






目录
一、简介
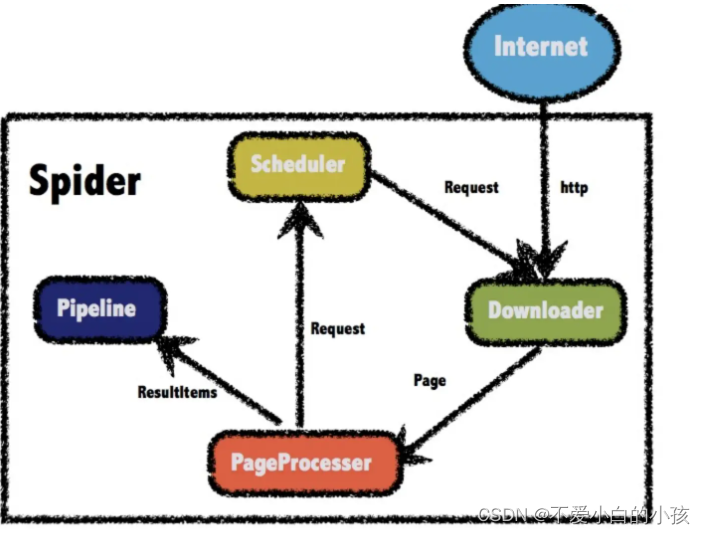
是一个爬虫框架,把爬虫开发层次化。
有4个组件
Downloader :通过url下载页面
PageProcess:解析Downloader下载后的 html页面
pipeline:数据持久层,处理PageProcess数据解析后有关的操作(保存)
Scheduler:初始化操作,前面组件编写完成后 对它们进行初始化
二、Downloader
1、简介
下载器组件,使用HttpClient实现,如果没有特殊需求,不需要自定义,默认的组件就可以满足全部需求 自定义时候需要实现Downloader接口 向PageProcess传递数据时候,把结果封装成Page对象
和PageProcesser可以通过Request(需要是同一个Request)的会话域进行会话
request.getExtra("key") //获得会话域的值
request.put("key",value) //向会话域发送值
当需要解析动态页面时候需要配合无头浏览器,就需要自定义Downloader
2、配置
自定义Downloader,需要继承Downloader接口
配置无头浏览器都在这个方法(保证无头浏览器可以多线程运行),已以及获取页面html,
获取后把html数据封装到page并且返回,在返回前可以request.put("key",value),告诉
PageProcesser当前是哪个url页面,这样PageProesser只要根据 request.getExtra("key")就能知道当前是哪个页面,不用再获取DOM判断
public Page download(Request request, Task task)
这个方法使用默认的就好
public void setThread(int i)
例如:配合无头浏览器的Downloader
//获取dom等操作都是使用的Selenium的api
@Component
public class MyDownloader implements Downloader {
//驱动
public MyDownloader(){
}
//下载html页面
/**
* 主页面
*
*
*判断是不是主页面
* #HomeRecommend 判断主页
* 是主页面就直接获取
* 不是就下划页面后获取(能) .img-warp 判断阅读 页面
*
*
*/
@Override
public Page download(Request request, Task task) {
//创建驱动
RemoteWebDriver driver;
//谷歌浏览器驱动位置(配置谷歌浏览器)
System.setProperty("webdriver.chrome.driver","D:\\C(RJ)\\Chrome\\Application\\chromedriver.exe");
//创建谷歌浏览器驱动
ChromeOptions chromeOptions=new ChromeOptions();
//解决 403 出错问题
chromeOptions.addArguments("--remote-allow-origins=*");
// 设置为headless模式 (必须) //无头浏览模式
//chromeOptions.addArguments("--headless");
//设置浏览器窗口打开大小 (必须)
chromeOptions.addArguments("--window-size=1366,700");
driver=new ChromeDriver(chromeOptions);
driver.get(request.getUrl());//打开无头浏览器跳转页面
// System.out.println(driver.getPageSource());
// dua;
//关闭弹窗
try {
WebElement dua= driver.findElement(new By.ByCssSelector(".close"));//找到弹窗的关闭DOM
System.out.println("输出节点"+dua.toString());
if (dua.isDisplayed()) {
//如果可见(即弹出)
dua.click(); //就点击
}
}catch (Exception e){
System.out.println("不是第一次");
}
//判断是否是主页
Boolean ishome=false;
try {
WebElement home =driver.findElement(new By.ByCssSelector("#HomeRecommend"));
ishome=true;
}catch (Exception e){
ishome=false;
}
if(ishome){
//如果是主页面
//还有判断是不是需要搜索框的操作(未完成)
//滑屏操作
driver.executeScript(" {\n" +
" let he= setInterval(()=>{\n" +
" //每次移动100\n" +
" document.documentElement.scrollTop+=100;\n" +
" //document.documentElement.scrollHeight\n" +
" if(document.documentElement.scrollTop>=(document.documentElement.scrollHeight-document.documentElement.scrollWidth)){\n" +
" clearInterval(he);\n" +
" console.log(\"停止\")\n" +
" }\n" +
" },50); //可以改变计计时器频率来代表速度\n" +
" }");
//等待页面加载
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
//直接返回页面
request.putExtra("key","home");//告诉会话域当前对应的是 主页面
return getPage(request.getUrl(),driver.getPageSource(),request,driver);
}else {
//滑屏操作
driver.executeScript(" {\n" +
" let he= setInterval(()=>{\n" +
" //每次移动100\n" +
" document.documentElement.scrollTop+=100;\n" +
" //document.documentElement.scrollHeight\n" +
