







作者:老余捞鱼
原创不易,转载请标明出处及原作者。
写在前面的话:在本文中,我将继续带你深入了解如何构建一个时态融合转换器(TFT)模型,用以预测1分钟级别的股票价格。这是整个主题的第二部分,我们将探讨市场微观结构、股票波动性的多维衡量方法,以及盈利事件对股价波动性的显著影响。此外,我还将分享如何通过成交量动态来评估交易活动的强度,以及这些洞察如何转化为机器学习模型(封面图为TFT 预测 AMD 股票的成功示意)。
欢迎回到我们使用时态融合转换器建立高频股价预测模型的系列!在第一部分中,我们介绍了数据收集和准备的基础知识,重点是收集高流动性股票的分钟级数据。现在,我们将深入研究市场微观结构,探索盈利事件、成交量模式和波动率等各种因素是如何相互作用创造交易机会的。通过了解这些关系,我们就能为我们的 TFT 模型设计出更有意义的特征。如果您还没有阅读第 1 部分,我建议您先阅读这一部分,以了解我们的数据管道和初始预处理步骤。让我们进入市场微观结构和技术分析的迷人世界!
第一部分看这里:《实战教学:构建可解释的变换器模型,精准预测股价波动(一)》
一、市场结构概览
在开始构建复杂的特征之前,先明确我们所选股票组合的结构是关键一步。在系列文章的第一篇中,我们已经对初步数据集进行了筛选,专注于那些具有最高流动性的股票。接下来,我们将对这些选定公司的核心特征进行详细审视。
1.1 获取基本数据
首先,我们将使用 yfinance 库为我们宇宙中的每只股票收集基本数据。其中包括行业分类、股权结构和收益日期:
import yfinance as yf
import json
from tqdm import tqdm
fundamental_data = {}
maybe_delisted = []
for stock in tqdm(df["symbol"].unique(), desc="Fetching fundamental data..."):
ticker = yf.Ticker(stock)
try:
ticker_info = ticker.info
fundamental_data[stock] = {
"earning_dates": [date for date in ticker.earnings_dates.index if DATA_START.date() <= date.date() < DATA_CUTOFF.date()],
"sector": ticker_info["sector"],
"industry": ticker_info["industry"],
"total_shares": ticker_info["sharesOutstanding"],
"float_shares": ticker_info["floatShares"],
}
except Exception as e:
maybe_delisted.append(stock)
continue
for stock in fundamental_data.keys():
fundamental_data[stock]["earning_dates"] = [date.strftime("%Y-%m-%d %H:%M:%S") for date in fundamental_data[stock]["earning_dates"]]
with open("fundamental_data.json", "w") as f:
json.dump(fundamental_data, f)
df = df[df["symbol"].isin(list(fundamental_data.keys()))] # df is the same dataframe from part 1. It holds the minute level bars.
df = df[~(df["symbol"] == "GOOGL")] # Google has 2 classes of shares, their price is identical, so we will remove one运行上面的代码后,我们将得到一个包含符号基本面数据的字典。例如,要查看 $AAPL 的基本面数据,我们可以这样做:
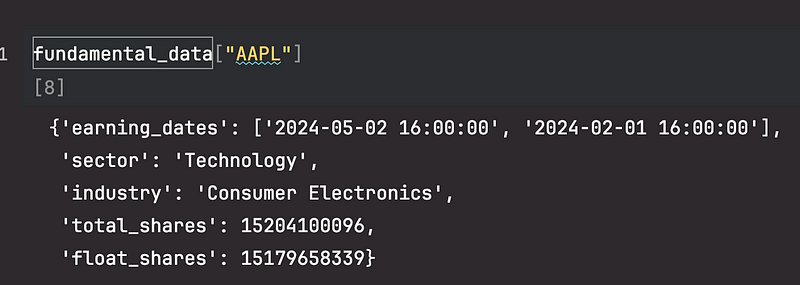
注意:在本教程中,我们只使用从 2024-01-01 开始的数据,因此我们相应地过滤了收入日期。
1.2 分析行业分布情况
现在,我们有了基本面数据,让我们来分析一下股票市场的行业分布:
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
