







长短期记忆网络(LSTM)
长短期记忆网络
- 忘记门:将值朝 0 减少
- 输入门:决定不是忽略掉输入数据
- 输出门:决定是不是使用隐状态
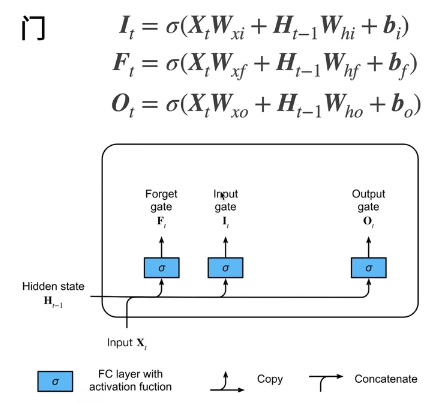
门
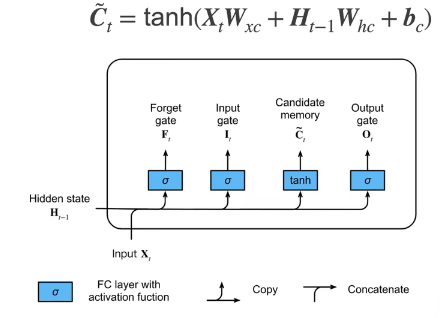
候选记忆单元
记忆单元
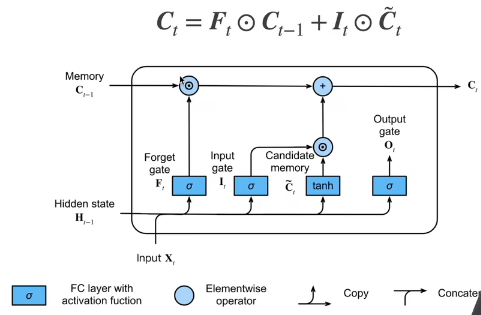
上面的这个公式,右侧的两个相加,可以得到
C
t
C_t
Ct 在
[
−
2
,
2
]
[-2,2]
[−2,2] 之间。
隐状态
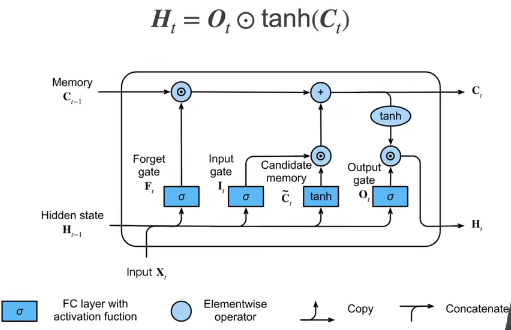
要是我想让
H
t
H_t
Ht 在
[
−
1
,
1
]
[-1,1]
[−1,1] 之间的话,需要再做一次
t
a
n
h
tanh
tanh 。
总结
I t = σ ( X t W x i + H t − 1 W h i + b i ) I_t = \sigma(X_t W_{xi} + H_{t-1} W_{hi} + b_i) It=σ(XtWxi+Ht−1Whi+bi)
F t = σ ( X t W x f + H t − 1 W h f + b f ) F_t = \sigma(X_t W_{xf} + H_{t-1} W_{hf} + b_f) Ft=σ(XtWxf+Ht−1Whf+bf)
O t = σ ( X t W x o + H t − 1 W h o + b o ) O_t = \sigma(X_t W_{xo} + H_{t-1} W_{ho} + b_o) Ot=σ(XtWxo+Ht−1Who+bo)
C ~ t = tanh ( X t W x c + H t − 1 W h c + b c ) \tilde{C}_t = \tanh(X_t W_{xc} + H_{t-1} W_{hc} + b_c) C~t=tanh(XtWxc+Ht−1Whc+bc)
C t = F t ⊙ C t − 1 + I t ⊙ C ~ t C_t = F_t \odot C_{t-1} + I_t \odot \tilde{C}_t Ct=Ft⊙Ct−1+It⊙C~t
H t = O t ⊙ tanh ( C t ) H_t = O_t \odot \tanh(C_t) Ht=Ot⊙tanh(Ct)
代码实现
首先还是导入必要的环境和所需的数据集:
import torch
from torch import nn
from d2l import torch as d2l
batch_size, num_steps = 32, 35
train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps)
接着就是初始化模型参数,按照标准差 0.01 0.01 0.01 的高斯分布初始化权重,并将偏置项设为 0 0 0。
def get_lstm_params(vocab_size, num_hiddens, device):
num_inputs = num_outputs = vocab_size
def normal(shape):
return torch.randn(size=shape, device=device)*0.01
def three():
return (normal((num_inputs, num_hiddens)),
normal((num_hiddens, num_hiddens)),
torch.zeros(num_hiddens, device=device))
W_xi, W_hi, b_i = three() # 输入门参数
W_xf, W_hf, b_f = three() # 遗忘门参数
W_xo, W_ho, b_o = three() # 输出门参数
W_xc, W_hc, b_c = three() # 候选记忆元参数
# 输出层参数
W_hq = normal((num_hiddens, num_outputs))
b_q = torch.zeros(num_outputs, device=device)
# 附加梯度
params = [W_xi, W_hi, b_i, W_xf, W_hf, b_f, W_xo, W_ho, b_o, W_xc, W_hc,
b_c, W_hq, b_q]
for param in params:
param.requires_grad_(True)
return params
下面初始化函数,与之前的 RNN,LSTM 不一样的地方在于,这里有两个 zero 了。形状为(批量大小,隐藏单元数)
