







为更好地提供数据支持的电影制作依据,要求大家以TMDB 5000 Movie Dataset数据集为研究对象,完成以下数据可视化任务:2000-2016年期间Twentieth Century Fox Film Corporation、Universal Pictures和Paramount Pictures三家影视公司每年制作的电影数量
import json
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt # 导入绘图库
plt.rcParams['font.family']='SimHei' # 设置黑体字体以正常显示中文
plt.rcParams['axes.unicode_minus']=False # 正常显示负号
plt.rcParams['font.size'] = 13
import warnings
# 忽略警告。pandas很多时候会弹出警告,说某条命令即将在新版本中过期,建议换用新命令。如不想看到警告信息,可用此设置忽略
warnings.filterwarnings('ignore') (1)预处理数据阶段
df = pd.read_csv('tmdb_5000_movies.csv')
df1 = df[['original_title','genres','release_date','runtime','production_companies']]
#修改特定列的值
df1.loc[2656,'runtime'] = 98.0
df1.loc[4140,'runtime'] = 81.0
df1.loc[4553,'release_date'] = '2014-06-01'#查看df1的内容
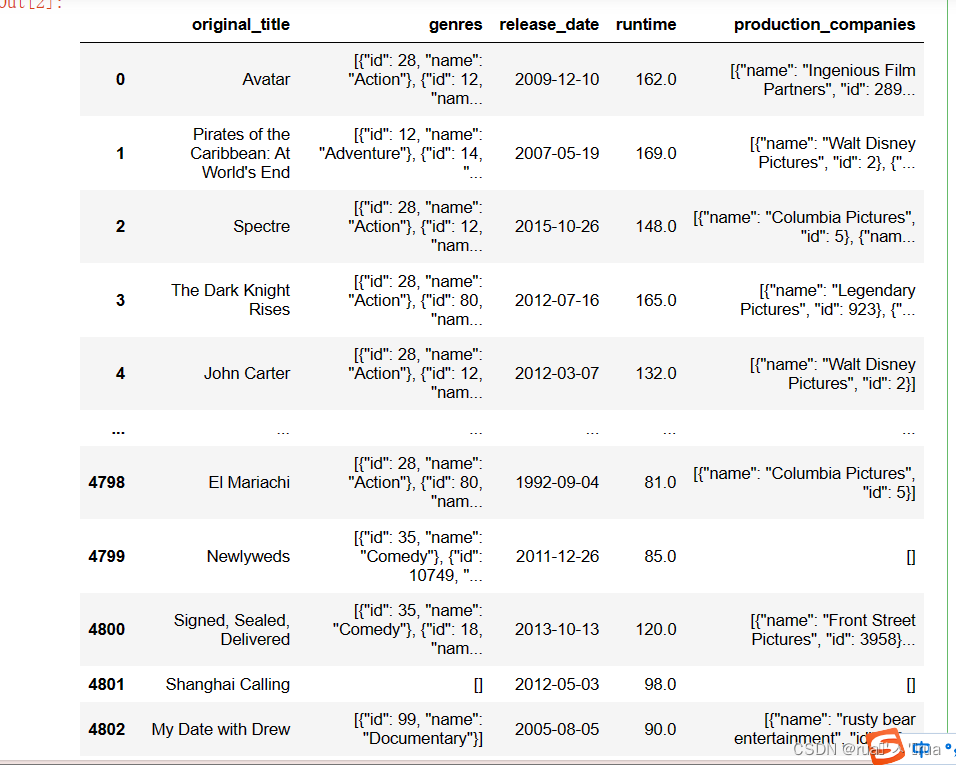
df1['genres'] = df1['genres'].apply(json.loads)
df1['production_companies'] = df1['production_companies'].apply(json.loads)
def decode(col):
genre = []
for item in col:
genre.append(item['name'])
return '/'.join(genre)df1['genres'] = df1['genres'].apply(decode)
