








既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
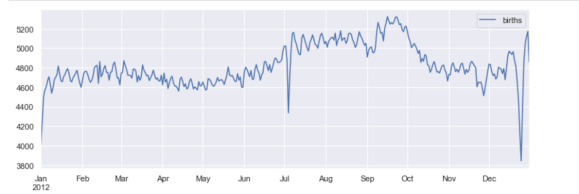
另一个有趣的观点是画出每年的平均出生人数。让我们首先将数据按月和日分别分组:
births_month = births.pivot_table('births', [births.index.month, births.index.day])
print(births_month.head())
births_month.index = [pd.datetime(2012, month, day)
for (month, day) in births_month.index]
print(births_month.head())

只关注月和日,我们现在有了一个时间序列,反映了每年出生的平均人数。由此,我们可以使用plot方法来绘制数据。它揭示了一些有趣的趋势:
fig, ax = plt.subplots(figsize=(12, 4))
births_month.plot(ax=ax)
plt.show()
4.时间序列数据科学项目-自行车计数
作为处理时间序列数据的一个例子,让我们看看西雅图弗里蒙特桥上的自行车数量。这些数据来自于2012年底安装的一个自动自行车计数器,它在大桥的东西两侧人行道上安装了感应传感器。每小时的自行车计数可以在这里下载。
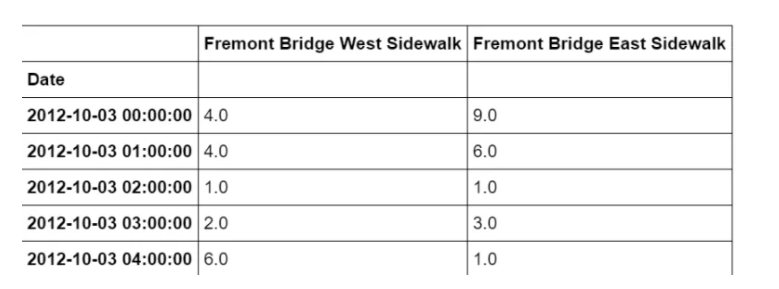
一旦下载了这个数据集,我们就可以使用Pandas将CSV输出读取到一个DataFrame中。我们将指定我们想要的日期作为索引,并且我们想要这些日期被自动解析:
import pandas as pd
data = pd.read_csv("fremont-bridge.csv", index_col= 'Date', parse_dates=True)
data.head()
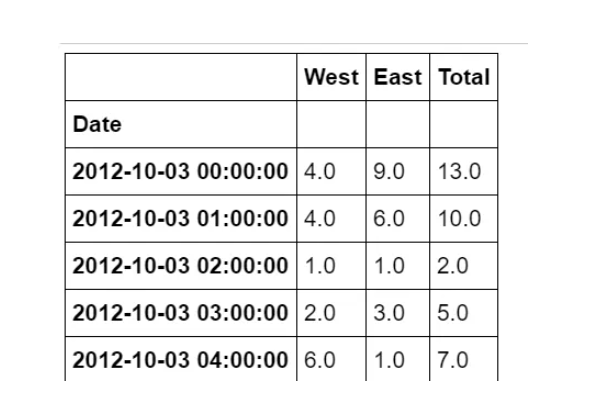
为方便起见,我们将通过缩短列名并添加 “总计” 列来进一步处理此数据集:
data.columns = ["West", "East"]
data["Total"] = data["West"] + data["East"]
data.head()
现在,让我们看一下此数据的摘要统计信息:
data.dropna().describe()
4.1 可视化数据
我们可以通过可视化来深入了解数据集。让我们从绘制原始数据开始:
import matplotlib.pyplot as plt
import seaborn
seaborn.set()
data.plot()
plt.ylabel("Hourly Bicycle count")
plt.show()
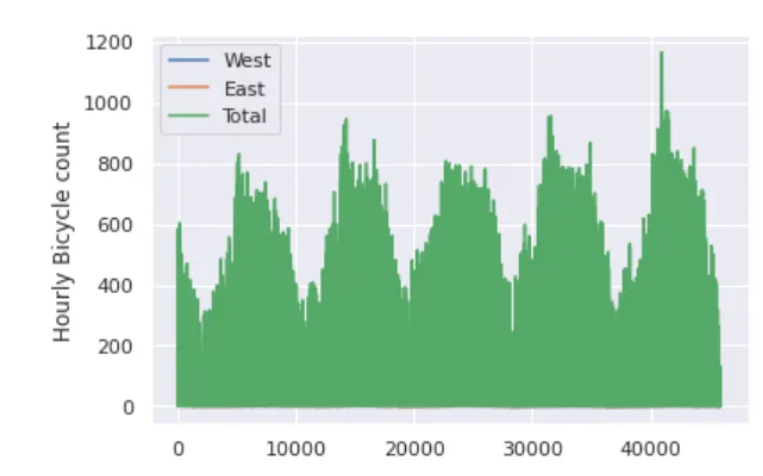
每小时约25000个样本的密度太大了,我们无法理解。我们可以通过将数据重新采样到一个粗糙的网格来获得更多的见解。让我们按周重新取样:
weekly = data.resample("W").sum()
weekly.plot(style=[':', '--', '-'])
