







现在的编译器大多流行小端模式如VS20222,Dev-c++等;
其中小端模式如下;存储顺序是倒的。
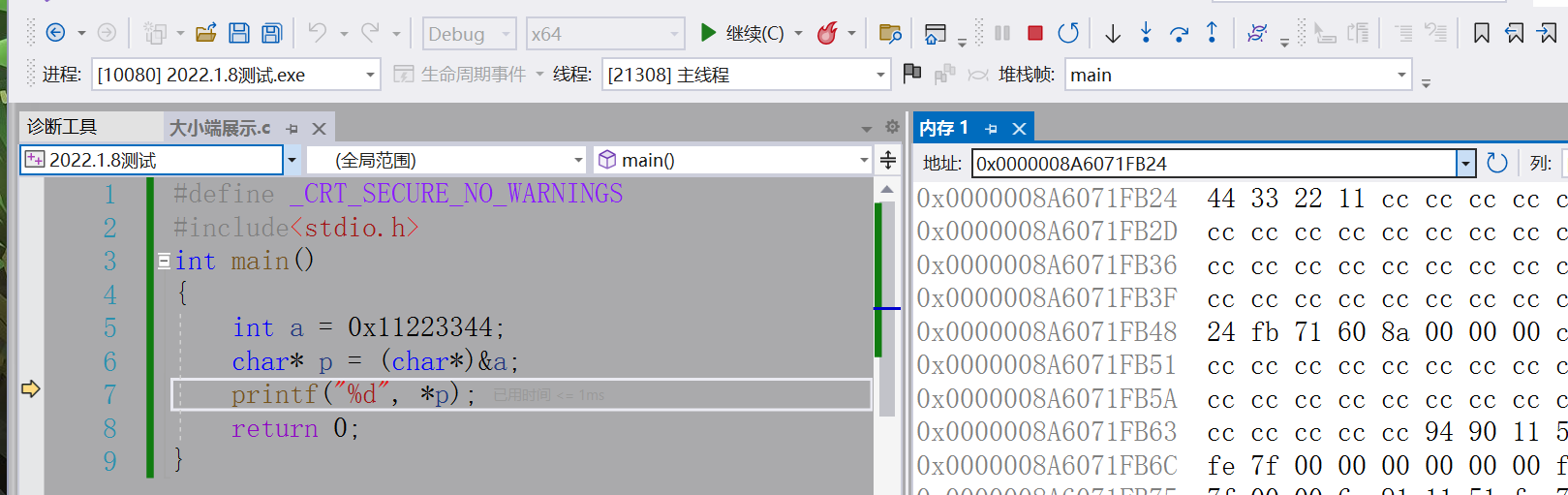
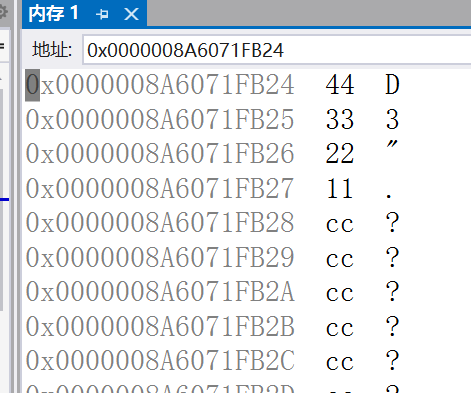
而大端(存储)方式的顺序是正的,如
int a=0x11223344
存储中是按11 22 33 44的顺序存储。
地址以数据的低位保存在内存的低地址中,而数据的高位,保存在内存的高地
址中。
什么是大端小端:
大端(存储)模式,是指数据的低位保存在内存的高地址中,而数据的高位,保存在内存的低地址
中;
小端(存储)模式,是指数据的低位保存在内存的低地址中,而数据的高位,保存在内存的高地
址中。
为什么会有大小端模式之分呢?
是因为在许算机系统,我们是以字节为单位的,每个地址单元
都对应着一个字节, -个字节为8 bit.但是在C语言中除了8 bit的char之外,还有16 bit的short
型,32 bit的long型(要看具体的编译器),另外,对于位数大于8位的处理器,例如1 6位或者32
位的处理器,由于寄存器宽度大于一个字节,那么必然存在着一个如何将多个字节安排的问题。因
此就导致了大端存储模式和小端存储模式.
大小端的选择取决于具体应用场景和硬件平台的要求。在网络通信、嵌入式系统等领域,通常采用小端模式;而在一些高性能计算和大规模数据处理任务中,可能会采用大端模式。
百度面试曾出现过一道与之相关的题目:
编写判断编译器为大小端的程序
判断的原理是根据是否低位保存在内存的低地址中。
#include<stdio.h>
/*int check_sys()
{
int a=1;
char*p=(char*)&a;
if(*p==1)
return 1;
else
return 0;
}*/
int check_sys()
{
int a=1;
return *(char*)&a;
}
int main()
{
int ret = check_sys();
if(1 == ret)
{
printf("小端");
}
else
{
printf("大端");
}
}














 724
724











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









