑎𝑦1,𝑔𝑟𝑎𝑦2,𝑔𝑟𝑎𝑦3}∈r1x𝐻×𝑊的边缘,得到三幅不同的边缘图像{𝒆1,𝒆2,𝒆3}∈r1x𝐻×𝑊。将拉普拉斯式𝛥(首当其冲,首当其冲)定义为图像(首当其冲,首当其冲)的二阶导数,其数学表达式为:

式中,分别表示图像的水平和垂直位置,𝜕2(⋅)𝜕(⋅)2表示求二阶导数的运算。由于拉普拉斯算子具有各向同性和旋转不变性,因此可以根据对图像施加二阶导数后发生的零交叉来确定图像中的边缘。在离散域,对于图像,对图像应用卷积核𝑲得到拉普拉斯算子后的边缘图像𝑬,可以表示为:
![]()
其中𝐿𝑎𝑝表示拉普拉斯算子,*表示二维卷积运算。通过拉普拉斯算子提取边缘信息后,沿通道维度将边缘图像进行拼接,得到复合边缘图像,表示为𝒆𝑐𝑎𝑡∈r 3x𝐻×𝑊。上述过程可描述为:

其中,𝑎𝑡表示沿通道维度的串联操作。接下来,通过组卷积块(Group Conv Block)对𝒆𝑐𝑎𝑡进行特征提取和降维,其中包含六个组卷积层,每个组的核大小为3 × 3,组为3。这个过程产生了浅层特征表示𝑭𝑐𝑎𝑡∈R𝐶1×𝐻/4 ×𝑊/4。可以表示为:
![]()
然后,提取的边缘特征通过RRDB进行传播并逐渐丰富。如图4底部所示,RRDB由两组卷积层和三个重复残差密集块(RDB)组成,残差连接用于传输输入特征信息。特别地,RDB由五个紧密连接的群卷积层组成。假设RDB的输入特征为𝑭𝑛∈R 𝐶×𝐻×𝑊,则RDB中各组卷积层的输入-输出映射关系为:
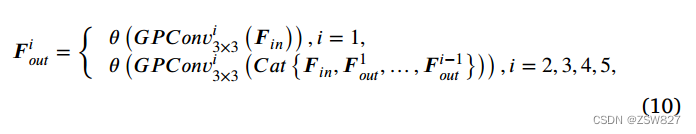
式中𝑭𝑜𝑢𝑡∈R𝑖×𝐻×𝑊表示𝑖th组卷积层的输出特征,𝐺𝑜𝑛𝑣3×3(⋅)表示RDB中的𝑖th 3×3组卷积层。因此,RDB的输入输出映射关系可以表示为:
![]()
其中𝑭𝑜𝑢𝑡∈R 𝐶×𝐻×𝑊为RDB操作后的输出特征,𝑭5𝑜𝑢𝑡∈R 𝐶×𝐻×𝑊为第5组卷积层的输出特征。通过RRDB提炼边缘特征𝑭𝑐𝑎𝑡的整个过程可以描述为:
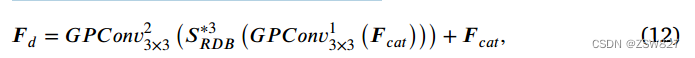
式中𝑭𝑑∈R 𝐶1×𝐻/4 ×𝑊/4为RRDB的输出特征,𝐺 𝑜𝑛𝑣𝑛3×3(⋅)表示RRDB中的𝑛th 3×3组卷积层,𝑆∗3𝑅𝐷表示重复RDB操作三次。随后,利用HR Conv Block进一步提取深边缘特征,表示为𝑭h∈R𝐶2×𝐻/4 ×𝑊/4。可以表示为:

此外,IEEM利用具有sigmoid激活功能的掩模转换块来细化边缘特征𝑭𝑐𝑎𝑡并减轻噪声。上述过程可表示为:
此外,IEEM利用具有sigmoid激活功能的掩模转换块来细化边缘特征𝑭𝑐𝑎𝑡并减轻噪声。上述过程可表示为:

其中𝑠 ̄𝑔𝑚𝑜 ̄𝑑为s型函数。𝑭𝑚∈R𝐶2×𝐻/4 ×𝑊/4是一个权值矩阵,用于细化边缘特征𝑭的值,从而得到最终的边缘特征𝑭𝑙∈R𝐶2×𝐻4 ×𝑊4,可以表示为:

其中⊗表示元素乘法运算。𝑭𝑙通过Up Sample Conv Block进行大小恢复,从而获得增强的边缘图像{𝒆∗1,𝒆∗2,𝒆∗3}。上述过程可定义为:
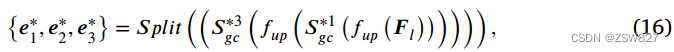
式中𝑆𝑝𝑙 ̄𝑡表示沿通道维数除法运算,𝑓𝑢𝑝表示最接近的2倍上采样插值运算
最后,从增强的边缘表示中减去由拉普拉斯算子勾画的边缘,然后将其重新整合到输入图像中,从而完成边缘增强过程。得到最终边缘增强灰度图像{𝑔1,𝑔2,𝑔3}∈r1x𝐻×𝑊的过程可以表示为:
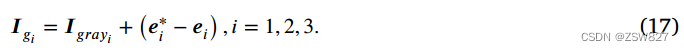
3.4. 三维自适应门控特征融合模块
门控特征融合模块是深度学习中典型的特征融合模块。它可以帮助网络更好地融合不同层次、分辨率或来源的特征,提取更丰富的信息。然而,传统的门控特征融合模块往往只考虑不同特征间通道维度内的信息,而忽略了空间信息在不同特征间选择性融合中的重要性。特别是在目标检测任务中,空间信息对于捕获目标的结构特征至关重要。
本文提出了一种三维自适应门控特征融合模块(TAGFFM)来解决这一问题。TAGFFM分别对特征的通道、高度和宽度维度上的信息进行编码,将不同特征对应的三个维度的信息映射到共同的特征空间,并对通道和空间信息进行建模,从而使通道和空间维度上的信息相互学习和匹配
图5示出了传统门控特征融合模块中编码通道信息的示意图。门控模块使用卷积层对特征层的通道维度信息进行编码,可以表示为:
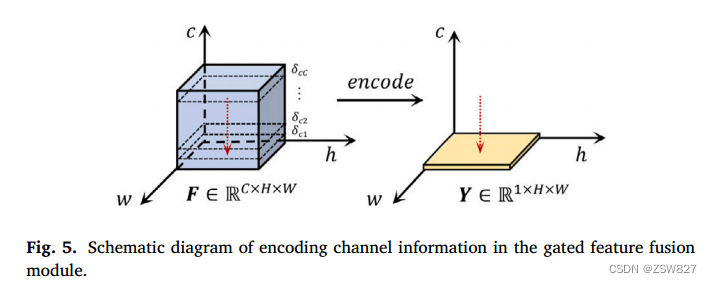
𝑌(ℎ𝑤)表示价值(ℎ𝑤)功能层的𝒀∈R1×𝐻×𝑊后推导出编码沿着通道尺寸(特征图在通道方向上进行编码),𝐶代表数量的渠道功能层的编码,𝛿𝑐代表权重值在编码过程中,和𝐹(ℎ𝑐,𝑤)显示的值(ℎ𝑤)在特征层𝑭∈R𝐶×𝐻×𝑊受制于𝑐th通道编码吗
假设𝑭𝑥∈R𝐶×𝐻×𝑊和𝑭𝑦∈R𝐶×𝐻×𝑊是两个输入功能层。以上过程在𝑭中进行,分别使用卷积运算压缩通道维数的信息,得到编码后的特征映射𝒀∈r1x𝐻×𝑊和𝒀中∈r1x𝐻×𝑊。然后,使用gate函数激活𝒀和𝒀,可以表示为:

通过这种方式,封闭的权重𝑮𝐶𝑥∈[0,1]1×𝐻×𝑊和𝑮𝐶𝑦∈[0,1]1×𝐻×𝑊得到,分别。然后,沿通道方向分别复制𝑮变量变量和𝑮变量变量,将其形状变为R𝐶×𝐻×𝑊。
最后,利用沿通道维度编码的门控权值,得到融合特征𝑭∈R𝐶×𝐻×𝑊。这个过程可以表示为:
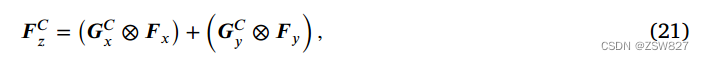
其中⊗表示元素乘法运算。
在这种模式下,门控模块完全依赖信道编码信息来匹配和融合位于不同特征层相同空间位置的特征。然而,这种方法忽略了这些层之间不同空间位置特征信息的交互匹配。为了解决这个问题,如图6所示,本文提出的TAGFFM使用卷积层分别沿宽度(图6中的𝑤轴)和高度(图6中的轴)两个维度对特征进行编码。这个过程可以表示为:
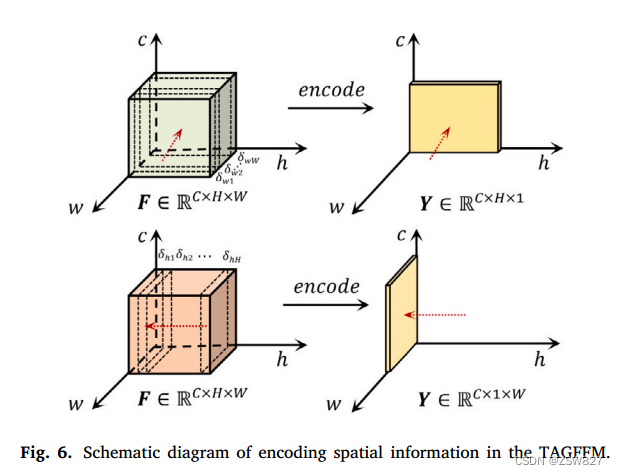

