







目录
Chatting or Acting?——DeepSeek的突破边界与“浙大先生”的未来图景
DeepSeek:回望AI三大主义与加强通识教育
从达特茅斯启航的人工智能三大主义
1. 1955年8月,基本猜想:学习的所有特点以及大多数智能,原则上都可以被精确描述出来,从而用一台机器来模拟。
What I cannot create,I cannot understand. 不可造也,未能知也。
2. 1956年6月—8月,达特茅斯会议的七大议题:自动计算机、使用语言对计算机进行编程、神经网络、计算复杂度、智能算法的自我改进、智能算法的抽象能力、智能算法的随机性和创造力。
3. 达特茅斯会议号角的吹响,宣布着人工智能登上了历史舞台。
人工智能三剑客之一:符号主义人工智能的逻辑推理
1. 人工智能的三大主义:以符号主义为核心的逻辑推理,以连接主义为核心的数据驱动、以行为主义为核心的强化学习。
2. 人工智能的逻辑推理:正确的知识+正确的推理=>正确的结果

The limits of my language are the limits of my mind. All I know is what I have words for. 语言的边界就是思想的边界。
3. 常用到的两种推理方法:演绎推理、归纳推理。
(1)演绎推理
定义:人们以一定反应客观规律的理论认识为依据,从服从该事物的已知部分,推理得到事物的未知部分的思维方法。
例子:哲学圣贤亚里士多德经典的苏格拉底三段论就是一个非常有名的演绎推理。
(2)归纳推理
定义:人们以一系列经验事物或知识素材为依据,寻找出其服从的基本规律或共同规律,并假设同类事物中的其他事物也服从这些规律。
例子:这里的天鹅都是白色的,那里的天鹅都是白色的,天鹅是白色的。
4. 知识工程
围绕某一特定领域的应用,将人类专家知识转化为结构化知识,存储进数据库,从而支持该领域应用,构建“知识水晶球”,这就是知识工程(knowledge engineering)和专家系统(expert system)。

世界上第一个专家系统Dendral:1965年,图灵奖获得者、斯坦福大学计算机科学家费根鲍姆和化学家勒德贝格合作,结合化学领域的专门知识,研制了世界上第一个专家系统Dendral,进行分子结构分析。
6. 专家系统的缺陷:缺乏人类常识、知识不完备
例子一:大前提不完备,并非所有的鸟都会飞

例子二:缺乏人类常识
麦卡锡批评当时盛行的专家系统因为缺乏常识而给出令人一头雾水的解决方案。在向专家系统询问有关如何治疗肠道中存在霍乱弧菌的方案时,专家系统开出了服用两周四环素的处方。虽然这很可能会杀死所有的细菌,但到那时病人已经死了。
人工智能三剑客之二:连接主义人工智能的数据驱动
1. 深度神经网络:层层递进,逐层抽象。
深度学习的基本动机在于通过“端到端学习(end-to-end learning)”这一机制来构建多层神经网络,已学习隐含在数据内部的关系,从而使学习所得特征具有更强的表达能力。

像素点空间 ---神经网络非线性映射---> 语义空间
2. CPU与GPU
CPU就好比是一位脑力劳动者/领导。可以应对各种复杂的逻辑运算、有序任务。使计算机的整体运行井井有条。像操作系统怎么运行、程序怎么调度,都需要CPU的管理。
GPU更像是一个体力劳动者/工人。拥有大量的计算核心,能同时处理大量简单又重复的计算任务。在处理图形效果、大规模数据并行计算这些方面,GPU表现出的效率比CPU高太多了。
之前看到的一个很有趣的比喻:
CPU:8个博士写高数
GPU:上万次加减法
3. 神经元的工作机制:加权累加、阈值输出。

1943年,神经学家沃伦和逻辑学家沃尔特·皮兹合作提出了以他们名字命名的“MCP神经元”模型:在科学史上第一次,我们知道了我们是怎么知道的。
4. 概率为王下的黑箱效应
面对神经网络如炼金术一样的“黑箱效应”,不得不感叹复杂深度模型“我亦无他,唯手熟尔”,与知其然且知其所以然相去甚远。

