






一.Hive入门
1.Hadoop
Hive是基于Hadoop产生的重要数据仓库工具,因此要想学习Hive,必须先了解Hadoop。如果读者已经熟悉如何使用Hadoop,那么可以跳过本节。当然,通过阅读本节,读者可以唤醒自己关于Hadoop的记忆,并重新回顾Hadoop的重点概念。
Hadoop是大数据领域应用得最广泛的框架之一,其对海量数据的存储、计算,以及对资源调度分配的支持能力,是众多互联网企业对其青眼有加的重要原因。可以说,Hadoop的发展史就是大数据的发展史 Hadoop的推出解决了大数据开发的诸多难题。以Hadoop为中心发展出的Hadoop生态体系(Hive就是其中之一),使大数据的发展走上了高速路。
Hadoop 由Apache Lucence(Lucence是一个应用广泛的文本搜索系统库)的创始人Doug Cutting开发,其借鉴参考了 Google 的两篇论文-The Google File System和MapReduce:Simplified Data Processing On Large Clusters,开发了Hadoop的两大核心功能模块HDFS和MapReduce。
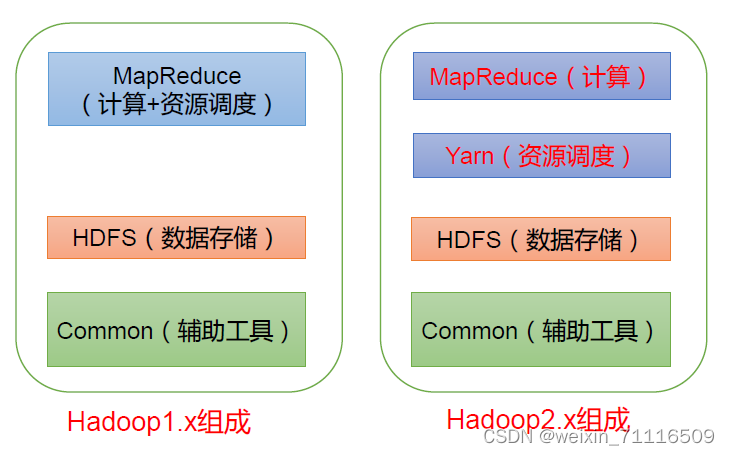
MapReduce:Hadoop提供的分布式数据计算模型。
HDFS:分布式文件存储系统,用于实现海量数据的高可靠存储。
YARN:负责作业调度和资源管理。
common:支持其他Hadoop模块的通用程序包。
2.什么是Hive
3.Hive的架构
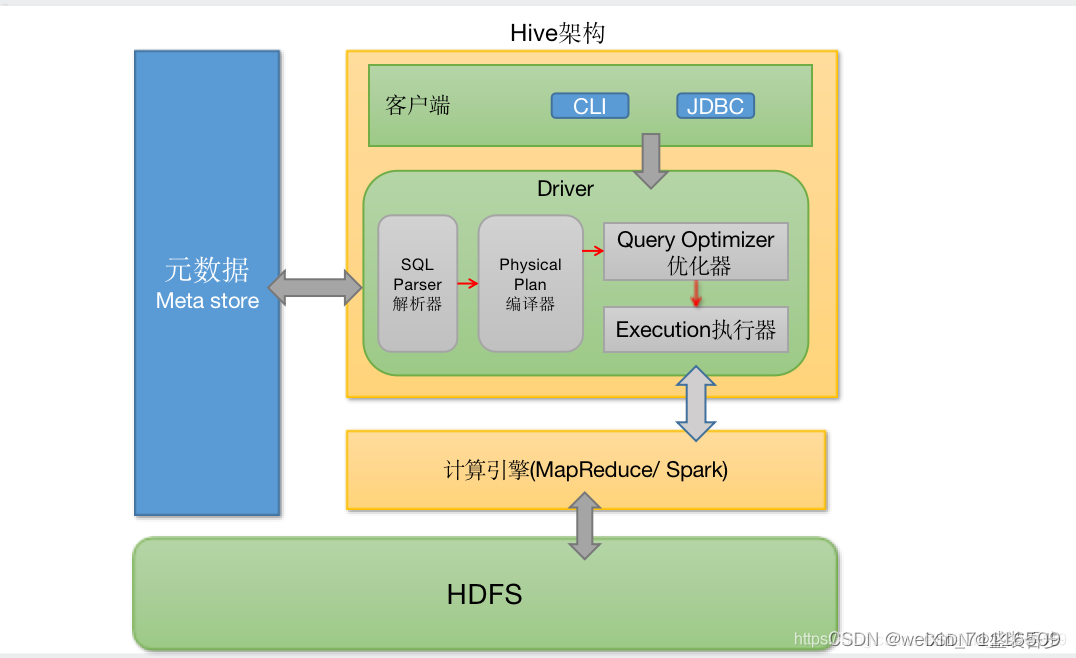
1.用户接口(Client)
Hive的用户接口共有两种,分别是命令行接口(CLI)和JDBC/ODBC协议接口。
2.元数据服务(Metastore)
元数据的含义是描述数据的数据。在Hive中,元数据信息包括数据库、表名、表的所有者、列信息、分区列信息、表的类型、表数据所在目录等。在默认情况下,这些元数据信息存储在Hive自带的 derby数据库中,由derby数据库对外提供元数据服务。但是因为derby数据库默认只支持单客户端访问,而在实际开发中对元数据服务的访问通常是并发的,所以不建议使用默认的derby数据库。推荐使用MySQL存储元数据,并且对外提供元数据服务。
3.驱动器(Driver)
Hive的驱动器包含以下组件:
①解析器(SQLparser)②语义分析器③逻辑计划生成器④逻辑优化器⑤物理计划生成器⑤物理优化器⑦执行器(Execution)
二.Hive基础操作
1.数据定义语言
数据库的定义
1.1创建数据库
create database [if not exists] database_name
[comment database_name]
[location hdfs_path]
[with dbproperties (property_name=property_value,...)];注:若不指定路径,其默认路径为/user/hive/warehouse
1.2.1查询数据库
show database [like '...'];1.2.2查看数据库详细信息
desc database [extended] db_name1.3修改数据库
--修改dbpropertise
alter database database_name set dbproperties (property_name=property_value)
--修改location
alter database database_name set location hdfs_path
--修改owner user
