







文章目录
知识点
基础程序设计技巧
万能头文件
#include<bits/stdc++.h>
while执行多次输入
while (~scanf("%d", &n)) {}
循环退出
break是指直接跳出本层循环continue是指结束本次循环,但不跳出本层循环,进入下一次循环。
scanf,printf & cin, cout
cin, cout输入数据达到1e6或1e7后会变慢,则
改为scanf,printf
int 初定义
int类型的表示范围(-231~231-1),
有一种比int更大的类型,称为**long long**,它的表示范围是-263~263-1,比-1019~-1019略窄。
n太大(n≤1012),超过了int类型的表示范围,输入输出的时候用 %lld,如:scanf("%lld",&a);printf("%lld",a);
注意:C++中的cout无法输出 __int64类型变量的值。#求c(n,m)=n!/(m!*(n-m)!)
#define int long long
//加上这一行有时候程序过不了,则
#define ll long long
开数组一般大小:
const int N = 1e6 + 10;
int a[N];
布尔型(bool)
布尔型(bool)变量的值只有 真 (true) 和假 (false)。
应用:
①布尔型变量可用于逻辑表达式,也就是“或”“与”“非”之类的逻辑运算和大于小于之类的关系运算,逻辑表达式运算结果为真或为假。
②bool可用于定义函数类型为布尔型,函数里可以有 return TRUE; return FALSE 之类的语句。
③布尔型运算结果常用于条件语句:
if (逻辑表达式){如果是 true 执行这里;}
else{如果是 false 执行这里;}
④bool输出:只有0为假,其他都为真
基本数据类型取值范围
| type | size | 数值范围 |
|---|---|---|
| 无值型void | 0byte | 无值域 |
| 布尔型bool | 1 byte | true false |
| 有符号短整型short[int] / signed short[int] | 2 byte | -32768~32767 |
| 无符号短整型unsigned short[int] | 2byte | 0~65535 |
| 有符号整型int / signed[int] | 4 byte | -2147483648~2147483647 |
| 无符号整型unsigned[int] | 4 byte | 0~4294967295 |
| 有符号长整型long[int] / signed long[int] | 4 byte | -2147483648~2147483647 |
| 无符号长整型unsigned long[int] | 4 byte | 0~4294967295 |
| long long | 8 byte | 0~18446744073709552000 |
| 有符号字符型charlsignedchar | 1 byte | -128~127 |
| 无符号字符型unsigned char | 1 byte | 0~255 |
| 宽字符型wchar_t(unsigned short.) | 2byte | 0~65535 |
| 单精度浮点型float | 4 byte | 3.4e-38 - 3.4e+38 |
| 双精度浮点型double | 8 byte | 1.7e-308~1.7e+308 |
| long double | 8 byte |
文件输入输出操作
使用文件最简单的方法是使用输入输出重定向,只需要在main函数的入口处加入以下两条语句:freopen("input.txt","r",stdin);freopen("output.txt","w",stdout);
它将使得scanf从文件input.txt读入,printf写入文件output.txt.
浮点数陷阱
#include <stdio.h>
int main()
{
double i;
for(i=0;i!=10;i+=0.1)
printf("%.1lf\n",i);
return 0;
}
说明对于i可以达到10.0,但永远不会与10相等,所以for循环是一个死循环。
对于float和dobule类型的数据不能直接用 ==和!=来比较大小,即不要测试精确的浮点型数值,需要用精度比较,来测试一个可接受的数值范围。如:
for(i=0;fabs(10-i)>1e-5;i+=0.1)
C++中的输入输出
1)输入输出流:
头文件:#include <iostream> 头文件iostream包含了对输入输出流的定义#include<cstdio> (c++) == #include<stdio.h> (c)#include<cmath> (c++) == #include<math.h> (c)using namespace std 使用名字空间stdcin是输入流istream类对象,>>是提取运算符,存到a,b中cout是输出流ostream类的对象,<<是插入运算符,按顺序输出,endl为换行
析取器(>>)从流中输入数据
插入器(<<)向流中输出数据
#include <iostream> //头文件iostream包含了对输入输出流的定义
using namespace std; //使用名字空间std
int main(){
int a,b;
while(cin>>a>>b)
//cin是输入流istream类对象,>>是提取运算符,存到a,b中
cout<<a+b<<endl;
//cout是输出流ostream类的对象,<<是插入运算符,按顺序输出,endl为换行
return 0;
}
2)输入输出文件流:#include <fstream>fstream类,它是从iostream类派生的,用来支持对磁盘文件的输入输出。ifstream fin("aplusb.in");输入文件流,从硬盘到内存ofstream fout("aplusb.out");输出文件流,从内存到硬盘
#include <fstream> //fstream类,它是从iostream类派生的,用来支持对磁盘文件的输入输出。
using namespace std;
ifstream fin("aplusb.in"); //输入文件流,从硬盘到内存
ofstream fout("aplusb.out"); //输出文件流,从内存到硬盘
int main(){
int a, b;
while(fin>>a>>b) //析取器(>>)从流中输入数据
fout<<a+b<< "\n"; //插入器(<<)向流中输出数据
return 0;
}
如果想再次使用cin和cout,是否要逐个把程序中的所有fin和fout替换为cin和cout
不用这么麻烦,只需要把fin和fout的声明语句去掉,并加上这样两行即可:#define fin cin#define fout cout
递归
1、递归调用
2、递归出口
案例1:设计一个求阶乘的递归函数
1)形式化,写成一个函数,参数只有一个
令f(n) = n!
2)分解问题,尾递归,把n拿出来,子问题变成(n - 1)!
3)找到相似性,得到递推式
n!= (n - 1)!*n
f(n) = f(n - 1) * n
4)递归出口
n > n - 1 > n - 2 > n - 3 > … > 0
案例2:设计一个求解汉诺塔的递归函数
1)形式化,写成一个函数,参数有4个
//把n给盘子从a柱移到c柱,借助中间柱b
void hanoi(int n, char a, char b, char c);
2)分解问题,尾递归,把最大的盘子n拿出来,分解成n号盘子和上面的n - 1个盘子
3)找到相似性,得到递推式
//1)上面的n-1个盘子从a柱移到中间柱b,借助c
hanoi(n - 1, a, c, b);
//2)最大的盘子n从a柱移动到c柱
printf("move %d# from %c to %c\n", n, a, c);
//3)上面从n-1个盘子从b柱到c柱
hanoi(n - 1, b, a, c);
4)递归出口
n > n - 1 > n - 2 > n - 3 > … > 0
完整代码:
#include<bits/stdc++.h>
using namespace std;
void hanoi(int n, char a, char b, char c);
int main() {
int n;
while (cin >> n) {
hanoi(n, 'A', 'B', 'C');
}
return 0;
}
//把n给盘子从a柱移到c柱,借助中间柱b
void hanoi(int n, char a, char b, char c) {
if (n == 0) return ;
//1)上面的n-1个盘子从a柱移到中间柱b,借助c
hanoi(n - 1, a, c, b);
//2)最大的盘子n从a柱移动到c柱
printf("move %d# from %c to %c\n", n, a, c);
//3)上面从n-1个盘子从b柱到c柱
hanoi(n - 1, b, a, c);
}
案例3:字符串逆序
1)形式化,写成一个函数,参数有1个
//字符串s逆序
void reverse(char *s);
2)分解问题,尾递归,把第一个字符s[0]拿出来,分成2部分首字符s[0]和剩余的字符串(起始地址是s + 1)
3)找到相似性,得到递推式
//1)把第一个字符放到后面
char ts[2] = { s[0] };
strcat(s + 1, ts);
4)递归出口
n > n - 1 > n - 2 > n - 3 > … > 0
案例4:x星球
1)形式化,写成一个函数,参数有1个
//字符串s逆序
void reverse(char* s);
2)分解问题,有两种选择
(1)车队开进检查站,f(a - 1, b + 1)
(2)检查站开出1辆车,f(a, b - 1)
3)找到相似性,得到递推式
f(a, b) = f(a - 1, b + 1) + f(a, b - 1);
4)递归出口
n > n - 1 > n - 2 > n - 3 > … > 0
完整代码
#include<bits/stdc++.h>
using namespace std;
int f(int, int);
int main() {
int n;
while (cin >> n) {
cout << f(n, 0) << endl;
}
return 0;
}
//出站次序,车队有a辆车,检查站有b辆车
int f(int a, int b) {
if (a == 0) {
return 1;
}
if (b == 0) {
return f(a-1,1);
}
return f(a - 1, b + 1) + f(a, b - 1);
}
指针
& :取地址符 & 用于获取变量的内存地址。它可以被用于任何数据类型的变量,包括基本数据类型(如整型、浮点型等)和复合数据类型(如数组、结构体等)。*为解引用符,解引用操作是指通过指针访问存储在其指向地址上的值。
#include<bits/stdc++.h>
using namespace std;
int main() {
int a = 10;
scanf("%d",&a); //& 为取地址符
cout << *(&a) << endl; //* 为解引用符,取出地址中的值
return 0;
}
int main() {
int a = 10;
int* pa = &a;
*pa = 11;
cout << *pa << endl; //11
cout << a << endl; //11
return 0;
}
sort()基本使用方法
sort()的定义
sort()函数可以对给定区间所有元素进行排序。
它有三个参数sort(begin, end, cmp):begin为指向待sort()的数组的第一个元素的指针,end为指向待sort()的数组的最后一个元素的下一个位置的指针,cmp参数为排序准则,cmp参数可以不写,默认从小到大进行排序。
返回值:无
时间复杂度:O(nlogn)
排序范围:[first,last)
int main() {
int a[10] = { 10,9,8,7,6,5,4,3,2,1 };
sort(a + 0, a + 2 + 1,cmp); //排序前三位
for(int i = 0;i < 10;i++)
cout << a[i] << endl;
return 0;
}
bool控制cmp自定义排序:
bool cmp(int e1, int e2) { //int 对应 int a[10]
return e1 > e2; //降序为true不交换,升序为false交换
}
结构体排序
sort()也可以对结构体进行排序,
比如我们定义一个结构体含有学生的姓名和成绩的结构体Student,
然后我们按照每个学生的成绩从高到底进行排序。首先我们将结构体定义为:
struct Student {
string name;
int score;
};
根据排序要求我们可以将排序准则函数写为:
bool cmp_score(Student x, Student y) {
return x.score > y.score;
}
完整代码:
#include<iostream>
#include<string>
#include<algorithm>
using namespace std;
struct Student {
string name;
int score;
Student() {}
Student(string n, int s) :name(n), score(s) {}
};
bool cmp_score(Student x, Student y) {
return x.score > y.score;
}
int main() {
Student stu[3];
string n;
int s;
for (int i = 0; i < 3; i++) {
cin >> n >> s;
stu[i] = Student(n, s);
}
sort(stu, stu + 3, cmp_score);
for (int i = 0; i < 3; i++) {
cout << stu[i].name << " " << stu[i].score << endl;
}
return 0;
}
[#B3827[NICA #2] 高考组题](#B3827[NICA #2] 高考组题)
STL
STL是C语言标准中的重要组成部分
以模板类和函数的形式提供数据结构和算法优化STL大致分为3类,容器,算法,迭代器STL的主要组成部分
容器:用于存储数据集合的通用类模板,包括序列容器(如vector、list、deque)、关联容器(如set、multiset、map、multimap)和容器适配器(如stack、queue、priority_queue)。
算法:用于对容器中的元素进行各种操作的通用函数模板,例如排序、搜索、复制等。
迭代器:实现STL算法与容器交互所需的通用指针
vector动态数组
在 C++ 中,vector 是一个模板类,用于存储一个动态数组, 运行时根据需要改变数组大小
vector <数据类型> 变量名;
e.g. vector a; 默认初始化,a为空
e.g. vector b(a); 用a定义b
e.g. vector a(100); a有100个值为0的元素
开辟空间后可以直接访问a[0]…a[99],没有用()开辟则无法访问,会溢出
多维数组
定义多维数组,例如定义一个二维数组 : vector<int> a[MAXN];
它的第一维大小是固定的MAXN,第二维是动态的。
用这个方式,可以实现图的邻接表存储。
vector语法
| 功能 | 例子 | 说明 |
|---|---|---|
| 赋值 | a.push_back(100); | 在尾部添加元素 |
| 元素个数 | int size = a.size(); | 元素个数 |
| 是否为空 | bool isEmpty = a.empty(); | 是否为空 |
| 打印 | cout << a[0] << endl; | 打印第一个元素 |
| 中间插入 | a.insert(a.begin() + i, k); | 在第i个元素前面插入k |
| 尾部插入 | a.push_back(8); | 尾部插入为8的元素 |
| 尾部插入 | a.insert(a.end(), 10, 5); | 尾部插入10个值为5的元素 |
| 删除尾部 | a.pop_back(); | 删除尾部元素 |
| 删除区间 | a.erase(a.begin() + i, a.begin() + j); | 删除区间[i, j - 1]的元素 |
| 删除元素 | a.erase(a.begin() + 2); | 删除第3个元素 |
| 调整大小 | a.resize(n); | 数组大小变为n |
| 清空 | a.clear(); | |
| 翻转 | reverse(a.begin(), a.end()); | 用函数reverse翻转数组 |
| 排序 | sort(a.begin(), a.end()); | 用函数sort排序,从小到大 |
样例代码
#include<bits/stdc++.h>
using namespace std;
int main() {
vector<int> a;
vector <int> a(100); //a设置100个值为0的元素
//开辟空间后可以直接访问a[0]...a[99],没有用()开辟则无法访问 会溢出
a.push_back(8);
a.push_back(7);
cout << a.size();//元素个数
cout << *a.begin();//a[0],a.begin()迭代器类似于指针,要用解引用符
cout << *(a.end()-1);//a.end()指向最后元素的后一位
return 0;
}
迭代器&&循环遍历
迭代器Iterator是一种设计模式,在编程语言中用于访问容器的元素,而不需要暴露集合的内部表现方式。
迭代器提供了一种统一的方式来遍历不同类型的集合,使得代码更加灵活和可复用。
使用*操作符可以解压或展开迭代器或可迭代对象Iterable,将其内容依次提取出来。
vector<int>::iterator it;
for(it=a.begin(); it != a.end();it++){}
cout << *it; //解引用符解迭代器
for (auto it = a.begin(); it != a.end(); it++){}
cout << *it; //解引用符解迭代器
auto语法
auto的定义
【auto】(自动识别类型)
在C++中,auto关键字是一个类型说明符,用于自动推导变量的类型。
这意味着编译器会根据变量的初始化表达式自动确定变量的类型,从而使得代码更加简洁,
特别是当处理复杂类型时。auto关键字是在C++11标准中引入的,之后被广泛应用于现代C++编程中。
auto的语法
规则1:声明为auto(不是auto&)的变量,忽视掉初始化表达式的顶层const。即对有const的普通类型(int 、double等)忽视const,对常量指针(顶层const)变为普通指针,对指向常量(底层const)的常量指针(顶层cosnt)变为指向常量的指针(底层const)。
规则2:声明为auto& 的变量,保持初始化表达式的顶层const或 volatile 属性。
规则3:若希望 auto推导的是顶层const,加上const,即const auto。
参考资料
- [更喜欢用这个]
auto会拷贝一份容器内的veckor,在修改x时不会改变原容器当中的vector值,只会改变拷贝的vector。x为元素可直接使用
for(auto x : a){}
cout << x;
- 当需要对原数据进行同步修改时,就需要添加
&,即vector的引用,会在改变x的同时修改vector。
for (auto& x : vector){}
- [不常用]
const(常类型),不能作为左值&(引用),不拷贝,不申请新空间,
会对原vector修改当我们不希望拷贝原vector(拷贝需要申请新的空间),同时不愿意随意改变原vector,那么我们可以使用for(constauto & x:vector),这样我们可以很方便的在不拷贝的情况下读取vector,同时不会修改vector。一般用在只读操作。
for (const auto& x : vector)
auto在编程时真正的用途
1、代替冗长复杂的变量声明vector<int>::iterator it = v.begin(); 直接用auto代替 auto it = v.begin();
2、定义模板参数时,用于声明依赖模板参数的变量
template <typename _Tx, typename _Ty>
void Multiply(_Tx x, _Ty y) {
auto v = x + y;
std::cout << v;
}
使用reverse反向排列算法
#include<iostream>
#include<vector>
#include<algorithm>
using namespace std;
int main()
{
vector<int> v(10);
for (int i = 0; i < 10; i++)
{
v[i] = i;
}
reverse(v.begin(), v.end());
vector<int>::iterator it;
for (it = v.begin(); it != v.end(); it++)
{
cout << *it << " ";
}
cout << endl;
return 0;
}
stack栈
栈的定义
栈Stack是一种线性数据结构,其特点是只允许在一端进行插入和删除操作;
这一端被称为栈顶top,相对地,把另一端称为栈底bottom;
这种数据结构遵循后进先出LIFO, Last In First Out的原则。
栈的语法
| 例子 | 说明 |
|---|---|
| stack< Type >s; | 定义栈,Type为数据类型,如int,foatchar等 |
| s.push(item); | 把item放到栈顶 |
| s.top(); | 返回栈顶的元素,但不会删除 |
| s.pop(); | 删除栈顶的元素,但不会返回 |
| s.size(); | 返回栈中元素的个数 |
| s.empty(); | 检查栈是否为空,如果为空返回true.否则返回false |
爆栈问题
栈需要用空间存储,存进栈的数组太大,那么总数会超过系统为栈分配的空间,就会爆栈,即栈溢出。
解决办法有两种 :
(1)在程序中调大系统的栈。依赖于系统和编译器。
(2)手工写栈。
P1427 小鱼的数字游戏
题目描述
小鱼最近被要求参加一个数字游戏,要求它把看到的一串数字
a
i
a_i
ai(长度不一定,以
0
0
0 结束),记住了然后反着念出来(表示结束的数字
0
0
0 就不要念出来了)。这对小鱼的那点记忆力来说实在是太难了,你也不想想小鱼的整个脑袋才多大,其中一部分还是好吃的肉!所以请你帮小鱼编程解决这个问题。
输入格式
一行内输入一串整数,以
0
0
0 结束,以空格间隔。
输出格式
一行内倒着输出这一串整数,以空格间隔。
样例 #1
样例输入 #1
3 65 23 5 34 1 30 0
样例输出 #1
30 1 34 5 23 65 3
提示
数据规模与约定
对于
100
100\ %
100 的数据,保证
0
≤
a
i
≤
2
31
−
1
0 \leq a_i \leq 2 ^ {31} - 1
0≤ai≤231−1,数字个数不超过
100
100
100。
#include<bits/stdc++.h>
using namespace std;
int main() {
stack<int> s;
int x;
while (cin >> x&&x!=0) {
s.push(x);
}
while (!s.empty())
{
cout << s.top() << " ";
s.pop();
}
return 0;
}
解题集
闰年判断
if ((m%4==0&&m%100!=0)||m%400==0)
找完全平方数
int main() {
for (int a 1; a <= 9; a++) {
for (int b = 0; b <= 9; b++) {
int n = a * 1100 + b * 11;
double x = sqrt(n);
if (fabs(x - (int)x) < 1e-6) { //完全平方数 用0.000001判断
printf("%d %.0f\n", n, x);}}}}
可以用 对比0.000001 来判断是否为 整数!!!