plt.ylabel('Weekly bicycle count')
plt.show()
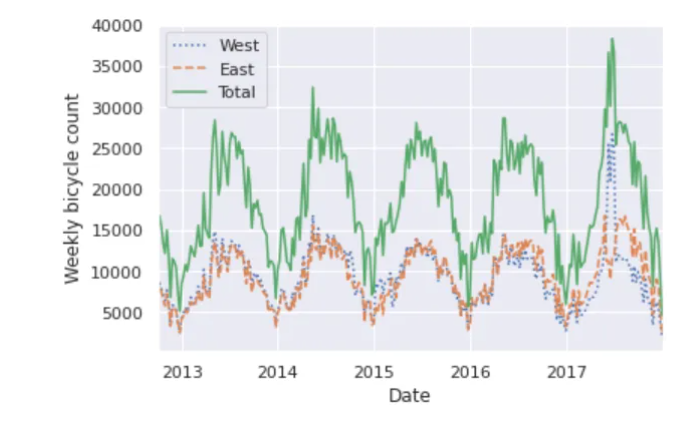
这向我们展示了一些有趣的季节趋势:如你所料,人们在夏天比在冬天骑自行车更多,甚至在一个特定的季节里,自行车的使用每周都不同。
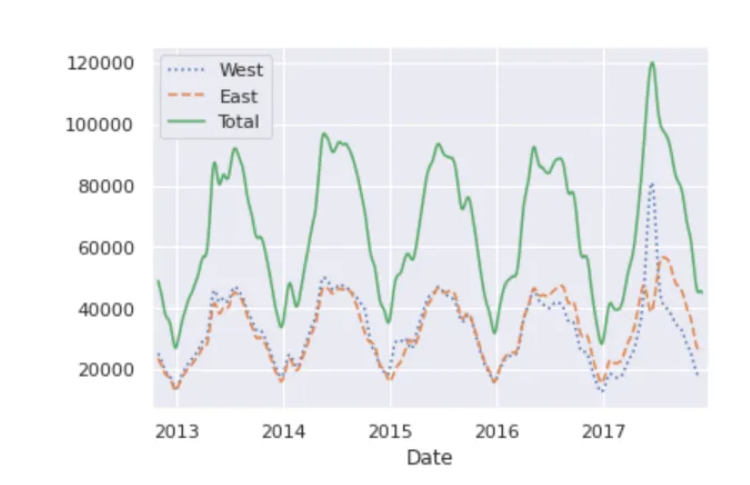
另一种便于聚合数据的方法是使用滚动平均数,利用pd.rolling_mean()函数。这里我们将对我们的数据做一个30天的滚动平均值,确保窗口居中:
daily = data.resample('D').sum()
daily.rolling(30, center=True).sum().plot(style=[':', '--', '-'])
plt.ylabel('mean hourly count')
plt.show()
结果的锯齿状是由于窗户的硬切断。我们可以使用窗口函数得到滚动均值的平滑版本——例如高斯窗。
daily.rolling(50, center=True,
win_type='gaussian').sum(std=10).plot(style=[':','--', '-'])
plt.show()
4.2 挖掘数据
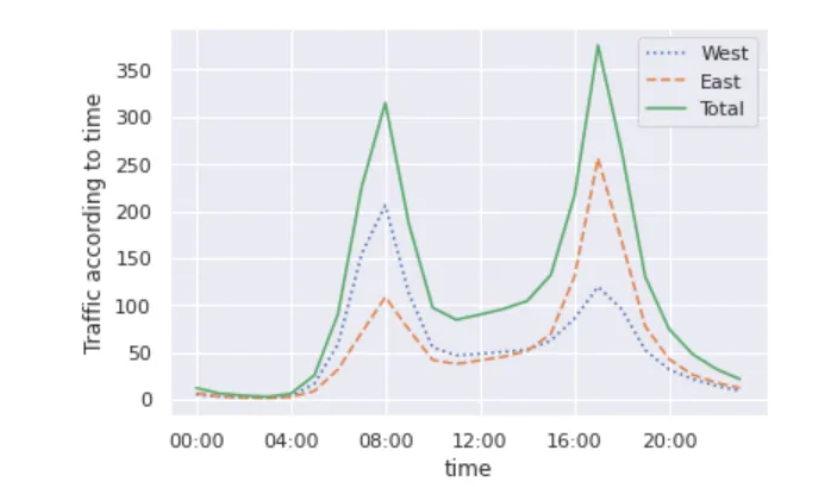
虽然平滑数据视图有助于了解数据的总体趋势,但它们隐藏了许多有趣的结构。例如,我们可能希望将平均流量看作是一天中时间的函数。我们可以使用GroupBy功能来做到这一点:
import numpy as np
by_time = data.groupby(data.index.time).mean()
hourly_ticks = 4 60 60 \* np.arange(6)
by_time.plot(xticks= hourly_ticks, style=[':', '--', '-'])
plt.ylabel("Traffic according to time")
plt.show()
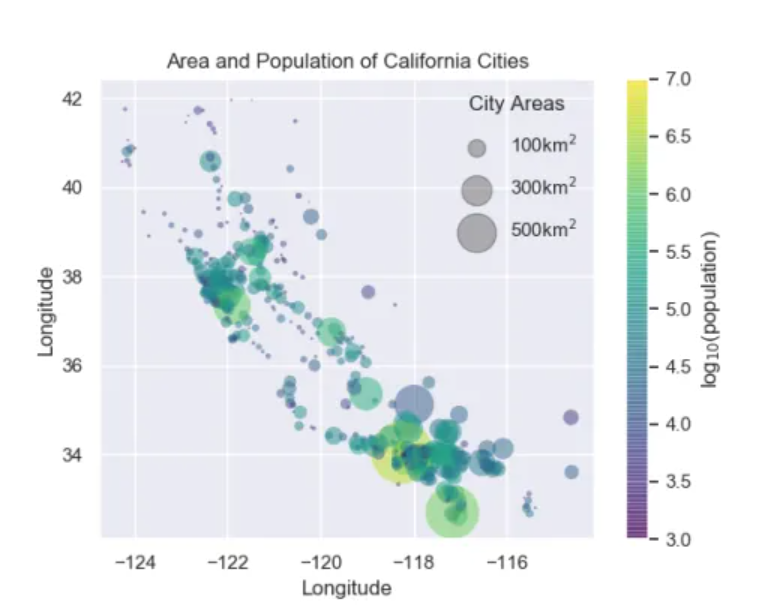
5.区域与人口分析
在这个项目中,我们将使用点的大小来指示加利福尼亚城市的面积和人口。我们想要一个指定点大小比例的图例,我们将通过绘制一些没有条目的标记数据来实现这一点。
您可以从此处下载此项目所需的数据集。
链接:https://pan.baidu.com/s/1_KoQ7zTT8fJpRYrxksr0aQ
提取码:guqw
import pandas as pd
cities = pd.read_csv("california\_cities.csv")
print(cities.head())

5.1 提取我们感兴趣的数据
latitude, longitude = cities["latd"], cities["longd"]
population, area = cities["population\_total"], cities["area\_total\_km2"]
5.2 分散点,使用尺寸和颜色,但不使用标签
import numpy as np
import matplotlib.pyplot as plt
import seaborn