alter database database_name set owner user user_name1.4删除数据库
drop database [if exists] database_name [restrict|cascade];注:restrict表示严格模式,若数据库不为空,则删除失败,默认使用严格模式。cascade表示级联模式若数据库不为空,则会把数据库中的表一起删除。
表的定义
2.1一般创建方式
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] table_name
(
column_name1 data_type1 [COMMENT column_comment1],
column_name2 data_type2 [COMMENT column_comment2],
...
)
[COMMENT table_comment]
[PARTITIONED BY (partition_column_name data_type [COMMENT column_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...) [SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[ROW FORMAT row_format]
[STORED AS file_format]
[LOCATION 'hdfs_path']
[TBLPROPERTIES (property_name=property_value, ...)]
- TEMPORARY:创建临时表,仅在当前session中可见,session结束后自动删除。
- EXTERNAL:创建外部表,数据存储在Hive元数据指定的HDFS位置之外。
- IF NOT EXISTS:如果表已存在,则不执行任何操作。
- PARTITIONED BY:创建分区表。
- CLUSTERED BY 和 SORTED BY:用于指定表的桶和排序方式(高级特性)。
- ROW FORMAT:定义表的数据格式,如
DELIMITED、SERDE等。- STORED AS:指定表的数据存储格式,如
TEXTFILE、ORC、PARQUET等。- LOCATION:指定表在HDFS上的存储位置(主要针对外部表)。
- TBLPROPERTIES:用于设置表的额外属性。
2.2查看表
show tables [in database_name] like []2.3删除表
drop tables [if exists] table_name;2.4清空表
truncate [table] table_name2.数据操作语言
数据加载
LOAD DATA LOCAL INPATH 'filepath' [overwrite] INTO TABLE my_table tablename [partition (partcol1=val1,partcol2=val2...)];LOCAL: 这是一个可选的关键字。如果指定了LOCAL,Hive将从本地文件系统中加载数据;如果不指定,Hive将从HDFS中加载数据。OVERWRITE: 这是一个可选的关键字。如果指定了OVERWRITE,Hive将在加载新数据时覆盖表中的数据;如果不指定,Hive将在表中追加新数据。PARTITION (partcol1=val1, ...): 如果表是分区表,这个关键字允许你指定要加载数据的分区。
数据插入
①查询结果插入表中
INSERT INTO TABLE target_table
SELECT column1, column2, ...