df1['production_companies'] = df1['production_companies'].apply(decode)
#提取release_date的年份
df1['release_date'] = pd.to_datetime(df1['release_date']).dt.year
#修改列的名称
col = {'release_date':'year'}
df1.rename(columns = col,inplace=True)
df1['year'].apply(int).head() #转为整数
df1.to_excel('8周课后预处理数据.xlsx')(2)利用预处理好的数据进一步处理并绘图
df = pd.read_excel('8周课后预处理数据.xlsx')
#有个别行数据处理时不是nan但为空列表,提取后为nan
df.dropna(inplace=True)
#筛选出2000年到2016年的数据
df = df[(df['year'] >= 2000)&(df['year'] <= 2016)]
df.reset_index(inplace=True)#查看此时df数据内容
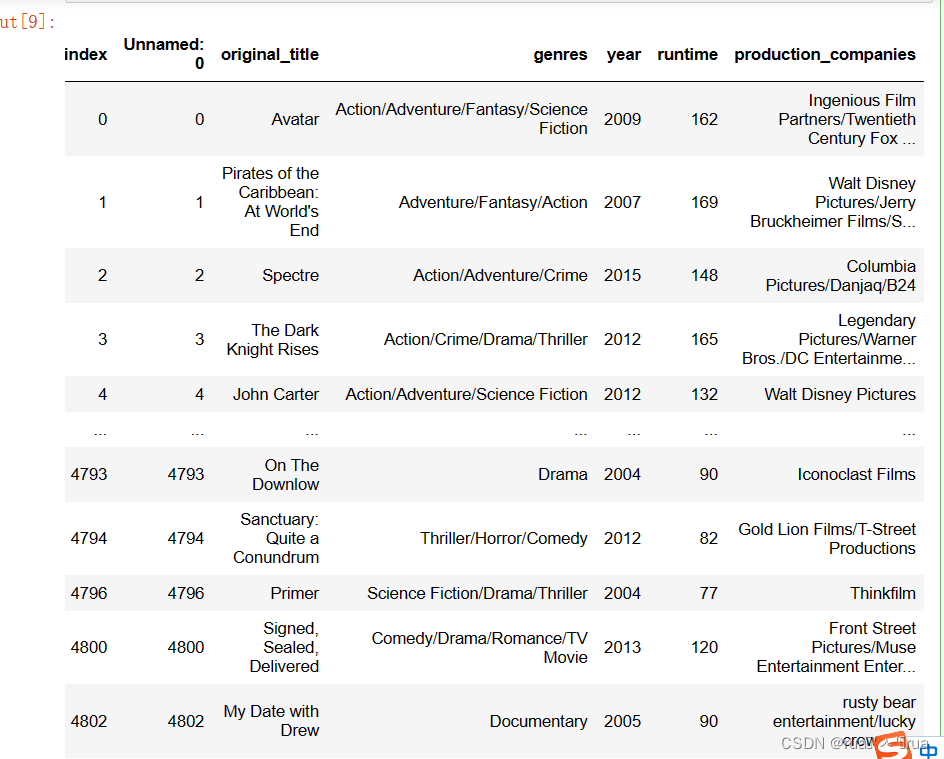
three_companies = ['Twentieth Century Fox Film Corporation',
'Universal Pictures','Paramount Pictures']
for company in three_companies:
#判断每行 有这个公司 对应公司的列下添个1
df[company] = df['production_companies'].str.contains(company).apply(lambda x:1 if x else 0)
company_year = df.loc[:,three_companies]
#将年份作为索引标签
company_year.index = df['year']
#将数据集按年份分组并求和,得出每个年份,各电影类型的电影总数
three_companies_df = company_year.groupby('year').sum()
three_companies_df.columns = ['T','U','P']
#绘图
x = range(0,17)
fig,ax = plt.subplots(1,1,figsize=(14,8))
