






一、学考模拟卷1
1.1、数据
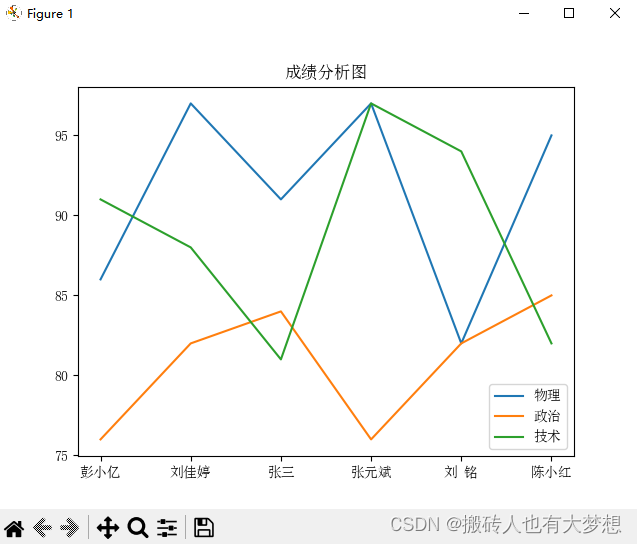
| 学号 | 姓名 | 物理 | 政治 | 技术 |
| 1001 | 彭小亿 | 86 | 76 | 91 |
| 1002 | 刘佳婷 | 97 | 82 | 88 |
| 1003 | 张三 | 91 | 84 | 81 |
| 1004 | 张元斌 | 97 | 76 | 97 |
| 1005 | 刘 铭 | 82 | 82 | 94 |
| 1006 | 陈小红 | 95 | 85 | 82 |
1.2、代码
import pandas as pd
import matplotlib.pyplot as plt
from pylab import *
# 学考模拟卷1
def test011():
plt.rcParams['font.sans-serif'] = ['SimSun'] # 图表显示中文
df = pd.read_excel('./pandasPractice/test001.xlsx')
x = df["姓名"]
y1 = df["物理"]
y2 = df["政治"]
y3 = df["技术"]
plt.plot(x, y1, label="物理")
plt.plot(x, y2, label="政治")
plt.plot(x, y3, label="技术")
plt.title("成绩分析图")
plt.legend()
plt.show()1.3、结果
二、 as_index,sort_values,sum,count使用
2.1、数据
| 序号 | 名称 | 类型 |
| 1 | 《平凡的世界》 | 现代文学 |
| 2 | 《蛙》 | 现代文学 |
| 3 | 《老人与海》 | 世界名著 |
| 4 | 《基地与帝国》 | 科幻 |
| 5 | 《沙丘》 | 科幻 |
| 6 | 《悲惨世界》 | 世界名著 |
| 7 | 《红与黑》 | 世界名著 |
| 8 | 《三国演义》 | 中国古典 |
| 9 | 《水浒传》 | 中国古典 |
| 10 | 《左传》 | 历史地理 |
2.2、代码
def test001():
# 处理中文乱码问题
plt.rcParams['font.sans-serif'] = [u'LiSu']
plt.rcParams['axes.unicode_minus'] = False
# 需要提前安装openpyxl模块,否则报错 cmd/pip install openpyxl
df = pd.read_excel('./pandasPractice/7天报错分类统计.xlsx')
df1 = df.groupby("类型", as_index=False).count() #如果 as_index=True,则下面 x=df3.index,因为类型列变索引列了,类型列就不存在了; 如果count()改为sum(),发现序号被求和了
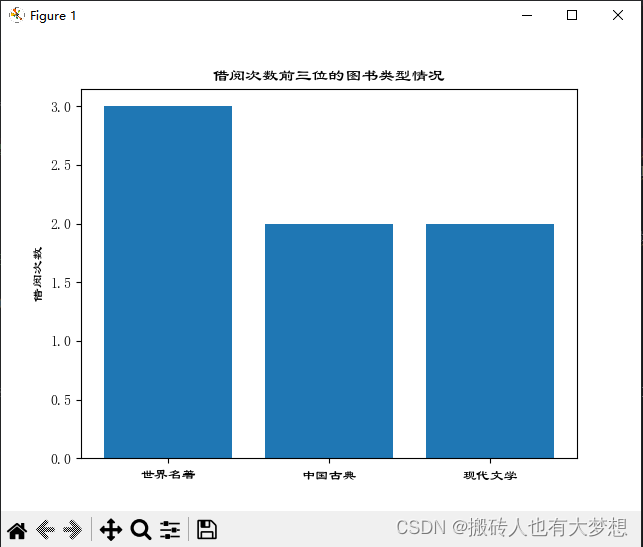
df2 = df1.sort_values("序号", ascending=False).head(3) #这里用序号和名称都可以,# df2 = df1.sort_values("名称", ascending=False).head(3)
df3 = df2.rename(columns={"名称": "借阅次数"})
x = df3["类型"] # x = df3.index
y = df3.借阅次数 # y=df3.借阅次数 或者 df3["借阅次数"] 或者 df2.名称 或者 df2.序号 或者 df2["名称"] 或者 df2["序号"]
plt.title("借阅次数前三位的图书类型情况")
plt.bar(x, y)
plt.ylabel("借阅次数")
plt.show()2.3、结果
三、groupby, head, sum, df2[(df2["销售数量"] > 25) | (df2["销售数量"] < 10)]
3.1、数据
| 序号 | 商品名称 | 销售人员 | 单品进价 | 销售数量 | 单品售价 | 销售金额 | 利润 |