seaborn.set()
plt.scatter(longitude, latitude, label=None, c=np.log10(population),
cmap='viridis', s=area, linewidth=0, alpha=0.5)
plt.axis(aspect='equal')
plt.xlabel('Longitude')
plt.ylabel('Longitude')
plt.colorbar(label='log(population)')
plt.clim(3, 7)
5.3 现在我们将创建一个图例,我们将绘制具有所需大小和标签的空列表
for area in [100, 300, 500]:
plt.scatter([], [], c='k', alpha=0.3, s=area, label=str(area) + 'km')
plt.legend(scatterpoints=1, frameon=False, labelspacing=1, title='City Areas')
plt.title("Area and Population of California Cities")
plt.show()
6.一个完整的Python机器学习项目实战
在本文中,我将带您完成一个使用Python编程语言的完整机器学习项目演练。这个完整的机器学习项目演练包括由Scikit-Learn提供的算法的实现,Scikit-Learn是用于机器学习的最佳Python库之一。
以下是本机器学习项目演练中涵盖的步骤:
- 导入数据
- 数据可视化
- 数据清理和转换
- 对数据进行编码
- 将数据拆分为训练和测试集
- 微调算法
- 使用KFold交叉验证
- 对测试集的预测
使用Python的机器学习项目演练
现在,在本节中,我将带您完成一个使用Python编程语言的完整机器学习项目演练。我将首先导入必要的Python库和数据集:
链接:https://pan.baidu.com/s/1ShfQd-ig8JhLqwigxfP_-g
提取码:3zgw
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
data_train = pd.read_csv('train.csv')
data_test = pd.read_csv('test.csv')
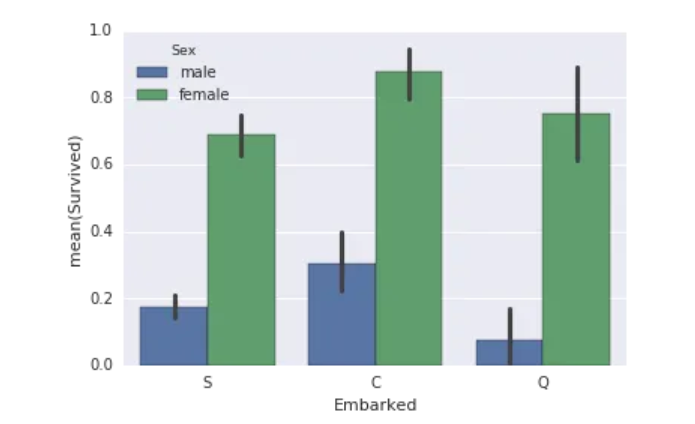
现在让我们看看如何可视化这些数据。数据可视化对于识别适当训练机器学习模型的基础模式至关重要:
sns.barplot(x="Embarked", y="Survived", hue="Sex", data=data_train)
plt.show()
6.1 数据清理和转换
现在下一步是根据我们需要的输出来清理和转换数据。以下是我将在此步骤中考虑的步骤:
- 为了避免过度匹配,我将把人们分成合乎逻辑的人类年龄组。
- 每个展位都以一封信开头。我打赌这封信比后面的数字大得多,让我们把它剪掉。
- 关税是另一个应该简化的连续值。
- 从 “名称” 函数中提取信息。我没有使用全名,而是提取了姓氏和名字前缀 (Mr,Mrs等),然后将它们添加为特征。
- 最后,我们需要删除不必要的功能。
