







前言
本文是关于文件内容操作的习题整理和讲解
1
按照数据的组织形式,可以把文件分为文本文件和二进制文件两大类
-
文本文件:(人读的)
- 文本文件是由字符组成的,它们使用特定的字符编码(如ASCII、UTF-8等)来表示文本数据。
- 文本文件是可读的,可以用任何文本编辑器打开和编辑,如记事本、Vim、Emacs等。
- 它们通常用于存储源代码、文档、配置文件等,这些数据需要以人类可读的格式存在。
-
二进制文件:(机读的)
- 二进制文件由二进制数据组成,即由0和1的序列构成,这些数据是计算机可以直接识别和处理的。
- 二进制文件不是为人类阅读而设计的,它们通常包含复杂的数据结构,如图像、音频、视频文件、可执行程序等。
- 打开和编辑二进制文件需要专门的软件,因为它们需要能够解析文件中的二进制数据结构。
| 文件类型 | 定义 | 常见用途 | 例子 | 文件扩展名 |
|---|---|---|---|---|
| 文本文件 | 由字符组成的文件,使用字符编码如ASCII或UTF-8。 | 存储人类可读的文本信息,如文档、源代码、配置信息等。 | 源代码、网页、文档、配置文件 | .txt, .py, .js, .html, .xml, .csv |
| 二进制文件 | 由二进制数据组成的文件,包含0和1的序列,计算机可以直接处理。 | 存储计算机程序、图像、音频、视频等非文本数据。 | 可执行程序、图片、音频、视频、数据库 | .exe, .jpg, .mp3, .avi, .png, .db |
解释:
-
文本文件:通常包含可打印的字符,可以通过任何文本编辑器打开。例如,Python源代码文件是文本文件,因为它包含Python语言编写的源代码,可以用文本编辑器打开和编辑,其文件扩展名通常是
.py。 -
二进制文件:包含计算机程序或非文本数据,需要相应的软件来正确打开和使用。例如,视频文件(如扩展名为
.mp4的文件)和音频文件(如扩展名为.mp3的文件)都是二进制文件,因为它们包含的数据是专门为视频播放器和音频播放器设计的二进制格式。
值得注意的是: .csv 文件:逗号分隔值文件,虽然它们看起来像文本文件,但实际上可以是文本也可以是二进制,取决于它们的编码方式和内容。如果.csv文件只包含纯文本数据,如数字和文本,没有任何特殊编码,则可以用文本编辑器打开。但如果它包含特殊字符或二进制数据,则可能需要专门的软件来正确读取。(但一般来说属于文本文件)
2. open()
概述:
Python中,open 是一个内置函数,用来打开或创建文件,并返回一个文件对象。这个文件对象提供了一系列的方法来对文件进行操作,如读取、写入、追加等。
open 函数的基本用法:
open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True)
参数说明:
file:文件路径,可以是字符串或者字节,表示要打开的文件。mode:文件打开模式,可以是以下值之一:'r':读取模式,默认值。文件指针放在文件的开始位置。'w':写入模式。如果文件存在,文件指针放在文件的开始位置,并清空文件内容。如果文件不存在,创建新文件。'a':追加模式。如果文件存在,文件指针放在文件的末尾。如果文件不存在,创建新文件。'b':二进制模式。用于二进制文件的读写。- 其他常用模式组合:
'rb'(二进制读取),'wb'(二进制写入),'ab'(二进制追加)。
buffering:缓冲区大小。默认是-1,意味着使用默认的缓冲方式。encoding:文件编码。如果未指定,使用系统默认编码。errors:错误处理方案,如'ignore','replace'等。newline:控制何时写入换行符。closefd:用于在文件操作完成后是否关闭文件描述符。默认是True。
使用 open 函数时,通常配合 with 语句,这样可以确保文件在使用后会被正确关闭,即使发生异常也是如此。
举例:
with open('example.txt', 'r') as file:
contents = file.read()
# 处理文件内容
在上述示例中,'example.txt' 是要打开的文件名,'r' 表示以读取模式打开。使用 with 语句,文件在 with 块执行完毕后会自动关闭。如果不使用 with 语句,需要手动调用文件对象的 close() 方法来关闭文件。
file = open('example.txt', 'r')
contents = file.read()
# 处理文件内容
file.close() # 手动关闭文件
使用文件对象时,可以根据需要使用不同的方法,如 read(), readline(), write(), writelines() 等,来进行文件的读取和写入操作。
3.文件打开模式 - mode
Python中open函数支持的文件打开模式的整理表格:
| 模式 | 描述 | 文件指针位置 | 读写操作 |
|---|---|---|---|
r | 读取模式 | 文件开头 | 读取数据 |
w | 写入模式 | 文件开头 | 写入数据,文件内容会被清空 |
a | 追加模式 | 文件末尾 | 写入数据,内容追加到文件末尾 |
b | 二进制模式 | 文件开头 | 用于二进制文件的读写 |
t | 文本模式(默认) | 文件开头 | 用于文本文件的读写 |
r+ | 读写模式 | 文件开头 | 读取和写入数据 |
w+ | 读写模式,写入时会先清空文件 | 文件开头 | 读取和写入数据 |
a+ | 读写模式,写入时会追加到文件末尾 | 文件末尾 | 读取和写入数据 |
'U' | 通用模式(Unix专用,不推荐使用) | 根据文件内容决定 | 读取和写入数据 |
注意事项:
- 在使用
'U'模式时,Python 2.x版本中用于读取二进制文件,但这个模式在Python 3.x中已经不推荐使用,并且其行为与文本模式相同。 - 模式可以组合使用,例如:
'rb'表示以二进制读取模式打开文件,'w+b'表示以二进制读写模式打开文件,并且会清空文件内容。 - 默认情况下,
open函数打开的是文本文件,如果需要处理二进制数据,需要使用二进制模式(即在模式字符串中包含'b')。 - 使用
'r+'、'w+'或'a+'模式时,文件指针的位置取决于具体的实现,可能需要手动移动文件指针到所需的位置。
特别注意:
| 模式 | 描述 | 文件指针位置 | 打开时对文件内容的影响 | 读取操作 | 写入操作 |
|---|---|---|---|---|---|
r+ | 读写模式,文件既可用于读取也可用于写入 | 文件开头 | 无影响 | 正常 | 覆盖当前位置数据 |