" if(document.documentElement.scrollTop>=(document.documentElement.scrollHeight-document.documentElement.scrollWidth)){\n" +
" clearInterval(he);\n" +
" console.log(\"停止\")\n" +
" }\n" +
" },20); //可以改变计计时器频率来代表速度\n" +
" }");
//睡眠等待 页面加载
try {
Thread.sleep(8000);
} catch (InterruptedException e) {
e.printStackTrace();
}
//通过页面某个元素判断页面是阅读页面还是详情页面
Boolean isShow=true;
try {
WebElement show=driver.findElement(new By.ByCssSelector(".img-warp"));
isShow=true;
}catch (Exception e){
isShow=false;
}
if(isShow){
//是阅读界面
//直接返回页面
request.putExtra("key","show");//告诉会话域当前对应的是 主页面
return getPage(request.getUrl(),driver.getPageSource(),request,driver);
}else {
//直接返回页面
request.putExtra("key","details");//告诉会话域当前对应的是 主页面
return getPage(request.getUrl(),driver.getPageSource(),request,driver);
}
}
}
//封装page,并且在封装前把无头浏览器关闭
private Page getPage(String url,String html,Request request,RemoteWebDriver driver){
Page page=new Page();
//封装html
page.setRawText(html);
//封装url (文本信息)
page.setUrl(new PlainText(url));
//设置Request对象(必须)
page.setRequest(request );
driver.close();
return page;
}
//默认就好
@Override
public void setThread(int i) {
}
}二、PageProess
1、简介
作用:对Downloader中封装好的html进行解析,通过获取dom获取页面数据
常用api
page.putField("key",value); //把数据通过key-value传输pipeline;
request.getExtra("key") //获取会话域中的数据,通常用于与Downloader会话
Selectable titlel= html.css(".title") //通过css选择器获取页面节点
2、内部组件
(1)Site
需要特殊获取一些信息时候使用, 一般使用默认的就好,如果真需要设置后通过
download中的task.getSite() 获取信息配置无头浏览器,那还不如直接配置无头浏览器。
常用api
可以设置抓取的频率 重试的次数 超时时间 等
setCharset(String) 设置编码 setUserAgent(String) 设置UserAgent 信息头 setTimeOut(int) 设置超时时间 毫秒 setRetryTimes(int) 设置重试次数 setCycleRetryTimes(int) 设置循环重试次数 addCookie(String,String) 添加一跳cookie setDomain(String) 设置域名,需要设置域名后addCookie才可以生效 addHeader(String,String) 添加一条addHeader setHttpProxy(HttpHost) 设置Http代理 没有特殊需求直接使用默认即可
(2)、Page (重要)
Html html= page.getHtml(); //获取html页面
getResultItems(): 返回ResultItems对象,向pipeline传递数据时候使用 (使用putField更好)
page.putField("titlel",titlel); //把数据通过key-value传输pipeline;
page.addTargetRequests(urllst)、addTargetRequest(url) :向scheduler对象中添加url,url最终会被传输到线程池中(即需要Downloader提取html页面的下一个地址)
(3)HTML(重要)
html也是一个Selectable对象 一个selectable就可以表示一个dom节点
使用html解析页面的三种方式
1、使用原生的jsoup方法进行解析
Document document=html.getDocument();
2、使用css选择器解析(常用,推荐使用)
html.css("选择器)
html.$("选择器") 和 html.css("选择器) 等价
例如:
获取全部相关的节点
List<Selectable> list=html.css(".padding16").nodes(); //获取要提取
获取节点(Selectable节点)
Selectable titlel= html.css(".title") //多个节点时候会默认获取第一个
获取标签的内部文本信息
Selectable titlel=html.css(".title","text") //获取标签的内部文本信息 <h3>文本信息</h3>
获取标签内单独的属性值
Selectable titlel= html.css(".title","class") // 获取标签内单独的属性值
多次筛选
Selectable titlel= html.css("div").css(".intrTextBox");//推荐在第一个css直选出
输出节点的内容
List list= titlel.all() //获得全部
titlel.toString 转换成字符串 和titlel.get() 一样 如果返回结果是一个dom列表 只返回第一个元素
page.putField("titlel",titlel); //相当于titlel.toString 只会输出一个节点
page.putField("titlel",titlel.all());3、使用xpath解析(不推荐)
(4)Request
并不是Http请求的Request对象,就是url封装成Request对象
可以实现 Downloader 和PageProcess的通信
同一个url中进行会话域
