







目录
专栏文章
一、方法简介(背景综述)
先来看看什么是TOPSIS:
TOPSIS (Technique for Order Preference by Similarity to an Ideal Solution )模型中文叫做“逼近理想解排序方法”,通常也习惯被叫做优劣解距离法,是根据评价对象与理想化目标的接近程度进行排序的方法,是一种距离综合评价方法。基本思路是通过假定正、负理想解,测算各样本与正、负理想解的距离,得到其与理想方案的相对贴近度(即距离正理想解越近同时距离负理想解越远),进行各评价对象的优劣排序。
大家还记的上一篇文章中用到的方法吗?对,就是层次分析法!
在层次分析法的建模过程中,我们首先要建立评价体系,目标层,准则层,方案层,然后建立判断矩阵,求解一致性指标,然后再算权重,从而得出最终结果。但是在这个过程中也有诸多局限性:
- 在建立判断矩阵的时候,很多指标加进了不少主观性的判断,不能代表大部分人的想法。
- 评价的决策层不能太多,太多的话平均随机一致性指标RI表中的n会很大,判断矩阵和一致矩阵差异可能会很大。
- 当决策层的数据是已知的时候,就没法去主观填写判断矩阵了。
这时候,我们的TOPSIS 优劣解距离法就起到了作用,下面先看一道例题的分析,可以初步了解一下优劣解距离法和层次分析法的不同之处在哪里?
二、例题分析
1.题目简介
评价下表中20条河流的水质情况。
注:含氧量越高越好; PH值越接近7越好;细菌总数越少越好;植物性营养物量介于10‐20之间最佳,超过20或低于10均不好。
| 河流 | 含氧量(ppm) | PH值 | 细菌总数(个/mL) | 植物性营养物量(ppm) |
| 1 | 4.69 | 6.59 | 51 | 11.94 |
| 2 | 2.03 | 7.86 | 19 | 6.46 |
| 3 | 9.11 | 6.31 | 46 | 8.91 |
| 4 | 8.61 | 7.05 | 46 | 26.43 |
| 5 | 7.13 | 6.5 | 50 | 23.57 |
| 6 | 2.39 | 6.77 | 38 | 24.62 |
| 7 | 7.69 | 6.79 | 38 | 6.01 |
| 8 | 9.3 | 6.81 | 27 | 31.57 |
| 9 | 5.45 | 7.62 | 5 | 18.46 |
| 10 | 6.19 | 7.27 | 17 | 7.51 |
| 11 | 7.93 | 7.53 | 9 | 6.52 |
| 12 | 4.4 | 7.28 | 17 | 25.3 |
| 13 | 7.46 | 8.24 | 23 | 14.42 |
| 14 | 2.01 | 5.55 | 47 | 26.31 |
| 15 | 2.04 | 6.4 | 23 | 17.91 |
| 16 | 7.73 | 6.14 | 52 | 15.72 |
| 17 | 6.35 | 7.58 | 25 | 29.46 |
| 18 | 8.29 | 8.41 | 39 | 12.02 |
| 19 | 3.54 | 7.27 | 54 | 3.16 |
| 20 | 7.44 | 6.26 | 8 | 28.41 |
2.题目分析
据题目要求,经分析可得,河流的水质为评价目标,有四个指标,含氧量(极大型指标)——越多越好,PH值(中间型指标)——越接近7越好,细菌总数(极小型指标)——越少越好,植物性营养物量(区间型指标)——在区间最好。
(1)原始矩阵
| 4.69 | 6.59 | 51 | 11.94 |
| 2.03 | 7.86 | 19 | 6.46 |
| 9.11 | 6.31 | 46 | 8.91 |
| 8.61 | 7.05 | 46 | 26.43 |
| 7.13 | 6.5 | 50 | 23.57 |
| 2.39 | 6.77 | 38 | 24.62 |
| 7.69 | 6.79 | 38 | 6.01 |
| 9.3 | 6.81 | 27 | 31.57 |
| 5.45 | 7.62 | 5 | 18.46 |
| 6.19 | 7.27 | 17 | 7.51 |
| 7.93 | 7.53 | 9 | 6.52 |
| 4.4 | 7.28 | 17 | 25.3 |
| 7.46 | 8.24 | 23 | 14.42 |
| 2.01 | 5.55 | 47 | 26.31 |
| 2.04 | 6.4 | 23 | 17.91 |
| 7.73 | 6.14 | 52 | 15.72 |
| 6.35 | 7.58 | 25 | 29.46 |
| 8.29 | 8.41 | 39 | 12.02 |
| 3.54 | 7.27 | 54 | 3.16 |
| 7.44 | 6.26 | 8 | 28.41 |
分析可得2,3,4列需要进行正向化处理
(2)正向化矩阵
| 4.69 | 0.717241 | 3 | 1 |
| 2.03 | 0.406897 | 35 | 0.694036 |
| 9.11 | 0.524138 | 8 | 0.905791 |
| 8.61 | 0.965517 | 8 | 0.444252 |
| 7.13 | 0.655172 | 4 | 0.691443 |
| 2.39 | 0.841379 | 16 | 0.600691 |
| 7.69 | 0.855172 | 16 | 0.655143 |
| 9.3 | 0.868966 | 27 | 0 |
