






1.机器学习到底是什么?
机器学习(Machine learning)是人工智能的分支之一,是指通过计算机算法和大量数据,让机器能够自动地从数据中学习,并根据学习到的知识进行决策。机器学习构建的系统可以通过一些预定义的规则,基于输入数据给出预测和输出结果。机器学习应用广泛,包括语音识别、图像处理、自然语言处理、智能推荐等领域。
机器学习的核心思想是从数据中学习规律,实现对数据的自动分析和理解。机器学习的算法可以分为监督学习、无监督学习和强化学习三类。其中,监督学习需要给出训练数据和标签来进行训练,无监督学习只有输入数据而无标签,强化学习则通过不断与环境交互,对策略进行优化和学习。
机器学习可以帮助人工智能更好地理解世界,提高人工智能的智能水平和自适应性。同时,机器学习还可以帮助人们更好地分析数据、预测趋势、发现规律,对决策和规划有着广泛的应用。
2.python机器学习
Python 是一种非常流行的编程语言,其在机器学习领域也有着广泛的应用。Python 机器学习是指利用 Python 语言及其周边工具和库,构建和应用机器学习算法,以解决各种问题,如分类、聚类、预测、文本处理、图像识别、自然语言处理等。
Python 提供了许多用于机器学习的库和框架,如:
1.Scikit-learn:提供了各种机器学习算法的实现,包括分类、回归、聚类、降维等。
2.TensorFlow:由 Google 开发的深度学习框架,用于构建各种神经网络。
3.PyTorch:Facebook 开发的另一个深度学习框架,与 TensorFlow 相比更加易用和灵活。
3.python常用机器学习及深度学习库介绍
3.1NumPy
NumPy(Numerical Python)是 Python的一个扩展程序库,支持大量的维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库,Numpy底层使用C语言编写,数组中直接存储对象,而不是存储对象指针,所以其运算效率远高于纯Python代码。
1.numpy的操作
处理多维数组:NumPy提供了一个ndarray对象,可以处理多维数组,如向量、矩阵等。
进行数学运算:NumPy提供了许多数学函数和工具,如三角函数、指数函数、对数函数等。
处理数据:NumPy可以读取和写入各种格式的数据文件,如CSV、TXT、MATLAB等。
绘制图表:NumPy可以使用Matplotlib等库绘制图表,以可视化数据和结果。
科学计算:NumPy提供了许多用于科学计算的函数和工具,如线性代数、傅里叶分析、随机数生成等。
机器学习:NumPy与Scikit-learn等机器学习库结合使用,可以进行各种机器学习任务,如分类、回归、聚类等
关于numpy的操作有很多,在这提到一下数组的操作
2.修改形状
1. reshape 不改变数据的条件下修改形状
numpy.reshape(arr, newshape, order')
其中:
arr:要修改形状的数组
newshape:整数或者整数数组,新的形状应当兼容原有形状
order:'C'为 C 风格顺序,'F'为 F 风格顺序,'A'为保留原顺序。
import numpy as np
a = np.arange(8)
print '原始数组:'
print a
print '\n'
b = a.reshape(4,2)
print '修改后的数组:'
print b
原始数组:
[0 1 2 3 4 5 6 7]
修改后的数组:
[[0 1]
[2 3]
[4 5]
[6 7]]
可以看到我们将数组分成了四行两列
2.numpy.ndarray.flat
通常情况下,ndarray.flat 方法用于简化某些操作中的循环。下面是一个使用ndarray.flat 的例子:
import numpy as np
# 定义一个 2x2 的数组
arr = np.array([[1, 2], [3, 4]])
# 使用 ndarray.flat 展平数组
for element in arr.flat:
print(element)
# 输出:
# 1
# 2
# 3
# 4
3. flatten 返回折叠为一维的数组副本
numpy.ndarray.flatten
该函数返回折叠为一维的数组副本,函数接受下列参数:
ndarray.flatten(order)
其中:
order:'C' -- 按行,'F' -- 按列,'A' -- 原顺序,'k' -- 元素在内存中的出现顺序。
例子
import numpy as np
a = np.arange(8).reshape(2,4)
print '原数组:'
print a
print '\n'
# default is column-major
print '展开的数组:'
print a.flatten()
print '\n'
print '以 F 风格顺序展开的数组:'
print a.flatten(order = 'F')
原数组:
[[0 1 2 3]
[4 5 6 7]]
展开的数组:
[0 1 2 3 4 5 6 7]
以 F 风格顺序展开的数组:
[0 4 1 5 2 6 3 7]
4. ravel 返回连续的展开数组
import numpy as np
