






论文核心主旨
大模型好用,在很多任务上表现非常好,但是在推荐上现在表现的比较一般,可能的原因是模型训练的时候不太关注推荐的数据去训练。那我做一个微调框架,让大模型可以更好的学会推荐的能力。
结构总览
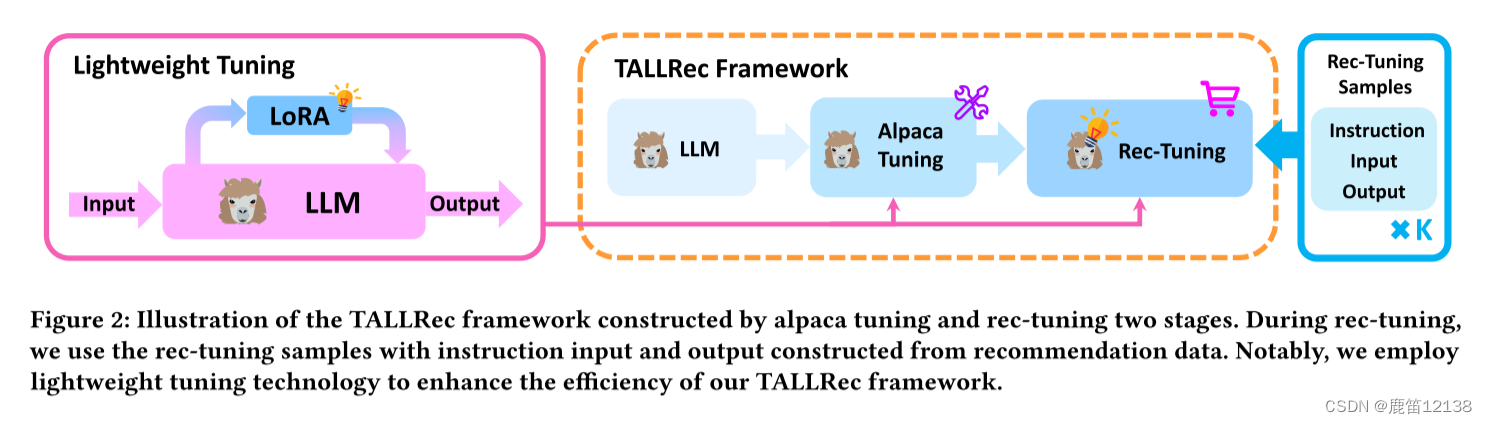
实验方法
1.将数据处理为微调指令
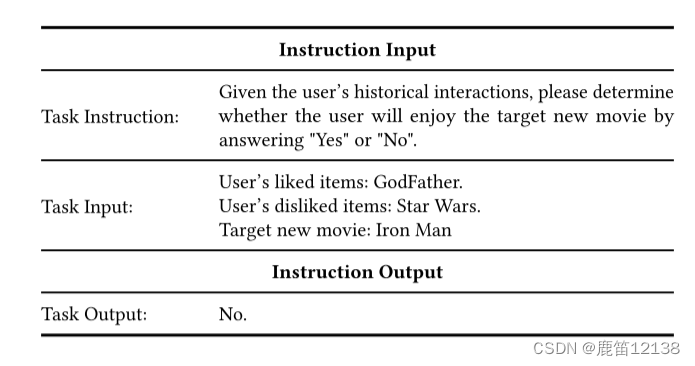
2. Alpaca调优阶段
利用下面链接中提供的自学数据来训练LLM。具体地说,在调优过程中利用条件语言建模目标,如链接中资源库所示。tloen/alpaca-lora: Instruct-tune LLaMA (github.com)
