






摘要
虽然推荐系统(RS)通过深度学习取得了显着进步,但当前的RS方法通常在特定任务的数据集上训练和微调模型,限制了它们对新推荐任务的泛化能力以及由于模型规模和数据大小限制而利用外部知识的能力。设计了一个LLMpowered自主推荐代理,RecMind,它能够利用外部知识,利用精心规划的工具提供zero-shot个性化推荐。我们提出了一种自适应规划算法,以提高规划能力。在每一个中间步骤,LLM“自我启发”考虑所有以前探索的状态,以计划下一步。该机制大大提高了模型理解和利用历史信息进行推荐规划的能力。我们评估RecMind在各种推荐场景中的表现。我们的实验表明,RecMind在各种任务中优于现有的基于zero/few-shot 基于LLM的推荐方法,并实现了与经过充分训练的推荐模型P5相当的性能。
特点
planning部分
设计了一种思维方式Self-Inspiring(自我激励),coT,Tot在生成新状态时丢弃先前探索的路径中的状态(思想),SI在生成新状态时保留来自所有历史路径的所有先前状态。本质来说:其实就是加大了数据量呗
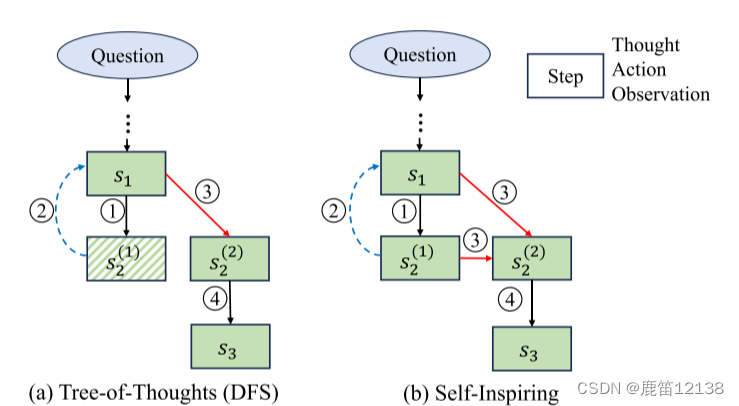
