







- new与delete(动态内存管理)
- 初始化列表
- 隐式类型转换
- 匿名对象
目录
动态内存管理
在学C++之前,有人说学了C++就可以给自己new或者delete一个对象了,这里的new或者delete就是动态内存管理在C++的体现,区别于C语言的calloc realloc malloc 和free几个函数,new一个对象和delete一个对象就显得更加方便了
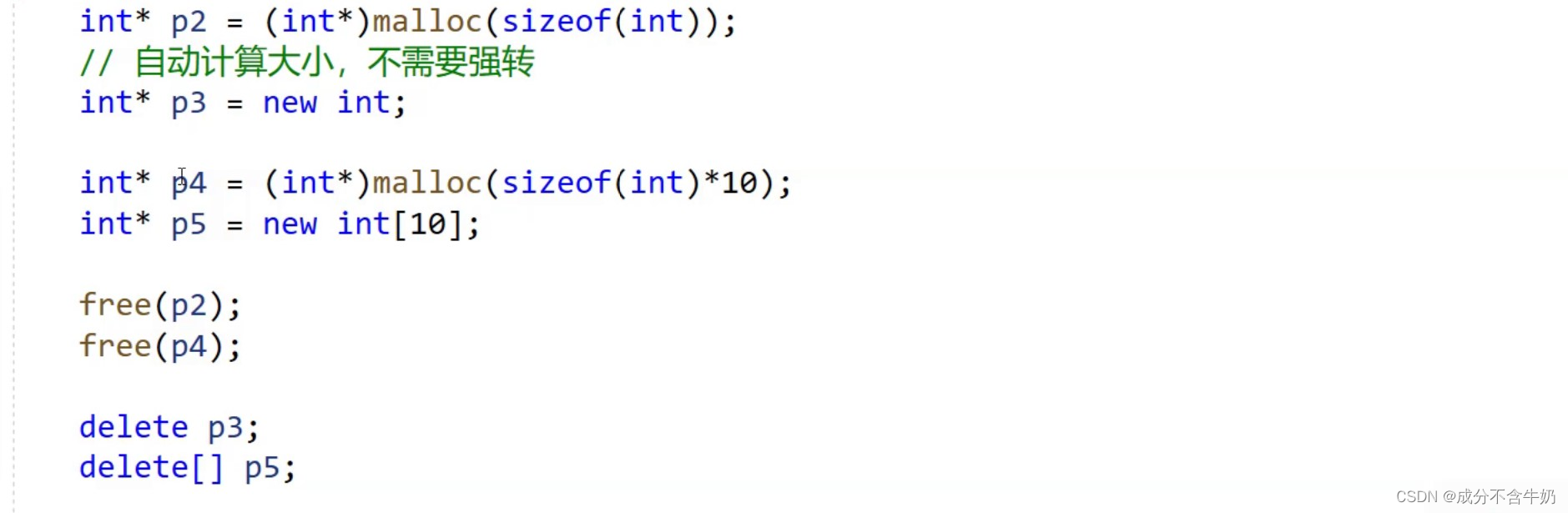 这里我们就可以大概明白,new和delete确实会比传统c语言方便许多,在类与对象中的自定义类型就更加明显啦
这里我们就可以大概明白,new和delete确实会比传统c语言方便许多,在类与对象中的自定义类型就更加明显啦
class myStack {
public:
myStack(int capacity = 4)
// 初始化列表
:_array(nullptr)
,_capacity(capacity)
,_size(0)
{
_array = new int[_capacity];
cout<<"构造 启动!"<<endl
}
~myStack() {
_array = nullptr;
_capacity = 0;
_size = 0;
cout<<" 析构 启动!"<<endl;
}
private:
int* _array;
int _capacity;
int _size;
};
int main() {
// malloc没有办法很好的支持动态申请的自定义对象进行初始化
myStack* s1 = (myStack*)malloc(sizeof(myStack) * 1);
// 并且malloc不会调用构造函数
// 所以这时候就是new的优势, new了一个自定义类型的同时调用构造函数
myStack* s2 = new myStack;
myStack* s3 = new myStack(8);
// delete的同时也调用了析构函数,然后释放空间
delete s2;
delete s3;
// 可以用free(s2) 来验证一下会不会调用析构
// 针对多个对象时
myStack* s4 = new myStack[10]; // 开了一个栈
delete[] s4;
myStack ss1(1);
myStack ss2(2);
myStack* s5 = new myStack[2]{ ss1, ss2 };
delete[] s5;
}所以我们以后进行动态内存开辟的时候就用new方便一点啦,然后在使用配套的delete来释放,因为delete的使用会顺便调用析构函数,而free就不会调用析构函数,容易导致内存泄漏。那么这里我们就需要new和delete配套使用
匹配使用! 匹配使用!匹配使用!
new与operator new

当我们new一个stack对象的时候,我们打开汇编代码发现new的过程中会(call)调用operator new 和stack的构造函数,而operator new中为realloc函数和c++抛异常机制的结合,所以我们知道new是realloc的升级版,在c语言我们用realloc需要判断,c++中我们直接通过抛异常机制,用new来开辟动态内存
 定位new表达式
定位new表达式
我们知道c++不能自己调用显示构造函数,可以自己调用显示析构函数
int main() {
Stack* pst1 = (Stack*)operator new(sizeof(Stack));
// pst1->Stack(4); 这里无法调用显示构造函数Stack
// 定位new语法-------------new(指针对象地址)对象名(传入参数列表)
new(pst1)Stack(4); // 等价于new ,也可以调用显示构造函数
// 可以调用析构
pst1->~Stack();
operator delete(pst1);
}malloc/free和new/delete的区别(面试会考?)
区别:要从 “用法和底层原理” 来区别