| 5.45 | 0.572414 | 49 | 1 |
| 6.19 | 0.813793 | 37 | 0.784788 |
| 7.93 | 0.634483 | 45 | 0.699222 |
| 4.4 | 0.806897 | 37 | 0.541919 |
| 7.46 | 0.144828 | 31 | 1 |
| 2.01 | 0 | 7 | 0.454624 |
| 2.04 | 0.586207 | 31 | 1 |
| 7.73 | 0.406897 | 2 | 1 |
| 6.35 | 0.6 | 29 | 0.182368 |
| 8.29 | 0.027586 | 15 | 1 |
| 3.54 | 0.813793 | 0 | 0.408816 |
| 7.44 | 0.489655 | 46 | 0.27312 |
正向化处理后的矩阵如上
(3)标准化矩阵
| 0.162186 | 0.248255 | 0.024544 | 0.306458 |
| 0.0702 | 0.140837 | 0.286347 | 0.212693 |
| 0.315035 | 0.181417 | 0.065451 | 0.277586 |
| 0.297744 | 0.33419 | 0.065451 | 0.136145 |
| 0.246564 | 0.226772 | 0.032725 | 0.211898 |
| 0.082649 | 0.291223 | 0.130902 | 0.184086 |
| 0.26593 | 0.295997 | 0.130902 | 0.200773 |
| 0.321605 | 0.300771 | 0.220896 | 0 |
| 0.188468 | 0.198127 | 0.400886 | 0.306458 |
| 0.214058 | 0.281674 | 0.30271 | 0.240504 |
| 0.274229 | 0.21961 | 0.368161 | 0.214282 |
| 0.152157 | 0.279287 | 0.30271 | 0.166075 |
| 0.257976 | 0.050128 | 0.253622 | 0.306458 |
| 0.069508 | 0 | 0.057269 | 0.139323 |
| 0.070546 | 0.202901 | 0.253622 | 0.306458 |
| 0.267313 | 0.140837 | 0.016363 | 0.306458 |
| 0.219591 | 0.207675 | 0.237259 | 0.055888 |
| 0.286678 | 0.009548 | 0.12272 | 0.306458 |
| 0.122418 | 0.281674 | 0 | 0.125285 |
| 0.257284 | 0.169482 | 0.376342 | 0.0837 |
标准化处理的矩阵如上
(4)归一化并计算得分
| 排名 | 序号 | 得分 |
| 1 | 11 | 0.070162 |
| 2 | 10 | 0.068393 |
| 3 | 9 | 0.068074 |
| 4 | 12 | 0.059093 |
| 5 | 20 | 0.056466 |
| 6 | 7 | 0.053947 |
| 7 | 15 | 0.053307 |
| 8 | 13 | 0.052652 |
| 9 | 8 | 0.050998 |
| 10 | 4 | 0.04882 |
| 11 | 3 | 0.048497 |
| 12 | 2 | 0.047799 |
| 13 | 17 | 0.046574 |
| 14 | 1 | 0.045058 |
| 15 | 6 | 0.044838 |
| 16 | 18 | 0.043844 |
| 17 | 16 | 0.043359 |
| 18 | 5 | 0.043113 |
| 19 | 19 | 0.03581 |
| 20 | 14 | 0.019196 |
三、模型方法总结
1.使用条件
和层次分析法比较类似,但是题目中不同的评价指标已经给了具体的数据,这时候就不需要我们去主观建立判断矩阵来进行求解了,而是去将数据进行进一步的处理来给出评价体系。
2.基本过程
- 将原始数据矩阵统一指标类型(一般正向化处理)得到正向化的矩阵。
- 对正向化的矩阵进行标准化处理以消除各指标量纲的影响,并找到有限方案中的最优方案和最劣方案。
- 分别计算各评价对象与最优方案和最劣方案间的距离,获得各评价对象与最优方案的相对接近程度,以此作为评价优劣的依据。
3.具体分析
(1)原始矩阵正向化
| 指标名称 | 指标特点 | 例子 |
| 极大型(效益性)指标 | 越大(多)越好 | 成绩,GDP增速,企业利润 |
| 极小型(成本性)指标 | 越小(少)越好 | 费用,坏品率,污染程度 |
| 中间型指标 | 越接近某个值越好 | 水质量评估时的PH值 |
| 区间型指标 | 落在某个区间最好 | 体温,水中植物性的营养物量 |
所谓的将原始矩阵正向化,就是要将所有的指标类型统一转化为极大型指标。(转换公式不唯一)
- 极小型
极大型:
,
- 中间型
是一组中间型指标序列,且最佳的数值为
,则正向化的公式为:
- 区间型
,则正向化的公式为:
(2)正向化矩阵标准化
标准化的目的是消除不同指标量纲的影响。