w+ | 读写模式,写入前会先清空文件 | 文件开头 | 清空 | 正常 | 写入新数据 |
a+ | 读写模式,写入时会追加到文件末尾 | 文件末尾 | 无影响 | 正常 | 追加到文件末尾 |
说明:
-
在
r+模式下,打开文件时不会对文件内容产生任何影响,文件指针位于文件开头,可以读取也可以写入。写入时会覆盖文件指针当前位置的数据。 -
在
w+模式下,打开文件时会先清空文件中的所有内容,然后创建一个空的文件对象。这意味着,无论文件原先包含什么内容,一旦以w+模式打开,这些内容都会被删除。文件指针位于文件开头,可以读取(但此时文件为空),也可以写入新数据。 -
在
a+模式下,打开文件时也不会对文件内容产生影响,文件指针位于文件末尾,准备追加数据。可以读取整个文件的内容,写入时会将数据追加到文件末尾,而不会覆盖现有内容。
有趣的是:
从表面上看,w+ 模式似乎在写入前清空了文件内容,使得随后的读取操作只能读取到一个空文件,让人感觉读取功能没有太大用处。然而,w+ 模式的读取能力实际上在某些情况下是有用的,尤其是在需要先读取文件内容,然后在此基础上进行修改和更新的场景中。
一些可能会用到 w+ 模式读取功能的情况:
-
读取后修改:可能需要先读取文件中的现有内容,对其进行某些处理,然后再写回文件。在这种情况下,
w+模式允许读取和写入同一个文件,而不需要先读取到一个临时文件或内存中。 -
比较差异:在写入新内容之前,可能需要比较新内容和旧内容之间的差异。
w+模式可以让读取旧内容,进行比较,然后决定如何更新文件。 -
初始化文件:如果文件不存在,
w+模式会创建一个新文件。在这种情况下,可以先检查文件是否存在,如果不存在,先写入一些初始化内容。 -
数据校验:在写入新数据之前,可能需要读取文件,进行数据校验或验证,以确保写入的数据是正确的。
-
追加操作:在某些情况下,可能需要读取文件内容,然后决定是覆盖文件还是追加到现有内容之后。
w+模式提供了灵活性,让可以先读取,再决定如何写入。 -
交互式更新:在一些交互式应用中,可能需要先显示当前文件内容,然后让用户选择是否进行更新或修改。
总结:
-
单一模式:这些模式允许对文件进行特定的操作,通常是只读或只写操作。
r:读取模式,用于读取文件。w:写入模式,用于写入文件,会清空文件原有内容。a:追加模式,用于写入文件,会在文件末尾追加内容。b:二进制模式,用于二进制文件的读写。
-
复合模式:这些模式结合了读取和写入操作,允许对文件同时进行读取和写入。
r+:读写模式,可以读取和写入文件,写入时会覆盖当前位置的数据。w+:读写模式,写入前会先清空文件,然后可以读取和写入。a+:读写模式,写入时会追加到文件末尾,可以读取整个文件。
引入复合模式的原因包括:
- 灵活性:在某些情况下,可能需要在不关闭文件的情况下,对文件进行读取和写入操作。复合模式提供了这种灵活性。
- 效率:使用复合模式可以在同一个文件描述符上进行读写操作,避免了多次打开和关闭文件的开销。
- 操作的连续性:在处理文件时,有时需要先读取文件内容,基于这些内容进行一些处理,然后再写回文件。复合模式允许这种连续的操作流程。
r+、w+ 和 a+ 模式:
r+模式允许在文件中任意位置读取和写入,写入时会覆盖文件指针当前位置的数据。w+模式在打开文件时会清空文件内容,然后可以在空文件中任意位置进行读取和写入。a+模式允许在文件末尾追加内容,同时也能读取整个文件的内容。
单一模式和复合模式的引入,是为了提供不同的读写组合,以满足不同的文件操作需求。
4 打开文本文件时所使用的编码格式 - encoding
在Python中,使用open函数打开文件时,可以通过encoding参数指定文件的编码格式。
| 编码格式 | 描述 |
|---|---|
ascii | 仅用于英文文本,只包含128个字符,7位编码,不包含扩展的ASCII |
utf-8 | 一种变长的Unicode转换格式,常用于网页编码 |
utf-16 | 一种16位的Unicode转换格式,使用两个字节表示大多数常用字符 |
utf-32 | 一种32位的Unicode转换格式,每个Unicode字符占用四个字节 |
latin-1 | 用于西欧语言的8位编码,等同于ISO-8859-1 |
iso-8859-1 | 西欧语言的8位编码 |
iso-8859-2 | 中欧语言的8位编码 |
iso-8859-5 | 斯拉夫语言的8位编码 |
iso-8859-7 | 希腊语的8位编码 |
iso-8859-9 | 土耳其语的8位编码 |
iso-8859-15 | 西欧语言的8位编码,包含欧元符号 |
cp850 | DOS 多语言8位编码 |
cp1252 | Windows 多语言8位编码 |
gbk | 简体中文的8位编码 |
big5 | 繁体中文的8位编码 |
shift-jis | 日语的8位编码 |
euc-jp | 用于日语的扩展Unix编码 |
euc-kr | 用于韩语的扩展Unix编码 |
koi8-r | 斯拉夫语言的8位编码 |
koi8-u | 乌克兰语的8位编码 |
5 with 语句
概述:
在Python中,with 语句可以用来包裹执行文件操作的代码块,确保文件在使用后会被正确关闭,即使在代码块中发生异常也是如此。这种结构称为上下文管理器。
使用 with 关键字的好处包括:
- 自动关闭文件:无论在代码块中发生了什么,文件都会在代码块执行完毕后自动关闭。
- 异常安全:如果在处理文件时发生异常,
with语句会确保文件被关闭,并且可以正确处理异常。 - 简洁性:它使得文件操作的代码更加简洁易读。
例子:
with 语句通常与 open 函数一起使用,如下所示:
with open('filename.txt', 'r') as file:
content = file.read()
# 对文件内容进行处理
# 文件在这个块之外的任何地方都会被自动关闭
在这个例子中,不管 file.read() 和后续操作是否成功执行,文件都会在离开 with 代码块时自动关闭。
此外,with 语句也可以与任何实现了上下文管理协议(即具有 __enter__ 和 __exit__ 方法)的对象一起使用,这使得它非常灵活,不仅限于文件操作。
Python 的文件写入操作可能会被暂存在缓冲区中,而不是直接写入硬盘。在正常情况下,当文件对象被关闭时,Python 会执行一个 flush 操作,确保所有未写的数据都被写入硬盘。但是,如果系统发生崩溃或其他意外情况,可能会有数据丢失的风险。为了进一步确保数据的安全性,有时还需要使用其他机制,如文件系统的同步操作(例如,在Unix系统上使用fsync())。
9.6
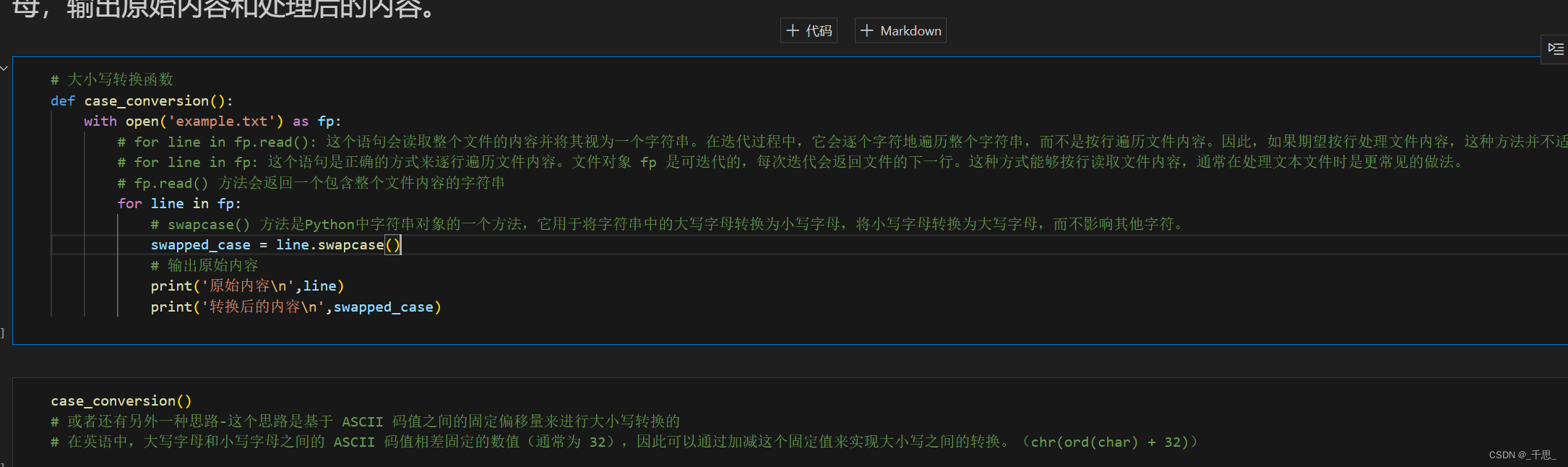