Request request=new Request("url")
request.getExtra("key")
request.put("key",value)
(5)、ResultItems(没啥用)
数据传递对象 作用就是把解析的结果传递给pipeline 可以使用page对象的geiResultItems()方法获得此对象 也可以直接使用putField将数据添加到ResultItems对象中
PageProess必须自定义,需要继承PageProcessor接口
public void process(Page page) //必须重写
public Site getSite();//可以返回一个Site.me(),必须返回一个Site
项目中例子:
@Component
public class MyPageProcessor implements PageProcessor {
@Override
//必须重写
public void process(Page page) {
Html html=page.getHtml();
String url=page.getUrl().toString();
System.out.println("路径:"+url);
// System.out.println(html.toString());
//获取key判断是啷个界面
String key=(String) page.getRequest().getExtra("key");
if(key.equals("home")){
//如果是主页面
ResHome(html,url,page);
}else if(key.equals("show")){
ResShow(html,url,page);
}else if (key.equals("details")){
ResDetails(html,url,page);
}else {
System.out.println("不能爬取");
}
}
//自创建方法
//处理详情页面
private void ResDetails(Html html,String ymUrl,Page page) {
//.imgCover 图片和名字
//每集链接 .cover>a
//标题 h3[class="title"]
//简介 .detailsBox>p
//临时变量
Details details =new Details();
//集数地址和名字
List<Url> temUrl=new ArrayList<>();
//集数地址
// List<String> tem=new ArrayList<>();
//本页地址
details.setUrl(ymUrl);
//本页图片
//简介
details.setIntro(html.css(".detailsBox>p","text").toString());
//标题
details.setName(html.css("h3[class=title]","text").toString());
List<Selectable> list=html.css(".cover>a").nodes();
for (Selectable da:list){
Url url=new Url();
url.setUrl( da.css("a","href").toString()); //集数地址
url.setName( da.css(".imgCover","alt").toString());//集数名字
temUrl.add(url);
page.addTargetRequest("https://www.kuaikanmanhua.com"+url.getUrl());
}
details.setUrlAll(temUrl);
page.putField("details",details);
}
//自创建方法
//处理 阅读列表
private void ResShow(Html html,String url,Page page) {
//创建临时存储对象
Imgs imgs=new Imgs();
imgs.setUrl(url);
//临时存储。图片
List<String> tem=new ArrayList<>();
List<Selectable> list=html.css(".img-box>img").nodes();
for (Selectable Img:list){
tem.add(Img.css(".img","src").toString());
}
imgs.setImgs(tem);
page.putField("imgs",imgs);
}
//自创建方法
//处理主页面
private void ResHome(Html html,String url,Page page) {
//.获取padding16
List<Selectable> list=html.css(".padding16").nodes(); //获取要提取
//临时存储
List<HomeBean> homeList=new ArrayList<>();
for (Selectable selectable: list){
HomeBean home =new HomeBean();
home.setUrl(url+ selectable.css("a","href").toString());
home.setImg(selectable.css(".imgBox>img+img","src").toString());
home.setName(selectable.css(".itemTitle","text").toString());
page.addTargetRequest(home.getUrl());
homeList.add(home);
}
//存储
page.putField("home",homeList);
}
//默认操作
@Override
public Site getSite() {
//默认,Site.me()本质上是new Site(),必须返回一个Site
return Site.me();
}
}三、pipeline
项目持久层,可以进行相关的保存操作,提取PageProessz中page.putField("key",value);传输过来的数据进行保存操作(数据库操作,保存到数据库中)
获取数据:
Object jobInfo= resultItems.get("key");
框架提供三个实现类
ConsolePipeline: 向控制台输出。默认使用
FilePipeline: 向磁盘文件中输出
JsonFilePipeline: 保存json格式的文件
例如
.addPipeline(new ConsolePipeline()) //打印控制台的pipeline