(3)计算得分并归一化
归一化并不会影响排序的最终结果,且此时计算时默认权重是相同的。

(4)利用熵权法对有权重的TOPSIS模型的修正
当这些评价指标占有权重时,我们就需要对模型进行修正了,我们在层次分析法中已经讲过了如何去填写权重,但是其主观性太强,因此这里讲一个新的方法——熵权法。
<1>熵权法的原理:
指标的变异程度越小(方差越小),所反映的信息量也越少,其对应的权值也应该越低。(客观= 数据本身就可以告诉我们权重)
举一个例子大家可能更好理解什么是信息量的多少:
小张和小王是两个高中生。小张学习很差,而小王是全校前几名的尖子生。高考结束后,小张和小王都考上了清华。小王考上了清华,大家都会觉得很正常,里面没什么信息量,因为学习好上清华,天经地义,本来就应该如此的事情。然鹅,如果是小张考上了清华,这就不一样了,这里面包含的信息量就非常大。怎么说?因为小张学习那么差,怎么会考上清华呢?把不可能的事情变成可能,这里面就有很多信息量。
注:本例子来自微信公众号:“小宇治水”
<2>如何度量信息量的大小:
如果把信息量用字母I表示,概率用p表示,那么我们可以将它们建立一个函数关系:
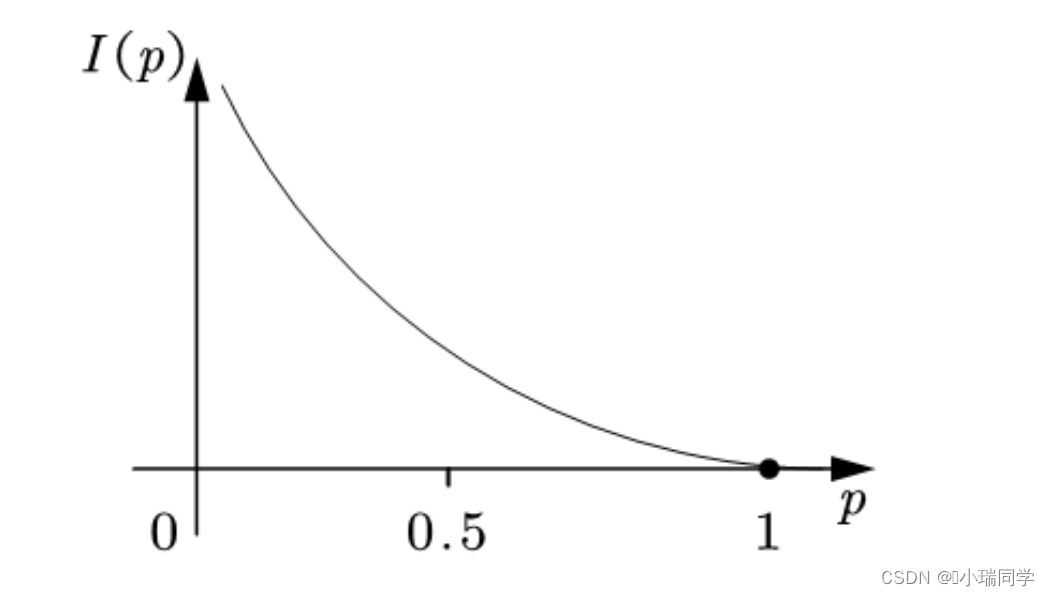

<3>信息熵的定义:

大家在高中化学《化学反应原理》中学过熵的定义,简而言之就是不确定性,信息熵越高,不确定性越高,所包含的信息量越大,但是能给你提供的由有效信息就越少, 所以信息熵越大,信息量就越小。
<4>熵权法的计算步骤:
- 判断输入的矩阵中是否存在负数,如果有则要重新标准化到非负区间(后面计算概率时需要保证每一个元素为非负数)

- 计算第 j 项指标下第 i 个样本所占的比重,并将其看作相对熵计算中用到的概率
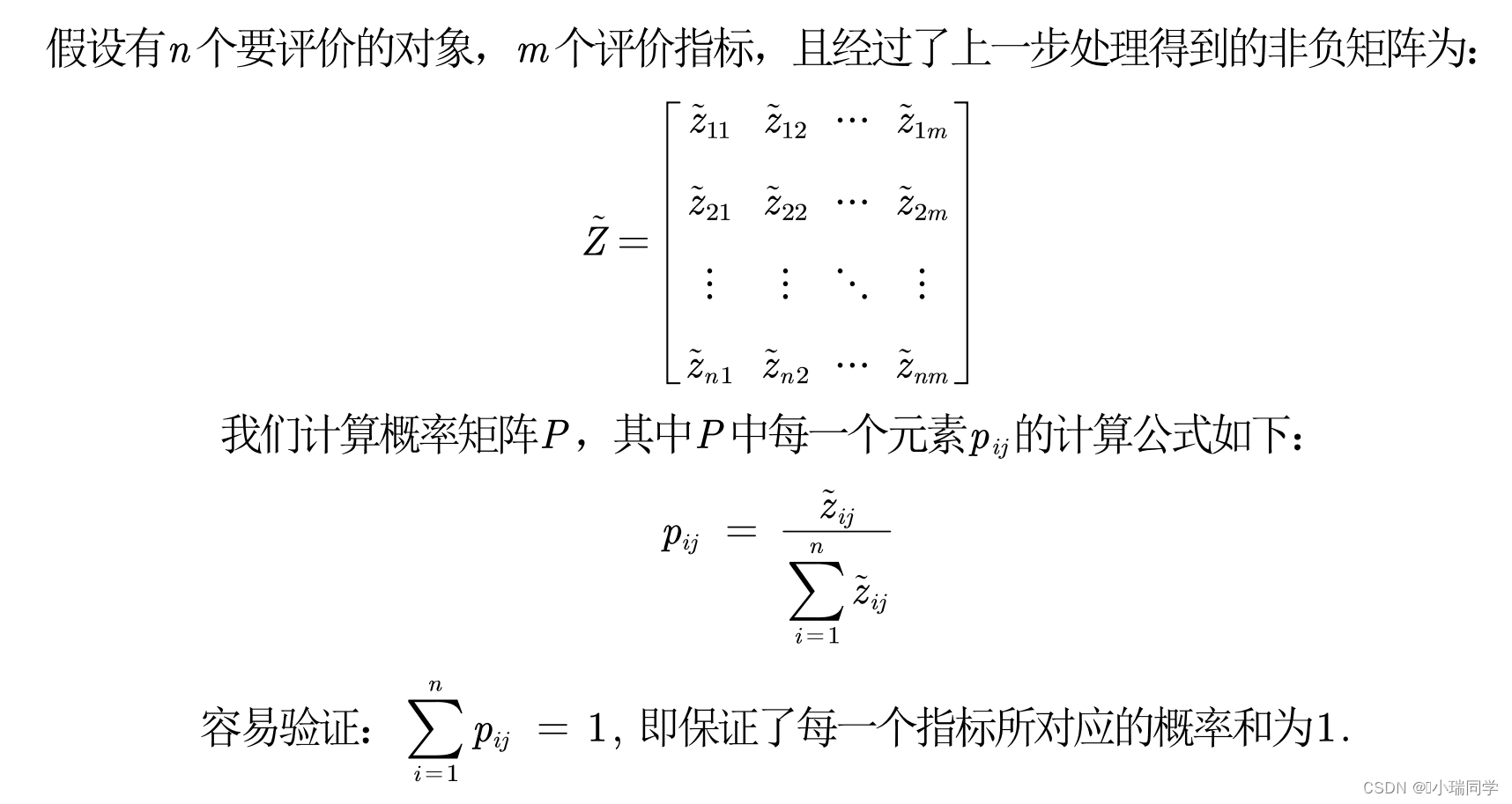
- 计算每个指标的信息熵,并计算信息效用值,并归一化得到每个指标的熵权




















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