对于文本文件,使用 Python 内置函数 open() 以读文本模式(例如,使用 ‘r’ 或 ‘rt’ 模式)成功打开后返回的文件对象可以使用 for 循环直接迭代。
对文件对象使用 for 循环进行迭代时,Python 会逐行读取文件内容。每次迭代返回的是文件中的每一行,作为字符串形式,包括行尾的换行符(\n)。
下面是一个使用 for 循环迭代文件对象的例子:
# 打开文件,假设文件名为 'example.txt'
with open('example.txt', 'r') as file:
for line in file:
# 处理每一行
print(line, end='') # 打印每一行,end='' 防止print函数添加额外的换行符
在这个例子中,for 循环会自动读取文件的每一行,直到文件结束。print(line, end='') 用于打印读取的每一行,其中 end='' 参数用于防止 print 函数在每行末尾添加额外的换行符,因为从文件中读取的每一行已经包含了换行符。
通常情况下,只有以只读文本模式(如 ‘r’ 或 ‘rt’)打开的文件对象可以直接使用 for 循环进行迭代。这是因为在只读文本模式下,文件对象允许按行读取,而 for 循环可以逐行迭代这些内容。
附加:文件对象
在Python中,文件对象是open函数返回的一个类型为io.TextIOBase(对于文本文件)或io.BufferedIOBase(对于二进制文件)的对象。当以文本模式(如使用'r'、'rt'、'r+'等模式)打开一个文件,并使用for循环迭代这个文件对象时,Python会默认按照行来迭代。
这里的“行”是基于换行符来划分的,通常在Unix/Linux系统中是\n,在Windows系统中可能是\r\n。每次迭代返回的是文件中的一行内容,作为字符串形式,包括行尾的换行符。
下面是一个使用for循环迭代文件对象的例子:
with open('example.txt', 'r') as file:
for line in file: # 迭代文件对象,每次迭代返回文件的一行
print(line.strip()) # 打印处理后的行内容,去除行尾的换行符
-
with open('example.txt', 'r') as file:以只读文本模式打开名为example.txt的文件,并返回一个文件对象,赋值给变量file。 -
for line in file:这一行告诉Python,对文件对象file进行迭代。每次迭代,line变量会被赋予文件的下一行内容。 -
print(line.strip())打印出每一行的内容,strip()方法用于移除字符串两端的空白字符,这通常包括行尾的换行符\n。
7
将 readme.txt 文件中的所有内容复制到 dst.txt 中:
with open('readme.txt', 'r') as src, open('dst.txt', 'w') as dst:
dst.write(src.read())
解释
-
with open('readme.txt', 'r') as src:以只读模式打开readme.txt文件,并创建一个名为src的文件对象来引用它。 -
, open('dst.txt', 'w') as dst:在同一个with语句中,以写入模式打开一个新文件dst.txt,并创建一个名为dst的文件对象。 -
dst.write(src.read()):读取src文件对象的所有内容到内存中(这将读取整个文件内容),并将它们写入到dst文件对象。
这种方法适用于复制小型文件。如果文件非常大,一次性读取整个文件内容可能会导致内存不足。在处理大文件时,可以使用循环来逐行读取和写入,如下所示:
with open('readme.txt', 'r') as src, open('dst.txt', 'w') as dst:
for line in src:
dst.write(line)
在这个例子中,代码会逐行读取 readme.txt 文件,并将每一行写入 dst.txt 文件。这种方法更节省内存,适合处理大文件。
9.8
openpyxl 是一个 Python 库,用于读写 Excel 2010 xlsx/xlsm/xltx/xltm 文件。它允许用户对 Excel 文件进行各种操作,包括但不限于读取数据、写入数据、修改单元格样式、创建图表等。
xlwings 是另一个流行的库,它提供了一个更高层的API来处理 Excel 文件。它允许用户调用 Excel 应用程序本身,执行宏,以及与 Excel UI进行交互,而不仅仅是读写文件。
两个库的一些特点:
openpyxl
- 支持 Excel 2010 xlsx/xlsm/xltx/xltm 文件。
- 允许用户对工作簿(Workbooks)和工作表(Worksheets)进行操作。
- 可以读取和写入单元格数据,包括格式化和公式。
- 支持创建图表、图片、数据透视表等。
- 是一个相对底层的库,不依赖于 Excel 应用程序。
xlwings
- 支持与 Excel 交互,包括宏的运行和UI操作。
- 可以读取和写入单元格数据,并且能够使用 Excel 的公式和函数。
- 允许用户操作 Excel 应用程序,如激活特定的工作表、运行宏等。
- 依赖于 Excel 应用程序,因此使用 xlwings 需要在有 Excel 安装的计算机上运行。
9.9
使用Python读写 word 2007文件
python-docx
- 官方网站: https://python-docx.readthedocs.io/en/latest/
- 功能: 允许用户创建新的Word文档,向文档中添加文本、图片、表格等,以及修改现有文档的内容。
- 特点: 不依赖于Microsoft Word应用程序,可以作为一个独立的库使用。
docx2python
- 功能: 主要用于读取
.docx文件,将文档内容转换为Python可以处理的数据结构。 - 特点: 允许用户访问和解析Word文档的结构,但写入功能可能不如
python-docx库那么强大。
安装方法
通过pip安装这些库:
pip install python-docx
pip install docx2python
使用示例
以下是使用python-docx创建和写入Word文档的一个简单示例:
from docx import Document
# 创建一个新的Word文档
doc = Document()
# 添加一个标题
doc.add_heading('Python Docx Example', 0)
# 添加一个段落
p = doc.add_paragraph('Hello, docx!')