阶乘之和(末6位)
输入n,计算S=1!+2!+3!+…+n!的末6位(不含前导0)。n≤106。这里,n!表示前n个正整数之积。
样例输入
10
样例输出
37913
完整代码
#include<bits/stdc++.h> //万能头文件
const int M = 1e6;
int main() {
int n;
while (~scanf("%d", &n)) { //可执行多次输入
long long s = 0, f = 1;
for (int i = 1; i <= n; i++) {
f = f * i % M; //i!
s = (s + f) % M; //阶乘和
}
printf("%lld %lld\n", n, s);
}
}
若逐个计算,则会发生乘法溢出,所以:
要计算只包含加法、减法和乘法的整数表达式除以正整数n的余数,可以在每步计算之后对n 取余,结果不变。
求c(n,m)=n!/(m!*(n-m)!)
#include<bits/stdc++.h>
typedef unsigned long long ull; //ll 2^63-1>>unsigned 2^64-1 变大一倍
//求阶乘
ull f(int);
int main() {
int n, m;
while (~scanf("%d %d", &n,&m)) {
int x = f(n) / (f(m) * f(n - m));
printf("c(%d,%d) = %d\n", x);
}
return 0;
}
ull f(int n) {
int x = 1;
for (int i = 1; i <= n; i++){
x *= i;
}
return x;
}
孪生素数
#include<cstdio>
#include<iostream> //输入输出流
using namespace std; //使用名字空间std
//判断x是否素数
bool isPrime(int x);
int main() {
int m;
while (cin >> m) //cin是输入流istream类对象,>>是提取运算符,存到m中
{
//从大到小枚举
for (int i = m; i >= 5; i--)
{
if (isPrime(i) && isPrime(i - 2)) {
//cout是输出流ostream类的对象,<<是插入运算符,按顺序输出小的、空格、大的、换行,endl是换行
cout << i - 2 << " " << i << endl; break;
}
}
}
return 0;
}
素数判断可以使用“试除法”:
//函数定义,素数判断
bool isPrime(int x) {
if (x < 2)
{
return false;
}
//试除法
for (int i = 2; i <= x/i; i++)
{
if (x % i == 0) {
return false;
}
}
return true;
}
苹果和虫子
Description
小 B 喜欢吃苹果。她现在有 𝑚m(1≤𝑚≤1001≤m≤100)个苹果,吃完一个苹果需要花费 𝑡t(0≤𝑡≤1000≤t≤100)分钟,吃完一个后立刻开始吃下一个。现在时间过去了 𝑠s(1≤𝑠≤100001≤s≤10000)分钟,请问她还有几个完整的苹果?
Input
输入三个非负整数表示 𝑚,𝑡,𝑠m,t,s。
Output
输出一个整数表示答案。
Sample 1
Input
50 10 200
Output
30
Hint
如果你出现了 RE,不如检查一下被零除?
注意
用flag = k - (int)k;来判断是否为整数,因为求的是剩余完整的苹果数
解题代码
#include<stdio.h>
int main() {
int m, t, s;
while (~scanf("%d %d %d", &m, &t, &s)&& 1<=m&&m<=100&& 0<=t&&t<=100&& 1<=s&&s<=10000) {
if (t == 0) {
printf("%d", 0); return 0;
}
double k = (double)s / t;
double flag = k - (int)k;
if ((int)k>m)
{
printf("%d", 0);
}
else
{
if (flag) {
printf("%d", m - (int)k - 1);
}
else {
printf("%d", m - (int)k);
}
}
}
return 0;
}
Download Manager下载文件
Download Manager
佳佳下载了很多很多文件,比你想象的还要多。有人说他一次可以下载多达20000个文件。如果20000个文件同时共享有限的带宽,那么就会出现大问题,没有任何文件能够正常下载。因此,他使用了一个下载管理器。
如果有T个文件需要下载,下载管理器在下载文件时会采用以下策略:1. 下载管理器会给较小的文件更高的优先级,因此它会在启动时下载最小的n个文件。如果出现平分的情况,下载管理器会选择剩余字节较少的那个文件(用于下载)。我们假设至少有500兆比特/秒的带宽,这样n个文件就可以同时下载,而没有任何问题。2. 可用带宽由正在下载的所有文件平等共享。当一个文件完全下载后,其带宽立即分配给下一个文件。如果没有其他文件可供下载,则剩余的带宽将立即平等地分配给正在下载的所有其他文件。
根据每个文件的大小和完成百分比,您的任务是智能模拟下载管理器的行为,以找出下载所有文件所需的总时间。
输入
最多有10个测试用例。每个案例都以三个整数T(1 <= T <= 20000)、n(1 <= n <= 2000且1 <= n <= T)和B(50 <= B <= 1000)开始。其中B表示Jiajia可用的总带宽(以兆字节/秒为单位)。请注意,下载管理器总是并行下载n个文件,除非可用的可下载文件少于n个。接下来的T行中,每行包含一个非负浮点数S(小于20000,小数点后最多两位)和一个整数P(0 <= P <= 100)。这两个数字表示一个文件的大小为S兆字节,并且已经下载了P%。还需要注意的是,虽然理论上,文件的大小或剩余部分的大小以字节为单位时不可能是小数,但为了简化问题,请假设这种情况在本问题中是可能的。最后一个测试案例是T=n=B=0,不应进行处理。
输出
对于每个案例,打印出案例编号和下载所有文件所需的总时间,以小时为单位并保留两位小数。在每个测试案例的输出后打印一个空行。
Sample
Input
6 3 90
100.00 90
40.40 70
60.30 70
40.40 80
40.40 85
40.40 88
1 1 56
12.34 100
0 0 0
Output
Case 1: 0.66
Case 2: 0.00
提示
第一个示例中有6个文件,下载管理器可以同时下载3个文件。最小文件的大小为40.40兆字节,但有4个这样的文件(第2、4、5和6个文件)。因此,下载管理器选择第6、5和4个文件进行下载,因为它们剩余的字节数较少。所有这些文件都享有相等的带宽(30.00兆字节/秒)。在这三个文件中,第8个文件首先完成。因此,第2个文件立即开始下载。然后,第5个文件完成。因此,下一个较大的文件(第3个文件)开始下载。这个过程会一直持续到所有文件都下载完成。
参考代码
#include<stdio.h>
int main()
{
int t,n,b,i=1;
while(~scanf("%d%d%d",&t,&n,&b)&&(t||n||b)){
double s,sum=0;
int p;
while(t--){
scanf("%lf %d",&s,&p);
sum+=s*(1-p/100.0);
}
printf("Case %d: %.2f\n\n",i++,sum/b);
}
return 0;
}
sort排序输出&数字填补
sort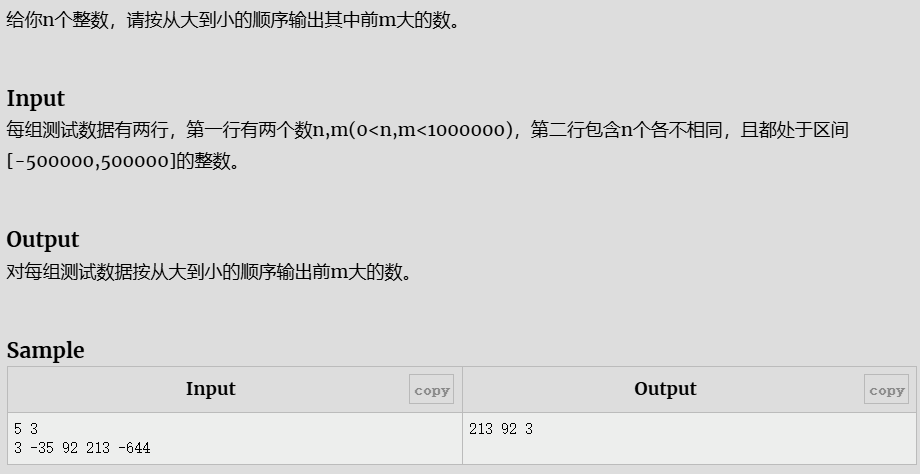
参考代码
#include<stdio.h>
int main()
{
int n,m,t;
while(~scanf("%d%d",&n,&m)){
int a[1000001]={0};
while(n--){
scanf("%d",&t);
a[t+500000]++;
}
for(int i=1000000;m;i--){
if(a[i]){
printf("%d",i-500000);
m--;
if(m)
printf(" ");
}
}
printf("\n");
}
return 0;
}
函数题
任一大于 2 的偶数=两个质数之和
哥德巴赫猜想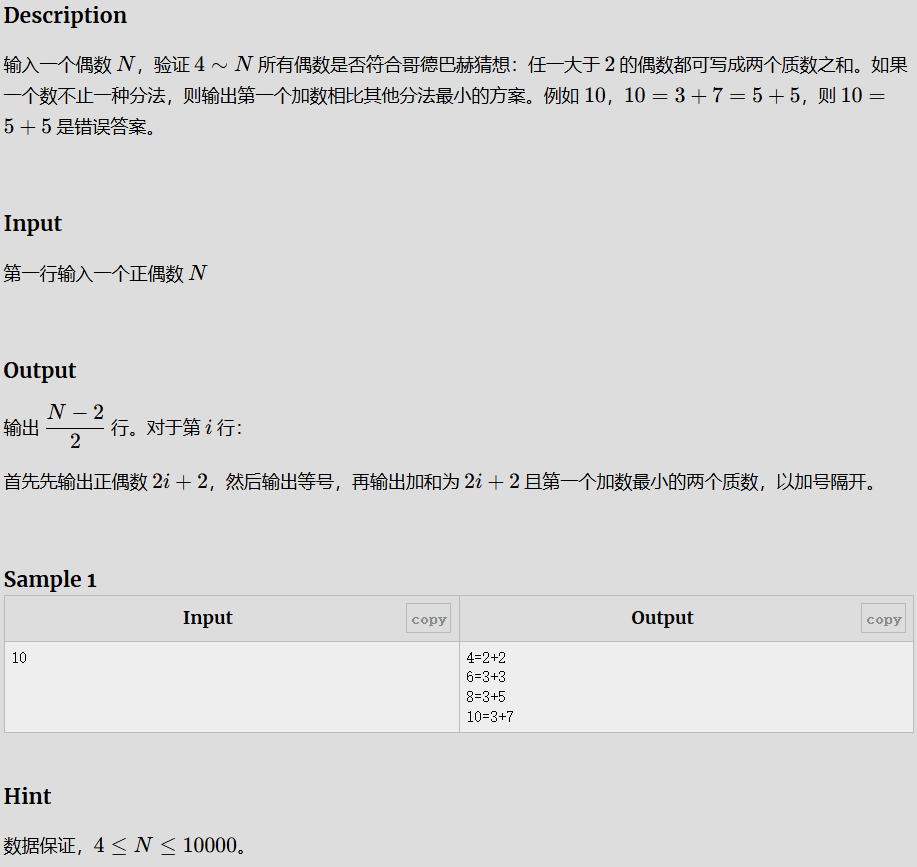
思路
遍历所有的偶数,每个数再去从小到大去找两个质数之和,这里如果把判断质数也放到循环内的话,时间复杂度为n^3, 所以可以先预处理出n以内的数是否为质数,可将复杂度降低为 n^2;
参考代码
#include<bits/stdc++.h>
using namespace std;
const int N=10005;
int is_prime[N];
int isprime(int x){
for(int i=2;i<x;i++){
if(x%i==0) return 0;
}
return 1;
}
int main()
{
int n;
cin>>n;
for(int i=1;i<=n;i++) is_prime[i]=isprime(i);
for(int i=4;i<=n;i+=2){
for(int j=2;j<=i;j++){
if(is_prime[j]&&is_prime[i-j]){
cout<<i<<'='<<j<<'+'<<i-j<<'\n';
break;
}
}
}
return 0;
}
解题代码
#include<bits/stdc++.h>
bool isPrime(int x);
int main() {
int n;
while (~scanf("%d",&n))
{
for (int i = 4; i <= n; i=i+2)//waicen
{
int flag = 1;
for (int j = 2; j < i; j++) {//neicen
if (isPrime(j)) {
if (isPrime(i - j)){
if (flag){
printf("%d=%d+%d\n", i, j, i - j);
flag = 0;
}
}
}
}
}
}
return 0;
}
bool isPrime(int x) {
if (x < 2)
{
return false;