fundamental_df = pd.DataFrame.from_dict(fundamental_data, orient='index')
sector_industry_counts = fundamental_df.groupby(['sector', 'industry']).size().unstack(fill_value=0)
sector_totals = sector_industry_counts.sum(axis=1)
sector_industry_counts = sector_industry_counts.loc[sector_totals.sort_values(ascending=False).index]
plt.figure(figsize=(12, 8))
sector_industry_counts.plot(kind='bar', stacked=True, colormap='viridis', figsize=(12, 8))
plt.title('Number of Stocks per Sector and Industry')
plt.xlabel('Sector')
plt.ylabel('Number of Stocks')
plt.legend(title='Industry', bbox_to_anchor=(1.05, 1), loc='upper left', fontsize='small')
plt.tight_layout()
plt.show()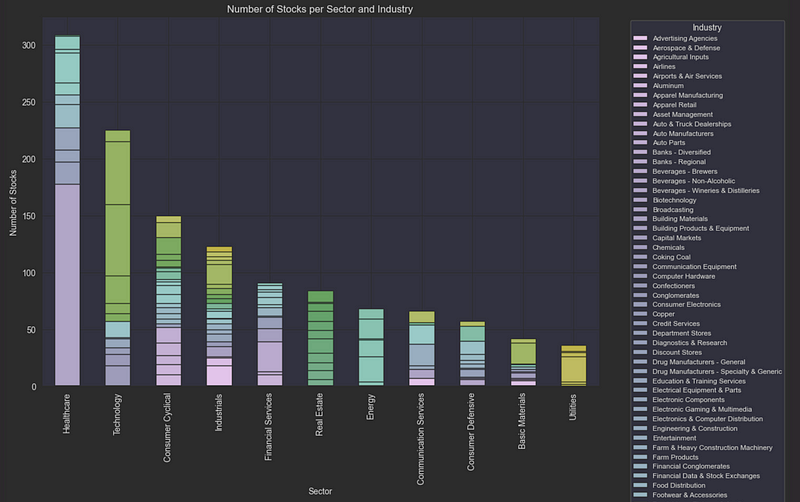
这项分析表明,我们选择的股票范围在各主要行业都有很好的分散性,尤其集中在科技、医疗保健和金融服务领域。这种多样性对我们的模型非常重要,因为它需要学习不同类型股票的通用模式。
1.3 评估股票规模
市值是交易者用来评估股票规模的一个关键指标。计算方法是用股价乘以已发行股票总数。在盘中数据框架中,我将使用当天的开盘价作为股价来计算市值。然后除以 100 万,就得到了以百万为单位的市值。
df["market_cap"] = df.groupby(["symbol", "date"])["open"].transform("first") * df["symbol"].apply(lambda x: fundamental_data[x]["total_shares"]).astype(float) / 1_000_000
# Top 20 stocks by market capitalization
top_20_stocks = df.groupby("symbol")["market_cap"].last().nlargest(20)
# Step 3: Plot the top 20 stocks
plt.figure(figsize=(12, 8))
top_20_stocks.sort_values().plot(kind='barh', color='skyblue')
plt.title("Top 20 Stocks by Market Capitalization")
plt.xlabel("Market Capitalization (in millions)")
plt.ylabel("Stock Symbol")
plt.show()下面是评估出的市值排名前 20 位的股票:
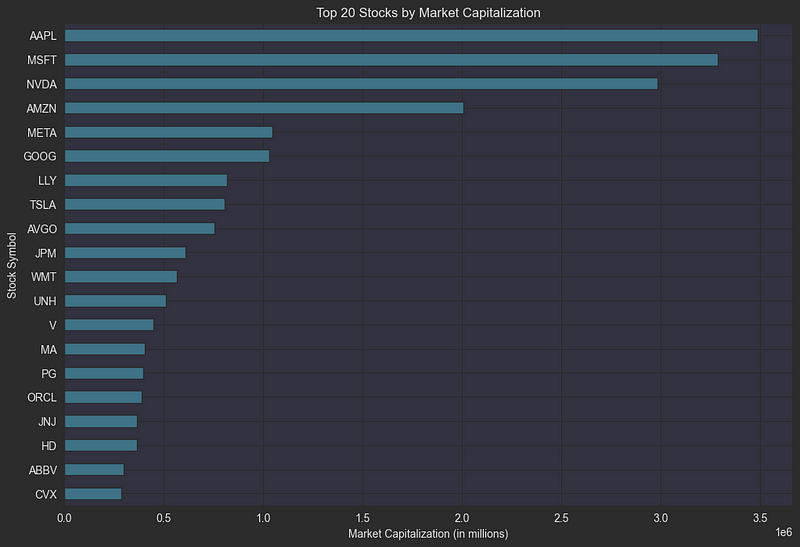
让我们深入探讨日内交易者极为关注的指标——波动性。波动性反映了股票价格的“脉动”,即价格随时间变化的波动幅度。这种波动通过两种主要方式被捕捉:它量化了股票价格在任一方向上的剧烈变动。可以将波动性视为股票的“性格”,有的股票表现平稳,而有的则变动无常。高波动性的股票往往伴随着较高的风险,但它们对日内交易者来说颇具吸引力,因为大幅的价格波动提供了更多的盈利潜力(同时也伴随着更高的亏损风险)。为了将这种波动性量化,我们采用历史波动率来进行计算,具体方法如下:
- 取每日回报的标准偏差
- 按开盘价归一化
- 将结果按年计算(乘以 √252,即一年的交易天数)
这为我们提供了一种标准化的方法来比较不同股票的“紧张度”,而无需考虑它们的价格水平。年化波动率为30%的股票,其价格变动通常要比波动率为15%的股票更为剧烈。
df_daily = df.groupby('symbol').resample('D').agg({
'close': 'last'
}).dropna() # dropna to remove Saturdays and Sundays