FROM source_table
WHERE condition;insert into: 表示将数据插入到Hive表中
②将给定values插入表中
INSERT INTO TABLE target_partitioned_table PARTITION (partition_column='partition_value')
VALUES (value1, value2, ..., 'partition_value');数据的导出与导入
--导出
export table tablename to 'export_target_path'
--导入
import [external] table new_or_original_tablename from 'source_path' [location 'import_target_path']3. 查询
3.2 基本查询
SELECT [ALL | DISTINCT | DISTINCTROW ]
FROM table_references
[WHERE where_condition] --where子句中不能使用列别名,因为在执行到where子句的时候,尚未对列进行赋别名的操作
[GROUP BY col_name]
[HAVING where_condition] --having子句只能对使用group by子句进行分组统计之后的结果进行过滤,不能单独使用
[ORDER BY col_name]
[LIMIT number]
列别名:列别名指的是为一列起的别名,即对一个列进行重命名。列别名可以紧跟在列名后出现,在列名和列别名之间也可以加入关键字as。
3.3 分组聚合
3.3.1聚合函数
聚合函数、group by子句和having子句经常一起出现
①COUNT(列名)
返回指定列的行数。
语法:COUNT(*) 或 COUNT(column_name)
②SUM(列名)
返回指定列的总和。
语法:SUM(column_name)
③AVG(列名)
返回指定列的平均值。
语法:AVG(column_name)
④MIN(列名)
返回指定列的最小值。
语法:MIN(column_name)
⑤MAX(列名)
返回指定列的最大值。
语法:MAX(column_name)
3.4 join连接
join_table:
table_reference [INNER] JOIN table_factor [join_condition] --内连接
| table_reference {LEFT|RIGHT|FULL} [OUTER] JOIN table_reference join_condition --左外连接,右外连接
| table_reference LEFT SEMI JOIN table_reference join_condition
| table_reference CROSS JOIN table_reference [join_condition] (as of Hive 0.10)
table_reference:
table_factor
| join_table
table_factor:
tbl_name [alias]
| table_subquery alias
| ( table_references )
join_condition:
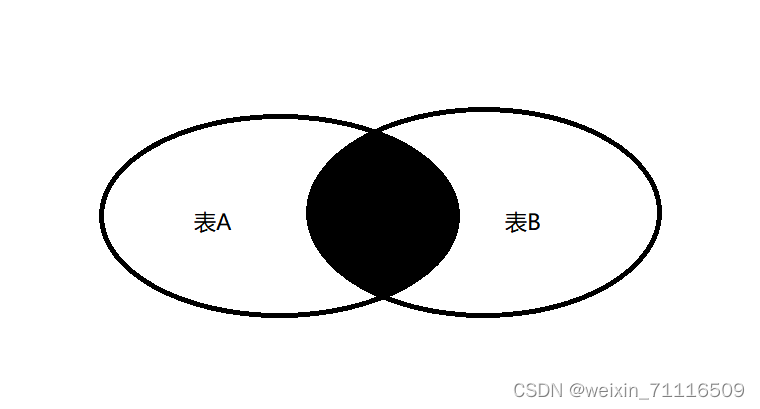
ON expression①内连接
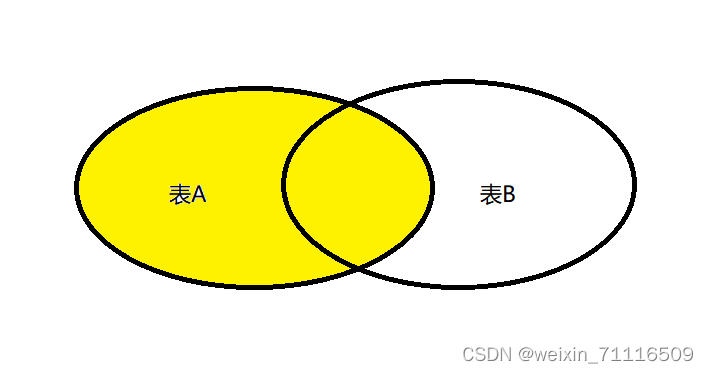
②左外连接
③右外连接
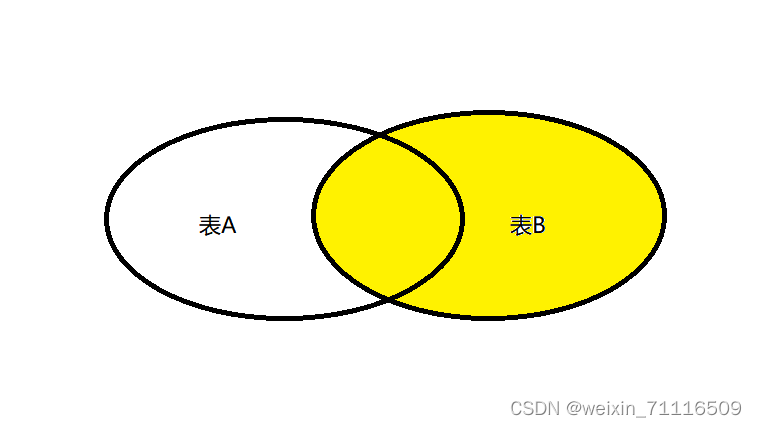
④满外连接
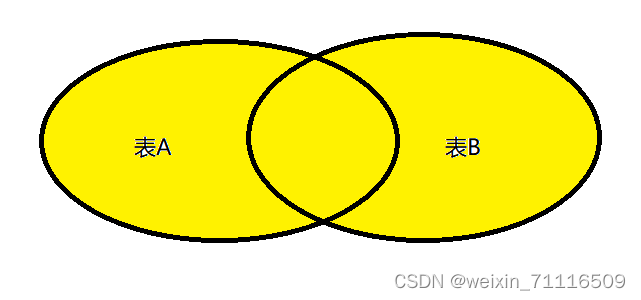
3.5 联合(union&union all)