}
//试除法
for (int i = 2; i <= x / i; i++)
{
if (x % i == 0) {
return false;
}
}
return true;
}
最大质因子序列
最大质因子序列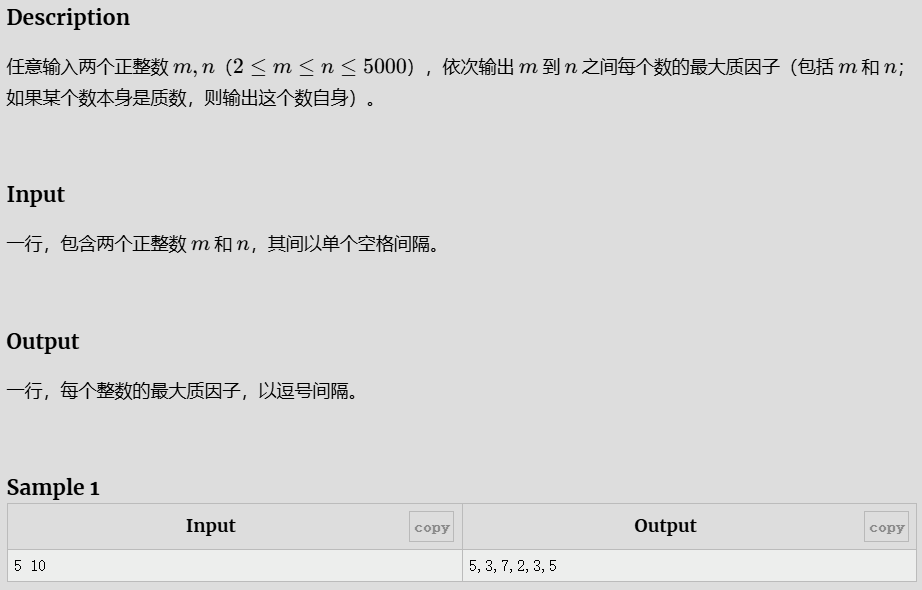
思路
先预处理出
参考代码
#include<bits/stdc++.h>
using namespace std;
const int N=10005;
int is_prime[N];
int isprime(int x){
for(int i=2;i<x;i++){
if(x%i==0) return 0;
}
return 1;
}
int main()
{
int m,n;
cin>>m>>n;
for(int i=1;i<=n;i++) is_prime[i]=isprime(i);
for(int i=m;i<=n;i++){
for(int j=i;j>=1;j--){
if(i%j==0&&is_prime[j]){
cout<<j;
break;
}
}
if(i!=n) cout<<',';
}
return 0;
}
解题代码
#include<cstdio>
#include<math.h>
bool isPrime(int);
int panduan(int);
int main(){
int a, b;
while (~scanf("%d %d",&a,&b))
{
for (int i = a; i <= b; i++) {
printf("%d", panduan(i));
if (i!=b)
{
printf(",");
}
}
}
return 0;
}
bool isPrime(int x) {
if (x < 2)
{
return false;
}
//试除法
for (int i = 2; i <= x / i; i++)
{
if (x % i == 0) {
return false;
}
}
return true;
}
int panduan(int i) {
if (isPrime(i)) {
return i;
}
else {
int max=2;
for (int j = 2; j < i; j++) {
if (i % j == 0 && isPrime(j)) {
if (j > max)max = j;
}
}
return max;
}
}
回文质数
回文质数 Prime Palindromes
思路
先枚举区间内所有奇数,再将回文数用v数组存起来,然后遍历v数组,判断是否是质数。
参考代码
#include<bits/stdc++.h>
using namespace std;
const int N=100005;
int v[N];
int isprime(int n){
for(int i=2;i<=sqrt(n);i++){
if(n%i==0) return 0;
}
return 1;
}
int is_huiwen(int n){
int sum=0,n1=n;
while(n1){
sum=sum*10+n1%10;
n1/=10;
}
return sum==n;
}
int main()
{
int a,b;
cin>>a>>b;
int idx=1;
if(a%2==0) a++;
for(int i=a;i<=b;i+=2){
if(is_huiwen(i)) v[idx++]=i;
}
for(int i=1;i<idx;i++){
if(isprime(v[i])) cout<<v[i]<<'\n';
}
return 0;
}
解题代码
#include<stdio.h>
bool huiwen(int);
bool isPrime(int);
int main() {
int a, b;
while (~scanf("%d %d", &a, &b)&&a>=5&&b<=1e8) {
for (int i = a; i <= b; i++) {
if (i == 9989900) break;
if(huiwen(i)&&(isPrime(i))){
printf("%d\n", i);
}
}
}
return 0;
}
bool isPrime(int x) {
if (x < 2)return false;
if (x == 2 || x == 3) return true; // 2 和 3 是质数
if (x % 2 == 0) return false; // 排除偶数
for (int i = 3; i*i <= x ; i+=2){ //试除法
if (x % i == 0) return false;
}
return true;
}
bool huiwen(int x) {
int b = x;
int c, s = 0;
while (b) {
c = b % 10;
b /= 10;
s = s * 10 + c;
}
return s == x;
}
古老的密码
古老的密码
古罗马帝国拥有强大的政府体系,设有多个部门,包括特勤局部门。重要文件以加密形式在各省和首都之间发送,以防止窃听。当时最流行的密码是所谓的替换密码和置换密码。替换密码将每个字母的所有出现更改为其他字母。所有字母的替代物必须不同。对于某些字母,替换字母可能与原始字母重合。例如,应用替换密码,将所有字母从“A”更改为“Y”,将字母表中的下一个字母更改为“A”,并将“Z”更改为消息“VICTORIOUS”,则得到消息“WJDUPSJPVT”。排列密码对消息的字母应用一些排列。例如,将排列 ⟨2、1、5、4、3、7、6、10、9、8⟩ 应用于消息“VICTORIOUS”,则得到消息“IVOTCIRSUO”。人们很快注意到,如果单独应用,替换密码和置换密码都相当弱。但是当它们结合在一起时,它们在那个时代足够强大。因此,最重要的消息首先使用替换密码进行加密,然后使用排列密码对结果进行加密。使用上述密码的组合对消息“VICTORIOUS”进行加密,可以得到消息“JWPUDJSTVP”。考古学家最近发现了刻在一块石板上的信息。乍一看,这似乎完全没有意义,因此建议使用一些替换和排列密码对消息进行加密。他们已经推测出加密的原始消息的可能文本,现在他们想检查他们的猜想。他们需要一个计算机程序来做到这一点,所以你必须编写一个。
Input
输入文件包含多个测试用例。它们中的每一个都由两行组成。第一行包含刻在板上的信息。在加密之前,所有空格和标点符号都被删除了,因此加密的消息只包含英文字母的大写字母。第二行包含原始消息,推测该消息在第一行的消息中被加密。它还仅包含英文字母的大写字母。输入文件的两行长度相等,不超过 100。
Output
对于每个测试用例,打印一行输出。如果输入文件第一行的消息可能是加密第二行消息的结果,则输出“YES”,或者在另一种情况下输出“NO”。
Sample Input
JWPUDJSTVP
VICTORIOUS
MAMA
ROME
HAHA
HEHE
AAA
AAA
NEERCISTHEBEST
SECRETMESSAGES
Sample Output
YES
NO
YES
YES
NO
题意
有两种加密方式,一种是将字符串中所有为c的字符变成字符b,(c和b可能相等),另外一种是将字符串打乱
顺序,问能否使用者两种加密方式使第二种字符串变成第一种。
思路
分别记录每个字符串的字符数量,然后依次判断字符数量是否能够匹配。
参考代码
#include<bits/stdc++.h>
using namespace std;
int cnt1[30],cnt2[30];
signed main()
{
string s1,s2;
while(cin>>s1>>s2){
for(int i=0;i<=26;i++) cnt1[i]=cnt2[i]=0;
for(char c:s1) cnt1[c-'A']++;
for(char c:s2) cnt2[c-'A']++;
sort(cnt1,cnt1+26);
sort(cnt2,cnt2+26);
int flag=1;
for(int i=0;i<26;i++){
if(cnt1[i]!=cnt2[i]) flag=0;
}
if(flag) cout<<"YES\n";
else cout<<"NO\n";
}
return 0;
}
解题代码
#include<bits/stdc++.h>
using namespace std;
int main() {
string x, y;
while (cin >> x >> y) { //输入流
int length = y.length();
int i = 0, flag=1;
int a[26] = { 0 }, b[26] = { 0 };
//不知道替换字符,则将字符转化为数字存储到数组中,只要比较数组即可
for (int i = 0; i < length; i++) {
a[int(x[i] - 'A')]++; //字符串为特殊数组,可直接[]取用
b[int(y[i] - 'A')]++;
}
for (int i = 0; i < 26; i++) {
for (int j = i; j < 26; j++) {
if (a[i] < a[j]) {
int tmp = a[i];
a[i] = a[j];
a[j] = tmp;
}
if (b[i] < b[j]) {
int tmp = b[i];
b[i] = b[j];
b[j] = tmp;
}
}
}
for (int i = 0; i < 26; i++)
{
if (a[i] != b[i]) { flag = 0; break; }
}
if (flag==1) {
cout << "YES" << endl;//输出流
}
else cout << "NO" << endl;
}
return 0;
}
刽子手游戏
刽子手游戏
在“刽子手法官”中,你要编写一个程序来评判一系列的刽子手游戏。对于每个游戏,都给出了谜题的答案以及猜测。规则与经典的刽子手游戏相同,给出如下:
1.参赛者试图通过一次猜一个字母来解决难题。
2.每次猜对时,单词中所有与猜想相符的字符都会被“翻转”。例如,如果你的猜测是“o”,而单词是“book”,那么解决方案中的两个“o”都将被计为“solved”。
3.每猜错一次,刽子手的图画就会加一笔,需要7笔才能完成。每个独特的错误猜测只对参赛者计一次。
4. 如果刽子手的抽奖在参赛者成功猜出单词的所有字符之前就完成了,则参赛者输了。
5. 如果参赛者在抽签完成之前已经猜出了单词的所有字符,则参赛者赢得比赛。