5. 数据驱动下的滑铁卢
由于训练样本有限、不全面(样本数据:隐藏坦克的阴天森林、无坦克的晴天森林),神经网络只学会了区分阴天和晴天,而不是区分森林是否有坦克。

这提示我们,当人工智能应用到人们的生活时(如:无人驾驶),如果测试场景有限、不全面,那这个系统在未来可能会出现很多低级和严重错误。
人工智能三剑客之三:行为主义人工智能的百折不挠
1. 强化学习
孙子兵法云:“谋定而后动,知止而有得”。
意思是:谋划准确周到而后行动,知道在合适的时机收手,会有收获。
强化学习:人工智能算法在不断与其所处环境交互中进行学习,通过“尝试与试错”不断与环境交互,形成序贯决策,直至进入终止状态。反馈牵引,从经验中策略学习。

2. 围棋人机大战:上帝之落子
李世石与AlphaGo第四局中第78步落子被称为“上帝之落子(God' s Touch)”、“神之一手”,这一步在AlphaGo的训练数据中从未见过,触发了AlphaGo的AI盲区,李世石成功扳回一局。
从ChatGPT到DeepSeek
ChatGPT
1. 人工智能的IPHONE时刻
2007年1月9日,乔布斯发布第一代iPhone苹果手机,把iPod、电话、移动互联网设备等进行有机整合(苹果生态圈),推动了移动互联网进入了黄金发展年代。
2023年2月,英伟达创始人兼CEO黄仁勋提出随着ChatGPT为代表的大模型出现,我们已经进入“人工智能的iPhone时刻(iPhone moment of AI) ”,这一观点受到美国《财富》杂志、华尔街时报等媒体的广泛认可并转载。
《自然》杂志列出2023年度十大人物(Nature's10) ,除了按惯例从全球的重大科学事件中评选出十位人物外,还有一位非人类——人工智能(AI)工具ChatGPT也“抢镜”上榜。
2. GPT(Generative Pretraining Transformer)
《Google:Attention is all you need》中提出的Transformer架构:

Transformer的结构图,拆解开来,主要分为图上4个部分:输入、编码器、解码器、输出。Transformer是一个基于Encoder-Decoder框架的模型。通过Q、K、V矩阵计算实现自注意力机制。
3. GPT训练的三大方式:无监督预训练、有监督微调、反馈强化学习。
4. 数据是燃料,模型是引擎,算力是加速器。

SORA
单词有意义的线性组合->句子;像素点有意义的空间组合->图像;时空子块有意义的时序组合->视频。
2024年春节,OpanAI发布人工智能文生视频大模型,but OpenAI并未单纯将其视为视频模型,而是作为“世界模拟器” 。根据OpenAI提供的有限的技术报告,Sora主要是利用了Diffusion和Transformer模型。Diffusion也叫扩散模型,主要包含加噪和去噪两个过程,它的特点是:更多的注意力在细节,可以生成精美图片;Transformer的关键部件是注意力和编解码器,它的特点是:可以突破序列长度限制,更擅长掌控全局。
Sora基于概率合成的失误视频:

2025年2月25日晚,阿里云宣布开源视频生成大模型万相2.1(Wan),不仅代码、权重全开源,更以86.22%的评测成绩碾压Sora、Luma等国际巨头,中国AI大模型的“封神时刻”到来!
The bitter lession in AI
通过不断扩充模型规模而形成“我亦无他,唯手熟尔”合成能力的思路存在一定天花板,因为“化繁为简,大巧不工”是推动“机器学习”走向“学习机器”的初心。
DeepSeek
DeepSeek打破了大语言模型以大算力为核心的预期天花板,在资源有限的情况下,取得了比肩世界顶级模型的性能。
DeepSeek-V3:混合专家模型、模型参数低秩压缩、工程化努力