select_statement UNION [ALL | DISTINCT] select_statement UNION [ALL | DISTINCT] select_statement ...
通过以上语法可以得知,union关键字用于将多个查询语句的结果组成一个结果集。Hive 1.2.0之前的版本只支持union all关键字,也就是不去重的表联合
使用 union 关键字和 union all关键字时,要注意以下几点。
①union 关键字和 union all关键字都是将查询语吾句的查询结果上下联合,这一点和join连接是有区别的,join 连接实现的是两表的“左右连接”,union 关键字和 union all关键字实现的是“上下拼接”。
②union 关键字会对联合结果去重,union all关关键字不去重。
③union 关键字和union all关键字在上下拼接查询语句时要求,两个查询语句的结果,其列的个数和名称必须相同,并且上下对应列的类型必须一致。
三.初级函数
1.单行函数
3.1.1 数值函数
①round:取整函数 语法:round(double A)或round(dauble A,int b)
SELECT ROUND(10.5);
11
SELECT ROUND(10.45, 1);
10.5②ceil:向上取整函数
SELECT CEIL(10.1);
11③floor:向下取整函数
SELECT FLOOR(10.9);
10④rand:随机数函数
SELECT RAND(); -- 返回 0 到 1 之间的随机浮点数
select round(100* rand(),1); --生成0到100的随机数
15.1⑤abs:绝对值函数
SELECT ABS(-10);
103.1.2 字符串函数
①substring:字符串截取函数 语法一:substring(string A,int start) 返回值(string) 语法二:substring(string A,int start,int len) 返回值(string)
SELECT SUBSTR('Hello World', 2);
'ello World'
SELECT SUBSTR('Hello World', -2);
'ld'
SELECT SUBSTR('Hello World', 7, 5);
'World'②replace:字符串替换函数 语法:replace(string A,string B,string C) 返回值(string)
SELECT REPLACE('Hello World', 'World', 'Hive');
'Hello Hive'③regexp_replace:正则替换函数 语法:regexp_replace(string A, pattern, replacement)
SELECT REGEXP_REPLACE('abc123def456','[0-9]','#');
'abc###def###'
SELECT REGEXP_REPLACE('abc123def456','[^0-9]','#');
'###123##456'④regexp:正则匹配函数 返回值:boolean
SELECT 'dfsaaaa' REGEXP 'dfsa+';
true
SELECT 'dfsaaaa' REGEXP 'dfsb+';
false⑤repeat:重复函数 语法:repeat(string A,int n) 返回值:(string)
SELECT REPEAT('123',3);
123123123⑥split:字符串切割函数 语法:split(string str,string pat) 返回值:(array)
SELECT SPLIT('apple,banana,orange', ',');
['apple', 'banana', 'orange']⑦concat:字符串拼接函数 语法:concat(string A,string B,string C,...) 返回值:(string)