6. 如果参赛者没有猜出足够的字母来决定输赢,则参赛者将退出。
作为“刽子手裁判”,你的任务是确定每场比赛的参赛者是赢、输还是没完成一场比赛。
Input
您的程序将获得一系列有关游戏状态的输入。所有输入都将为小写。每个部分的第一行将包含一个数字,以指示正在进行哪一轮游戏;下一行将是谜题的答案;最后一行是参赛者做出的一系列猜测。整数“-1”表示所有游戏(和输入)的结束。
Output
程序的输出是指示参赛者当前正在玩的游戏回合以及游戏的结果。有三种可能的结果:
You win.
You lose.
You chickened out.
Sample Input
1
cheese
chese
2
cheese
abcdefg
3
cheese
abcdefgij
-1
Sample Output
Round 1
You win.
Round 2
You chickened out.
Round 3
You lose.
题意
给一个字符串s1,问能否在7次内全部猜中其中的字母。
思路
遍历猜测的字符,记录猜错的次数和剩余没猜到的字母数,最后判断即可。
参考代码
#include<bits/stdc++.h>
using namespace std;
int cnt1[30],cnt2[30];
signed main()
{
int n;
while(cin>>n){
if(n==-1) break;
for(int i=0;i<=26;i++) cnt1[i]=cnt2[i]=0;
string s1,s2;
cin>>s1>>s2;
int cnt=s1.size(),sum=0;
for(char c:s1) cnt1[c-'a']++;
for(char c:s2) cnt2[c-'a']++;
int flag=0;
for(char c:s2){
if(cnt2[c-'a']==0) continue;
cnt2[c-'a']=0;
if(cnt1[c-'a']){
cnt-=cnt1[c-'a'];
}
else sum++;
if(cnt==0) break;
}
if(sum>=7){
printf("Round %d\nYou lose.\n",n);
}
else if(cnt==0){
printf("Round %d\nYou win.\n",n);
}
else{
printf("Round %d\nYou chickened out.\n",n);
}
}
return 0;
}
救济金发放
救济金发放
为了缩小(减少)救济金队列的认真尝试,新国家绿色工党犀牛党决定采取以下策略。每天,所有救济金申请者将被安排在一个大圆圈中,面朝内。某人被任意选为数字 1,其余的人逆时针编号到 N(谁将站在 1 的左边)。从 1 开始,逆时针移动,一名劳工官员计算 k 名申请人,而另一名官员从 N 开始,顺时针移动,计算 m 名申请人。被选中的两人然后被送去接受再培训;如果两个官员都选择了同一个人,她(他)就会被派去当政治家。然后,每个官员都开始在下一个可用的人处再次计数,该过程继续进行,直到没有人离开。请注意,两名受害者(对不起,练习生)同时离开擂台,因此一名官员可以计算另一名官员已经选定的人。
Input
编写一个程序,该程序将依次(按此顺序)读取三个数字(N、k 和 m;k、m > 0、0 < N < 20),并确定申请人被送去接受再培训的顺序。每组三个数字将位于一条单独的线上,数据的结束将由三个零 (0 0 0) 表示。
Output
对于每个三元组,输出一行数字,指定选择人员的顺序。每个数字都应位于 3 个字符的字段中。对于成对的数字,首先列出逆时针官员选择的人。用逗号分隔连续的对(或单例)(但不应有尾随逗号)。注意:下面样本输出中的符号 ⊔ 代表一个空格。
Sample Input
10 4 3
0 0 0
Sample Output
␣␣4␣␣8,␣␣9␣␣5,␣␣3␣␣1,␣␣2␣␣6,␣10,␣␣7
题意
一个由从1到n这些数字按逆时针顺序围成的环,一个人从1开始点,每次逆时针数到第k个,然后将第k个数除去;另一个人从n开始,每次顺时针数到第m个,然后将第m个数除去;循环往复,每次依次输出除去的两个
数。
思路
每次模拟找出要删掉的位置,直到完全删完。
参考代码
#include<stdio.h>
int n,k,m,a[25];
int go(int p,int d,int t){
while(t--){
do{
p=(p+d+n-1)%n+1;
}while(!a[p]);
}
return p;
}
int main()
{
while(~scanf("%d%d%d",&n,&k,&m)&&(n||k||m)){
int num=n,p1=n,p2=1;
for(int i=1;i<=n;i++)
a[i]=i;
while(num){
p1=go(p1,1,k);
p2=go(p2,-1,m);
printf("%3d",p1);
num--;
if(p2!=p1){
printf("%3d",p2);
num--;
}
a[p1]=0;a[p2]=0;
if(num)
printf(",");
}
printf("\n");
}
return 0;
}
歌唱比赛
歌唱比赛
思路
模拟即可
参考代码
#include<bits/stdc++.h>
using namespace std;
const int N=10005;
int a[N];
int main()
{
int n,m;
cin>>n>>m;
double mx=0;
for(int i=1;i<=n;i++){
double ans=0;
for(int j=1;j<=m;j++) cin>>a[j],ans+=a[j];
sort(a+1,a+1+m);
ans-=a[1]+a[m];
ans/=1.0*(m-2);
mx=max(mx,ans);
}
cout<<fixed<<setprecision(2)<<mx;
return 0;
}
解题代码
#include<stdio.h>
int main() {
int n, m; double a[100] = { 0.00 };
int x=0, sum=0;
double f=0.00;
scanf("%d %d", &n, &m);
for(int i=0;i<n;i++){
int max = 0, min = 10;
for (int j = 0; j < m; j++) {
scanf("%d", &x);
if (x >= max) {
max = x;
}
if (x <= min) {
min = x;
}
sum += x;
}
double f = (sum-max-min)*1.00 / (m - 2);
a[i] = f;
sum = 0;
}
for (int i = 0; i < n; i++) {
for (int j = i; j < n; j++) {
if (a[i] < a[j]) {
double tmp = a[i];
a[i] = a[j];
a[j] = tmp;
}
}
}
printf("%.2lf", a[0]);
return 0;
}
最厉害的学生
最厉害的学生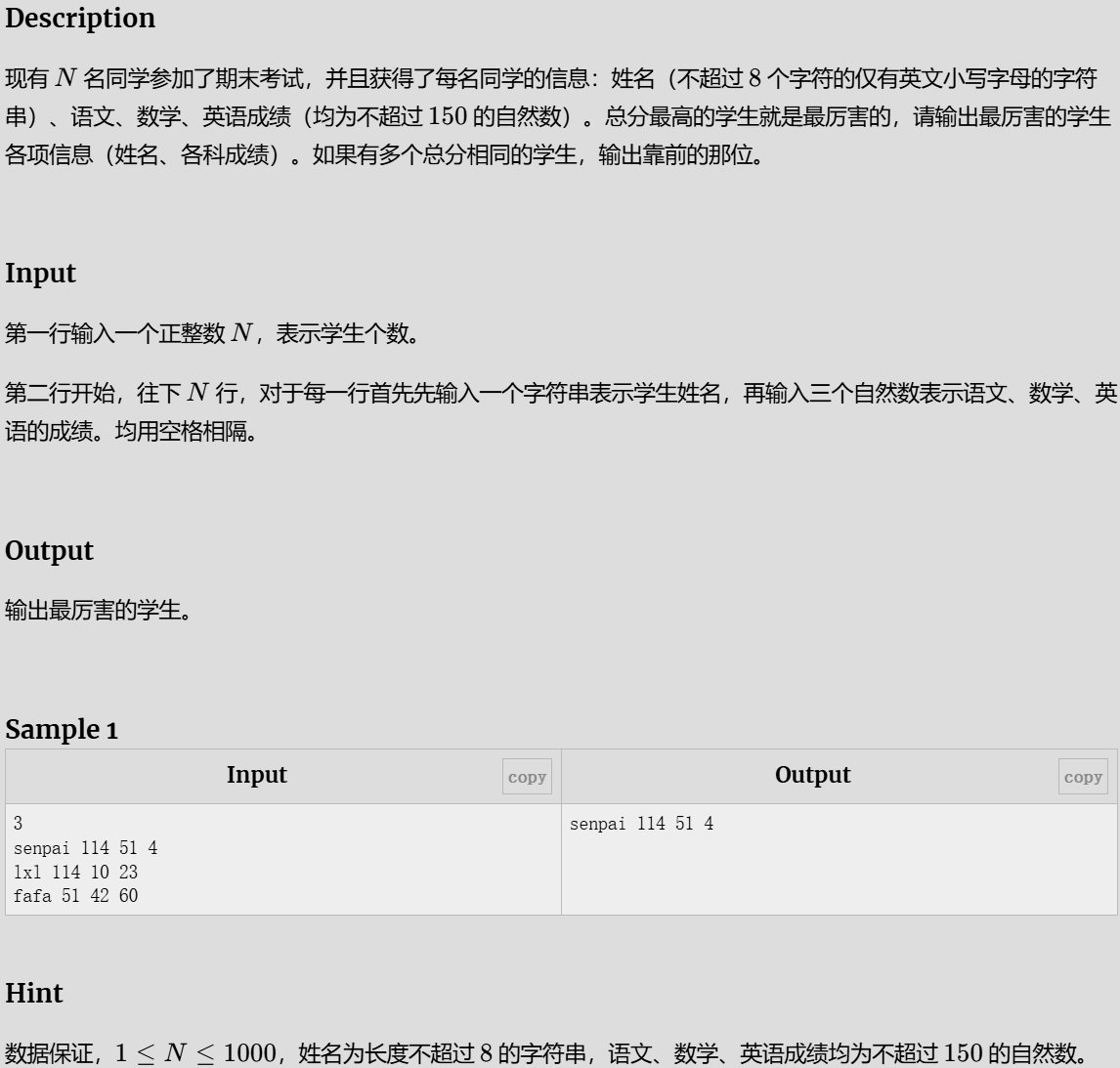
思路
模拟即可
参考代码
#include<stdio.h>
struct node{
char a[10];
int x,y,z;
}f[1000];
int main()
{
int n;
scanf("%d",&n);
for(int i=0;i<n;i++){
scanf("%s %d %d %d",f[i].a ,&f[i].x ,&f[i].y ,&f[i].z );
}
int max=0;
for(int i=0;i<n;i++){
if(f[i].x +f[i].y +f[i].z >max)
max=f[i].x +f[i].y +f[i].z ;
}
for(int i=0;i<n;i++){
if(f[i].x +f[i].y +f[i].z ==max){
printf("%s %d %d %d",f[i].a ,f[i].x ,f[i].y ,f[i].z);
break;
}
}
return 0;
}
解题代码
#include<stdio.h>
struct Student
{
char name[10];
int yuwen;
int shuxue;
int yinyu;
}a[1000];
int main() {
int n, m = 0, max = 0;
scanf("%d", &n);
for (int i = 0; i < n; i++) {
scanf("%s %d %d %d", &a[i].name, &a[i].yuwen, &a[i].shuxue, &a[i].yinyu);
int sum = a[i].yuwen + a[i].shuxue + a[i].yinyu;
if (sum>m)
{
m = sum;
max = i;
}
}
printf("%s %d %d %d", a[max].name, a[max].yuwen, a[max].shuxue, a[max].yinyu);
return 0;
}
递归题
汉诺塔问题
汉诺塔问题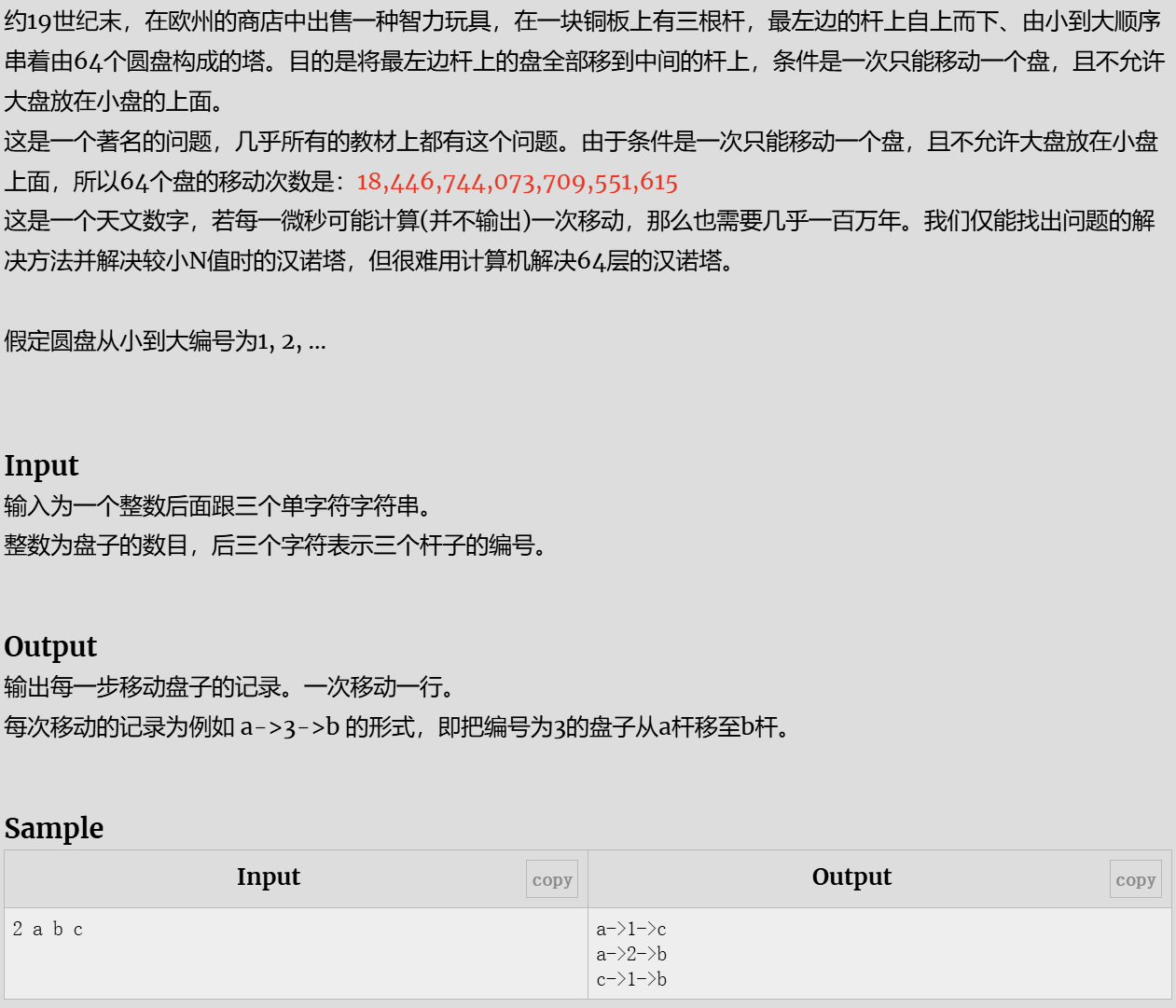
思路
当n为1时,直接将该盘移到目标柱,当n大于1时,将上面的n-1个借助目标柱移到辅助柱,将最后一个移到 目标柱后再将n-1个柱移动到目标柱。
参考代码
#include<bits/stdc++.h>
using namespace std;
void Hanoi(int n,char A,char B,char C)
{
if(n==1)
{
cout<<A<<"->"<<n<<"->"<<C<<endl;
}
else
{
Hanoi(n-1,A,C,B);
cout<<A<<"->"<<n<<"->"<<C<<endl;
Hanoi(n-1,B,A,C);
}
}
int main()
{
int n;
cin >> n;
char A,B,C;
cin>>A>>B>>C;
Hanoi(n,A,C,B);
return 0;
}
新汉诺塔
新汉诺塔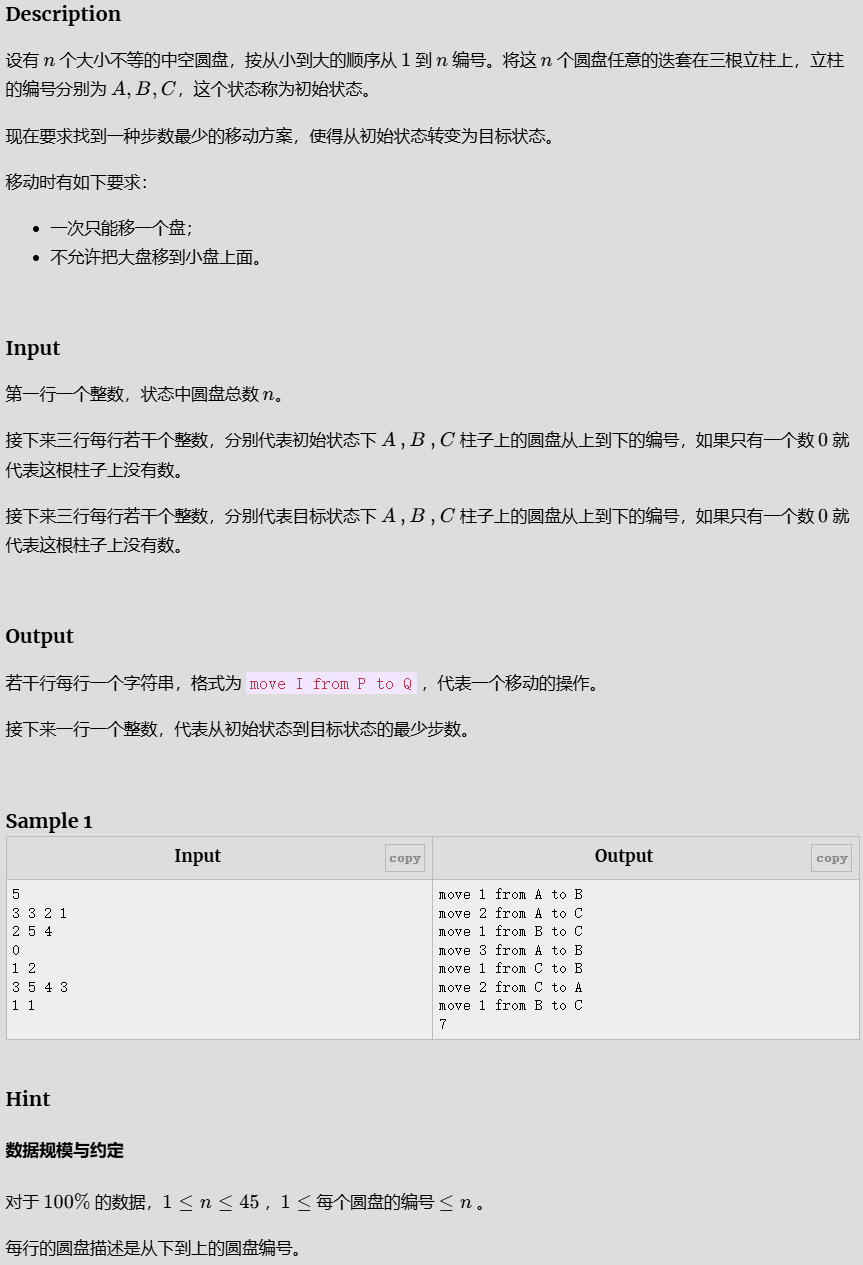
思路
我们可以考虑一下怎么才从初始的变到最终的答案. 首先我们可以想到需要从大到小依次归位,因为如果先归位小的 圆盘.如果后续还需要归位大的圆盘,我们需要对其进行移动,因此我们需要从大到小归位.