# 添加一个表格
table = doc.add_table(rows=1, cols=2)
hdr_cell = table.rows[0].cells[0]
hdr_cell.text = 'Header 1'
hdr_cell = table.rows[0].cells[1]
hdr_cell.text = 'Header 2'
# 保存文档
doc.save('example.docx')
使用docx2python读取Word文档的示例:
from docx2python import Docx2Python
# 打开一个Word文档
doc = Docx2Python('example.docx')
# 打印文档内容
print(doc.paragraphs())
10
.判断对错:使用内置函数open()以二进制模块打开文件时,也可以使用参数 encoding 指定编码格式。
判断:错误
原因:在使用内置函数 open() 以二进制模式打开文件时,encoding 参数是不必要的,因为二进制模式处理的是原始字节数据,而不是字符串。encoding 参数只在文本模式下使用,用于指定字符串与字节之间的编码转换。在二进制模式下,处理的是字节,而不是字符和字符串,因此不需要指定编码。
9.11
判断对错:使用内置函数 open()的’r’模式打开包含多行内容的文本文件并返回文件对象 fp,那么表达式 fp.readline()[-1]的值一定为’\n’。
判断:正确
另外:这道题不是很严谨,当使用 open() 函数的 'r' 模式打开一个文本文件并返回文件对象 fp 后,fp.readline() 读取文件的第一行内容,包括行尾的换行符 \n(除非该行内容到达了文件末尾)。然而,fp.readline()[-1] 尝试获取读取到的行内容的最后一个字符,这在行内容的最后一个字符恰好是换行符 \n 时才为真。如果第一行内容不以换行符结束(例如,文件的最后一行或者读取的内容恰好没有包含完整的最后一行),那么 fp.readline()[-1] 的值就不会是 \n。
9.12
判断对错:使用内置函数 open()的’r’ 模式打开包含多行内容的文本文件并返回文件对象 fp,那么表达式 fp.readlines()[0][-1]的值为’\n’。
判断:正确
另外:这道题不是很严谨,
fp.readlines() 会读取文件中的所有行,并将它们作为一个字符串列表返回,其中每个字符串代表文件中的一行。然而,这个方法默认会保留行尾的换行符 \n,这意味着每一行的末尾都可能含有一个换行符。(所以后面还要处理掉)
表达式 fp.readlines()[0][-1] 试图获取通过 fp.readlines() 返回的第一行(索引为 0)的最后一个字符(索引为 -1)。如果该行文本确实以换行符结束,那么这个表达式将返回 \n。但是,如果第一行文本的末尾没有换行符,或者在读取时由于某些原因(如文件损坏、非标准行尾序列等)丢失了换行符,那么这个表达式的值就不会是 \n。
此外,如果文件中的第一行不包含任何字符,或者读取到的第一行实际上是空字符串(例如,文件的第一行只有一个换行符),那么 fp.readlines()[0] 将是一个空字符串,尝试访问 [-1] 将会引发一个 IndexError。
因此,不能保证 fp.readlines()[0][-1] 的值一定为 '\n',这取决于文件内容和读取时的行为。如果需要确保去除行尾的换行符,可以使用 rstrip() 方法,例如 fp.readlines()[0].rstrip('\n')。
9.13
判断对错:使用内置函数 open()打开文本文件时,参数 encoding 不重要直接使用默认值就可以。
判断:错误
原因:参数 encoding 在使用内置函数 open() 打开文本文件时非常重要,它指定了文件的字符编码格式。不同的文本文件可能使用不同的编码格式,如 ASCII、UTF-8、ISO-8859-1 等。如果文件的实际编码与指定的 encoding 参数不一致,可能会导致字符读取错误,出现乱码或者 UnicodeDecodeError 异常。
直接使用默认值可能在某些情况下没有问题,特别是当文件使用默认编码(通常是 UTF-8)时。但是,如果文件使用不同的编码格式,那么必须指定正确的 encoding 参数以避免解码错误。
例如,如果一个文件是用 ISO-8859-1 编码的,使用 UTF-8 作为默认值打开文件,那么读取的文本可能会包含错误或无法识别的字符。
如果不确定文件的编码格式,可能需要检查文件的来源或使用工具检测其编码。
9.14
判对错:假设当前文件夹中包含非空文件test.dat,那么先后执行语fp= open(‘test.dat’,‘rb’)、print(fp.read(5))、fp.seek(0)print(fp.read(5)),连续两次输出的内容是一样的。
判断:正确
-
fp = open('test.dat', 'rb'):
这行代码使用open函数以二进制读取模式(‘rb’)打开一个名为test.dat的文件。如果文件成功打开,函数返回一个文件对象,然后该对象被赋值给变量fp。二进制模式意味着文件被当作字节序列处理,而不是文本。 -
print(fp.read(5)):(在Python中,使用文件对象的 read(size) 方法时,参数 size 指定了要读取的字节数)
这行代码调用文件对象fp的read方法,并传入参数5,它尝试从文件中读取5个字节的数据。read方法返回一个包含读取字节的字节串。然后,print函数将这个字节串输出到控制台。 -
fp.seek(0):
seek方法用于重新定位文件指针,参数0表示将指针移动到文件的开始位置。在执行此操作之前,文件指针位于read(5)方法停止的位置(即文件开头的第5个字节之后)。调用fp.seek(0)后,文件指针被重置到文件的最开始。 -
print(fp.read(5))(再次执行):
由于文件指针已经被fp.seek(0)重置到了文件的开始位置,再次调用fp.read(5)会重新读取文件开头的5个字节。如果文件中至少有5个字节,并且从文件开始到当前位置没有发生变化,那么这次读取的内容将与第一次调用read(5)时相同。
综上所述,如果test.dat文件中至少有5个字节,并且文件内容在两次读取之间没有被修改,那么两次执行print(fp.read(5))输出的内容将是相同的。
9.15