SELECT CONCAT('Hello', '-', 'World');
'Hello-World'⑧concat:以指定分隔符拼接字符串或字符串数组 语法:concat_ws(string,string...|array(string))
SELECT CONCAT_WS('-',array('beijing','shanghai','shenzhen'));
'beijing-shanghai-shenzhen'⑨length:字符串长度函数 语法:length(string A) 返回值:(int)
SELECT LENGTH('Hello World');
11⑩lower、upper:字符串大小写转换函数 语法:lower/upper(string A) 返回值:(string)
⑪ltrim、rtrim、trim:空格截取函数 语法:ltrim/rtrim/trim(string A) 返回值:(string)
SELECT TRIM(' Hello World ');
'Hello World'
SELECT LTRIM(' Hello World ');
'Hello World '
SELECT RTRIM(' Hello World ');
' Hello World'
3.1.3 日期函数
①from_unixtime:将UNIX时间戳转换为当前时区的时间格式 语法:from_unixtime(unix_timestamp[, format])
SELECT from_unixtime(1620000000, 'yyyy-MM-dd HH:mm:ss');
"2021-05-01 00:00:00"②unix_timestamp: 语法:unix_timestamp([string date[, string format]])
SELECT unix_timestamp('2021-05-01 00:00:00');
1620000000③year/month/day :获取日期中的年份/月份/日 语法:year/month/day(date/timestamp/string)
SELECT year('2021-05-01');
2021
SELECT month('2021-05-01');
5
SELECT day('2021-05-01');
1 ④datediff:计算两个日期相差的天数,结束日期(enddate)减去开始日期(startdate)得到的天数 语法:datediff(string enddate,string startdate)
SELECT datediff('2021-05-01', '2021-04-25');
6⑤date_sub/date_add:返回日期(date)减少/增加指定天数(days)后的日期 语法:date_sub/date_add(string date,int days)
SELECT date_sub('2021-05-03',2);
2021-05-01
SELECT date)add('2021-05-01',2);
2021-05-03⑥date_format:将标准日期、时间戳或日期字符串解析成指定格式的字符串 语法:date_format(date/timestamp/string, format)
SELECT date_format('2021-05-01', 'dd MMMM yyyy'); --y:年--M:月--d:日--u:星期--H:小时--m:分钟
"01 May 2021"
3.1.4 流程控制函数
①nvl:控制查找函数 语法:nvl(A,B) 说明:若A的值为null,返回B
②case when:条件判断函数 语法一:case when a then b [when c then d]*[else e] end
case
when a then b
[when c then d]
[else e]
end --语法一
case a
when b then c