# Calculate the daily log returns
df_daily['return'] = df_daily.groupby('symbol')['close'].transform(lambda x: np.log(x / x.shift(1)))
# Calculate the rolling standard deviation of the daily returns
window_size = 30
df_daily['rolling_std'] = df_daily.groupby('symbol')['return'].rolling(window=window_size, min_periods=1).std().reset_index(0, drop=True)
# Annualize the volatility
df_daily['hist_vol'] = (df_daily['rolling_std'] * np.sqrt(252))
df_daily['hist_vol'] = df_daily['hist_vol'].fillna(method='bfill')
# Merge the daily historical volatility back into the original DataFrame
df_daily["symbol"] = df_daily.index.get_level_values(0)
df_daily["datetime"] = df_daily.index.get_level_values(1)
df_daily = df_daily.reset_index(drop=True)
df_daily["date"] = df_daily["datetime"].dt.date
minute_index = df.index
df = df.merge(df_daily[['symbol', 'date', 'hist_vol']], on=['symbol', 'date'], how='left').set_index(minute_index)二、分析交易动态
流通股代表实际可供公开交易的股票数量。虽然一家公司可能有数百万流通股,但流通股通常较少,其计算方法是从流通股总数中减去限制性股票(由内部人员、员工和主要股东持有)。浮动规模对交易动态有重大影响:
- 低流通量股票(可自由交易的股票数量较少)的价格波动往往更大,因为即使交易量适中,也会造成巨大的价格压力.
- 高流通量股票的价格走势通常更为稳定,因为需要更多的成交量才能推动价格变动。
交易者会密切关注浮动水平,因为:
- 价格影响:浮动比率越小,意味着每笔交易对价格的潜在影响越大。
- 流动性风险:低流通量股票可能会出现较大的买卖差价和快速的价格变化。
- 交易量:浮动交易量比有助于衡量有多少可用供应量在积极交易。
在交易低流通量股票时,要注意以下几点:
- 价格波动可能更剧烈、更难以预测。
- 由于流动性限制,头寸规模变得至关重要。
- 由于价差扩大,退出价格可能大大偏离预期水平。
df["shares_float"] = df["symbol"].apply(lambda x: fundamental_data[x]["float_shares"])
hist_and_float_df = df.groupby('symbol').agg({
'hist_vol': 'mean',
'shares_float': 'last',
'market_cap': 'mean'
}).dropna()
# Create a 1x2 grid of plots
fig, axes = plt.subplots(1, 2, figsize=(18, 8))
# Plot 1: Shares Float vs. Historical Volatility
sns.scatterplot(data=hist_and_float_df, x='shares_float', y='hist_vol', alpha=0.5, ax=axes[0])
axes[0].set_xscale('log')
axes[0].set_yscale('log')
axes[0].set_title('Shares Float vs. Historical Volatility')
axes[0].set_xlabel('Shares Float')
axes[0].set_ylabel('Historical Volatility')
# Plot 2: Market Cap vs. Shares Float
sns.scatterplot(data=hist_and_float_df, x='market_cap', y='hist_vol', alpha=0.5, ax=axes[1])