初始化列表
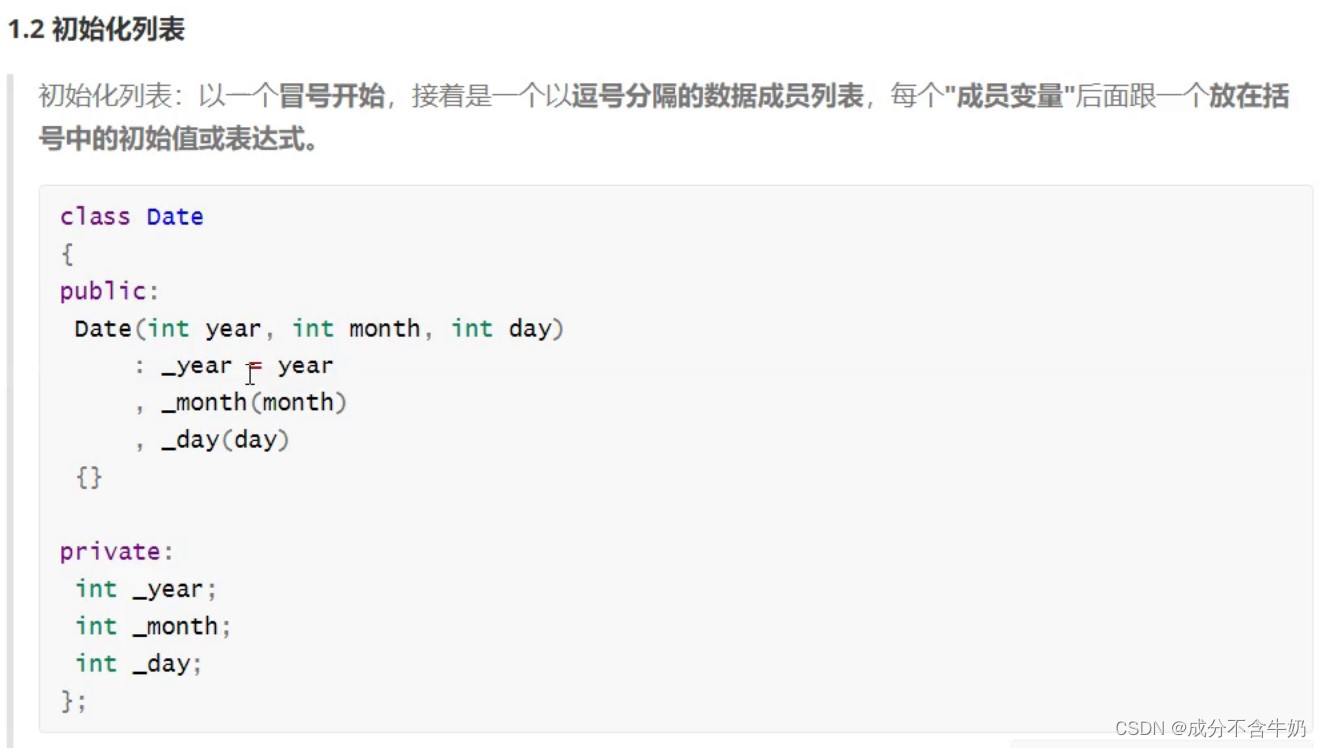
myStack(int capacity = 4)
// 初始化列表
:_array(nullptr)
,_capacity(capacity)
,_size(0)
{
_array = new int[_capacity];
}初始化列表作为初始值的绑定,例如我们知道的假如在封装区(private)处给成员变量绑定初始值,最后也回到初始化列表来分配,初始化列表()给的值是多少最后就是多少的初始值,然后构造函数里面是在初始化后的赋值,总结就是初始化列表的优先级更高,然后构造函数内部是对初始化后的成员变量进行赋值。并且初始化的顺序,跟成员变量声明的顺序一致
隐式类型转换
隐式类型转换是指在编程语言中,当不同类型的数据进行操作时,系统会自动进行类型转换,以便进行正确的计算和比较。这种类型转换是隐式的
class A{
public:
A(int i)
:_a(i)
{}
private:
int _a;
};
int main(){
// 正常构造对象
A aa1(1);
// 借助于隐式类型转换
A aa2 = 2;
// 过程为:用2调用A构造函数生成一个临时对象,再用这个对象去拷贝构造aa2,然后编译器优化
// 优化后直接为用2直接构造
// 与aa2如果想要等同的话就需要也是A对象,而2是int类型,通过隐式类型转换,可以达到目的
}所以隐式类型转换也是可以使代码简洁一点,将整型值和对象挂钩,进行转换
实际上使用时,隐式类型转换还是挺好用的,回到myStack的对象创造
// 隐式类型转换
myStack* s6 = new myStack[10]{ 1, 2 };
delete[] s6;匿名对象

// 匿名对象
myStack* s7 = new myStack[10]{ myStack(1), myStack(2) };
delete[] s7;
// 非匿名对象
myStack ss1(1);
myStack ss2(2);
myStack* s5 = new myStack[2]{ ss1, ss2 };
delete[] s5;
对于匿名对象来说我们不用可以创造一个对象,我们直接一次性使用,通过创造匿名对象,来完成我们的目标,并且也可以让代码看起来更加整洁















 37
37











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