[when d then e]
[else f]
end --语法二:如果a等于b则返回c,a等于d则返回e,否则返回f
③if:条件判断 语法:if(boolean testCondition,T value True,T valueFalse)
SELECT if(10 > 5,'true','false');
'true'3.1.5 综合案例
https://blog.csdn.net/weixin_71116509/article/details/139933796?spm=1001.2014.3001.5502
四.高级函数
1.表生成函数
①explode函数
explode(array<T>a) :传入参数为array数组类型,返回一行或多行结果,每行对应array数组中的一个元素 explode(map<K,V>m) :传入参数为map类型,由于map类型的结构为key-value,所以explode函数会将map类型参数转换为两列,一列是key,另一列是value
SELECT explode(array("a","b","c")) as item;
item
a
b
c
SELECT explode(map("a",1,"b",2,"c",3)) as (key,value)
key value
a 1
b 2
c 3②posexplode函数
posexplode(array<T>a):posexplode函数的用法与explode函数相似,但其增加了pos前缀,表明在返回array数组类型的每个元素的同时,还会返回元素在数据中所处的位置
SELECT posexplode(array("a","b","c")) as(pos,item);
pos item
0 a
1 b
2 c2.窗口函数
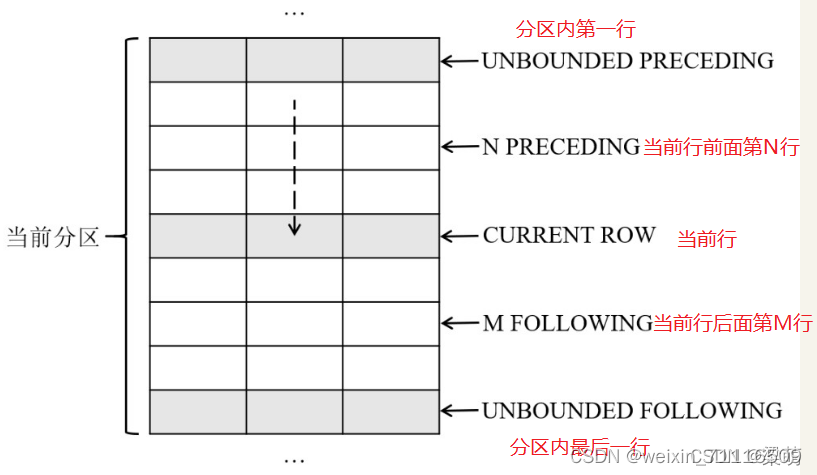
基于行的窗口范围定义语法: sum(amount) over (order by <column> rows between <start> and <end>)
基于值的窗口范围定义语法: sum(amount) over (order by <column> range between <start> and <end>)
4.2.1 跨行取值函数
①lead函数:用于获取窗口号内当前行往下第n行的值 lead(col,n,default):第一个参数为列名,第二个参数为往下第n行,第三个参数为往下第n行遇到null时所取的默认值,第二个参数可选,其默认值为1,第三个参数的默认值为null
②lag函数:用于获取窗口号内当前行往上第n行的值 lag(col,n,default):第一个参数为列名,第二个参数为往上第n行,第三个参数为往上第n行遇到null时所取的默认值,第二个参数可选,其默认值为1,第三个参数的默认值为null
SELECT
id,
date
value,
LAG(value,1) OVER (PARTITION BY date ORDER BY id) AS previous_value
LEAD(value,1) OVER (PARTITION BY date ORDER BY id) AS following_value
FROM
your_table;4.2.2 排名函数
①rank函数:为结果集中的每一行分配一个排名,如果两行或多行具有相同的值,则它们会获得相同的排名,并且下一个排名会跳过相应的数量。
②dense_rank函数:为结果集中的每一行分配一个排名,如果两行或多行具有相同的值,则它们会获得相同的排名,但是排名号不会跳过。
③row_number函数:为结果集中的每一行分配一个唯一的连续整数,不考虑值是否相同,都会为每一行分配一个不同的排名。
还在完善中...















 296
296

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