我们可以把归位的过程简单分为两步 1 把所有在目标点上的比该圆盘小的数移开, 2 把该圆盘移动到目标点; 重复操 作 但这就是最优的吗并不一定,因为我们起初的部分是一个恢复成一个常规汉诺塔操作的过程,因此我们实际上并不 止这一种恢复常规汉诺塔的方法,我们可以换一种方法 可以简单分为四步 1.把所有在另一个非目标点的圆柱上的比 该圆盘小的数移开 2.该圆盘移到另一个非目标点的圆柱上, 3把所有在目标点上的比该圆盘小的数移开, 4把该圆盘移 动到目标点;
我们会发现两种方法的12和34是相同的,因此我们只需要对最大的进行操作就可以了,然后先进行一次不输出结果的递归,查看各自所需要的步数,选择较小的输出方法
参考代码
#include <bits/stdc++.h>
using namespace std;
int main() {
int n;
cin >> n;
vector<int>a(n+1),b(n+1);
for ( int i = 0 ; i < 3 ; i++ ) {
int x;
cin >> x;
for ( int j = 0 ; j < x ; j++ ) {
int y;
cin >> y;
a[y] = i+1;
}
}
for ( int i = 0 ; i < 3 ; i++ ) {
int x;
cin >> x;
for ( int j = 0 ; j < x ; j++ ) {
int y;
cin >> y;
b[y] = i+1;
}
}
int flag = 0;
int mode = 0;
vector<int>t(n+1);
int cnt[2] = {0};
auto dfs = [&](auto self, int w, int s, int e)->void{
if ( s == e ) return;
for ( int i = w-1 ; i >= 1 ; i-- ) {
self(self,i,t[i],6-s-e);
}
if ( flag ) cout << "move " << w << " from " << char(s+'A'-1) << " to " << char(e+'A'-1)
<< '\n';
else cnt[mode]++;
t[w] = e;
};
mode = 0;
for( int i = 1 ; i < a.size() ; i++ ) {
t[i] = a[i];
}
for ( int i = n ; i >= 1 ; i-- ) dfs(dfs,i,t[i],b[i]);
mode = 1;
for( int i = 0 ; i < a.size() ; i++ ) {
t[i] = a[i];
}
dfs(dfs,n,t[n],6-t[n]-b[n]);
for ( int i = n ; i >= 1 ; i-- ) dfs(dfs,i,t[i],b[i]);
flag = 1;
for( int i = 1 ; i < a.size() ; i++ ) {
t[i] = a[i];
}
if ( cnt[0] < cnt[1] ) {
for ( int i = n ; i >= 1 ; i-- ) dfs(dfs,i,t[i],b[i]);
} else {
dfs(dfs,n,t[n],6-t[n]-b[n]);
for ( int i = n ; i >= 1 ; i-- ) dfs(dfs,i,t[i],b[i]);
}
cout << min(cnt[0],cnt[1]);
}
通天之汉诺塔
通天之汉诺塔
思路
容易得到答案是2^n-1,本题的n很大,可以用python或者java的大数类,也可以用c++模拟高精度。
参考代码
#include<bits/stdc++.h>
using namespace std;
#define int long long
const int N=5e5+10;
int a[N];
signed main()
{
int n;
cin>>n;
a[1]=1;
int idx=1;
while(n--){
for(int i=1;i<=idx;i++){
a[i]*=2;
}
for(int i=1;i<=idx;i++){
a[i+1]+=a[i]/10;
a[i]%=10;
}
if(a[idx+1]) idx++;
}
a[1]--;
for(int i=idx;i>=1;i--) cout<<a[i];
return 0;
}
高精度解法
#include<bits/stdc++.h>
using namespace std;
int n,l,i,a[10000];//a倒序放每位
void mul(){//高精乘2
for(int i=1;i<=l;i++)a[i]*=2;//每位乘2
for(int i=1;i<=l;i++)//满十进一(不会出现进2的情况)
if(a[i]>9){
a[i+1]++;
a[i]-=10;
}
if(a[l+1]>0)l++;//如高位进位,长度加1
return;
}
int main(){
cin>>n;
a[1]=1;
l=1;//答案初始长度为1
for(i=0;i<n;i++)mul();//求2^n
for(i=l;i>1;i--)cout<<a[i];//打印高位
cout<<a[1]-1;//由于不可能出现末位为0的情况,输出末位减1即可
return 0;
}
赦免战俘
赦免战俘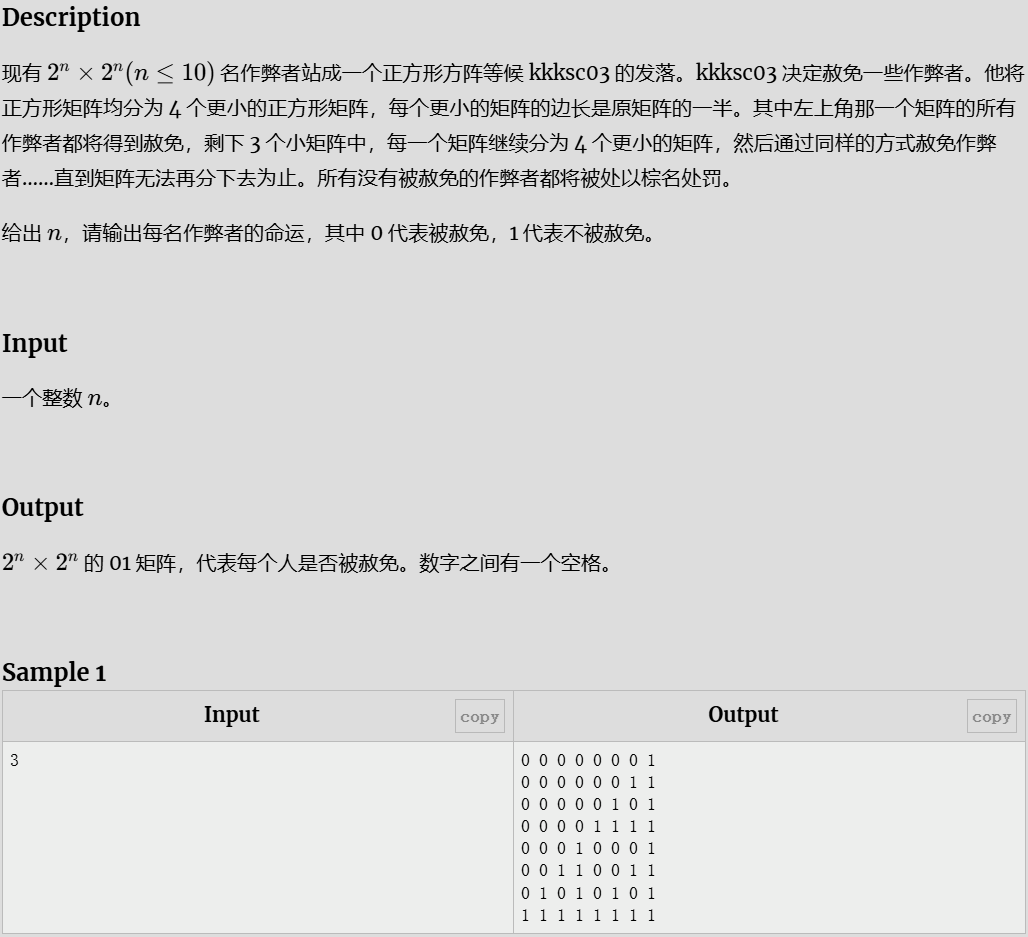
思路
每次递归找到要操作的正方形,直到不能继续分下去。
参考代码
#include<bits/stdc++.h>
using namespace std;
const int N=2005;
int a[N][N];
void solve(int x,int y,int r){
if(r<=1) return ;
r/=2;
for(int i=x;i<=x+r-1;i++){
for(int j=y;j<=y+r-1;j++){
a[i][j]=1;
}
}
solve(x,y+r,r);
solve(x+r,y,r);
solve(x+r,y+r,r);
}
signed main()
{
int n;
cin>>n;
solve(1,1,(1<<n));
for(int i=1;i<=(1<<n);i++){
for(int j=1;j<=(1<<n);j++){
cout<<1-a[i][j]<<' ';
}
cout<<'\n';
}
return 0;
}
解题代码
#include<bits/stdc++.h>
using namespace std;
#define LEN 1024
int s[LEN][LEN];
void Sm(int n, int ii, int jj);
int main() {
int n;
while (cin >> n) {
n = (int)pow(2, n);
for (int i = 0; i < n; i++) {
for (int j = 0; j < n; j++) {
s[i][j] = 1;
}
}//初始化
Sm(n, 0, 0);
for (int i = 0; i < n; i++) {
for (int j = 0; j < n; j++) {
printf("%d ", s[i][j]);
}
printf("\n");
}
}
return 0;
}
//赦免
void Sm(int n, int ii, int jj){
if (n >= 2) {
for (int i = ii; i < ii + n / 2; i++) {
for (int j = jj; j < jj + n/ 2; j++) {
s[i][j] = 0;
}
}
}
else return;
n = n / 2;
Sm(n, ii + n, jj);
Sm(n, ii, jj + n);
Sm(n, ii + n, jj + n);
}
数的计算
数的计算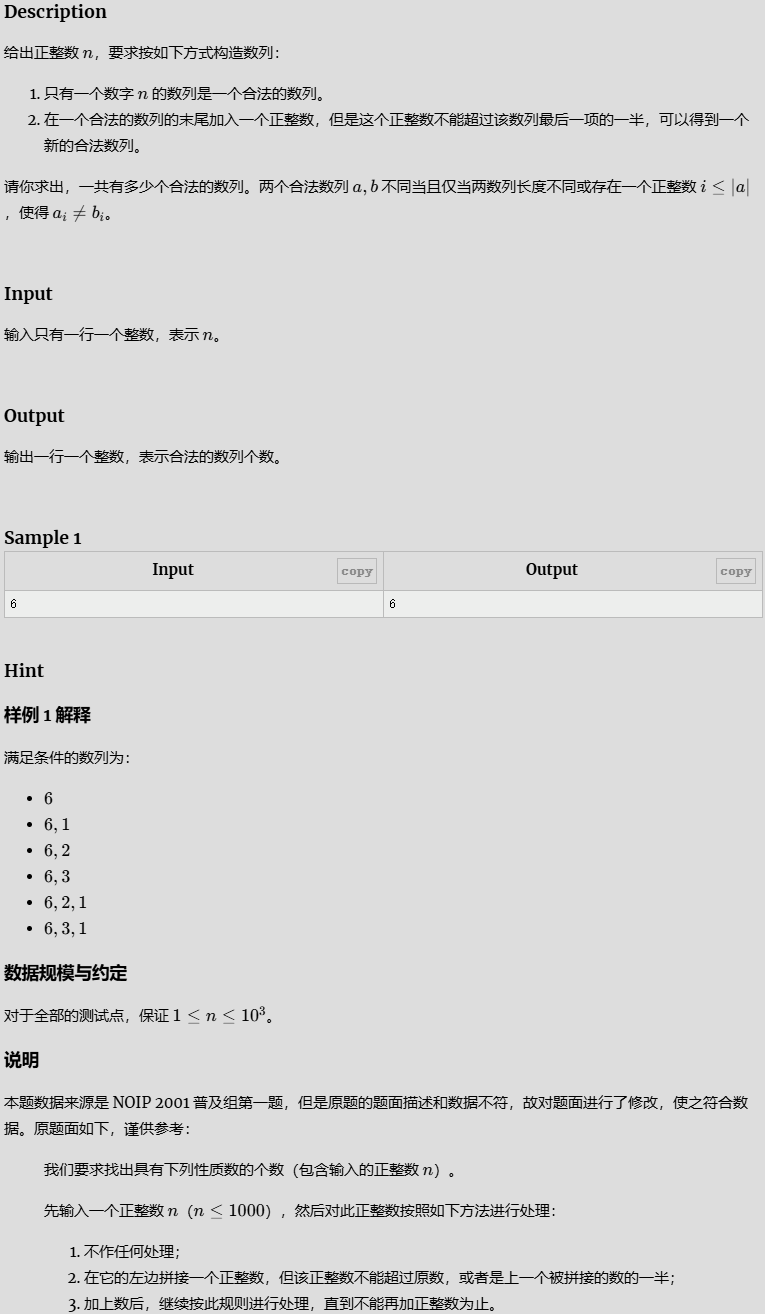
参考代码
#include<bits/stdc++.h>
using namespace std;
const int N=2005;
int cnt;
void solve(int x){
cnt+=x/2;
for(int i=2;i<=x/2;i++){
solve(i);
}
}
signed main()
{
int n;
cin>>n;
solve(n);
cout<<cnt+1;
return 0;
}
解题代码
#include<bits/stdc++.h>
#include<cmath>
using namespace std;
long long f(int);
void initDP();
int sum = 0;
int main() {
int n;
while (cin >> n) {
initDP();
cout << f(n) << endl;
}
return 0;
}
#define MAX_N 1000000 // 假设 n 的最大值为 1000000,可以根据需要调整
// 使用 long long 以防溢出
long long dp[MAX_N + 1];
// 初始化 dp 数组为 -1,表示这些值尚未计算
void initDP() {
for (int i = 0; i <= MAX_N; i++) {
dp[i] = -1;
}
}
// 递归函数,使用记忆化避免重复计算
long long f(int n) {
// 如果 dp[n] 已经被计算过,则直接返回结果
if (dp[n] != -1) {
return dp[n];
}
// 初始化 dp[n] 为 1,因为至少有一个合法的数列(只包含 n 本身)
dp[n] = 1;
// 遍历所有小于 n/2 的数,并累加它们的 dp 值到 dp[n]
for (int i = 1; i <= n / 2; i++) {
dp[n] += f(i);
}
// 返回计算得到的结果
return dp[n];
}
记忆化搜索
// 递归函数,使用记忆化避免重复计算
long long f(int n) {
// 如果 dp[n] 已经被计算过,则直接返回结果
if (dp[n] != -1) {
return dp[n];
}
// 初始化 dp[n] 为 1,因为至少有一个合法的数列(只包含 n 本身)
dp[n] = 1;
// 遍历所有小于 n/2 的数,并累加它们的 dp 值到 dp[n]
for (int i = 1; i <= n / 2; i++) {
dp[n] += f(i);
}
// 返回计算得到的结果
return dp[n];
}
结构体与STL入门
旗鼓相当的对手
旗鼓相当的对手
解题思路
录入每位同学的数据,遍历比较两个人每门课的差值和总分的差值,符合条件的两个人进行名字的字母大小进行排序输出。
注意
比较的是同学的名字的字母大小,用char name[9];进行存储比较;一开始我直接用string输入名字字符串,后比较输入顺序而导致错误。
参考代码
#include<iostream>
#include<cmath>
#define debug(x) cerr << #x << " "<<x <<endl;
using namespace std;
struct stu{
char name[100];
int c,m,e,sum;
}st[1010];
int main(){
int n;
cin >> n;
for(int i =0;i < n;i ++){
cin >> st[i].name >> st[i].c>>st[i].m>>st[i].e;
st[i].sum = st[i].c+st[i].e+st[i].m;
}
for(int i =0;i <= n-1;i ++){
for(int j = i+1;j <= n;j ++ ){
if(abs(st[i].c - st[j].c) <= 5 && abs(st[i].m-st[j].m) <= 5&&abs(st[i].e-st[j].e)<=5){
if(abs(st[i].sum - st[j].sum) <= 10){
cout << st[i].name <<" "<< st[j].name << endl;
}
}
}
}
return 0;
}
解题代码
#include<bits/stdc++.h>
using namespace std;
struct Student {
char name[9];
int yuwen;
int shuxue;
int yinyu;
int sum;
};
typedef Student student;
student a[1000];
bool cmp(student e1, student e2);
int main() {
int n;
while (cin >> n ) {
for (int i = 0; i < n; i++) {
cin >> a[i].name >> a[i].yuwen >> a[i].shuxue >> a[i].yinyu;
a[i].sum = a[i].yuwen + a[i].shuxue + a[i].yinyu;
}
for (int i = 0; i < n; i++) {
for (int j = i+1; j < n; j++)
{
if (cmp(a[i], a[j])) {
if (a[i].name[0] > a[j].name[0]) printf("%s %s\n", a[j].name, a[i].name);
else printf("%s %s\n", a[i].name, a[j].name);
}
}
}
}
return 0;
}
bool cmp(student e1, student e2) {
if ((abs(e1.yuwen - e2.yuwen) <= 5)
&&(abs(e1.shuxue - e2.shuxue) <= 5)
&&(abs(e1.yinyu - e2.yinyu) <= 5)
&&(abs(e1.sum - e2.sum) <= 10))
return true;
else return false;
}
第五人格之封禁出生密码机
第五人格之封禁出生密码机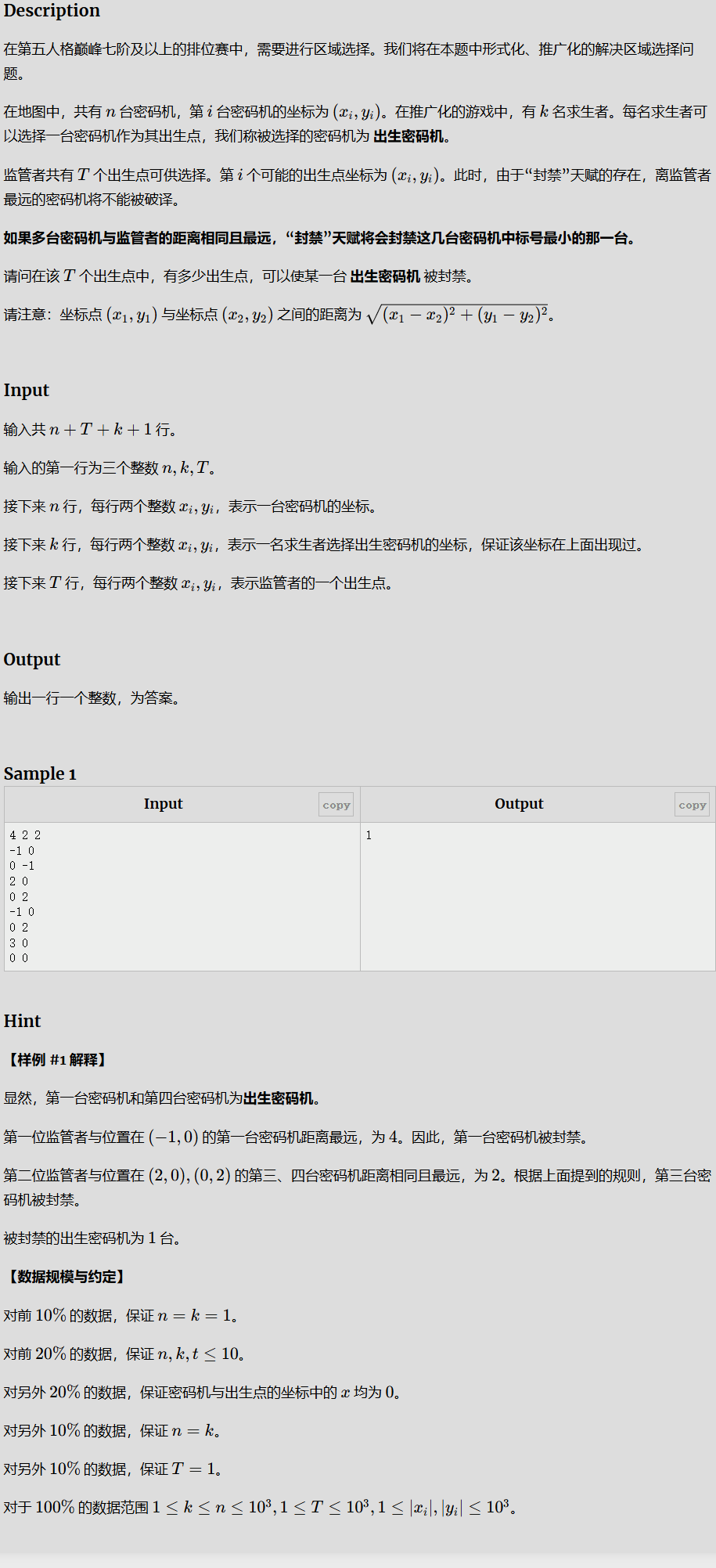
解题思路
总共有n个密码机 , k个出生密码机, t个监管者出生点
我们需要去求的是多少 有几个监管者的出生点可以 封禁 出生密码机
将所有坐标存入结构体,然后计算距离找出最远的几个点,在找出其中标号最小的点,然后与出生密码机比较,然后求解就好。
注意
不要用double类型 ,因为double再算距离的时候会造成精度不准确,算不出相等,所以在算距离的时候 不用开根号,直接进行比较
封禁不能单独提出来计算,否则重复只会计算一次,要在每个监管者封禁时都对出生密码机遍历一遍
参考代码
#include<iostream>
#include<cmath>
using namespace std;
struct ppp{
int x;
int y;
}p[10100];
struct ppp pp[10100];
int c[10010][10010];
int get ( int a,int b,int a1,int b1){
return (a - a1) *(a-a1) + (b - b1)*(b -b1);
}
int main(){
int T,N,K,a,b,m = 0;
cin >> N >> K>> T;
while(m < N ){cin >> pp[m].x >> pp[m].y; m ++;}
m = 0;
while(m < K ){
cin >> p[m].x >> p[m].y;
c[p[m].x + 1000][p[m].y + 1000] = 1;
m++;
}
int pi = 0,num = 0;
while( T -- ){
cin >> a >> b;
int mx = 0;
for(int i = 0;i < N;i ++ ){
int d = get(a,b,pp[i].x,pp[i].y);
if(d > mx){pi = i;mx = d;}
}
if(c[pp[pi].x+1000][pp[pi].y+1000] == 1){
num ++;
}
}
cout << num;
return 0;
}
解题代码
#include<bits/stdc++.h>
#include<cmath>
using namespace std;
struct ZB {
int x;
int y;
};
typedef ZB zb;
zb a[1000], b[1000], c[1000], fj[1000];
int jl(int, int, int, int);
//*注意: 不要用double类型 ,因为double 再算距离的时候会造成精度不准确,算不出相等,所以在算距离的时候 不用开根号,直接进行比较*
int cnt = 0;
int main() {
int n, t, k;
cin >> n >> k >> t;
for (int i = 0; i < n; i++) {//mmj
cin >> a[i].x >> a[i].y;
}
for (int i = 0; i < k; i++) {//qsz
cin >> b[i].x >> b[i].y;
}
for (int i = 0; i < t; i++) {//jgz
cin >> c[i].x >> c[i].y;
}//读入
for (int i = 0; i < t; i++) {//监管者
int max = -1; int m = -1;
for (int j = 0; j < n; j++) {//密码机
int tmp = 0;
tmp = jl(c[i].x, c[i].y, a[j].x, a[j].y);
if (tmp > max ) {
max = tmp;
m = j;//距离最大坐标
}
}
for (int i = 0; i < k; i++) {//求生者出生机
if (b[i].x == a[m].x && b[i].y == a[m].y) {
cnt++;
break;
}
}//封禁不能单独提出来计算,否则重复只会计算一次,要在每个监管者封禁时都对出生密码机遍历一遍
}
cout << cnt << endl;
return 0;
}
int jl(int x1, int y1, int x2, int y2) {
return ((x1 - x2) * (x1 - x2)) + ((y1 - y2) * (y1 - y2));
}
演唱会
演唱会
题意
总共n首歌 挑选m首歌 a个学生 b为zyl的学号
按照欢乐度排序 ,该歌曲欢乐度 = sum(a个学生 对于该首歌曲的 欢乐值)
特殊要求:
若 zyl 最喜欢的歌,被选上则排第一名
若没选上,则替换最后一名
1 <= m <= n <= 1e5
1 < b < a <100
参考代码
#include<bits/stdc++.h>
#include<limits.h>
#define endl '\n'
#define i64 long long
#define fi first
#define se second
#define Endl endl
#define END endl
#define mod3 998244353
#define mod7 1000000007