a = np.arange(8).reshape(2,4)
print '原数组:'
print a
print '\n'
print '调用 ravel 函数之后:'
print a.ravel()
print '\n'
print '以 F 风格顺序调用 ravel 函数之后:'
print a.ravel(order = 'F')
原数组:
[[0 1 2 3]
[4 5 6 7]]
调用 ravel 函数之后:
[0 1 2 3 4 5 6 7]
以 F 风格顺序调用 ravel 函数之后:
[0 4 1 5 2 6 3 7]
3.2tensorflow
相关知识
张量(Tensor):在 TensorFlow 中,所有的数据都是以张量的形式表示的。张量可以看作是一个多维数组,它有多个轴,每个轴上可以有任意长度。
变量(Variable):用于在 TensorFlow 的计算图中存储和更新参数,如神经网络权重。
占位符(Placeholder):在 TensorFlow 的计算图中占用位置,用于在运行计算图时填充和传输数据,如输入数据。
会话(Session):在 TensorFlow 中,会话用于运行计算图中的操作,可以在 CPU 或 GPU 上运行。
激活函数:用于在神经网络的每一层进行非线性变换,增加模型的表达能力,如 ReLU、Sigmoid、tanh 等。
损失函数:用于衡量模型的误差,如均方误差(MSE)、交叉熵(Cross-Entropy)等。
优化器(Optimizer):用于更新模型的参数,以降低损失函数的值,如随机梯度下降(SGD)、Adam、Adagrad 等。
图片处理:TensorFlow 提供了一些强大的工具用于图像处理,如数据增强、数据集加载、图像分类、目标检测等。
1.创建训练数据集
train_x = np.linspace(-1, 1, 100)
train_y = 2 * train_x + np.random.randn(*train_x.shape) * 0.3
这段代码创建了一个训练数据集train_x和train_y。其中,train_x是一个从-1到1等间距取100个点的数组。train_y是一个根据train_x生成的数组,每个元素都是train_x中对应元素的2倍加上一个服从标准正态分布的随机噪声。np.random.randn()函数是生成服从标准正态分布的随机数,np.random.randn(*train_x.shape)表示生成与train_x形状相同的随机数数组。噪声的标准差为0.3,用于模拟真实数据中的误差。这样生成的训练数据集可以用于训练一个简单的线性回归模型,目标是通过train_x预测train_y。
2.定义模型的输入和输出
X = tf.placeholder("float")
Y = tf.placeholder("float")
3.定义模型参数和预测函数
W = tf.Variable(tf.random_normal([1]), name="weight")
b = tf.Variable(tf.zeros([1]), name="bias")
pred = tf.add(tf.multiply(X, W), b)
这段代码定义了线性回归模型的参数和预测函数。其中,W和b分别表示模型的权重和偏置。W的形状为[1],表示该模型只有一个输入特征。通过tf.random_normal()函数随机生成一个初始值来初始化W参数。
b的形状为[1],初始值为0。它是一个偏置项,用于调整模型预测的偏移量。
pred是模型的预测输出,通过tf.add()函数将X与偏置b相加,再通过tf.multiply()函数将X与权重W相乘得到预测结果。其中,X是模型的输入特征,即训练数据集中的自变量,形状为[batch_size, 1],batch_size表示每次训练时输入的数据量。
这个模型实现了简单的线性回归,其预测输出为输入特征与权重的乘积加上偏置。
4.定义损失函数和优化器
cost = tf.reduce_mean(tf.square(Y - pred))
optimizer = tf.train.GradientDescentOptimizer(0.01).minimize(cost)
5.创建会话,并进行模型训练和预测
``` python with tf.Session() as sess: # 初始化模型参数 sess.run(tf.global_variables_initializer())# 进行模型训练
for epoch in range(20):
for (x, y) in zip(train_x, train_y):
sess.run(optimizer, feed_dict={X: x, Y: y})if epoch % 5 == 0:
c = sess.run(cost, feed_dict={X: train_x, Y: train_y})
print("Epoch:", '%04d' % (epoch+1), "cost=", "{:.9f}".format(c),
"W=", sess.run(W), "b=", sess.run(b))print("Optimization Finished!")
