







文章目录
介绍
并查集是一种可以动态维护若干个不重叠的集合,并支持合并与查询的数据结构。详细来说,并查集包括以下两个基本操作:
- find(),查询一个元素属于哪个集合。
- mergo,把两个集合合并为一个大集合。
并查集实际上就是处理具有关联关系的问题。比如给定若干对物品之间的关系,然后判断那一对关系是错的。
那么并查集该如何实现呢?
要实现并查集,就要从实际出发,想办法实现以上两个功能。 如果我们想要将若干个物品归为一类,我们可以令其同时等于一个元素,这样,当我们判断两个物品是否是同一类时,只需要查询两个物品是否都等于同一个元素即可。
为实现以上思路,我们可以建一个树形数据结构,每一棵树代表一个种类,每个节点的权值代表该节点,一个指针代表其父节点,然后我们查询该物品所属的种类时,通过递归父节点直到根节点,然后根节点就代表这棵树的种类,此时返回根节点。这是最基础直观的思路,但是我们仔细思考就会发现,单纯按照这种思路实现,那么每进行一次查找都要递归到子节点,时间复杂度较高,那么我们就需要考虑优化。
路径压缩
我们考虑用路径压缩来降低时间复杂度。什么是路径压缩?
既然同一棵树上的节点的类型都是根节点,那么我们可不可以将同一棵树上节点的父节点都直接指向根节点,那么每次查询的时间复杂度都只有
O
(
1
)
O(1)
O(1)。既然我们建树来将同一类物品放在一起,并将根节点作为这棵树的种类,那么树的具体形态也就不重要了,只要其父节点能通过递归指向根节点就行(而且递归层数越少越好)。我们就可以将树进行如下图转换:
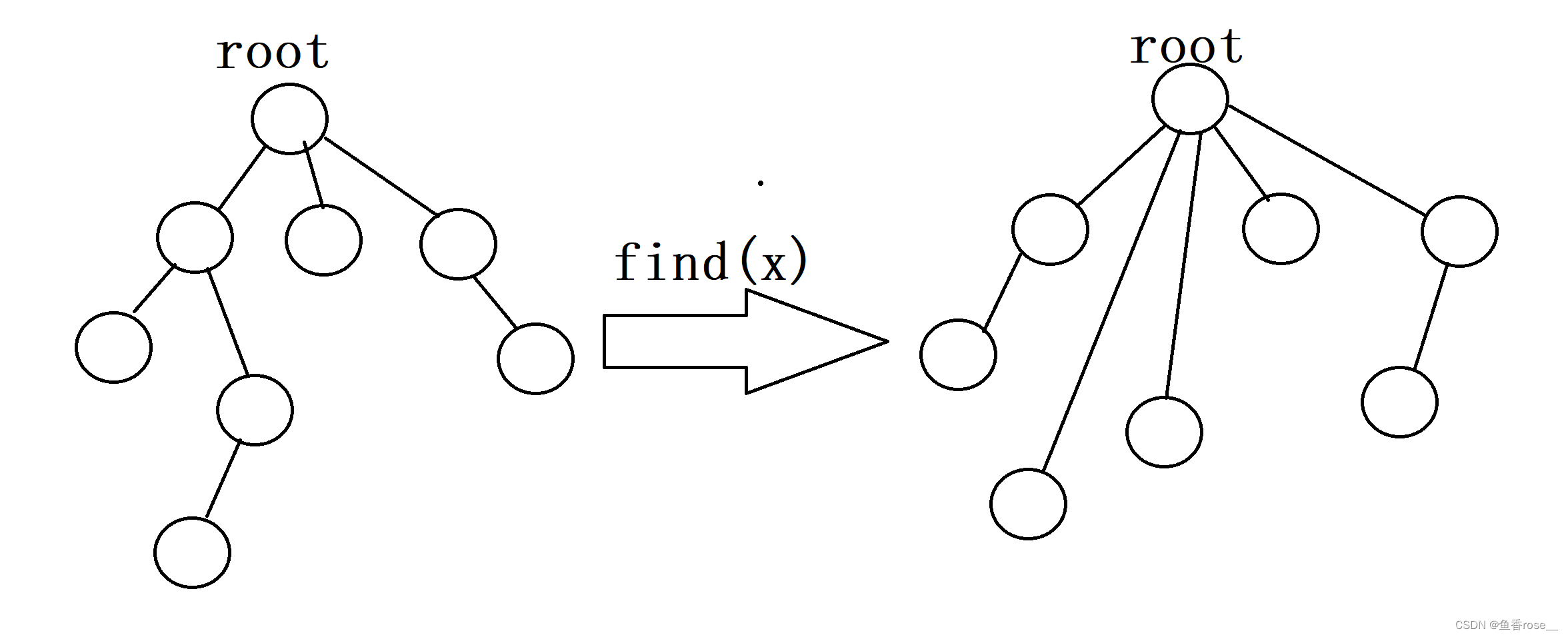
因此,我们在每次执行find操作的同时,把访问过的节点(也就是所查询元素的全部祖先)都直接指向树根,即把上图中左边那棵树变成右边那棵树。这种优化方法被称为路径压缩。采用路径压缩优化的并查集,每次find操作的均摊复杂度为
O
(
l
o
g
N
)
O(logN)
O(logN)。
实现
- 并查集的储存
使用一个数组 f a fa fa保存父节点(根节点的父节点设为自己)
int fa[N]; - 并查集的初始化
设有 n n n个元素,起初所有元素各自构成一个独立的集合,即有 n n n棵1个点的树。
for(int i = 1; i <= n; i ++ ) fa[i] = i; - 并查集的find操作
若 x x x是树根,则 x x x就是集合代表,否则递归访问 f a [ x ] fa[x] fa[x]直至根节点。
int find(int x) {
if(x == fa[x]) return x;
return fa[x] = find(fa[x]);
}
- 并查集的merge操作
合并元素 x x x、 y y y所在的集合,等价于让 x x x的树根作为 y y y的树根的子节点。
void merge(int x, int y) {
fa[find(x)] = find(y);
}
扩展域与边带权的并查集
并查集实际上是由若干棵树构成的森林,我们可以在树中的每条边上记录一个权值,即维护一个数组 d d d,用 d [ x ] d[x] d[x]保存节点 x x x到父节点 f a [ x ] fa[x] fa[x]之间的边权。在每次路径压缩后,每个访问过的节点都会直接指向树根,如果我们同时更新这些节点的 d d d值,就可以利用路径压缩过程来统计每个节点到树根之间的路径上的一些信息。这就是所谓“边带权”的并查集。
通过对上面函数的修改,可以实现每个节点到根节点的距离。
int find(int x) {
if(x == fa[x]) return x;
int root = find(fa[x]); //递归计算集合代表
d[x] += d[fa[x]]; //维护d数组--对边权求和
return fa[x] = root;
}














 1598
1598











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