| 1 | 显示器 | 高伟 | 1200 | 12 | 1500 | 18000 | |
| 2 | 微波炉 | 赵奇 | 400 | 2 | 500 | 1000 | |
| 3 | 显示器 | 杨光 | 1200 | 11 | 1500 | 16500 | |
| 4 | 按摩椅 | 高伟 | 640 | 2 | 800 | 1600 | |
| 5 | 按摩椅 | 赵奇 | 640 | 13 | 800 | 10400 | |
| 6 | 跑步机 | 林茂 | 1760 | 1 | 2200 | 2200 | |
| 7 | 液晶电视 | 毕春艳 | 4000 | 16 | 5000 | 80000 | |
| 8 | 液晶电视 | 毕春艳 | 4000 | 23 | 5000 | 115000 | |
| 9 | 液晶电视 | 杨光 | 4000 | 2 | 5000 | 10000 | |
| 10 | 液晶电视 | 林茂 | 4000 | 30 | 5000 | 150000 |
3.2、代码
# groupby, head, sum, df2[(df2["销售数量"] > 25) | (df2["销售数量"] < 10)]
def test010():
df = pd.read_excel('./pandasPractice/sale.xlsx', sheet_name='Sheet1')
df.at[0,"销售人员"]="毕春艳"
df["利润"]=(df["单品售价"]-df["单品进价"])*df["销售数量"]
df1 = df.groupby("商品名称")[["销售数量", "利润"]].sum() # df1 = df.groupby(["商品名称", "销售数量"])["利润"].sum() 报错
for name, group in df.groupby('商品名称'):
print(name, group)
df4 = df1.sort_values("利润", ascending=False).head(3)
df2 = df.groupby("销售人员", as_index=False)["销售数量"].sum()
print(df2[(df2["销售数量"] > 25) | (df2["销售数量"] < 10)])
# 取某一列,如 取利润列
df5 = df.groupby("商品名称").利润.sum()
df6 = df.groupby("商品名称")["利润"].sum()3.3、结果
微波炉 序号 商品名称 销售人员 单品进价 销售数量 单品售价 销售金额 利润
1 2 微波炉 赵奇 400 2 500 1000 200
按摩椅 序号 商品名称 销售人员 单品进价 销售数量 单品售价 销售金额 利润
3 4 按摩椅 高伟 640 2 800 1600 320
4 5 按摩椅 赵奇 640 13 800 10400 2080
显示器 序号 商品名称 销售人员 单品进价 销售数量 单品售价 销售金额 利润
0 1 显示器 毕春艳 1200 12 1500 18000 3600
2 3 显示器 杨光 1200 11 1500 16500 3300
液晶电视 序号 商品名称 销售人员 单品进价 销售数量 单品售价 销售金额 利润
6 7 液晶电视 毕春艳 4000 16 5000 80000 16000
7 8 液晶电视 毕春艳 4000 23 5000 115000 23000
8 9 液晶电视 杨光 4000 2 5000 10000 2000
9 10 液晶电视 林茂 4000 30 5000 150000 30000
跑步机 序号 商品名称 销售人员 单品进价 销售数量 单品售价 销售金额 利润
5 6 跑步机 林茂 1760 1 2200 2200 440
销售人员 销售数量
1 林茂 31
2 毕春艳 51
4 高伟 2















 7465
7465











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