def simplify\_ages(df):
df.Age = df.Age.fillna(-0.5)
bins = (-1, 0, 5, 12, 18, 25, 35, 60, 120)
group_names = ['Unknown', 'Baby', 'Child', 'Teenager', 'Student', 'Young Adult', 'Adult', 'Senior']
categories = pd.cut(df.Age, bins, labels=group_names)
df.Age = categories
return df
def simplify\_cabins(df):
df.Cabin = df.Cabin.fillna('N')
df.Cabin = df.Cabin.apply(lambda x: x[0])
return df
def simplify\_fares(df):
df.Fare = df.Fare.fillna(-0.5)
bins = (-1, 0, 8, 15, 31, 1000)
group_names = ['Unknown', '1\_quartile', '2\_quartile', '3\_quartile', '4\_quartile']
categories = pd.cut(df.Fare, bins, labels=group_names)
df.Fare = categories
return df
def format\_name(df):
df['Lname'] = df.Name.apply(lambda x: x.split(' ')[0])
df['NamePrefix'] = df.Name.apply(lambda x: x.split(' ')[1])
return df
def drop\_features(df):
return df.drop(['Ticket', 'Name', 'Embarked'], axis=1)
def transform\_features(df):
df = simplify_ages(df)
df = simplify_cabins(df)
df = simplify_fares(df)
df = format_name(df)
df = drop_features(df)
return df
data_train = transform_features(data_train)
data_test = transform_features(data_test)
6.2 编码特征
下一步是标准化标签。标签编码器将每个唯一的字符串转换为一个数字,使数据更加灵活,可用于各种算法。对人类来说,结果是一个可怕的数字数组,但对机器来说却很漂亮:
rom sklearn import preprocessing
def encode\_features(df_train, df_test):
features = ['Fare', 'Cabin', 'Age', 'Sex', 'Lname', 'NamePrefix']
df_combined = pd.concat([df_train[features], df_test[features]])
for feature in features:
le = preprocessing.LabelEncoder()
le = le.fit(df_combined[feature])
df_train[feature] = le.transform(df_train[feature])
df_test[feature] = le.transform(df_test[feature])
return df_train, df_test
data_train, data_test = encode_features(data_train, data_test)
现在下一步是将数据分成训练集和测试集。在这里,我将使用一个变量来存储所有特征减去我们想要预测的值,而另一个变量只存储我们想要预测的值。
对于这项任务,我将把这些数据随机混合成四个变量。在这种情况下,我训练80% 的数据,然后测试剩余的20%:
from sklearn.model_selection import train_test_split
X_all = data_train.drop(['Survived', 'PassengerId'], axis=1)
y_all = data_train['Survived']
num_test = 0.20
X_train, X_test, y_train, y_test = train_test_split(X_all, y_all, test_size=num_test, random_state=23)
6.3 拟合和调整机器学习算法:
现在是确定哪种算法将提供最佳模型的时候了。在此任务中,我将使用randomforest分类器,但是您也可以在此处使用任何其他分类器,例如支持向量机或朴素贝叶斯:
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import make_scorer, accuracy_score
from sklearn.model_selection import GridSearchCV
# Choose the type of classifier.
clf = RandomForestClassifier()
# Choose some parameter combinations to try
parameters = {'n\_estimators': [4, 6, 9],
'max\_features': ['log2', 'sqrt','auto'],
'criterion': ['entropy', 'gini'],
'max\_depth': [2, 3, 5, 10],
'min\_samples\_split': [2, 3, 5],
'min\_samples\_leaf': [1,5,8]
}
# Type of scoring used to compare parameter combinations
acc_scorer = make_scorer(accuracy_score)
# Run the grid search
grid_obj = GridSearchCV(clf, parameters, scoring=acc_scorer)
grid_obj = grid_obj.fit(X_train, y_train)