axes[1].set_xscale('log')
axes[1].set_yscale('log')
axes[1].set_title('Market Cap vs. Historical Volatility')
axes[1].set_xlabel('Market Cap (in millions)')
axes[1].set_ylabel('Historical Volatility')
# Show the plots
plt.tight_layout()
plt.show()
股票浮动与历史波动之间的相关性分析:
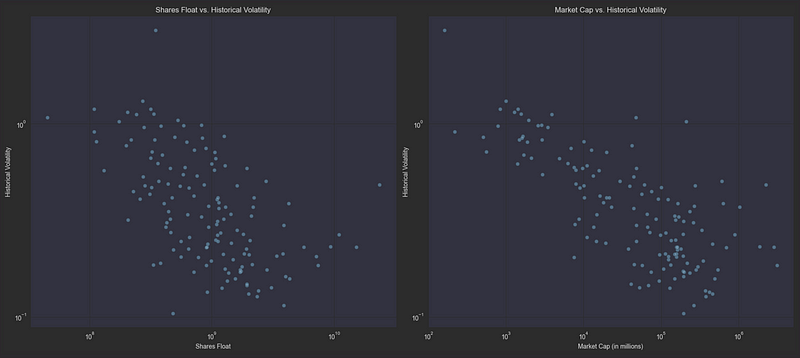
散点图直观地证实了这些关系--股票流通量和市值都与波动率呈明显的负相关。流通盘较小、市值较低的股票(每张图的左侧)始终表现出较高的波动性(在 y 轴上较高),而流通盘较大、市值较高的股票则集中在两张图的右下方,表现出更稳定的价格走势。
三、ATR:衡量日内波动性
平均真实波动范围(ATR)是衡量股票日内波动的有力工具。与只看收盘价的标准波动率衡量方法不同,ATR 可以捕捉整个交易日的全部价格波动范围,因此对日内交易者特别有价值。ATR的工作模式分为两项:
1.首先,我们计算每天的真实波动范围 (TR),它是以下两项中最大的一项:
- 当前高电平减去当前低电平。
- 当前最高价减去前收盘价。
- 前收盘价减当前最低价。
2.然后,将 ATR 计算为这些真实范围值的 14 天移动平均值。该公式考虑了所有的价格缺口和限价移动,提供了一个全面的价格波动视图。
当分析 ATR 时:
- ATR 值越高,表示股票波动越大,价格波动幅度越大。
- 较低的 ATR 值表明价格走势更稳定、更可预测。
- ATR 通常通过除以股票价格进行归一化处理,以便在不同价格水平之间进行比较。
下面是我们的计算方法:
df_daily = get_daily_df(df,{
'close': 'last',
'high': 'max',
'low': 'min'
})
minute_index = df.index
df_daily["TR"] = ta.true_range(high=df_daily['high'], low=df_daily['low'], close=df_daily['close'])
df_daily["ATR"] = ta.atr(high=df_daily['high'], low=df_daily['low'], close=df_daily['close'], length=14)
df = df.merge(df_daily[['symbol', 'date', 'ATR', 'TR']], on=['symbol', 'date'], how='left')
df.set_index(minute_index, inplace=True)
df["ATR"] = df["ATR"].fillna(method='bfill')
df["TR"] = df["TR"].fillna(method='bfill')
df["ATR"] = df["ATR"] / df["close"] # Normalize ATR by the stock price
df["TR"] = df["TR"] / df["close"] # Normalize TR by the stock price虽然 ATR 和历史波动率都能衡量价格走势,但它们捕捉的是市场行为的不同方面。让我们将它们的关系形象化,以了解它们是如何互补的:
- ATR 专注于日内价格范围,包括交易时段之间的间隙。
- 历史波动率考察的是日收益率在一段时间内的离散程度。
- 通过将这些指标相互对照,我们可以识别出哪些股票:
- 在两种衡量标准中都显示出较高的波动性(可能是日间交易的理想候选者)。
- 日波动率较高,但盘中波动幅度较小(容易出现缺口的股票)。
- 显示盘中大幅波动,但每日收盘更加一致。
# plot correlation between ATR and hist_vol
data = df.groupby("symbol").agg({"hist_vol": "mean", "ATR": "mean"}).dropna()
plt.figure(figsize=(12, 8))
sns.scatterplot(data=data, x="ATR", y="hist_vol")
plt.title("ATR vs Historical Volatility")
plt.xscale("log")
plt.yscale("log")