ax.plot(x,three_companies_df['T'],marker='^',linewidth=1.5,label='Twentieth Century Fox Film Corporation')
ax.plot(x,three_companies_df['U'],marker='o',linewidth=1.5,label='Universal Pictures')
ax.plot(x,three_companies_df['P'],marker='s',linewidth=1.5,label='Paramount Pictures')
a = 0
for y_h,y_l,y_k in zip(three_companies_df['T'],three_companies_df['U'],three_companies_df['P']):
plt.text(a,y_h + 0.1,y_h,family='SimHei',fontsize=12,fontstyle='normal')
plt.text(a,y_l + 0.1,y_l,family='SimHei',fontsize=12,fontstyle='normal')
plt.text(a,y_k + 0.1,y_k,family='SimHei',fontsize=12,fontstyle='normal')
a += 1
ax.set_title('8周课后2000-2016年期间三家公司制作电影的数量')
ax.set_xlabel('年份')
ax.set_ylabel('电影数量')
ax.tick_params(direction='in',length=6,width=2,labelsize=12)
ax.set_xticks(x)
ax.set_xticklabels(three_companies_df.index,rotation=20,fontsize=14)
plt.legend()
plt.savefig('8周课后2000-2016年期间三家公司制作电影的数量.png')
plt.show()#折线图效果
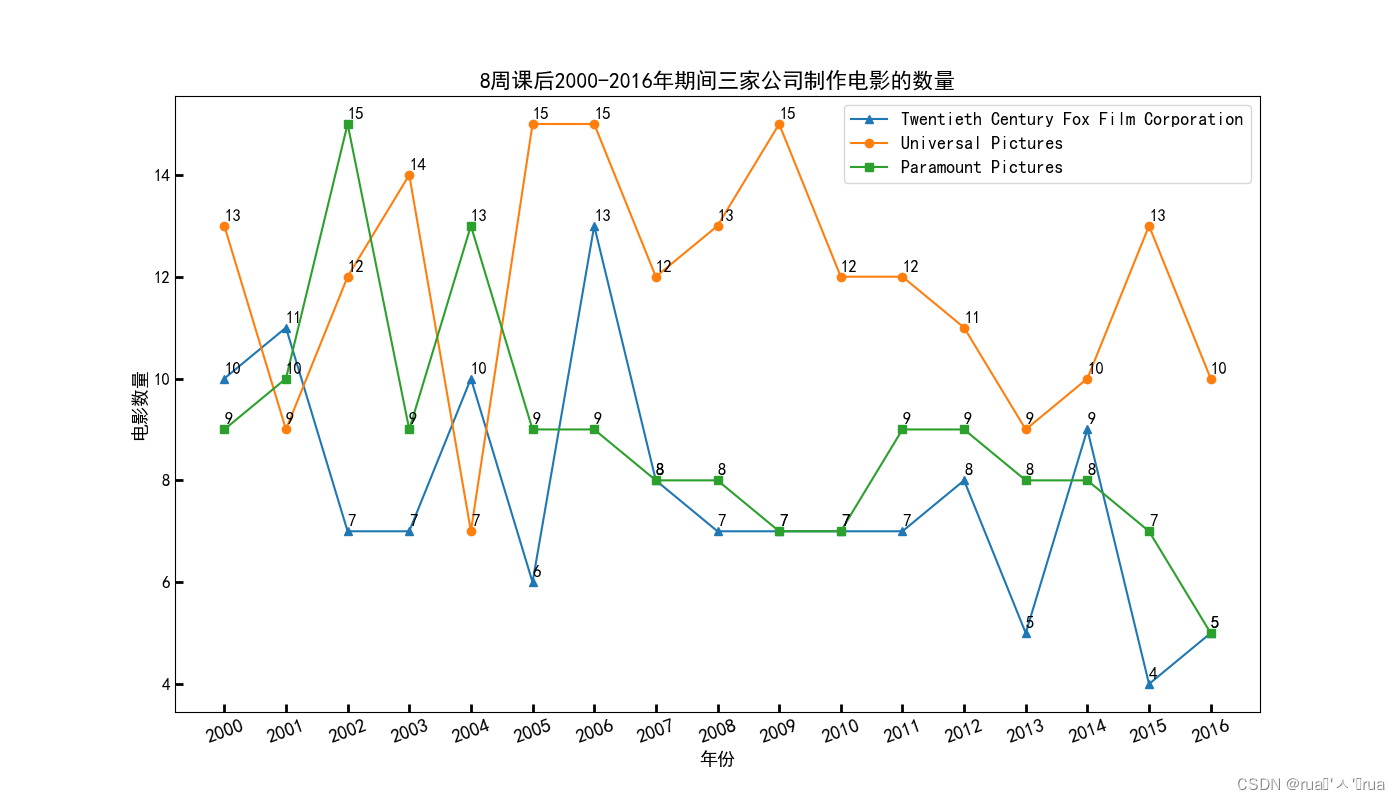















 805
805











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