#define de(x) cerr << #x <<" "<<x <<" ";
#define deb(x) cerr << #x <<" "<<x <<endl;
using namespace std;
struct song{
int id,v;
friend bool operator<(const song &a,const song &b){
return a.v > b.v;
}
};
int main(){
ios_base::sync_with_stdio(false);
cin.tie(nullptr);
cout.tie(nullptr);
int n,m,a,b;
cin >> n >> m >> a >> b;
vector<song>s(n);
int id=-1,v=0;
for(int i = 0;i < a;i ++){
for(int j = 0;j < n;j++){
int x;
cin >> x;
s[j].v+=x,s[j].id = j + 1;
if(i+1 == b && x > v){
v = x,id = j + 1;
}
}
}
sort(s.begin(),s.end());
int ok = 0;
for(int i = 0;i < m;i ++){
if(s[i].id == id){ok = 1;break;}
}
if(ok){
cout << id <<" ";
for(int i =0 ;i <m;i++){
if(s[i].id != id)cout << s[i].id <<" ";
}
}else{
for(int i =0 ;i < m - 1;i++){
cout << s[i].id <<" ";
}cout << id;
}
return 0;
}
解题代码
#include<bits/stdc++.h>
using namespace std;
struct song{
int id,k;
}h[100010];
bool cmp(song a,song b){
return a.k>b.k;
}
int main()
{
int n,m,a,b;
int max=0,max1=0;
scanf("%d %d %d %d",&n,&m,&a,&b);
for(int i=1;i<=a;i++){
for(int j=1;j<=n;j++){
h[j].id=j;
int x;
scanf("%d",&x);
if(i==b){
if(x>max){
max=x;
max1=j;
}
}
h[j].k+=x;
}
}
sort(h+1,h+n+1,cmp);
int ret=0;
for(int i=1;i<=m;i++){
if(h[i].id==max1){
ret=1;
break;
}
}
if(ret==1){
printf("%d",max1);
for(int i=1;i<=m;i++){
if(h[i].id!=max1)
printf(" %d",h[i].id);
}
}
else{
for(int i=1;i<m;i++){
printf("%d ",h[i].id);
}
printf("%d",max1);
}
}
第五人格之ban人
BAN-PICK
题意
给出不按照阵营顺序和熟练值=度顺序的 n+m 个 角色(包名字、阵营、熟练度)
要求:让我们将熟练度最高的 5个 S阵营删除后,找出最高熟练度的S阵营角色名
相应的 H阵营 只需删除2个角色 ,然后输出角色名称priority_queue<>
先分类,然后进行结构体排序,可以直接用优先队列代替
数据范围:n < =1e3, m <= 1e3
参考代码
#include<bits/stdc++.h>
#include<limits.h>
#define endl '\n'
#define i64 long long
#define fi first
#define se second
#define pb(x) push_back(x)
#define Endl endl
#define END endl
#define mod3 998244353
#define mod7 1000000007
#define de(x) cerr << #x <<" "<<x <<" ";
#define deb(x) cerr << #x <<" "<<x <<endl;
using namespace std;
const int N = 1e3+10;
struct node{
string name,side;
i64 v;
friend bool operator<(const node &a,const node &b){
return a.v > b.v;
}
};
解法一: 结构体
int main(){
int n,m;
cin >> n >> m;
vector<node>s,h;
for(int i = 0;i < n + m;i ++){
node tmp;
cin >> tmp.name >> tmp.side >> tmp.v;
if(tmp.side == "S"){
s.pb(tmp);
}else{
h.pb(tmp);
}
}
sort(s.begin(),s.end());
sort(h.begin(),h.end());
cout << h[2].name <<Endl;
for(int i = 0;i < 4;i ++){
cout << s[5+i].name <<Endl;
}
return 0;
}
解法二 : 优先队列
int main(){
int n,m;
cin >> n >> m;
priority_queue<node>s,h;
for(int i = 0;i <n + m;i ++){
node tmp;
cin >> tmp.name >> tmp.side >> tmp.v;
if(tmp.side == "S"){
s.push(tmp);
}else{
h.push(tmp);
}
}
s.pop();
s.pop();
s.pop();
s.pop();
s.pop();
h.pop();
h.pop();
cout << h.top().name <<endl;
for(int i = 0;i < 4;i ++){
cout << s.top().name <<endl;
s.pop();
}
return 0;
}
高考组题
B3827[NICA #2] 高考组题
解题思路
有n道题目 , 找最重要的强两个,而有k个数的平均值表示为重要程度 ,若相同则选小号的;
参考代码
#include<bits/stdc++.h>
#include<limits.h>
#define endl '\n'
#define i64 long long
#define fi first
#define se second
#define Endl endl
#define END endl
#define mod3 998244353
#define mod7 1000000007
#define de(x) cerr << #x <<" "<<x <<" ";
#define deb(x) cerr << #x <<" "<<x <<endl;
using namespace std;
struct node{
int aver,id;
bool friend operator>(const node &a,const node &b){
return ((a.aver != b.aver) ? a.aver > b.aver : a.id < b.id);
}
};
int main(){
int n,k;
cin >> n >> k;
vector<node>a(n);
for(int i =0 ;i <n ;i ++){
int sum = 0;
for(int j = 0;j < k;j ++){
i64 tmp;
cin >> tmp;
sum += tmp;
}
a[i].id = i+1;
a[i].aver = sum/k;
}
sort(a.begin(),a.end(),greater<node>());
cout<<a[0].id <<endl<<a[1].id <<endl;
return 0;
}
解题代码
#include<bits/stdc++.h>
using namespace std;
struct Student {
int X;
double Num;
};
typedef Student student;
student a[100];
bool cmp(student e1, student e2);
int main() {
int n, k;
while (cin >> n >> k) {
for (int i = 0; i < n; i++) {
int sum = 0;
for (int j = 0; j < k; j++) {
int tmp;
cin >> tmp;
sum += tmp;
}
a[i].X = i + 1;
a[i].Num = sum/k;
}
sort(a, a + n, cmp);
cout << a[0].X << endl << a[1].X << endl;
}
}
bool cmp(student e1, student e2) {
if(e1.Num!=e2.Num)
return e1.Num > e2.Num;
else return e1.X < e2.X;
}
STL-vector动态数组
狼人杀
狼人杀
参考代码
#include<bits/stdc++.h>
#include<limits.h>
#define endl '\n'
#define i64 long long
#define fi first
#define se second
#define Endl endl
#define END endl
#define mod3 998244353
#define mod7 1000000007
#define de(x) cerr << #x <<" "<<x <<" ";
#define deb(x) cerr << #x <<" "<<x <<endl;
using namespace std;
// 题意翻译:
// 约瑟夫环 求解问题
// 只是 换成了更好用的vector ,相信大家都会的
int main(){
vector<int>a;
int n,m;
while(cin >> n >> m){
a.clear();
a.resize(2*n);
iota(a.begin(),a.end(),0);
int sum = a.size(),x = 0;
for(int i = 0;i < n ;i ++){
sum = a.size();
x = (x + m -1) % sum;
// de(x)
a.erase(a.begin() + x);
}
int cnt = 0;
sum=a.size();
for(int i = 0;i < 2 * n;i ++){
if(cnt < sum && a[cnt] == i){cout << "G";cnt++;}
else{cout<<"B";}
}
cout<<endl;
}
return 0;
}
解题代码
#include<bits/stdc++.h>
using namespace std;
int main() {
int n, m;
while (~scanf("%d %d", &n, &m)) {
int a[100000];
//初始化
for (int i = 1; i <= n * 2; i++) { //[1 - 2*n]
a[i] = 1;
}
int I = 1; int num = 1;//一共要杀 n 个,共有 2n 个人
int cnt = 1;
while (cnt <= n) {
if (a[I] == 0) {
if (I == 2 * n) {
I = 1;
}
else I++;
}
else if (num == m) {//数到了
cnt++;
num = 1;
a[I] = 0;
if (I == 2 * n) {
I = 1;
}
else I++;
}
else {//还没
num++;
if (I== 2 * n) {
I = 1;
}
else I++;
}
}
/*for (int i = 1; i <= 2 * n; i++) {
printf("%d", a[i]);
}
printf("\n");*/
for (int i = 1; i <= 2 * n; i++) {
if (a[i] == 1) {
printf("G");
}
else {
printf("B");
}
}
printf("\n\n");
}
return 0;
}
情书
情书
参考代码
#include<bits/stdc++.h>
#include<limits.h>
#define endl '\n'
#define i64 long long
#define fi first
#define se second
#define Endl endl
#define END endl
#define mod3 998244353
#define mod7 1000000007
#define de(x) cerr << #x <<" "<<x <<" ";
#define deb(x) cerr << #x <<" "<<x <<endl;
using namespace std;
void solve(){
string k,tmp;
getline(cin,k);
vector<string>s;
int n = k.size();
for(int i = 0;i < n;i ++){
if(k[i] !=' '){tmp += k[i];}
else{
s.push_back(tmp);
tmp =" ";
}
}
s.push_back(tmp);
n = s.size();
for(int i = 0;i < n;i ++){
reverse(s[i].begin(),s[i].end());
cout<< s[i] << " ";
}
cout<<endl;
}
int main(){
int T;
cin >> T;
getchar();
while(T --){
solve();
}
return 0;
}
解题代码
#include<bits/stdc++.h>
using namespace std;
int main() {
int T; scanf("%d", &T); getchar();
int tmp_T = T;
while (tmp_T >= 1) {
stack<char> s;
int flag = 1;
while (flag == 1) {
char tmp;
while (scanf("%c", &tmp) && tmp != ' ') {//输入
if (tmp == '\n') {
flag = 0; break;
}
s.push(tmp);
}//输出
while (!s.empty()) {//通过 flag 判断需不需要空格
printf("%c", s.top());
s.pop();
}
if (flag == 1) {
printf(" ");
}
}
printf("\n");
tmp_T--;
}
return 0;
}
简单计算器
简单计算器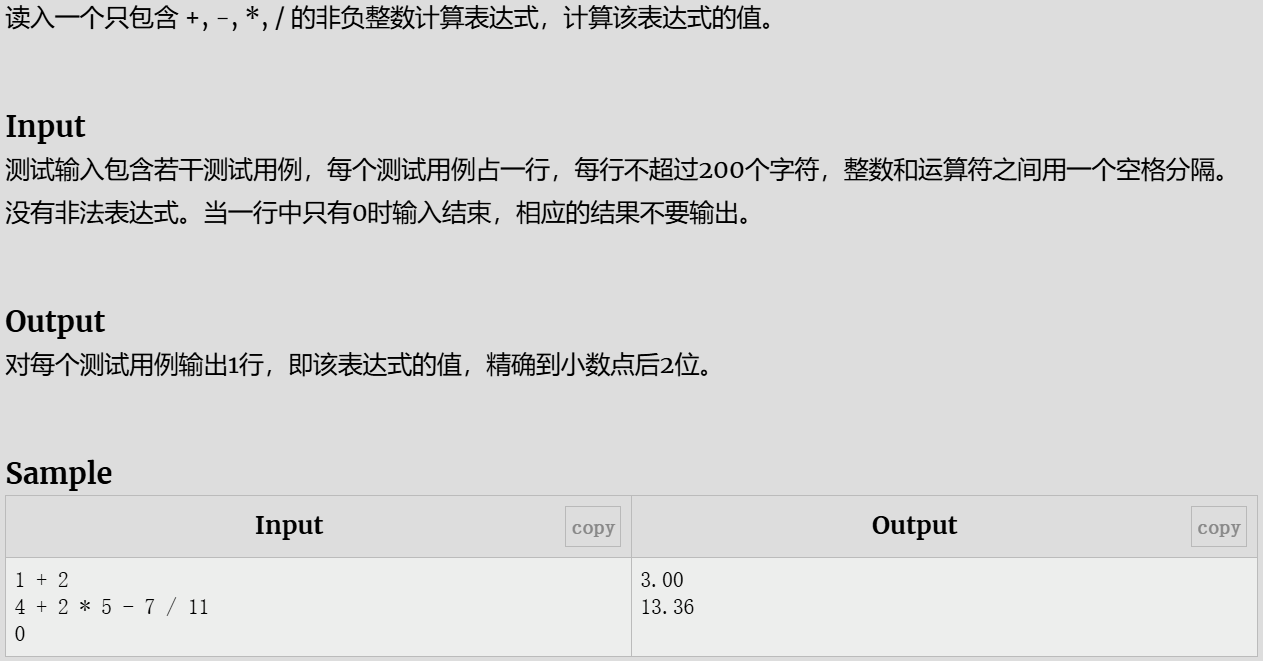
参考代码
#include<bits/stdc++.h>
#include<limits.h>
#define endl '\n'
#define i64 long long
#define fi first
#define se second
#define Endl endl
#define END endl
#define mod3 998244353
#define mod7 1000000007
#define de(x) cerr << #x <<" "<<x <<" ";
#define deb(x) cerr << #x <<" "<<x <<endl;
using namespace std;
double get(string s,int &i){
double res = 0;
for(;;i++){
if(s[i] <= '9' && s[i] >= '0'){
res = res * 10 + (int)(s[i] - '0');
}else{
break;
}
}
return res;
}
int main(){
string s;
while(getline(cin,s)&& s!="0"){
int n = s.size();
stack<char>of;
stack<double>stk;
double cnt = 0;
for(int i = 0;i < n;i ++){
if(s[i]>='0' && s[i]<='9'){
cnt = cnt * 10 + s[i] - '0';
// deb(cnt)
if(i+1==n ||s[i+1] == ' '){
stk.push(cnt);
cnt = 0;
}
}else if(s[i] == '+' || s[i] == '-'){
of.push(s[i]);
}else if(s[i] == '*'){
i += 2;
double res = get(s,i);
res = 1.0 * res * stk.top();
stk.pop();
stk.push(res);
}else if(s[i] == '/'){
i+=2;
double res = get(s,i);
res = 1.0*stk.top() / res;
stk.pop();
stk.push(res);
}
}
vector<double>num;
vector<char>oof;
while(!stk.empty()){
num.push_back(stk.top());
stk.pop();
}
while(!of.empty()){
oof.push_back(of.top());
of.pop();
}
n = oof.size();
reverse(num.begin(),num.end());
reverse(oof.begin(),oof.end());
double ans = num[0];
for(int i = 0;i < n;i ++){
if(oof[i] == '+')ans += num[i+1];
else{ans-=num[i+1];}
}
printf("%.02lf\n",ans);
while(!stk.empty())stk.pop();
}
return 0;
}
捉间谍
SPY
X Nation 的国家情报委员会收到一条可靠的信息,称 Y 国将派间谍窃取 X 国的机密文件。因此,国家情报委员会的指挥官立即采取措施,他将调查将进入NationX的人。同时,指挥官手里有两份名单,一份是Y国将要派往X国的间谍,另一份是X国之前派往Y国的间谍。这两个列表可能有一些重叠。因为间谍可能同时扮演两个角色,这意味着他可能是从X国派往Y国的人,所以我们只称这种类型为“双重间谍”。所以Y国可能会把“dual_spy”送回X国,现在很明显,这对X国有好处,因为“dual_spy”可以带回Y国的机密文件,而不用担心被Y国的边境扣留,所以指挥官决定没收Y国派来的那些,让老百姓和“dual_spy”同时进来。那么你能决定一个应该被指挥官抓住的名单吗?