plt.xlabel("ATR")
plt.ylabel("Historical Volatility")
plt.show()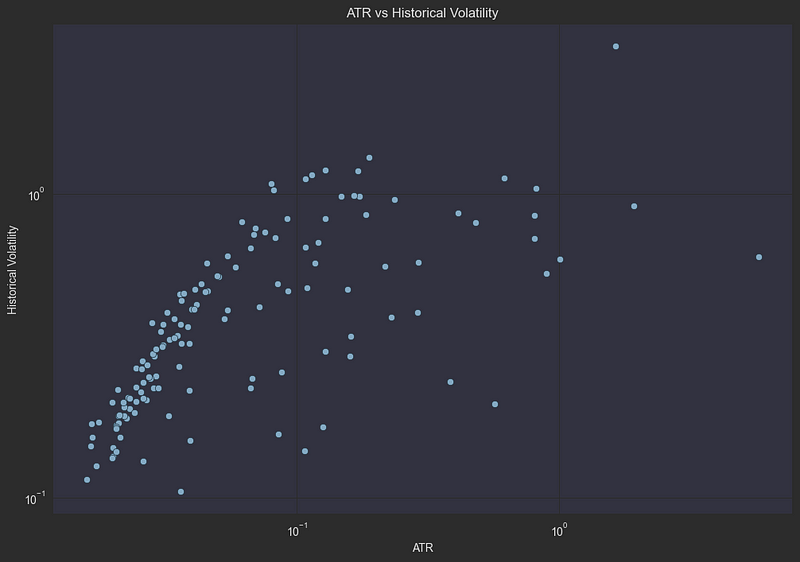
对数散点图显示,ATR 与历史波动率之间存在明显的正相关关系,各点形成明显的对角线形态。这种紧密的关系是有道理的:日内价格大幅波动(高 ATR)的股票往往也会表现出显著的日间收益变化(高历史波动率)。远离主要趋势线的少数离群点可能代表交易模式异常的股票,如受重大新闻事件或公司行动影响的股票。
四、了解盈利事件
盈利公告是股票交易周期中的关键时刻。当市场消化有关公司业绩的新信息时,这些季度事件可能会引发剧烈的价格波动。让我们来探讨一下这些日期为何重要,以及如何衡量它们的影响:
- 公司在开市前("BMO")或收市后("AMC")报告财务业绩。
- 股价反应取决于实际结果与市场预期的对比情况。
- 这些事件往往会导致股价出现最大的单日波动。
- 公告发布后,剧烈波动通常会持续数天。
为了量化收益的影响,我们将比较收益后交易日与正常交易日的价格波动性。我们使用区间-ATR 比率来计算,该比率衡量的是与典型的每日波动相比,一只股票的波动幅度有多大:
from pandas._libs.tslibs.offsets import BDay
def get_next_trading_day(datetime):
bdays = BDay()
the_day_after = datetime + timedelta(days=1)
is_business_day = bdays.is_on_offset(the_day_after)
while not is_business_day:
the_day_after = the_day_after + timedelta(days=1)
is_business_day = bdays.is_on_offset(the_day_after)
return the_day_after
fundamental_data_df = pd.DataFrame.from_dict(fundamental_data, orient='index').explode("earning_dates").dropna()
def get_date_following_earning(date_str):
datetime_ = datetime.strptime(date_str, "%Y-%m-%d %H:%M:%S")
if datetime_.hour < 16:
return datetime_.date()
else:
return get_next_trading_day(datetime_).date()
fundamental_data_df["date_after_earnings"] = fundamental_data_df["earning_dates"].apply(get_date_following_earning)
fundamental_data_df["date"] = fundamental_data_df["earning_dates"].apply(lambda x: datetime.strptime(x, "%Y-%m-%d %H:%M:%S").date())
df_index = df.index
df = df.merge(fundamental_data_df.reset_index()[["index", "date", "date_after_earnings"]], left_on=["symbol", "date"], right_on=["index", "date"], how="left").drop(columns=["index"]).rename(columns={"date_after_earnings": "is_earnings_day"}).fillna(False).set_index(df_index)
df["is_earnings_day"] = df["is_earnings_day"].apply(lambda date: True if date else False)
# range is defined as the intra-day price range of a stock
range = df.groupby(["symbol", "date"])["high"].transform("max") - df.groupby(["symbol", "date"])["low"].transform("min")
