






目录
索引概述
索引(index)是帮助MySQL高效获取数据的数据结构(有序)。在数据之外,数据库系统还维护这满足特定查找算法的数据结构,这些数据结构以某种方式引用(指向)数据,这样就可以在这些数据结构上实现高级的查找算法,这种数据结构就是索引。
优点:
1、提高数据检索的效率,降低数据库的IO成本
2、通过索引列队数据进行排序,降低数据的排序成本,降低CPU的消耗
缺点:
1、索引列也是要占用空间的
2、索引大大提高了查询效率,同时却降低了更新表的速度,如果对表进行INSERT、UPDATE、DELETE时,效率降低
索引结构
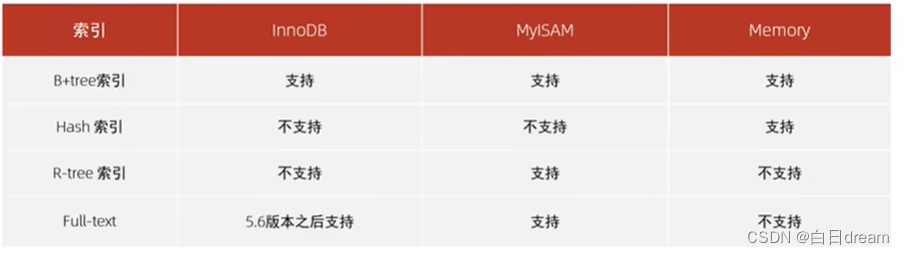
MySQL的索引是在引擎层实现的,不同的存储引擎有不同的结构,主要包含一下几种:

不同的存储引擎对索引结构支持情况:
数据结构: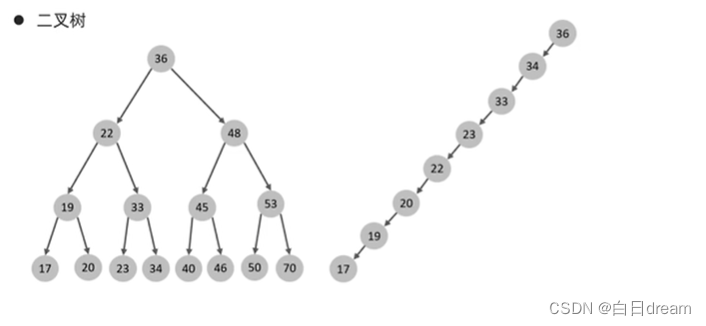
缺点:顺序插入时,会形成一个链表(如上图右侧),查询性能大大降低。大数据量情况下,层级较深,检索速度慢。
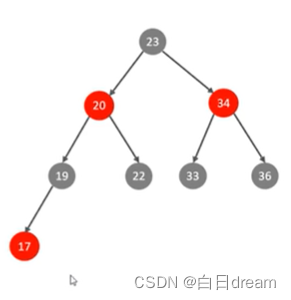
红黑树:有效解决二叉树顺序插入时形成链表的缺点,但是依然存在大数据量情况下层级较深、检索速度慢的弊端。
B-tree(多路平衡查找树):
以一颗最大度数(Max-degree)为5 的B-tree为例:
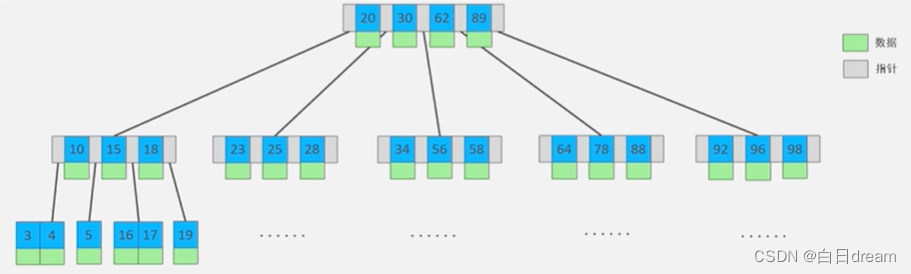
每个节点最多储存4个Key,5个指针。
B+tree:
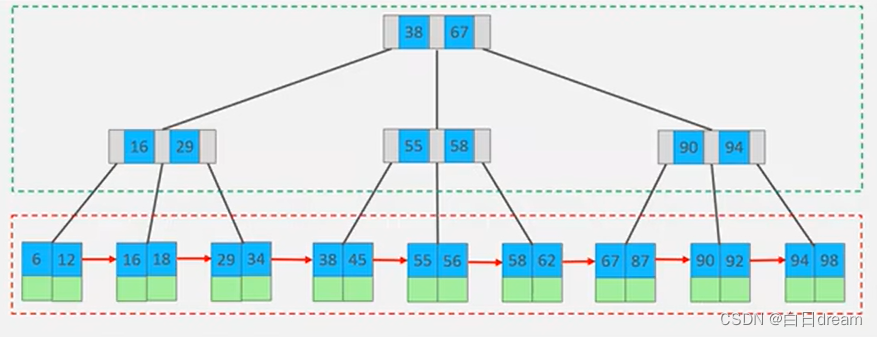
与B-tree 不同的是所有的元素都会出现在叶子结点,形成一个单向链表。如上图红色虚线内所示。
Hash索引;
哈希索引就是采用一定的Hash算法,将键值换算成hash值,映射到对应的槽位上,然后存储在hash表中。如果两个(或多个)键值,映射到一个相同的槽位上,他们就产生了hash冲突(也称之为hash碰撞),可以通过链表来解决。
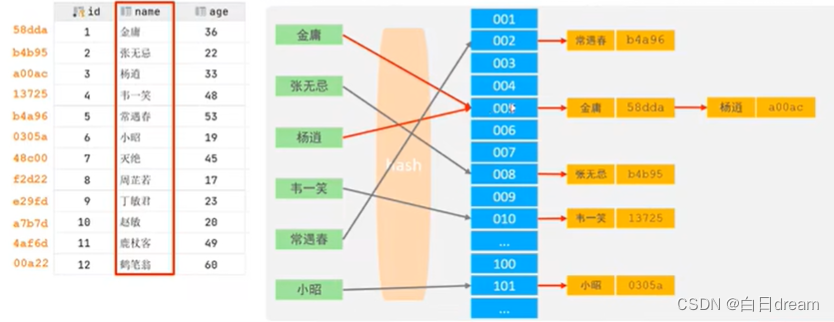
hash索引特点:
1、Hash索引只能用于对等比较(=,in),不支持范围查询(between,>,<,...)
2、无法利用索引完成排序操作
3、查询效率高,通常只需要一次(不出现hash碰撞情况下)检索就可以了,效率通常要高于B+tree索引
索引分类

在innoDB存储引擎中,根据索引的储存形式,又可以分位以下两种;

聚集索引选取规则:
如果存在主键,主键索引则是聚集索引。
如果不存在主键,将使用第一个唯一(unique)索引作为聚集索引。
如果表没有主键,或没有合适的唯一索引,则innoDB会自动生成一个rowID作为隐藏的聚集索引。















 10万+
10万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