A:该间谍列表包含将来到 NationX 前沿的内容。
B:该间谍列表包含将由 Nation Y发送。
C:该间谍列表包含之前发送给 NationY 。
输入
有几个测试用例。
每个测试用例包含四个部分,第一部分包含 3 个正整数 A、B、C,A 是将进入边界的数字。B 是 Nation Y 将要发送的号码,C 是 NationX 之前发送给 NationY 的号码。
第二部分包含 A 字符串,其名称列表将进入前沿。
第二部分包含 B 字符串,其名称列表由 NationY 发送。
第二部分包含C字符串,即“dual_spy”的名称列表。
每个测试用例后面都会有一个空行。
单个列表中不会有任何重复的名字,如果重复的名字出现在两个列表中,则它们意味着同一个人。
输出
输出指挥官应该抓到的名单(按名单B的出现顺序).如果没有人应该被抓到,那么,你应该输出“没有敌方间谍”
Sample
Input
8 4 3
Zhao Qian Sun Li Zhou Wu Zheng Wang
Zhao Qian Sun Li
Zhao Zhou Zheng
2 2 2
Zhao Qian
Zhao Qian
Zhao Qian
Output
Qian Sun Li
No enemy spy
参考代码
#include<bits/stdc++.h>
#include<limits.h>
#define endl '\n'
#define i64 long long
#define fi first
#define se second
#define Endl endl
#define END endl
#define mod3 998244353
#define mod7 1000000007
#define de(x) cerr << #x <<" "<<x <<" ";
#define deb(x) cerr << #x <<" "<<x <<endl;
using namespace std;
// dual spy
// 双料间谍
// 第一行 a,b,c;分别是 在X国家的人,Y国派来的间谍,之前X国安插在Y国的间谍
// 下面的文字输入和上面相同
// 找真正的Y国家到X国家的间谍
int main(){
int A,B,C;
while(cin >> A >> B >> C){
if(A == 0){break;}
vector<string>a(A),b(B),c(C);
for(int i = 0;i < A;i ++){ cin >> a[i]; }
for(int i = 0;i < B;i ++){ cin >> b[i]; }
for(int i = 0;i < C;i ++){ cin >> c[i]; }
for(int i = 0;i < B;i ++){
for(int j = 0;j < C;j ++){
if(b[i] == c[j]){
b.erase(b.begin()+i);
B --;
}
}
}
int ok = 0;
for(int i = 0;i < A;i++){
for(int j = 0;j <B;j ++){
if(a[i] == b[j]){
cout<< a[i] << " ";
ok = 1;
break;
}
}
}
if(!ok){cout << "No enemy spy";}
cout<<endl;
}
return 0;
}
写浏览器
Web Navigation
参考代码
#include<iostream>
#include<stack>
#include<queue>
#include<algorithm>
#include<limits.h>
#define endl '\n'
#define i64 long long
#define fi first
#define se second
#define Endl endl
#define END endl
#define mod3 998244353
#define mod7 1000000007
#define de(x) cerr << #x <<" "<<x <<" ";
#define deb(x) cerr << #x <<" "<<x <<endl;
using namespace std;
// visit 直接跳转
// back 回退 如果不能回退则 输出 忽略,
// forward 前进 如果不能前进则 输出 忽略 ,上面两个的形式都是
// 先进先出 ,所以很快就能够知道, 是用栈
// qiut 结束
// a b c (d)
// a (b) c d
int main(){
string s,cnt="";
stack<string>stkb,stkf; // stkb是back所用的,stkf为forward所用
// queue<string>q;
cnt = "http://www.acm.org/";
while(cin >> s){
if(s == "QUIT"){break;}
if(s == "VISIT"){
if(cnt != ""){stkb.push(cnt);}
while(!stkf.empty())stkf.pop();
cin >> cnt;
}else if(s == "BACK"){
if(!stkb.empty()){
stkf.push(cnt);
cnt = stkb.top();
stkb.pop();
}else{
cout <<"Ignored" <<endl;
continue;
}
}else{
if(!stkf.empty()){
stkb.push(cnt);
cnt = stkf.top();
stkf.pop();
}else{
cout <<"Ignored" <<endl;
continue;
}
}
cout << cnt <<endl;
}
return 0;
}
小鱼的数字游戏
小鱼的数字游戏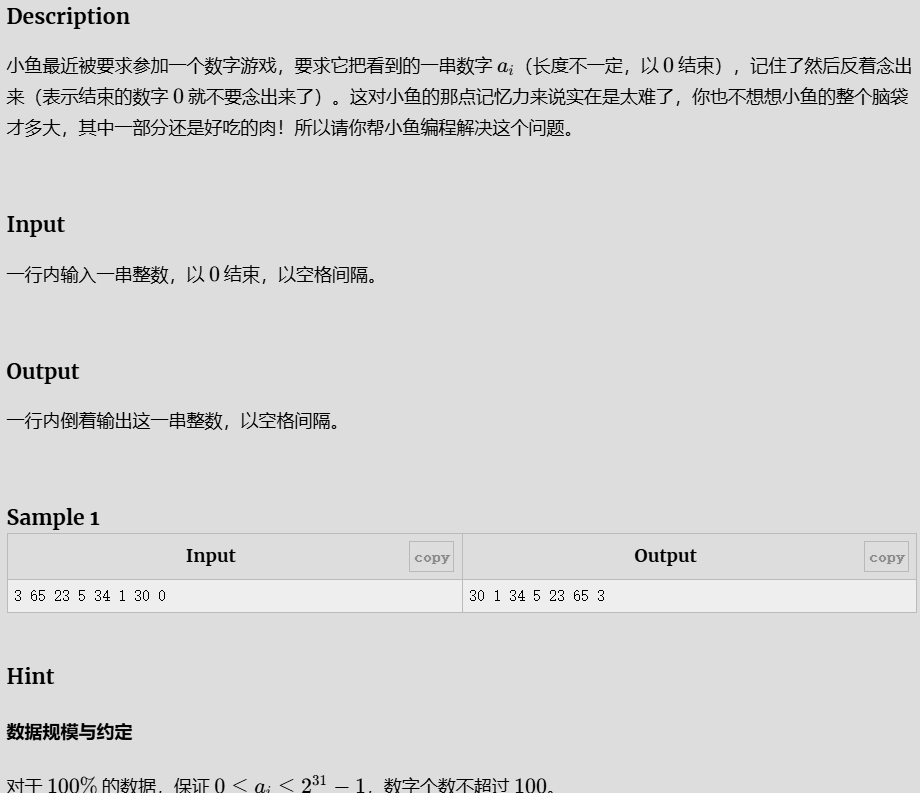
参考代码
#include<bits/stdc++.h>
#include<limits.h>
#define endl '\n'
#define i64 long long
#define fi first
#define se second
#define Endl endl
#define END endl
#define mod3 998244353
#define mod7 1000000007
#define de(x) cerr << #x <<" "<<x <<" ";
#define deb(x) cerr << #x <<" "<<x <<endl;
using namespace std;
int main(){
int t;
stack<int>stk;
while(cin >> t){
if(t == 0){break;}
stk.push(t);
}
while(!stk.empty()){
cout << stk.top() <<" ";
stk.pop();
}
return 0;
}
解题代码
#include<bits/stdc++.h>
using namespace std;
int main() {
stack<int> s;
int x;
while (cin >> x&&x!=0) {
s.push(x);
}
while (!s.empty())
{
cout << s.top() << " ";
s.pop();
}
return 0;
}
字符串判定
Chat room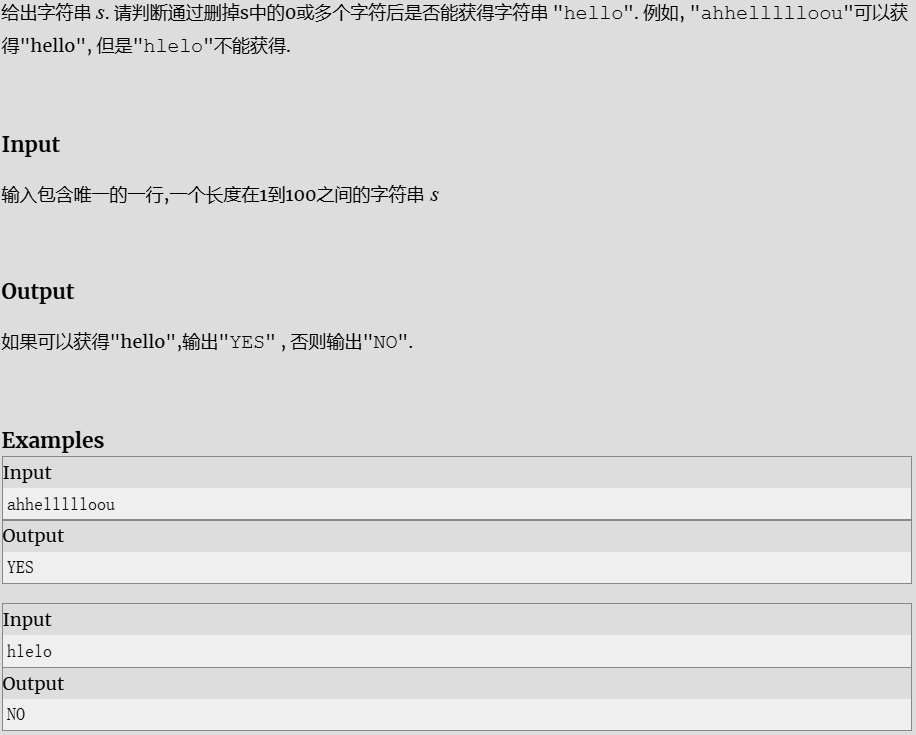
参考代码
#include<bits/stdc++.h>
#include<limits.h>
#define endl '\n'
#define i64 long long
#define fi first
#define se second
#define Endl endl
#define END endl
#define mod3 998244353
#define mod7 1000000007
#define de(x) cerr << #x <<" "<<x <<" ";
#define deb(x) cerr << #x <<" "<<x <<endl;
using namespace std;
int main(){
string s,h1 = "hello";
cin >> s;
int cnt = 0,n = s.size();
for(int i = 0;i < n;i ++){
if(s[i] == h1[cnt]){
cnt ++;
}
}
if(cnt == 5){
cout << "YES" <<endl;
}else{
cout << "NO" <<endl;
}
string s;
cin >> s;
string h = "hello";
int index = 0,cnt=0;
while((index = s.find(h[cnt],index))!= string::npos){
index ++;
cnt ++;
if(cnt >= 5){break;}
}
cout<< ((cnt == 5) ? "YES":"NO") <<endl;
return 0;
}
解题代码
#include<bits/stdc++.h>
#include<string.h>
using namespace std;
char a[6] = { 'h','e','l','l','o' };
int x=0;
bool flag = false;
int main() {
string y;
cin >> y;
int len = y.length();
for (int i = 0; i < len; i++) {
if (y[i] == a[x]) {
x++;
}
}
if (x == 5)flag = true;
if (flag)printf("YES");
else printf("NO");
return 0;
}
英雄联盟技能点
Doors and Keys
解题代码
#include<bits/stdc++.h>
#include<string.h>
using namespace std;
char a[6] = { 'r','g','b' };
char b[6] = { 'R','G','B' };
int jnd[3] = { 0 };
int x = 0;
int main() {
string y; int num;
cin >> num;
cin.ignore(numeric_limits<streamsize>::max(), '\n');
while (num-- > 0) {
cin >> y;x=0;int jnd[3] = { 0 };
for (char c : y) {
for (int j = 0; j < 3; j++){
if (c == b[j] && jnd[j] == 1) {
x++;
}
else if (c == a[j]) {
jnd[j] = 1;
}
}
}
bool flag = false;
if (x == 3)flag = true;
if (flag)printf("YES\n");
else printf("NO\n");
}
return 0;
}
复读机
复读机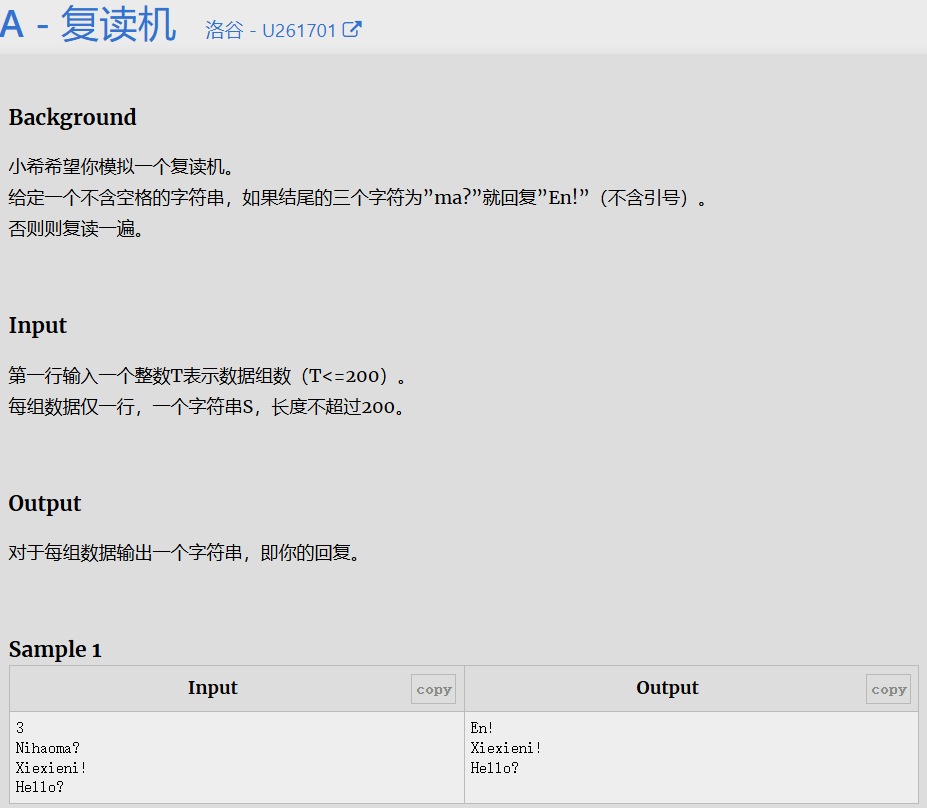
参考代码
#include <bits/stdc++.h>
using namespace std;
int main()
{
int n;cin>>n;
while(n--){
string s;cin>>s;
if(s.size()>=3&&s.substr(s.size()-3,3)=="ma?")