df["range_to_ATR_ratio"] = range / df["close"] / df["ATR"]
plot_agg = df.groupby(["symbol", "is_earnings_day"])["range_to_ATR_ratio"].mean().reset_index()
# plot boxplot of TR to ATR ratio on earnings days
plt.figure(figsize=(12, 8))
sns.boxplot(data=plot_agg, x="is_earnings_day", y="range_to_ATR_ratio")
plt.title("Range to ATR ratio on earnings days")
plt.show()下图清楚地显示了盈利公告对价格波动的重大影响。让我们来分析一下我们所看到的:
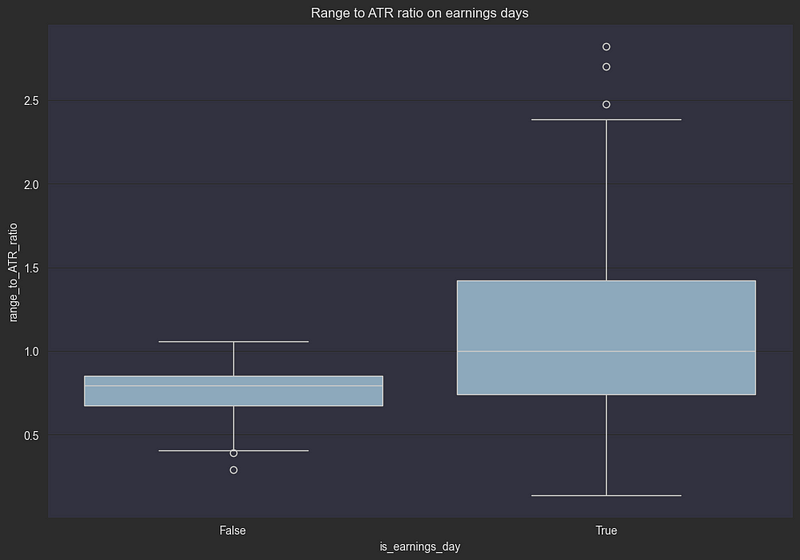
正常交易日(假):
- 中值范围/ATR 比率约为 0.7-0.8
- 紧密的四分位数区间显示出一致的行为
- 0.5 以下的异常值很少
盈利后的日子(真实):
- 中值范围/ATR 比率约为 1.0
- 四分位数范围更广(0.8 至 1.4)
- 几个极端异常值超过正常范围的 2.5 倍
- 底部晶须仍与正常天数相似,表明并非所有收益都会引起波动
这种可视化效果证实,收益日后的价格波动通常比正常交易日高出 40-50% 左右,有些股票的波动幅度是平时的两倍多。这种明显的差异使收益日成为我们 TFT 模型的一个基本特征,因为它可以帮助我们:
- 调整预测置信区间
- 考虑潜在的更大价格波动
- 更好地校准风险管理参数
五、了解成交量动态
成交量是市场活动的重要指标,有助于验证价格走势和识别重要的交易机会。让我们来分析两个关键的成交量指标:
交易量基本情况:
- 指在一个时期内交换的股份总数。
- 高成交量通常预示着 - 重要价格水平正在确立 - 市场动态新闻或事件 - 趋势延续的可能性增加。
日均交易量 (ADV):
- 按每日交易量的 30 天移动平均值计算。
- 为正常贸易活动提供基线。
- 计算公式:ADV = 平均值(过去 30 天的日交易量)。
相对容量(Rel Vol):
- 与典型水平相比,衡量当前的交易活动。
- 计算公式为:累计成交量/日均成交量。
- 解释: - Rel Vol = 1.0:交易节奏正常 - Rel Vol > 1.0:比平时更活跃 - Rel Vol < 1.0:比平时更不活跃。
- 时间敏感性:中午的相对波动率超过 0.7 可能表明交易活动频繁(因为交易日只过去了一半)。
例如,如果一只股票通常每天交易 100 万股:
- 上午 10:00 前 400,000 股 → 相对成交量 = 0.4(上午非常活跃)
- 收盘时为 150 万股 → 相对成交量 = 1.5(高成交量日)
df_daily = get_daily_df(df,{
'volume': 'sum'
})
df_daily = df_daily[df_daily["volume"] > 0]
df_daily["average_volume"] = df_daily.groupby("symbol")["volume"].rolling(window=30, min_periods=1).mean().reset_index(0, drop=True)
df_index = df.index
df = df.merge(df_daily[["symbol", "date", "average_volume"]], on=["symbol", "date"], how="left").set_index(df_index)
df["rel_volume"] = df.groupby(["symbol", "date"])["volume"].cumsum() / df["average_volume"]让我们来验证一个重要的交易假设:清晨异常高的交易量是否预示着当天剩余时间的波动性会增加?我们将通过观察一种特定的情况来研究这个问题:
我们的测试条件:
- 时间:上午 10:00(交易的前半小时)
- 体积阈值:相对体积 > 0.5
- 这意味着什么?只需 30 分钟就能完成半天的典型交易量
- 测量:比较高销量日和正常日的价格范围
high_rel_vol_at_10 = 0.5 # 50% of average daily volume traded in the first half hour
df["is_high_rel_early_candle"] = (df["rel_volume"] > high_rel_vol_at_10) & (df["hour"] == 9)