𝑌(ℎ𝑐)代表了价值(ℎ𝑐)功能层的𝒀∈R𝐶×𝐻×1获得编码后沿宽度尺寸(特征图在宽度方向上进行编码),𝑊特征层的编码是宽度,𝛿𝑤代表在编码过程中的权值,和𝐹(ℎ𝑐,𝑤)表示价值(ℎ𝑐)功能层的𝑭∈R𝐶×𝐻×𝑊𝑤th宽度上编码
同理,沿高度维编码得到的特征层𝒀∈R𝐶×1×𝑊在(𝑐,𝑤)处的值𝑌(𝑐,𝑤)可表示为:

根据Eq.(19),最终得到沿宽度和高度维度编码的门控权值𝑮𝑊∈[0,1]𝐶×𝐻×1和𝑮𝐻∈[0,1]𝐶×1×𝑊。同样,沿宽度方向复制𝑮𝑊,沿高度方向复制𝑮𝐻,将它们的形状更改为R𝐶×𝐻×𝑊。最后,分别使用沿宽度和高度维度编码的门控权值,可以得到融合特征𝑭𝑊,∈R𝐶×𝐻×𝑊和𝑭𝐻,∈R𝐶×𝐻×𝑊,其描述如下:
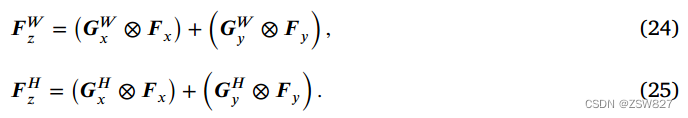
TAGFFM的结构如图7所示。模块的完整机制可以表示为:
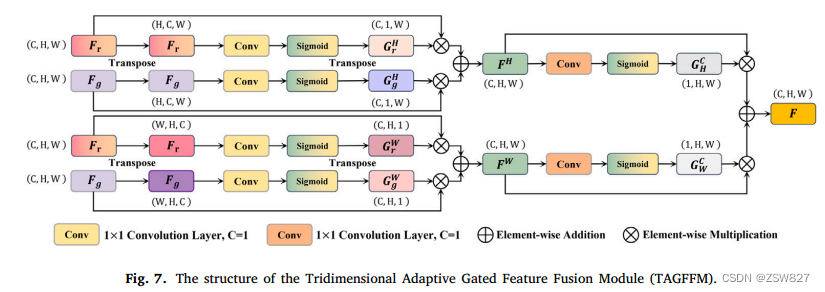
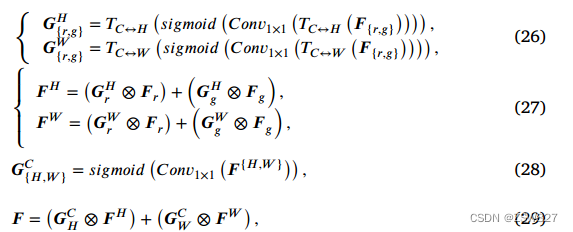
其中{𝑟,𝑔}表示𝑟或𝑔和{𝐻,𝑊}是相同的。𝑮𝐻𝑟和𝑮𝐻𝑔分别是𝑭𝑟和𝑭𝑔在高度维度上的门控权值,𝑮𝑊𝑟和𝑮𝑊𝑔在宽度维度上的定义相同。𝑇𝑎↔𝑏表示维度𝑎和维度𝑏之间的交换操作。𝑭𝐻和𝑭𝑊分别代表了沿高度和宽度两个维度的门控融合,实现了对数据的融合。𝑮𝐻和𝑮𝑊分别表示通道维度中𝑭𝐻和𝑭𝑊的门控权值。
3.5损失函数
值得注意的是,我们提出的DJL-Net中的图像脱色模块(IDM)和改进的边缘增强模块(IEEM)不是为了生成符合人类视觉认知的高质量图像,而是为了生成更好地服务于目标检测任务的图像。因此,DJL-Net只使用目标检测任务的损失来控制多任务联合学习的优化过程,而不添加额外的损失函数。
具体而言,DJL-Net采用端到端优化方式,损失函数与基线方法tod[31]相同,由分类损失𝐿𝑐𝑙𝑠和回归损失𝐿𝑟𝑒𝑔组成。𝐿𝑐𝑙𝑠定义为:
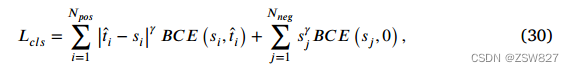
其中,𝑝𝑜𝑠和𝑛𝑒𝑔分别是正锚点和负锚点的个数。萨拉赫表示从正锚中选择的𝑖th锚,而𝑗表示从所有负锚中选择的𝑗th锚。
𝑠ºº是𝑖th正锚的预测分类得分,而𝑡ºº是𝑖th正锚的归一化任务对齐度量,它由分类得分和IoU的高阶组合组成。为焦损的聚焦参数[22]。表示二值交叉熵损失。𝑠𝑗是𝑗th负锚的预测得分。𝐿𝑟𝑒𝑔定义为:

其中𝐿𝐺𝐼𝑜𝑈为GIoU损失[64]。𝑏和𝑏分别为预测的边界框和相应的真值框。总体损失函数为𝐿𝑐𝑙𝑠与𝐿𝑟𝑒𝑔之和,定义为:
















 1552
1552

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