.addPipeline(new FilePipeline("D:\\AEK")) //保存的磁盘的pipeline pipeline可以存在多个 都是同时
项目中的实例:
@Component
public class MyPipeline implements Pipeline {
//数据库操作对象
@Autowired
HomerServer homerServer;
//保存数据 打印
@Override
public void process(ResultItems resultItems, Task task) {
//保存主页列表
try {
//获取数据
List<HomeBean> list= resultItems.get("home");
//保存数据
this. homerServer.homInsert(list);
}catch (Exception e){
System.out.println("主页没有数据");
}
//保存阅读图片
try {
Imgs imgs=resultItems.get("imgs");
System.out.println("地址:"+imgs.getUrl()+",图片数目:"+imgs.getImgs().size());
imgs.getImgs().forEach((i)->{
System.out.println(i);
});
System.out.println("成功插入数目"+ homerServer.ImgsInser(imgs)); ;
}catch (Exception e){
System.out.println("阅读页面没有数据");
}
//保存详情信息
Details details=resultItems.get("details");
System.out.println("地址:"+details.getUrl());
System.out.println("名字:"+details.getName());
System.out.println("简介:"+details.getIntro());
System.out.println("集数:"+details.getUrlAll().size());
details.getUrlAll().forEach((i)->{
System.out.println("每集名字:"+i.getName() +",每集地址:"+i.getUrl());
});
System.out.println("插入成功数据:"+homerServer.DetailsInser(details));
}
}四、Scheduler
爬虫的入口程序,把前面配置好的组件添加到爬虫中
访问url队列
默认使用的内存队列
url数据量大时会占用大量的内存
QueueScheduler
文件形式队列
FileCacheQueueScheduler
需要制定保存队列文档路径以及文件名字
使用redis队列
实现分布式爬虫时候。大规模爬虫时候
Spider 工具类,可以初始爬虫 在spider中配置各个组件 启动爬虫
项目实例:
//初始化pac
@Component
public class MySpider {
// private String url;
@Autowired
private Pipeline pipeline; //不能直接创建 应该使用注入
@Autowired
private Downloader downloader;
@Autowired
private PageProcessor processor ;
public void start(String url){
//布隆防止url重复
QueueScheduler scheduler=new QueueScheduler();
scheduler.setDuplicateRemover(new BloomFilterDuplicateRemover(1000000));
Spider.create(processor) //设置processor 组件
.setDownloader(downloader) //设置downloader 组件
.addPipeline(pipeline) //设置pipeline 组件
.setScheduler(scheduler) //设置url过滤
.addUrl(url) //设置起始url
.thread(4) //无头浏览器不支持多线程
.start(); //启动爬虫
}
public static void main(String[] args) {
new MySpider().start("https://www.kuaikanmanhua.com/");
}
}五、程序定时操作
spring 中定时任务 1、@Component类中 2、定义一个方法 3、在方法上使用@Scheduled注解注解,配置定期执行的时间 4、在springboot工程中引导类上添加@EnableScheduling注解(相当于开启定时任务)
定时任务 cron: cron表达式,制定任务在特定时间执行 fixedDelay 上一次任务执行完毕后多久再执行,参数为long 单位ms fixedDelayString 与fixedDelay含义一致,只是参数为String fixedRate 按一定的频率执行任务,参数类型为long,单位ms fixedRateString 与fixedRate的含义一样,只是将参数类型变为String initialDelay:延迟多久再第一次执行任务,参数类型为long 单位ms initialDelayString initialDelay的含义一致,只是参数类型变为string zone:时区,默认与当前时区,一般没有用到
@Scheduled //定时操作
例如:
@Component
public class SchedulerTest {
@Scheduled(cron = "0/1 * * * * ? ") //定时操作cron
public void showTime(){
System.out.println(new Date().toLocaleString());
}
}
六、项目中遇到的问题
1、无头浏览器线程问题:在配置Downloader时候 无头浏览器创建和配置在download方法中即可,不要把驱动创建在外部,不要在构造方法中配置无头浏览器
2、获取的DOM节点不存在而使爬虫停下:使用try环绕即可
3、空指针异常:webmagic所有组件交给springboot管理后,全部组件中的成员变量不要用new创建,而是直接使用@Autowired 注入,不然会在多线程情况下产生问题














 1107
1107











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