判断对错:使用内置函数 open()且以’w’模式打开的文件,文件指针默认指向文件尾。
判断:错误
原因:使用内置函数 open() 并以 'w'(写入模式)打开文件时,文件指针默认指向文件的开始位置,而不是文件尾。在写入模式下,文件系统准备好接收新数据,如果文件已经存在,它会被清空,即原有内容会被删除,文件指针位于空文件的开始位置。如果文件不存在,将会创建一个新文件,文件指针同样位于开始位置。
当向文件写入数据时,数据会被写入文件指针当前指向的位置,而在写入模式下,每次写入操作后文件指针通常会移动到新数据的末尾,为下一次写入操作做准备。如果需要在文件中特定位置写入或追加数据,可以使用 seek() 方法来移动文件指针。
9.16
判断对错:使用内置函数 open()打开文本文件时,不能指定’rb’,只能使用’r’模式和恰当的 encoding 参数。
判断:错误
原因:使用内置函数 open() 打开文本文件时,确实常用 'r' 模式,并且可以指定 encoding 参数来处理文本数据的编码和解码。
然而,open() 函数也支持使用 'rb'(二进制读取模式)来打开文本文件。虽然通常 rb 用于二进制文件,但并没有限制它用于文本文件。
扩展:文本文件和二进制文件的关系
为什么有文本文件和二进制文件这两种形式?这个问题涉及到计算机文件的表示和处理方式。
确实所有的文件在计算机中最终都是以二进制形式存储的,无论是文本文件还是二进制文件,它们都存在于磁盘上并以字节序列的形式存在。但是,它们在处理方式上有所不同,这主要是由于它们所包含的数据结构和解释方式的差异。
文本文件
- 文本文件是由字符组成的,通常使用某种字符编码(如ASCII或UTF-8)来表示。
- 它们可以通过文本编辑器直接打开和编辑。
- 在编程中,文本文件通常被打开为流式对象,可以按行或字符读取和写入。
- 使用文本模式(如
'r'或'w')打开文件时,Python会自动处理字符编码的转换,将字符串转换为字节,并在读取时将字节转换回字符串。
二进制文件
- 二进制文件包含的是程序或数据的二进制表示,它们不是以字符序列的形式存在,而是以更底层的数据结构(如图像像素、音频波形、可执行代码等)存在。
- 二进制文件通常需要专门的程序或库来读取和解释。
- 使用二进制模式(如
'rb'或'wb')打开文件时,Python会以字节序列的形式处理数据,不会进行任何字符编码的转换。
为什么要区分
区分文本文件和二进制文件的主要原因是:
-
抽象级别:文本模式提供了一个更高层次的抽象,使得处理文本数据更为简单和直观,无需关心底层的字节序列。
-
编码转换:文本模式自动处理字符编码的转换,使得跨平台文本数据的处理更为方便。
-
数据结构:二进制文件包含复杂的数据结构,需要以特定的方式解析和处理。
-
性能:在某些情况下,直接以二进制模式处理数据可能更高效,因为它避免了字符编码转换的开销。
-
安全性:文本模式可以防止一些潜在的安全风险,如二进制数据注入等。
-
兼容性:不同的操作系统和程序可能对文本文件和二进制文件有不同的处理方式,区分它们可以保证兼容性和预期的行为。
综上,尽管所有文件都是以二进制形式存储的,但区分文本文件和二进制文件在处理方式、编码转换、数据结构和程序设计上提供了灵活性和便利性。
另外:
“文本文件的底层就是二进制文件”这句话在概念上是正确的,因为所有的文件系统操作和存储都是基于二进制的。但是,这并不意味着文本文件“就是”二进制文件,它们是两种不同的概念,对应着不同的数据处理和表示方式。
无论文本文件还是二进制文件,它的底层都是二进制比特流的形式存储
9.17
判断对错:使用内置函数 open()且以’a’模式打开的文件,文件指针默认指向文件尾。
判断:正确
另外:这个题不严谨使用内置函数 open() 并以 'a'(追加模式)打开文件时,文件指针默认指向文件末尾的下一个字节位置,而不是文件末尾。这意味着,写入操作将会在现有内容的末尾添加数据,而不是覆盖文件末尾的数据。
追加模式主要用于在不破坏现有文件内容的情况下向文件添加更多数据。如果使用 open() 以 'a' 模式打开文件,然后调用 write() 方法,新内容会被添加到现有内容之后。如果想在文件中特定位置插入内容,需要先使用 seek() 方法将文件指针移动到所需位置。
扩展:文件的末尾和文件内容的末尾
在大多数情况下,对于一个文件来说,文件内容的末尾通常意味着文件的末尾,因为文件内容的末尾紧接着就是文件的物理存储结束的地方。然而,在某些情况下,文件内容的末尾和文件的末尾可能会有所区别,尤其是在涉及文件系统操作和数据恢复的复杂场景中。
以下是一些可能导致文件内容末尾和文件末尾不完全相同的情况:
-
残留空间:在文件系统的某个块或簇中,如果文件内容占用了空间但没有填满整个块或簇,那么文件内容的末尾和文件分配的末尾之间可能会有未利用的空间。
-
文件系统预留空间:某些文件系统可能会在文件分配的末尾预留一些空间,用于存储文件系统的元数据或其他信息。
-
删除和覆盖:如果一个文件被删除然后又用相同的名字重新创建,新文件的内容末尾可能不会达到原来文件的末尾。
-
文件系统损坏:在文件系统损坏或发生错误的情况下,可能会出现文件内容末尾和文件分配空间末尾不一致的情况。
-
数据恢复:在数据恢复过程中,恢复的文件内容可能不会完全覆盖原来的文件分配空间,导致内容末尾和文件末尾不一致。
在Python中,当使用 open() 以追加模式 'a' 打开文件时,Python会尝试将文件指针放置在文件内容的末尾之后,以便新数据可以追加到现有内容之后。但是,Python通常不会检查文件系统层面的文件末尾和内容末尾之间的差异,除非涉及到底层的文件系统操作。
总结来说,对于大多数常规用途,文件内容的末尾可以被视为文件的末尾。但在一些特殊的文件系统操作或数据恢复场景中,两者可能会有所区别。在大多数编程任务中,包括使用Python的文件操作,通常不需要考虑这种差异。
这里的话就是文件末尾就对就是了
9.18
判断对错:使用内置函数 open()且以’ab’模式打开的文件,文件指针默认指向文件尾。
判断:正确
9.19
判断对错:使用内置函数open()打开文件时,只要文件路径正确就总是以正确打开的。
判断:错误
原因:使用内置函数 open() 打开文件时,文件路径正确是必要条件,但不是唯一条件。即使文件路径正确,也可能因为以下原因之一导致文件无法正确打开:
-
文件权限:当前用户可能没有足够的权限去读取或写入指定的文件。
-
文件正在被使用:文件可能正被另一个进程使用,导致无法访问。