training_cost = sess.run(cost, feed_dict={X: train_x, Y: train_y})
print("Training cost=", training_cost, "W=", sess.run(W), "b=", sess.run(b))# 进行模型预测
test_x = np.linspace(-1, 1, 10
import tensorflow as tf
import numpy as np
# 创建训练数据
train_x = np.linspace(-1, 1, 100)
train_y = 2 * train_x + np.random.randn(*train_x.shape) * 0.3
# 定义模型的输入和输出
X = tf.placeholder("float")
Y = tf.placeholder("float")
# 定义模型参数和预测函数
W = tf.Variable(tf.random_normal([1]), name="weight")
b = tf.Variable(tf.zeros([1]), name="bias")
pred = tf.add(tf.multiply(X, W), b)
# 定义损失函数和优化器
cost = tf.reduce_mean(tf.square(Y - pred))
optimizer = tf.train.GradientDescentOptimizer(0.01).minimize(cost)
# 创建会话,并进行模型训练和预测
with tf.Session() as sess:
# 初始化模型参数
sess.run(tf.global_variables_initializer())
# 进行模型训练
for epoch in range(20):
for (x, y) in zip(train_x, train_y):
sess.run(optimizer, feed_dict={X: x, Y: y})
if epoch % 5 == 0:
c = sess.run(cost, feed_dict={X: train_x, Y: train_y})
print("Epoch:", '%04d' % (epoch+1), "cost=", "{:.9f}".format(c),
"W=", sess.run(W), "b=", sess.run(b))
print("Optimization Finished!")
training_cost = sess.run(cost, feed_dict={X: train_x, Y: train_y})
print("Training cost=", training_cost, "W=", sess.run(W), "b=", sess.run(b))
# 进行模型预测
test_x = np.linspace(-1, 1, 10)
print("Test Predictions:")
for x in test_x:
print(sess.run(pred, feed_dict={X: x}))4.总结
分类
可以根据其主要用途将这些库进行分类:
类别 库
图像处理 NumPy、OpenCV、scikit image、PIL、Pillow、SimpleCV、Mahotas、ilastik
文本处理 NLTK、spaCy、NumPy、scikit learn、PyTorch
音频处理 LibROSA
机器学习 pandas, scikit-learn, Orange, PyBrain, Milk
数据查看 Matplotlib、Seaborn、scikit-learn、Orange
深度学习 TensorFlow、Pytorch、Theano、Keras、Caffe2、MXNet、PaddlePaddle、CNTK
科学计算 SciPy
目前来说,chatgpt等人工智能的确给人类生活带来了很大的帮助
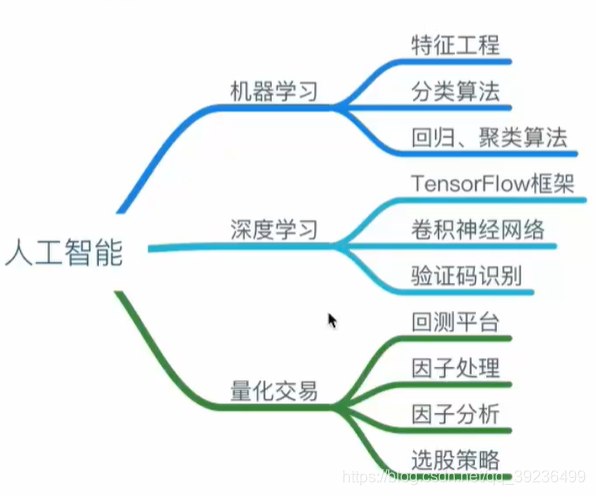
下面是人工智能对应的学习内容















 426
426











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