df["high_rel_volume_day"] = df.groupby(["symbol", "date"])["is_high_rel_early_candle"].transform("max")
# plot boxplot of TR to ATR ratio on high rel volume days compared to regular days
plot_agg = df.groupby(["symbol", "high_rel_volume_day"])["range_to_ATR_ratio"].mean().reset_index()
plt.figure(figsize=(12, 8))
sns.boxplot(data=plot_agg, x="high_rel_volume_day", y="range_to_ATR_ratio")
plt.title("Range to ATR ratio on high rel volume days")
plt.show()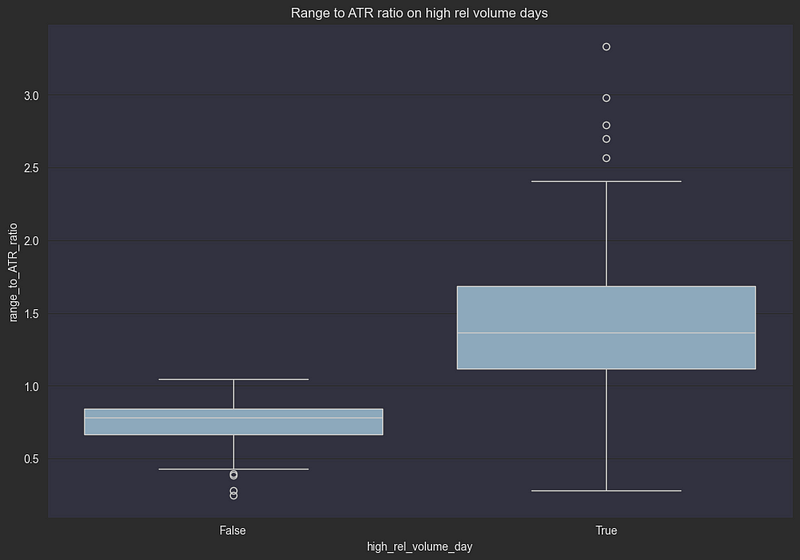
这种可视化方式证实了我们的假设:如果在前 30 分钟内交易了一天的一半交易量,我们就可以预期:
- 比一般价格高出近一倍
- 价格走势更加难以预测
- 出现极端动作的概率更高
让我们来检验一下一个常见的交易观念:高成交量会验证价格走势。这种观点认为,有强劲成交量支撑的走势更有可能持续,而低成交量的走势则可能逆转。我们将通过以下方式进行分析:
我们的衡量标准:
- 初始走势:上午 10:00 股价与开盘价相比的变化
- 继续:上午 10:00 至中午 12:00 期间的平均价格变化
- 成交量背景:上午 10:00 的相对成交量
change_from_open_at_10 = df[(df["hour"] == 10) & (df["minute"] == 0)].groupby(["symbol", "date"])["change_from_open"].first().reset_index()
change_from_open_10_12 = df[(df["hour"] < 12) & (df["hour"] >= 10)].groupby(["symbol", "date"])["change_from_open"].mean().reset_index()
rel_volume_at_10 = df[(df["hour"] == 10) & (df["minute"] == 0)][["symbol", "rel_volume", "date", "ATR"]]joined = change_from_open_at_10.merge(change_from_open_10_12, on=["symbol", "date"], suffixes=("_10", "_10_12_mean"))
joined = joined.merge(rel_volume_at_10, on=["symbol", "date"]).rename(columns={"rel_volume": "rel_volume_10"})
# we want to focus on days where the move is large in the first half hour of the day, like days where the change from open is greater than the ATR
joined = joined[joined["change_from_open_10"].abs() > joined["ATR"]]
change_bins = [-np.inf, -0.10, -0.075, -0.05, -0.025, 0.025, 0.05, 0.075, 0.10, np.inf]
change_labels = ['<-10', '-10 to -7.5', '-7.5 to -5', '-5 to -2.5', '-2.5 to 2.5', '2.5 to 5', '5 to 7.5', '7.5 to 10', '>10']
# Bin the change_from_open_10 values
joined['change_bin'] = pd.cut(joined['change_from_open_10'], bins=change_bins, labels=change_labels, include_lowest=True)