DeepSeek-R1:强化学习推理和小模型蒸馏

Chatting or Acting?——DeepSeek的突破边界与“浙大先生”的未来图景
DeepSeek简介
DeepSeek模型结构创新
1. 采用MoE解决路由崩溃难题
(1)传统的 Top-2 路由策略
经典的 MoE(Mixture-of-Experts)架构,使用 Top-2 Routing 策略。由 N 个专家(Expert) 组成,路由器(Router)会为每个输入选择 K=2 个专家进行计算。计算结果通过加权求和后输出。
(2)细粒度专家分割(Fine-grained Expert Segmentation)
这一阶段对专家进行了更细粒度的划分:将 N 个专家细分为 2N 个更小的专家,从而提供更多的专家选择,提高专家的专业化能力。路由器在更大规模的专家池中选择 K=4 个专家,从而增加多样性和灵活性。
(3)共享专家隔离(Shared Expert Isolation)
最终的 DeepSeekMoE 架构,在 (2) 的基础上 引入共享专家:绿色的专家表示 共享专家(Shared Expert),专门处理通用知识。其余专家仍然是 路由专家(Routed Expert),用于特定任务的处理。这里路由器选择 K=3 个专家,其中部分专家可以是共享专家。
整体意义:
通过 (2) 细粒度专家分割,使专家的选择更加多样,提高了模型的适应性。
通过 (3)共享专家隔离,使部分专家专注于通用任务,提升模型的泛化能力,同时减少专家之间的冗余。计算成本保持不变,但模型的效果更强。
2. MLA多头潜在注意力机制降低成本、提高效率
序列数据处理模型迭代:HMM,RNN、LSTM、Transformer(Attention)
Multi-Head Latent Attention(MLA)

MLA 通过低秩联合压缩技术,显著减少了推理时的键值缓存和训练时的激活内存,同时保持了与标准多头注意力机制相当的性能。MLA 的核心在于对键、值和查询矩阵进行低秩压缩,并通过旋转位置编码引入位置信息,从而在高效推理的同时捕捉输入序列中的复杂特征。
DeepSeel训练方法创新
1. 冷启动数据构建
2. 多阶段强化学习设计

LLM or Agent
有了大模型LLM,为什么还需要Agent?
LLM好比是人的大脑,Agent好比是一个完整的人,能凭借自身的交互执行、任务规划、环境适应、多模态感知及具身能力,弥补LLM的不足,将LLM的知识与能力转化为实际行动,更好地完成各种复杂任务,适应动态变化的环境。
大模型垂域优化的几大手段
1. 模型蒸馏:将大模型的能力迁移到小模型上,以适配更低端的算力环境。
2. 模型微调:使用特定数据集对通用模型进行小规模训练。
3. RAG:先查资料,再回答问题。
智能体开发
青铜:大模型+提示词
黄金:大模型+提示词+知识库+插件
王者:大模型+提示词+知识库+插件+工作流
第一期最后一句话,特别发人深省!

DeepSeek智能时代的全面到来和人机协作的新常态
智能演变
1. 大模型带来大知识

2. 顿悟时刻 Aha moment
在训练DeepSeek-R1-Zero中间版本时,模型展现出自我反思能力,能在推理过程中重新评估初始解题思路。
论文中有个典型例子,在求解数学方程时,模型生成的回答包含“Wait, wait. Wait. That’s an aha moment I can flag here.”和“Let’s reevaluate this step-by-step…”等语句。
这表明模型不仅在解题,还在有意识地监控自己的思维过程,识别潜在错误,决定回溯重新思考。这属于元推理——对思考的思考,有力证明了强化学习挖掘人工智能深层次智能的巨大潜力。
3. 思维链 Chain of Thoughts

4. Grok3 Vs DeepSeek

5. 推理模型与非推理模型

人机协作
1. 人机协作的三种模式

2. 人工智能时代

3. 图灵测试
1950年提出,人工智能领域最具争议与启发性的评估范式,持续75年的思想实验。见证了AI从规则系统到神经网络的范式迁移,见证了人类对自身智能本身的认知突破,见证了智能时代的到来。
图灵测试起源于计算机科学和密码学的先驱艾伦·麦席森·图灵发表于1950年的一篇论文《计算机器与智能》。该测试的流程是,一名测试者写下自己的问题,随后将问题以纯文本的形式(如计算机屏幕和键盘)发送给另一个房间中的一个人与一台机器。测试者根据他们的回答来判断哪一个是真人,哪一个是机器。所有参与测试的人或机器都会被分开。这个测试旨在探究机器能否模拟出与人类相似或无法区分的智能。
DeepSeek模型优势:算力、成本
算力(computing power)
1. 什么是算力
对信息数据进行计算,实现目标结果的能力。
2. 算力的分类
传统算力:信息计算力
现代算力:信息计算力、数据存储力、网络运载力
3. 算力的发展
原生算力:大脑(可处理复杂逻辑,但不能高速处理简单运算)
外部算力:草绳、石子 ---> 算盘 ---> 计算机
3. 计算机算力的发展
大型机时代(1940-1980):数字化未开始,算力需求潜力未发掘;
PC时代(1980-2000):一个应用只需要一台电脑,算力够;
云计算时代(2000-2020):应用需求超过一台机器的算力,算力基本够;
人工智能时代(2020-):算力开始不足,需大量高性能AI加速器。