如下图所示,RecMind由关键组件组成:LLM驱动的API(如ChatGPT),用于驱动整体推理,将任务分解为更小的子任务以进行逐步规划的规划,为智能体提供在较长时间内保留和调用信息的能力的内存,以及用于从模型权重中缺失的内存中获取相关额外信息并辅助推理的工具。
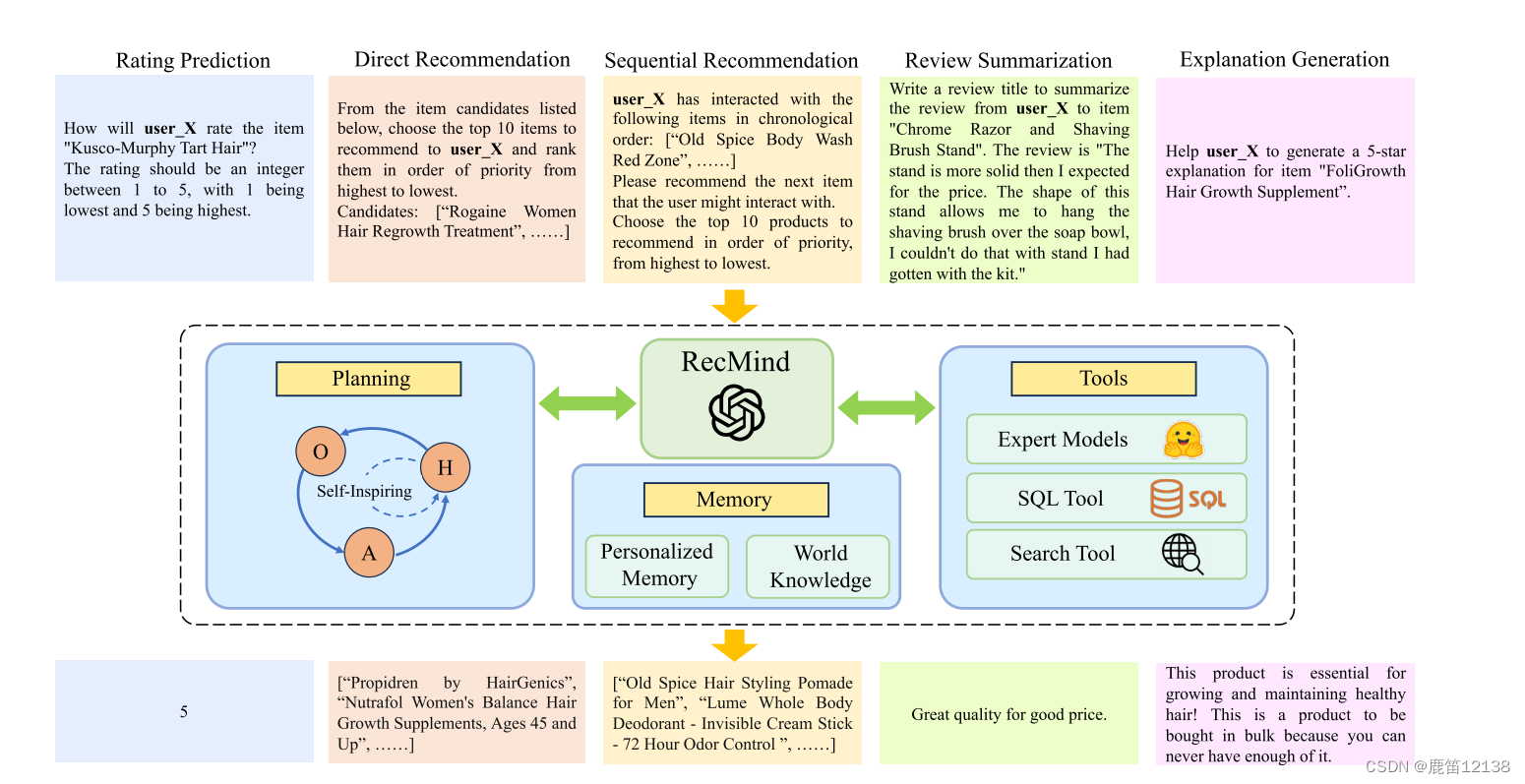
Tools部分:
SQL tool 没啥可说的,就是item相关的信息检索用的
Search tool 仅仅局限于搜索引擎的搜索,明显还可以做更多的拓展
hugging face 中用了一个语言总结分析工具(现成的)
实验部分
总结,比较惨烈
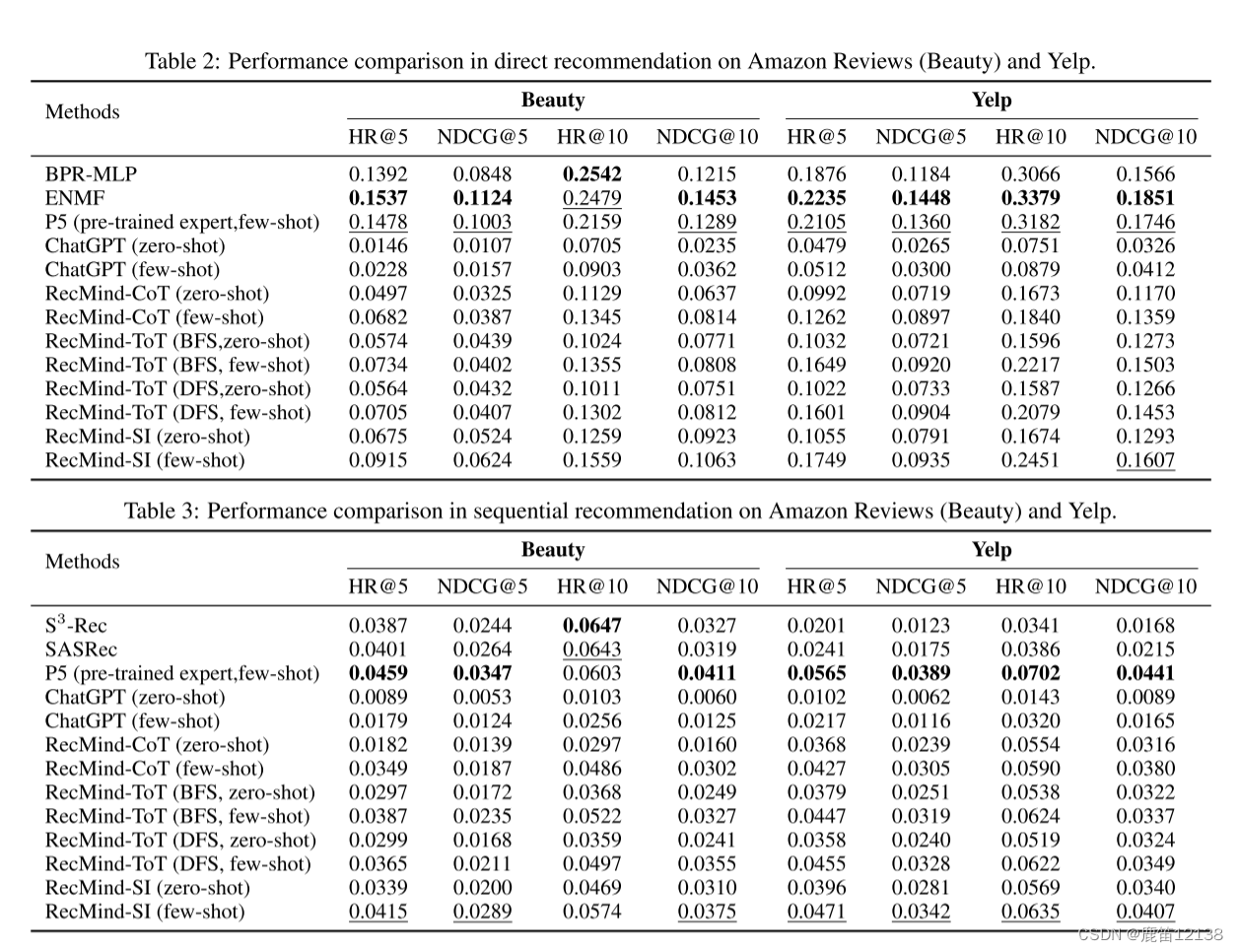
基本上是比不过普通的推荐模型或P5这类新型模型的基线的
结论与反思:
总体来说,文章的亮点有且只有SI,对于Agent的利用和增强的手段与工具都比较有限,同时没有很好的去和传统模型结合,只是单Agent在用工具的情况下就和P5的能力类似,开发潜力还是很大的。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