-
文件系统问题:文件系统可能存在问题,如损坏、挂载错误或其他文件系统级的问题。
-
文件损坏:文件本身可能已损坏,特别是如果它是一个二进制文件。
-
文件不存在:如果文件不存在于指定的路径上,即使路径格式正确,
open()也会失败。 -
文件模式不兼容:请求的文件打开模式可能与文件的实际用途不兼容。例如,尝试以写入模式打开一个只读文件。
-
文件系统不支持:尝试在一个不支持文件的文件系统上进行文件操作。
-
文件太大:文件的大小可能超出了可以处理的范围,尤其是在内存有限的情况下。
-
系统资源限制:系统可能达到打开文件的数量限制,或者磁盘空间不足。
-
符号链接问题:如果路径是符号链接,并且链接的目标不存在或权限不足,那么打开文件也会失败。
在Python中,如果 open() 函数无法成功打开文件,它会抛出一个 FileNotFoundError(如果文件不存在)或 PermissionError(如果权限不足)等异常。因此,在尝试打开文件时,最好使用异常处理机制(如 try...except 块)来处理可能出现的错误。(在Python中,在 try 块中执行代码,并且没有指定 except 块中要捕获的异常类型,那么 except 块将捕获所有继承自 BaseException 的异常。这意味着几乎所有的异常都能被捕获,但通常不推荐这样做)
9.20
判断对错:二进制文件不能使用记事本程序打开,会报错。
判断:错误
原因:二进制文件可以使用记事本程序打开,但打开后显示的内容很可能是不可读的,因为二进制文件包含的是程序或数据的原始字节表示,而不是文本字符。
用文本编辑器(如记事本)打开二进制文件时,可能会看到乱码,因为文本编辑器尝试将字节解释为字符,而二进制文件中的许多字节可能不对应有效的字符编码。尽管如此,某些二进制文件可能包含可打印字符的序列,这些部分在文本编辑器中可能会显示为人可读的文本。
此外,用文本编辑器打开二进制文件并不会“报错”,只是显示的内容可能没有意义
9.21 (有争议,暂且判断为会写入一部分(即正确))
9.21 判断对错:运行下面的代码:
fp= open(‘text.txt’,‘w’, encoding=‘utf8’)for i in range(10):fp.write(str(i//(i-3)))
fp.close()
代码会抛出异常,但是text.txt 文件中会写入一部分内容。
判断:错误
原因:在提供的代码中,for 循环中的 i 从 0 开始。当 i 为 0 时,表达式 i // (i - 3) 会导致 ZeroDivisionError
由于 ZeroDivisionError 是在循环的第一次迭代中发生的(当 i 为 1),因此 fp.write() 将没有机会执行,除非异常被捕获并处理。这意味着在 text.txt 文件中不会有任何内容被写入,因为程序会在尝试写入之前由于异常而停止执行。
如果代码在前几次循环中正常执行,并且没有遇到任何异常,那么在发生 ZeroDivisionError 之前,fp.write() 调用将会成功地将数据写入到 text.txt 文件中。
不过vscode里面测试是可以写入的

22
9.22 判断对错:运行下面的代码:
‘w’,encoding=‘utf8’)as fp:with open(‘text.txt’,for i in range(10):fp.write(str(i//(i-3)))
代码会抛出异常,但是 text.txt 文件中会写人一部分内容。
判断:正确
用with的就可以
9.23
判断对错:内置函数open()使用’w’模式打开的文件,不仅可以往文件中写入内容,也可以从文件中读取内容。
判断:错误
原因:
open() 函数使用 'w' 模式打开文件时,是用于写入操作。'w' 模式代表写入模式(write mode),这意味着文件被打开用于写入数据。如果文件不存在,'w' 模式会创建一个新文件;如果文件已存在,'w' 模式会截断(即清空)文件内容,然后允许写入新内容。
读取文件内容通常使用 'r' 模式,即读取模式(read mode)。在读取模式下,文件指针会从文件的开始位置读取内容,而不是写入。
因此,使用 'w' 模式打开的文件不能用于读取内容,只能用于写入内容。如果尝试从以 'w' 模式打开的文件中读取,将会引发错误。
9.24
判断对错:内置函数 open()使用’r’模式打开的文件,只能读取其中的内容,不能写人任何新内容。
判断:正确
原因:
open() 函数使用 'r' 模式打开文件时,是专门用于读取文件中的现有内容。'r' 模式代表读取模式(read mode),在这种模式下,文件指针会定位到文件的开始,允许程序读取文件中的数据。
在 'r' 模式下,尝试写入文件会引发错误,因为这种模式不允许对文件进行修改。如果目的是修改或添加内容到文件中,应该使用其他模式,如 'w'(写入模式,会截断文件)、'a'(追加模式,会在文件末尾添加内容而不截断)或者 'r+'(读写模式,允许读写操作,但会创建新文件如果文件不存在,或截断现有文件以开始写入)。
9.25
判断对错:内置函数 open()使用’r+'模式打开的文件,只能读取其中的内容,不能写人任何新内容。
判断:错误
原因:
open() 函数使用 'r+' 模式打开文件时,是用于同时进行读取和写入操作的模式。'r+' 模式代表读写模式(read and write mode),在这种模式下,文件既可以被读取,也可以被写入。
在 'r+' 模式下,文件指针会定位到文件的开始,允许程序读取文件中的数据,同时也允许对文件进行修改或添加新内容。不过,需要注意的是,当在 'r+' 模式下执行写入操作时,如果写入位置在文件的开始或中间,可能会覆盖掉原有的数据。
因此,'r+' 模式确实允许写入新内容,而不仅仅是读取文件内容。
9.26
判断对错:读写文件时,只要程序中调用了文件对象的close()方法,就定可以保证文件被正确关闭。
判断:错误
原因:
虽然在程序中显式调用文件对象的 close() 方法可以关闭文件,但这种做法并不是万无一失的。如果在调用 close() 方法之前发生异常,或者程序员忘记了调用这个方法,文件可能不会被正确关闭。未正确关闭的文件可能导致数据未被正确写入,或者在多线程环境中导致资源冲突。
为了确保文件在使用后能够被正确关闭,推荐使用 with 语句来管理文件上下文。with 语句基于上下文管理器,它会自动处理文件的打开和关闭,即使在发生异常的情况下也能确保文件被关闭。示例如下:
with open('filename', 'r') as file:
# 进行文件操作
data = file.read()
# 文件会在with语句块执行完毕后自动关闭,即使发生异常也是如此
使用 with 语句的好处是,它提供了一个清晰的语法结构,减少了文件忘记关闭的风险,并且在处理异常时更加安全。
9.27
判断对错:使用扩展库openpyxl的函数Workbook()创建新工作簿时,默认情况下是完全空白的,里面没有工作表,必须使用工作对象的createsheet()方法创建工作表才能写入数据。
判断:错误
原因:
使用扩展库 openpyxl 的 Workbook() 函数创建新的工作簿时,默认情况下会创建一个包含一个空白工作表的工作簿。这个工作表可以立即用来写入数据,无需额外创建。
以下是使用 openpyxl 创建工作簿并添加数据的示例:
from openpyxl import Workbook
# 创建一个新的工作簿,默认包含一个工作表
wb = Workbook()
# 获取默认创建的工作表
ws = wb.active
# 在工作表中写入数据
ws['A1'] = 'Hello, World!'
# 保存工作簿
wb.save('example.xlsx')
在这个示例中,我们没有使用 create_sheet() 方法来创建工作表,因为 Workbook() 在创建时已经包含了一个工作表。我们可以直接通过 wb.active 获取这个工作表,然后开始写入数据。
如果需要添加更多的工作表,可以使用 create_sheet() 方法来创建新的工作表:
# 创建一个新的工作簿
wb = Workbook()
# 添加一个新的工作表
sheet2 = wb.create_sheet(title="Sheet2")
# 在新工作表中写入数据
sheet2['A1'] = 'Data in second sheet'
# 保存工作簿
wb.save('example.xlsx')
在这个示例中,我们使用 create_sheet() 方法添加了一个新的工作表,并给它指定了一个标题 “Sheet2”。(在 openpyxl 中,默认的工作表名称通常是 “Sheet”,后面跟随一个数字,例如 “Sheet1”。)
9.28
判断对错:内置函数 open()以’r’模式打开的文本文件对象是可遍历的可以使用 for 循环遍历文件中每行文本。
判断:正确
原因:
在 Python 中,使用内置的 open() 函数以 'r' 模式打开的文件对象确实是可遍历的。这意味着可以使用 for 循环来遍历文件中的每一行文本。Python 会将文件的每一行视为迭代器中的一个元素,从而允许逐行读取文件内容。
以下是使用 for 循环遍历以 'r' 模式打开的文件的示例:
# 使用 'r' 模式打开文件
with open('example.txt', 'r') as file:
for line in file:
print(line.strip()) # 使用 strip() 移除每行末尾的换行符
在这个示例中,for 循环会自动读取文件 example.txt 中的每一行,并将它们逐个赋值给变量 line。strip() 方法用于移除字符串末尾的换行符,这样打印出来的每一行就不会包含额外的空白字符。使用 with 语句确保文件在操作完成后会被正确关闭。
9.29
判断对错:以读模式打开文件时,文件指针指向文件开始处。
判断:正确
原因:当以读模式(‘r’)打开文件时,文件指针默认位于文件的开始处,这意味着接下来的读取操作将从文件的第一行或第一个字符开始。
9.30
判断对错:以追加模式打开文件时,文件指针指向文件尾。
正确
9.31
判断对错:CSV格式的文件属于文本文件。
正确
9.32
判断对错:Python 源程序文件属于二进制文件。
判断:错误
原因:Python 源程序文件是文本文件,它们包含 Python 代码,可以被文本编辑器直接读取和编辑。虽然 Python 解释器会将这些文本文件转换为二进制形式的字节码执行,但源代码文件本身是文本格式。
9.33
判断对错:视频文件属于二进制文件。
判断:正确
原因:视频文件通常包含大量的二进制数据,这些数据编码了视频的图像和音频信息。视频文件格式如 MP4、AVI、MOV 等,都是以二进制形式存储数据的,它们不能直接通过文本编辑器查看或编辑,需要专门的视频播放软件来解码和播放。
9.34
判断对错:音频文件属于二进制文件。
判断:正确
原因:音频文件如 MP3、WAV、AAC 等,也是二进制文件。它们包含了以二进制形式编码的音频数据,这些数据描述了声音的波形。音频文件需要音频播放器来解码和播放,不能通过文本编辑器直接查看或编辑。
9.35
判断对错:扩展名为py 和 pyw 的 Python 程序文件属于文本文件。
判断:正确
原因:扩展名为 .py 和 .pyw 的文件都是 Python 程序文件,它们包含 Python 源代码,这是一种纯文本格式。.py 是标准的 Python 源代码文件扩展名,而 .pyw 通常用于在 Windows 系统上运行时不显示控制台窗口的 Python 脚本。
这些文件可以在任何文本编辑器中打开、查看和编辑,因为它们不包含二进制数据,而是由可读的文本组成,这些文本由 Python 编程语言的语法构成。尽管 .pyw 文件在运行时的行为可能与 .py 文件略有不同(如不显示控制台窗口),但这并不改变它们作为文本文件的本质。
9.36
判断对错:扩展名为py的文件属于文本文件,扩展名为pyw的文件属于二进制文件。
判断:错误
原因:扩展名为 .py 的文件和扩展名为 .pyw 的文件都属于文本文件。它们都包含 Python 源代码,可以在文本编辑器中打开和编辑。.py 是标准的 Python 源代码文件扩展名,而 .pyw 通常用于在 Windows 系统上运行时不显示控制台窗口的 Python 脚本,但这并不改变它们作为文本文件的本质。
二进制文件是指那些包含非文本数据的文件,比如图片、视频、音频文件,或者是编译过的程序文件。这些文件通常不能直接在文本编辑器中打开,或者即使能够打开,显示的也是无法阅读的字符。
因此,无论是 .py 还是 .pyw 文件,它们都是以文本形式存储的,包含可读的 Python 代码。
9.37
判断对错:扩展名为 whl 的文件属于二进制文件。
判断:正确