4. 人工智能大模型算力估计
(1)数据量(D) > 15 × 模型参数量(N)
万亿模型(N)= 10000 × 10^8 = 10^12
数据量(D)> 15 × 10^12 = 1.5×10^13
(2)计算次数 C ≈ 6 × D × N
万亿模型计算次数 C = 6 × 10^12 × 1.5×10^13 = 9×10^25
(3)计算时间 T = C / 算力 秒
 单H800(25万): 万亿模型的训练时间 T = 9×10^25 / 10^15 = 9×10^10 秒 = 1041700 天
单H800(25万): 万亿模型的训练时间 T = 9×10^25 / 10^15 = 9×10^10 秒 = 1041700 天
10000张H800(25亿):9×10^6秒 = 105天(实际会更久,由于并行效率、通信开销、内存带宽限制等,实际算力≠理论算力)
5. 大模型指导法则Scaling Law:富则火力覆盖,穷则战术穿插

一般而言,算力越大、数据集越大、参数越多,Test Loss越小,模型效果越好。

核心技术
1. DeepSeekMoE

2. MLA

走向数字社会:从DeepSeek到群体智慧
从图灵机到大模型
图灵机:图灵机是由艾伦・图灵提出的一种抽象计算模型,由纸带、读写头、状态寄存器和控制规则构成,通过读写头与纸带的交互来模拟计算过程,为现代计算机理论和可计算性研究奠定了基础。
图灵测试:图灵测试是艾伦・图灵提出的一种判断机器是否具备人类智能的测试方法,通过让测试者与被测试者(机器和人类)进行自然语言对话,依据测试者能否正确分辨对方是机器还是人类,来判定机器是否表现出与人类无法区分的智能。
机器学习模型分为生成式和判别式两种,生成式模型通过建模数据的联合概率分布 P(X,Y)(监督学习)或 P(X)(无监督学习),学习数据的生成过程。判别式模型学习条件概率 P(Y∣X),关注输入 X 到输出 Y 的映射关系,用于分类或回归任务(如逻辑回归、支持向量机)。
人工智能的范围划分:
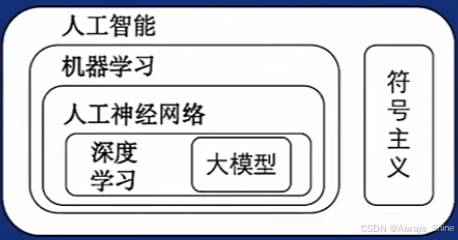
生成式大(语言)模型:大模型(1750亿参数)、大数据(45TB)、大算力(1万张A100)
DeepSeek的意义:
- 挑战大模型的“扩展定律”(Rich Sutton-The Bitter Lession):在2048块英伟达H800GPU上训练;
- 挑战闭源大模型由于开源大模型的现状,普及本地部署;
- 算法改进和工程优化:混合专家模型、多头潜在注意力、强化学习、蒸馏、思维链、计算优化。
分布式AI-群体智能
- 分布式建模,从大模型到群体小模型
- 多智能体
语言解码双生花:人类经验与AI算法的镜像之旅
1. 大模型训练流程