joined["is_positive_change"] = joined["change_from_open_10"] > 0
joined["continuation_move"] = joined["change_from_open_10_12_mean"] - joined["change_from_open_10"]
print(f"Average rel volume at 10:00: {joined['rel_volume_10'].mean()}")
# Scatter plot for negative days
plt.figure(figsize=(10, 6))
sns.scatterplot(x='rel_volume_10', y='continuation_move', hue='change_bin', data=joined, palette='coolwarm', legend='full')
plt.title("Scatter Plot of Continuation vs Relative Volume with Change Bins")
plt.xlabel("Relative Volume at 10 AM")
plt.ylabel("Continuation (10 AM - 12 PM)")
plt.legend(title='Change from Open at 10:00')
plt.vlines(0.65, min(joined['continuation_move']), max(joined['continuation_move']), colors='r', linestyles='dashed')
plt.show()持续时间与相对体积的散点图,带变化分段:
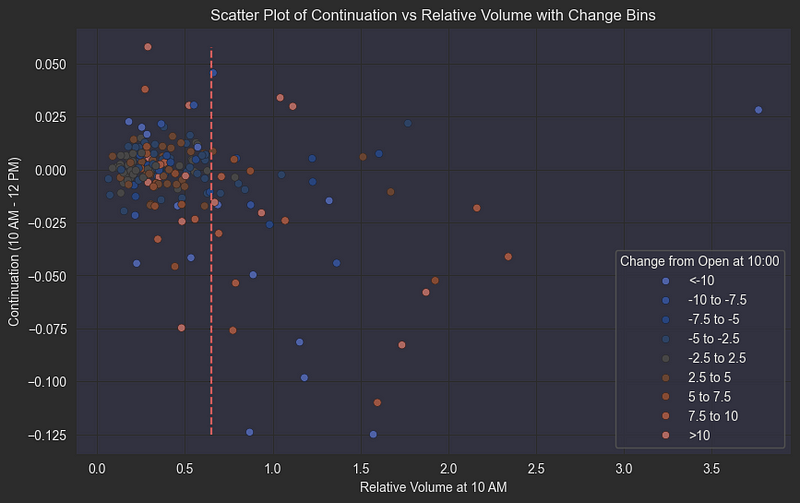
让我们来分析一下这个复杂但却能揭示早期交易量与价格变动模式之间关系的散点图:
- X 轴:上午 10:00 的相对成交量(与日均成交量相比)
- Y 轴:从上午 10:00 到下午 12:00 的价格变化(测量延续或逆转)
- 颜色编码:与上午 10:00 开盘时相比的变化(表示最初的价格方向)
这幅图揭示了引人入胜的市场行为模式:
1. 高成交量上涨移动(红点,高 x 值):
- 当股票在前半小时相对成交量较大的情况下大幅上涨时
- 在接下来的两小时内,这些走势往往会发生逆转
- 暗示潜在获利了结或短期阻力
2.放量下跌(蓝点,高 x 值):
- 早盘急跌,成交量大
- 更有可能在上午时段继续下跌
- 与恐慌性抛售行为和负面情绪连锁反应一致
3.平均/低成交量模式:
- 当相对容量低于 0.6 临界值时
- 价格走势没有明显的延续或反转倾向
- 表明市场参与者信心不足
这种在高成交量下上下波动的不对称行为为我们的预测模型提供了宝贵的洞察力,特别是在关键的上午交易时段识别潜在的延续与反转情况时。
虽然我们选择上午 10:00 和两小时窗口进行分析,但交易者可能需要尝试不同的时间框架(如上午 9:45 或 10:30)和不同的持续窗口。同样,0.6 的相对成交量阈值也可以根据个人交易策略或特定市场条件进行调整。我们将建立的 TFT 模型将帮助我们确定这些决策的最佳参数。
六、观点总结
在本系列的这一部分,我们深入探讨了市场微观结构的迷人世界,并发现了对我们的 TFT 模型至关重要的几种关键关系:
- 市场结构:我们分析了不同行业和市值的流动性股票,为我们的模型奠定了坚实的基础。
- 波动率指标:我们探讨了不同的波动率衡量标准(历史波动率和 ATR)如何相互关联和互补,帮助我们更好地理解价格变动模式。
- 事件影响:我们量化了盈利公告是如何显著增加价格波动的,盈利公告发布后,价格波动幅度会扩大 40-50%。
- 成交量动态:我们发现,早盘的成交量模式可以预测波动的加剧,我们还研究了成交量是如何确认或抵消价格走势的。
七、预告
既然我们已经了解了基本的市场动态,那么我们就可以将这些洞察力转化为强大的预测模型。完成从市场机制到机器学习的学习。在第 3 部分中,我们将:
- 使用技术分析指标建立全面的功能集,包括: - 移动平均线和动量指标 - 支撑线和阻力线。
- 训练我们的时态融合转换器,以预测前向窗口中分钟级的收盘价,包括置信区间。
如果您喜欢我对市场微观结构的深入研究,并想了解我会如何将这些理解转化为交易模型,请务必关注我即将推出的第三部分。
感谢您阅读到最后,希望本文能给您带来新的收获。祝您投资顺利!如果对文中的内容有任何疑问,请给我留言,必复。
本文内容仅限技术探讨和学习,不构成任何投资建议。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