原因:扩展名为 .whl 的文件是 Python Wheel 包,这是一种 Python 包的分发格式。Wheel 包是一种二进制分发格式,它允许用户快速安装包含原生代码的 Python 包,而不需要像源码包那样需要编译。
Wheel 文件通常由 setuptools 或 wheel 包的打包工具生成,它们包含了编译过的扩展模块和可能的其他文件,这些文件是为了在特定平台上运行而编译的。因此,.whl 文件包含了二进制数据,而不是纯文本数据。
Wheel 包格式的主要优势在于安装速度,因为它们不需要像源码包那样在安装时编译。此外,Wheel 包通常也比源码包更小,因为它们不包含源代码,只包含编译后的字节码或机器码。(简单来说,Wheel 包是一种编译好的、可直接安装使用的第三方库格式)
9.38
判断对错:扩展名为 pyd 的文件属于二进制文件。
判断:正确
原因:扩展名为 .pyd 的文件是 Python 扩展模块,它们通常是用 C 或 C++ 编写的,并编译为二进制格式以便在 Python 程序中使用。这些文件是动态链接库(Dynamic Link Libraries,简称 DLLs),在 Windows 系统上以 .pyd 为扩展名,在 Unix-like 系统上则可能是 .so(Shared Object)。
.pyd 文件包含了编译后的机器代码,因此它们是二进制文件,而不是文本文件。Python 可以使用 import 语句直接导入这些扩展模块,从而使用它们提供的额外功能,而无需了解底层实现细节。这些扩展模块常用于提升性能,封装复杂的外部库,或者访问系统级别的功能。
9.39
判断对错:Python 的主程序文件 python.exe 属于二进制文件。
判断:正确
原因:python.exe 是 Python 解释器在 Windows 操作系统上的可执行文件。它允许用户运行 Python 脚本和程序。这个文件包含了编译后的机器代码,使得计算机的处理器可以直接执行它来启动 Python 解释器。
由于 python.exe 文件包含了用于执行 Python 脚本的二进制指令,它是一个二进制文件,而不是文本文件。这意味着它不能直接通过文本编辑器查看或编辑,需要通过命令行界面或脚本运行器来使用。在其他操作系统上,Python 解释器的可执行文件通常命名为 python 或 python3,而不带 .exe 扩展名。
9.40
判断对错:Python 程序进行伪编译后得到的 pyc 文件属于二进制文件。
判断:正确
Python 程序进行伪编译后得到的 pyc 文件属于二进制文件。pyc 文件是 Python 代码编译后的字节码,其形式是二进制的,便于 Python 解释器执行。
9.41
判断对错:对字符串进行编码以后,必须使用同样的或者兼容的编码格式进行解码才能还原本的信息。
判断:正确
原因:对字符串进行编码后,其实是将字符串转换成了字节序列,而使用不同的编码格式进行解码可能导致字节序列被错误地解释。只有使用相同的或兼容的编码格式进行解码,才能正确地还原字符串的原始信息。例如,如果一个字符串使用 UTF-8 编码进行编码,那么解码时必须使用 UTF-8 编码格式才能还原原始字符串。
9.42
9.43
import pickle
score={'张':98,'李':90,'王':100}
with open('score.dat','wb')as fp:
pickle.dump(score,fp)
with open('score.dat','rb')as fp:
result=pickle.load(fp)
print(result)
这段代码的主要逻辑是使用 Python 的 pickle 模块对一个包含学生姓名和分数的字典对象进行序列化和反序列化。
import pickle:导入 Python 标准库中的 pickle 模块,该模块提供了对象序列化和反序列化的功能。
score = {'张三': 98, '李四': 90, '王五': 100}:创建一个字典 score,其中包含了三个学生的姓名和对应的分数。
with open('score.dat', 'wb') as fp::使用 with 语句打开一个名为 score.dat 的文件,以二进制写入模式('wb')打开。文件对象被赋值给变量 fp。
pickle.dump(score, fp):使用 pickle 模块中的 dump() 函数将字典对象 score 序列化后写入文件 fp 中。这一步将字典对象转换为字节流并写入文件。
with open('score.dat', 'rb') as fp::再次使用 with 语句打开 score.dat 文件,这次以二进制读取模式('rb')打开。文件对象被赋值给变量 fp。
result = pickle.load(fp):使用 pickle 模块中的 load() 函数从文件 fp 中反序列化数据,将其还原为 Python 对象。这一步将之前写入的字节流读取并解析为原始的字典对象。
print(result):打印反序列化后的结果,即之前序列化的字典对象 score。这个结果应该与原始的 score 字典完全相同。
9.44
7文本文件和二进制文件之间区别的简单对比7:
| 特性 | 文本文件 | 二进制文件 |
|---|---|---|
| 存储内容 | 可读文本字符 | 任意字节序列 |
| 文件扩展名 | .txt, .py, .js, .json 等 | .bin, .exe, .dll, .pyd, .whl, .out 等 |
| 编码 | 通常使用 UTF-8 或其他文本编码 | 无特定编码,直接存储字节 |
| 可读性 | 人类可读 | 通常不可读 |
| 存储结构 | 格式化的文本 | 可以是任何结构 |
| 内容解释 | 按行按字符解释 | 按字节解释 |
| 用途 | 源代码、文档、配置文件等 | 可执行文件、库文件、图片、音频、视频等 |
| 打开模式(Python) | 'r', 'w', 'a' 等 | 'rb', 'wb', 'ab' 等 |
| 示例应用 | 文本编辑器、阅读器 | 专用软件或库 |
文本文件是按字符序列存储的,适合人类阅读和编辑,而二进制文件则包含任意字节序列,通常需要特定的软件或库来正确读取和解释。
















 982
982











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