cout<<"En!"<<'\n';
else
cout<<s<<'\n';
}
return 0;
}
substr()
定义
substr()是C++语言函数,主要功能是复制子字符串,要求从指定位置开始,并具有指定的长度。如果没有指定长度_Count或_Count+_Off超出了源字符串的长度,则子字符串将延续到源字符串的结尾。——摘自百科词条
语法
substr(size_type _Off = 0,size_type _Count = npos) //一种构造string的方法
形式 : s.substr(pos, len)
返回值:string,包含s中从pos开始的len个字符的拷贝(pos的默认值是0,len的默认值是s.size() - pos,即不加参数会默认拷贝整个s)
异常:若pos的值超过了string的大小,则substr函数会抛出一个out_of_range异常;若pos+n的值超过了string的大小,则substr会调整n的值,只拷贝到string的末尾
万里的成绩
万里的成绩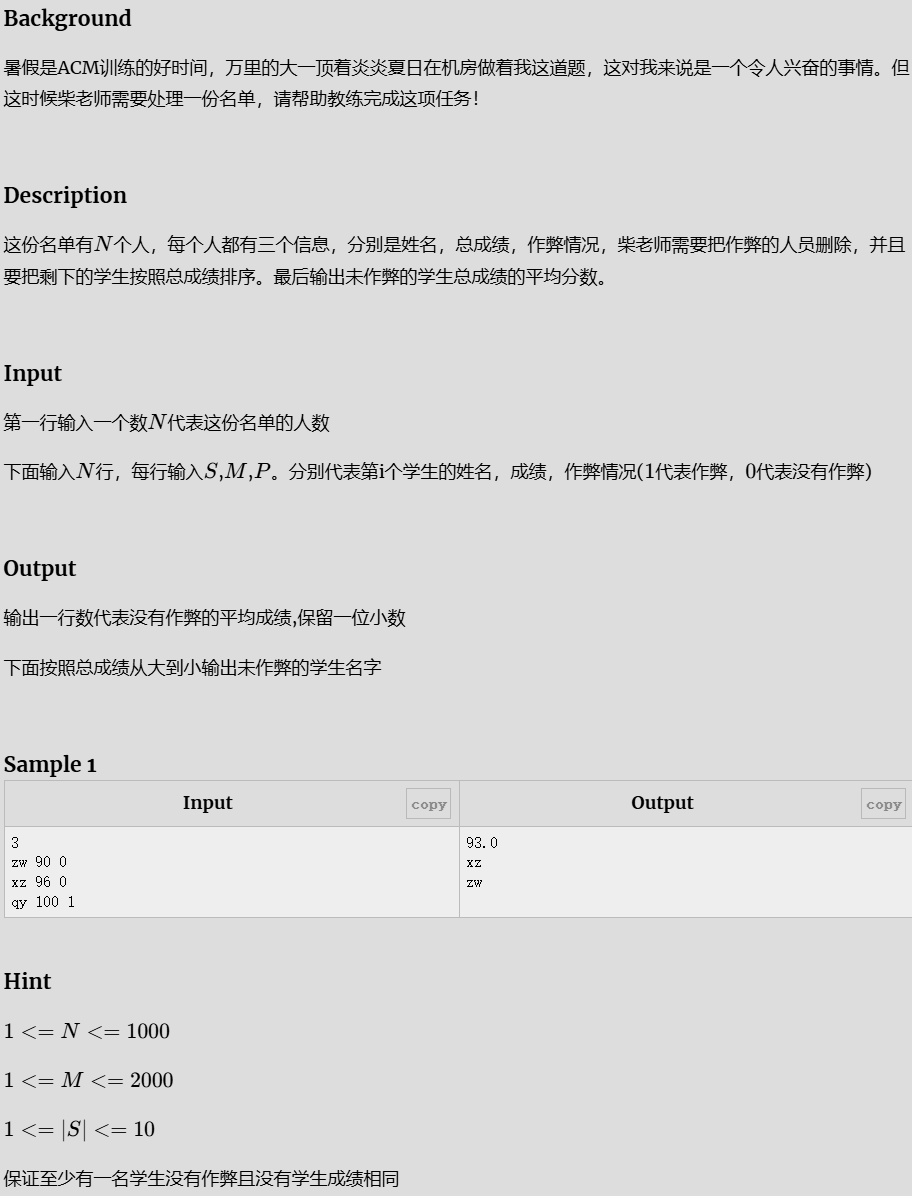
解题思路
姓名跟成绩要连在一起来排序,结构体,pair都可以,数组也行但麻烦很多。
参考代码
#include <bits/stdc++.h>
using namespace std;
#define all(x) x.begin(),x.end()
int main()
{
int n;cin>>n;
vector<pair<int,string>> v;//按成绩排序
//pair创建结构体
double sum=0,d=0;//成绩综合跟合格人数
for(int i=1;i<=n;i++){
int co,a;
string s;
cin>>s>>a>>co;
if(co) continue;//判断是否作弊
sum+=a;
d++;
v.push_back({a,s});//输入结构体
}
sum/=d;
printf("%.1lf\n",sum);
sort(all(v));//从小到大,上面定义了x.begin(),x.end()
reverse(all(v));//从大到小,将数组倒序
for(auto [x,y]:v)
cout<<y<<'\n';
}
pair<T1,T2>
在C++中,vector<pair<int, string>> v; 是一个声明了一个包含 pair<int, string> 对的向量。这种数据结构允许你将两个不同类型的数据(例如整数和字符串)组合成一个单一的元素,并且可以方便地存储在一个动态数组中
具体来说,pair<int, string> 是一个标准模板库(STL)中的数据结构,用于存储两个不同类型的对象,其中第一个类型是 int,第二个类型是 string。而 vector 是另一个STL容器,它是一个动态数组,可以存储任意类型的元素
要使用这个向量,你可以通过以下方式初始化和操作它:
vector<pair<int, string>> v;
使用 push_back 方法向向量中添加新的 pair 对象。需要注意的是,每次添加时都需要构造一个新的 pair 对象
pair<int, string> p(1, "hello");
v.push _back(p);
或 v.push_back({a,s});
可以通过索引访问向量中的每个 pair 对象,并分别获取其两个成员
auto first = v[0].first; // 获取第一个元素的值
auto second = v[0].second; // 获取第二个元素的值
使用范围基的for循环来遍历整个向量,并访问每个 pair 对象的两个成员
for (const auto& p : v) {
cout << "First: " << p.first << ", Second: " << p.second << endl;
}
总结起来,vector<pair<int, string>> v; 在C++中是一个非常有用的工具,能够让你以高效的方式存储和管理包含不同类型数据的对。
数组排序技巧
#define all(x) x.begin(),x.end()
sort(all(v));//从小到大,上面定义了x.begin(),x.end(),x用v代替
reverse(all(v));//从大到小,将数组倒序
for(auto [x,y]:v)
详见auto语法
自由删除组新序列
Make Them Narrow
解题思路
首先这题很容易想到贪心,但是实际上是不成立的,因为小的间隙的那边在去掉小间隙后可能来个巨大的间隙,例如
7 3
1 5 10 15 1000000 2000000 2000001
所以换种方法,删数一定要从数列的最大值或最小值中删的,这样才会使最值之差减小,因此要先将序列排序。由于无论怎么删,都是要删掉 𝑘 个数,所以我们可以枚举从序列左边删去多少个数,从而得出此种删数方法的结果,最后比出最小值即可,复杂度 𝑂(𝑛) 。
参考代码
#include <bits/stdc++.h>
using namespace std;
#define all(x) x.begin(),x.end() //又一次见,可见便利性
int main()
{
int n,k;cin>>n>>k;
vector<int> v(n+5); //动态数组
for(int i=1;i<=n;i++)
cin>>v[i];
sort(v.begin()+1,v.begin()+1+n);
int ans=1e9+100;
for(int i=0;i<=k;i++){
int x=i+1;
int y=n-(k-i);
ans=min(ans,v[y]-v[x]); //min()求最小值
}
cout<<ans<<'\n';
}
min()
在C/C++中,min()函数用于比较两个或多个值,并返回其中最小的值,允许它应用于多种类型的数据。
以下同理可得max()、max_element等。
多个参数的min()
对于多个参数的情况,可以使用标准库中的std::min_element函数或者直接使用std::min函数的变体:
#include <iostream>
#include <vector>
#include <algorithm>
int main() {
std::vector<int> numbers = {3, 1, 4, 1, 5, 9};
auto it = std::min_element(numbers.begin (), numbers.end ());
std::cout << "The smallest number is: " << *it << std::endl;
return 0;
}
自定义比较器
如果需要对自定义类型进行最小值比较,可以使用自定义比较器:
#include <iostream>
#include <vector>
#include <algorithm>
struct My对比器 {
bool operator()(const MyType& a, const MyType& b) const {
return a.get 某种属性() < b.get 某种属性();
}
};
int main() {
std::vector<MyType> myTypes = {MyType(1), MyType(2), MyType(3)};
auto it = std::min_element(myTypes.begin (), myTypes.end (), My对比器());
std::cout << "The smallest MyType is: " << *it << std::endl;
return 0;
}
总结来说,无论是C还是C++,min()函数都是一个非常实用的工具,能够方便地找到给定值中的最小值。在C++中,由于其强大的模板机制和标准库的支持,min()函数的应用范围更加广泛和灵活。
此处同理用到max()
#include <bits/stdc++.h>
using namespace std;
#define all(x) x.begin(),x.end()
int main()
{
double x1,x2,y1,y2,r1,r2;
cin>>x1>>y1>>r1>>x2>>y2>>r2;
double dx=x1-x2,dy=y1-y2;
double d=sqrt(dx*dx+dy*dy);
double ans=max(0.0,d-r1-r2);
printf("%.2lf",ans);
}
记忆化搜索(2)
Function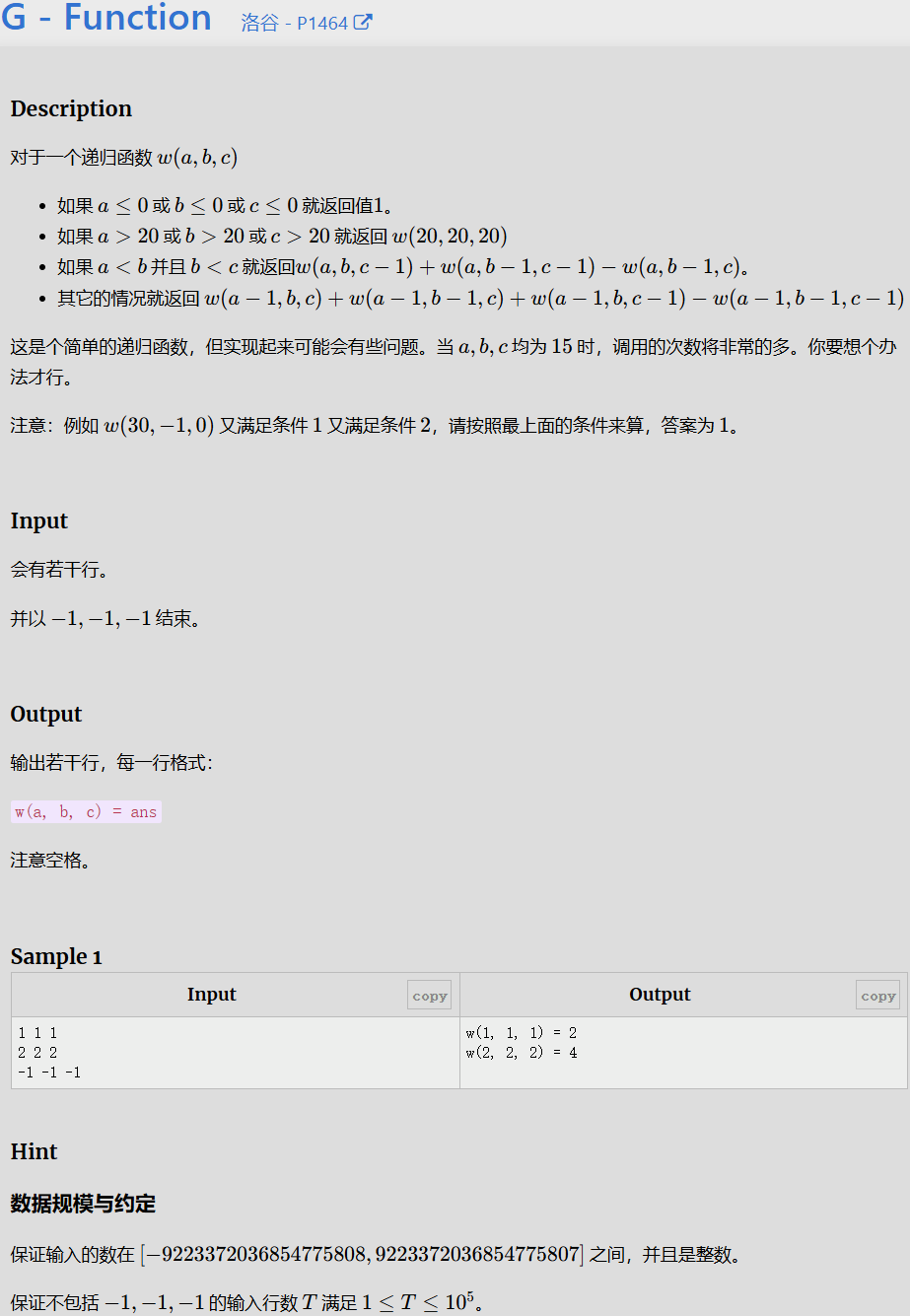
解题思路
记忆化搜索(更多解释请看参考资料),算出一次w(x,y,z)后就不用再算了
参考代码
#include <cstdio>
#define LL long long
LL dp[25][25][25];
LL w(LL a, LL b, LL c)
{
if(a <= 0 || b <= 0 || c <= 0) return 1;//两个特判,题意里都有的。
if(a > 20 || b > 20 || c > 20) return w(20, 20, 20);
if(a <b && b < c)//情况一,每一个没有储存过的“w”值全部储存,如果有就直接调用。
{
if(dp[a][b][c-1] == 0)
{
dp[a][b][c-1] = w(a, b, c-1);
}
if(dp[a][b-1][c-1] == 0)
{
dp[a][b-1][c-1] = w(a, b-1 ,c-1);
}
if(dp[a][b-1][c] == 0)
{
dp[a][b-1][c] = w(a, b-1, c);
}
dp[a][b][c] = dp[a][b][c-1] + dp[a][b-1][c-1] - dp[a][b-1][c];
}
else//同上
{
if(dp[a-1][b][c] == 0)
{
dp[a-1][b][c] = w(a-1, b, c);
}
if(dp[a-1][b-1][c] == 0)
{
dp[a-1][b-1][c] = w(a-1, b-1 ,c);
}
if(dp[a-1][b][c-1] == 0)
{
dp[a-1][b][c-1] = w(a-1, b, c-1);
}
if(dp[a-1][b-1][c-1] == 0)
{
dp[a-1][b-1][c-1] = w(a-1, b-1, c-1);
}
dp[a][b][c] = dp[a-1][b][c] + dp[a-1][b][c-1] + dp[a-1][b-1][c] - dp[a-1][b-1][c-1];
}
return dp[a][b][c];
}
int main()
{
LL a, b, c;
while(scanf("%lld%lld%lld", &a, &b, &c))//无限输入,直到“-1 -1 -1”
{
if(a == -1 && b == -1 && c == -1) return 0;//-1 -1 -1就直接结束,不运算了。
printf("w(%lld, %lld, %lld) = ", a, b, c);
printf("%lld\n", w(a, b, c));
}
}
Keep it Beautiful
Keep it Beautiful
解题思路
把 a 首尾相连。如果不存在或只存在一对相邻的数,前面的数大于后面的,那么 a 就是「漂亮的」。
参考代码
#include <bits/stdc++.h>
using namespace std;
int main() {
int tt;
cin >> tt;
while (tt--) {
int q;
cin >> q;
vector<int> x;
int cnt = 0;
while (q--) {
int num;
cin >> num;
if (x.empty()) {
x.push_back(num);
cout << 1;
continue;
}
int new_cnt = cnt;
new_cnt -= (x.back() > x[0]);//原先首尾部关系
new_cnt += (num > x[0]);//现在首尾关系
new_cnt += (x.back() > num);//加的数字跟尾部关系
if (new_cnt >= 2) {
cout << 0;
} else {
cnt = new_cnt;
x.push_back(num);
cout << 1;
}
}
cout << '\n';
}
return 0;
}















 7132
7132











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