3.rec-tuning调优阶段
对于rec调优,我们可以使用上图中描述的rec调优示例来调优LLM,类似于Alpaca调优。
实验结果
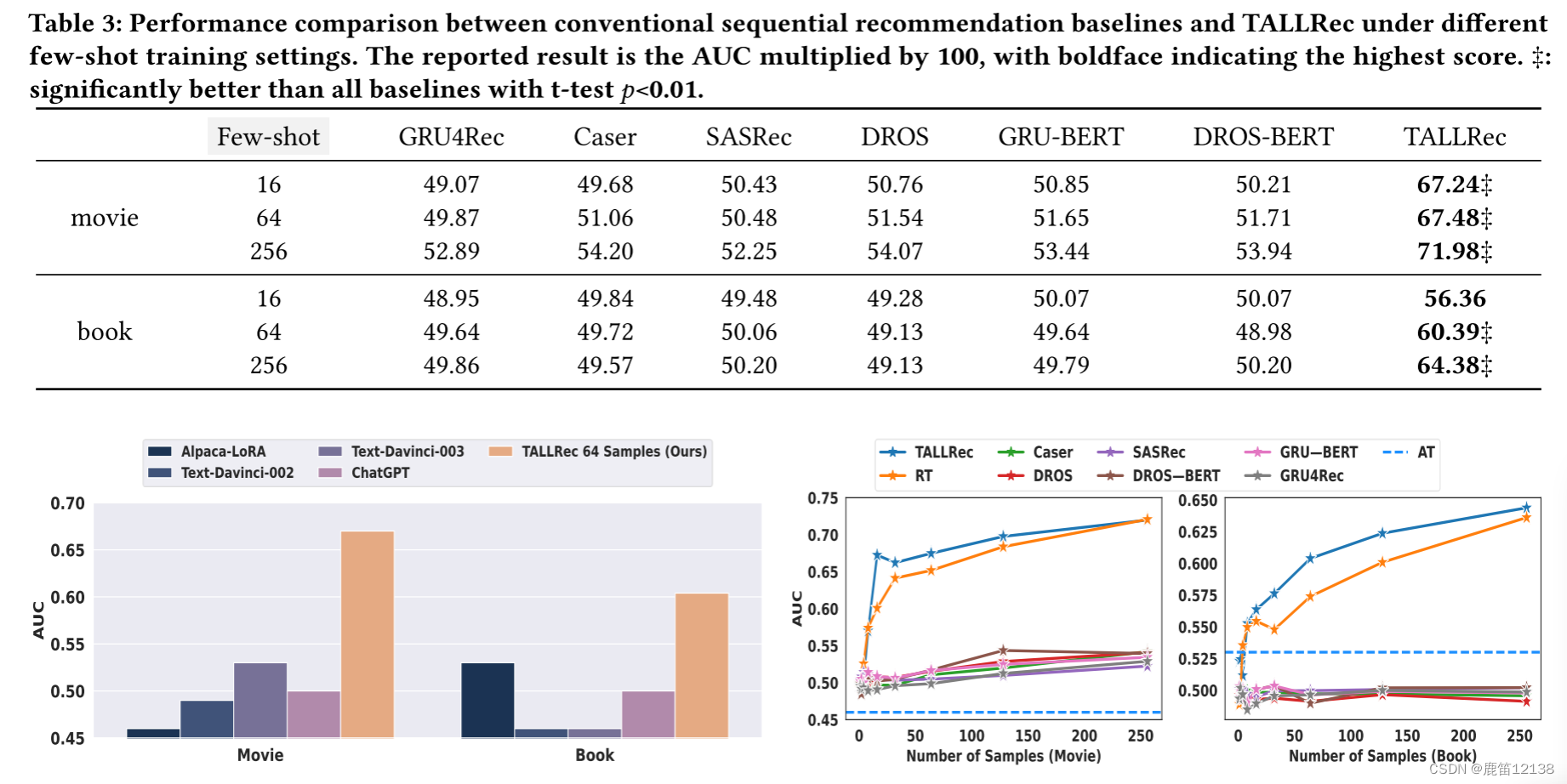
说几个重点:
1.这个表现的好是在few-shot training 下的,
2.另外这个指标用的只有AUC不知道是不是其他指标表现不太好,一般比较少用这种了


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