2. 以V3为基座模型得到其他模型
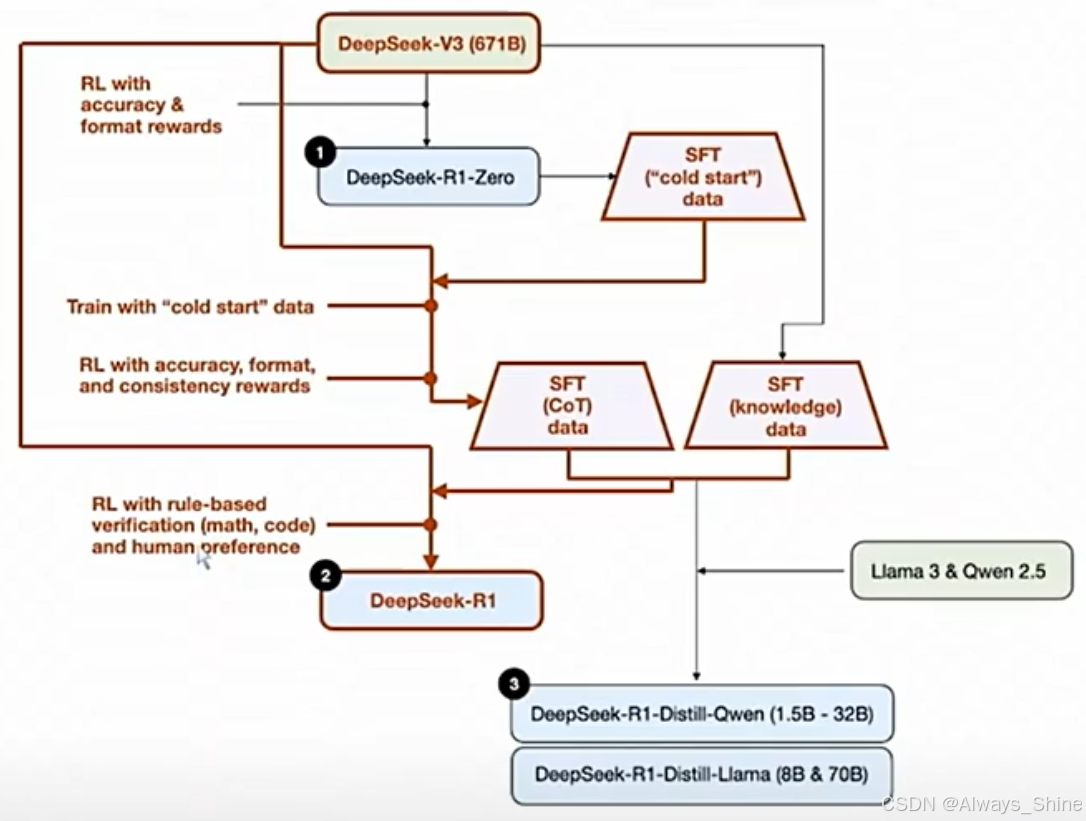
DeepSeek之火,可以燎原
DeepSeek本地部署
1. 技术架构
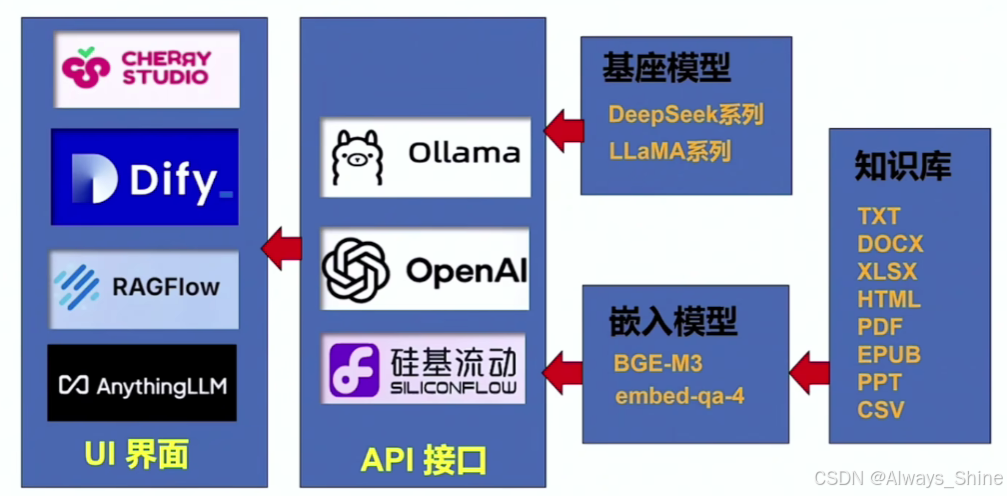
2. 实践
欢迎阅读我的上篇博客:DeepSeek的部署


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