# Set the clf to the best combination of parameters
clf = grid_obj.best_estimator_
# Fit the best algorithm to the data.
clf.fit(X_train, y_train)
RandomForestClassifier(bootstrap=True, class_weight=None, criterion='entropy',
max_depth=5, max_features='log2', max_leaf_nodes=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, n_estimators=9, n_jobs=1,
oob_score=False, random_state=None, verbose=0,
warm_start=False)
predictions = clf.predict(X_test)
print(accuracy_score(y_test, predictions))
0.804469273743
现在我们需要使用KFold交叉验证来验证我们的机器学习模型。KFold交叉验证有助于理解我们的模型好吗?这使得使用KFold验证算法的效率成为可能。这将把我们的数据分成10个隔间,然后使用不同的隔间作为每次迭代的测试集来运行算法:
from sklearn.cross_validation import KFold
def run\_kfold(clf):
kf = KFold(891, n_folds=10)
outcomes = []
fold = 0
for train_index, test_index in kf:
fold += 1
X_train, X_test = X_all.values[train_index], X_all.values[test_index]
y_train, y_test = y_all.values[train_index], y_all.values[test_index]
clf.fit(X_train, y_train)
predictions = clf.predict(X_test)
accuracy = accuracy_score(y_test, predictions)
outcomes.append(accuracy)
print("Fold {0} accuracy: {1}".format(fold, accuracy))
mean_outcome = np.mean(outcomes)
print("Mean Accuracy: {0}".format(mean_outcome))
run_kfold(clf)
Fold 1 accuracy: 0.8111111111111111
Fold 2 accuracy: 0.8764044943820225
Fold 3 accuracy: 0.8089887640449438
Fold 4 accuracy: 0.8764044943820225
Fold 5 accuracy: 0.8314606741573034
Fold 6 accuracy: 0.8089887640449438
Fold 7 accuracy: 0.7865168539325843
Fold 8 accuracy: 0.7528089887640449
Fold 9 accuracy: 0.8764044943820225
Fold 10 accuracy: 0.8089887640449438
Mean Accuracy: 0.8238077403245943
6.4 测试模型
现在我们需要根据实际测试数据进行预测:
ids = data_test['PassengerId']
predictions = clf.predict(data_test.drop('PassengerId', axis=1))
output = pd.DataFrame({ 'PassengerId' : ids, 'Survived': predictions })
output.head()
PassengerId Survived
0 892 0
1 893 1
2 894 0
3 895 0
4 896 1
我希望你喜欢这篇关于初学者的完整机器学习项目演练的文章。
7.使用Python进行文本摘要
文本摘要是创建包含原文最重要信息的特定文档摘要的过程,其目的是获得文档要点的摘要。在本文中,我将向您介绍一个关于Python文本摘要的机器学习项目。
7.1 文本摘要

有大量的数据以数字方式显示,因此有必要开发一种独特的程序来立即总结长文本,同时保持主要思想。文本摘要还可以缩短阅读时间,加快信息搜索速度,并获得尽可能多的关于一个主题的信息。
使用机器学习进行文本摘要的主要目标是将参考文本简化为较小的版本,同时保持其知识和含义。提供了多个文本摘要描述,例如,将报告解释为从一个或多个文档生成的文本,这些文档在第一个文本中传达了相关知识,这不超过正文的一半,通常比这更有限。

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
以数字方式显示,因此有必要开发一种独特的程序来立即总结长文本,同时保持主要思想。文本摘要还可以缩短阅读时间,加快信息搜索速度,并获得尽可能多的关于一个主题的信息。
使用机器学习进行文本摘要的主要目标是将参考文本简化为较小的版本,同时保持其知识和含义。提供了多个文本摘要描述,例如,将报告解释为从一个或多个文档生成的文本,这些文档在第一个文本中传达了相关知识,这不超过正文的一半,通常比这更有限。
[外链图片转存中…(img-ve1dGRMS-1715642796148)]
[外链图片转存中…(img-iFkxFi8E-1715642796149)]
[外链图片转存中…(img-uq5mplT0-1715642796149)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