def init_lstm_state(batch_size, num_hiddens, device):
return (torch.zeros((batch_size, num_hiddens), device=device),
torch.zeros((batch_size, num_hiddens), device=device))
实际模型的定义与前面讨论的一样:提供三个门和一个额外的记忆元。但是,只有隐状态才会传递到输出层,而记忆元 C t \mathbf{C}_t Ct不直接参与输出计算。
def lstm(inputs, state, params):
[W_xi, W_hi, b_i, W_xf, W_hf, b_f, W_xo, W_ho, b_o, W_xc, W_hc, b_c,
W_hq, b_q] = params
(H, C) = state
outputs = []
for X in inputs:
I = torch.sigmoid((X @ W_xi) + (H @ W_hi) + b_i)
F = torch.sigmoid((X @ W_xf) + (H @ W_hf) + b_f)
O = torch.sigmoid((X @ W_xo) + (H @ W_ho) + b_o)
C_tilda = torch.tanh((X @ W_xc) + (H @ W_hc) + b_c)
C = F * C + I * C_tilda
H = O * torch.tanh(C)
Y = (H @ W_hq) + b_q
outputs.append(Y)
return torch.cat(outputs, dim=0), (H, C)
训练
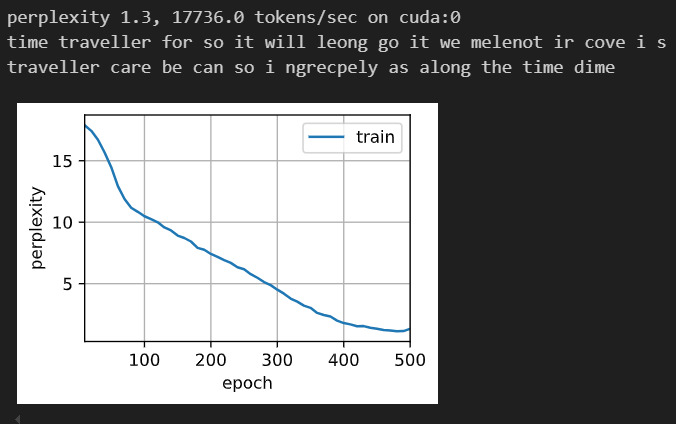
vocab_size, num_hiddens, device = len(vocab), 256, d2l.try_gpu()
num_epochs, lr = 500, 1
model = d2l.RNNModelScratch(len(vocab), num_hiddens, device, get_lstm_params,
init_lstm_state, lstm)
d2l.train_ch8(model, train_iter, vocab, lr, num_epochs, device)
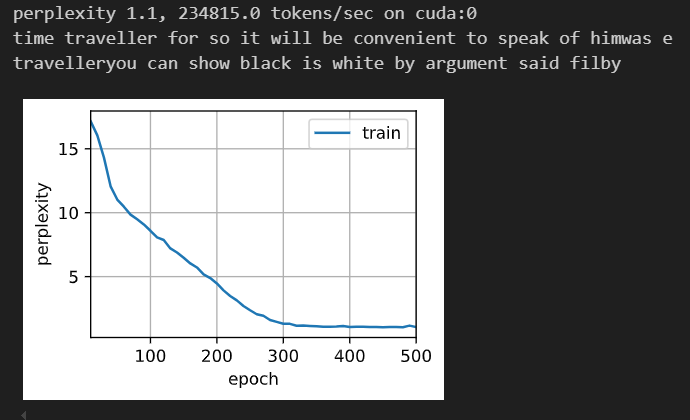
简洁实现:
num_inputs = vocab_size
lstm_layer = nn.LSTM(num_inputs, num_hiddens)
model = d2l.RNNModel(lstm_layer, len(vocab))
model = model.to(device)
d2l.train_ch8(model, train_iter, vocab, lr, num_epochs, device)
长短期记忆网络是典型的具有重要状态控制的隐变量自回归模型。多年来已经提出了其许多变体,例如,多层、残差连接、不同类型的正则化。然而,由于序列的长距离依赖性,训练长短期记忆网络和其他序列模型(例如门控循环单元)的成本是相当高的。因此,后面 Transformer 横空出世。
小结
- 长短期记忆网络有三种类型的门:输入门、遗忘门和输出门。
- 长短期记忆网络的隐藏层输出包括 “ 隐状态 ” 和 “ 记忆元 ” 。只有隐状态会传递到输出层,而记忆元完全属于内部信息。
- 长短期记忆网络可以缓解梯度消失和梯度爆炸。
QA 思考
1. 调整和分析超参数对运行时间、困惑度和输出顺序的影响。
答案:
超参数的调整对LSTM模型的训练效率、性能及输出质量有重要影响,主要包括以下几个方面:
-
学习率(Learning Rate):
- 过大:可能导致模型无法收敛,增加运行时间和不稳定的困惑度。
- 过小:训练缓慢,收敛速度慢,可能陷入局部最优。
-
批量大小(Batch Size):
- 增加批量大小通常会加快每轮(epoch)训练速度,但可能需要更多内存。
- 小批量有助于更好的泛化能力,但会增加训练总时间。
-
隐藏层维度(Hidden Size):
- 更大的维度能提升模型表达能力,降低困惑度,但也显著增加计算量。
- 可能导致过拟合,特别是在数据较少时。
-
层数(Number of Layers):
- 多层结构可能提高模型表现,但也会明显增加训练与推理时间。
- 深度增加还可能导致梯度传播困难(即使使用 LSTM 也可能发生)。
-
序列长度(Sequence Length):
- 更长的序列有助于模型学习长期依赖,但也增加了每次前向/反向传播的计算负担。
- 对于基于字符的任务,更长的序列可能会改变输出顺序的准确性。
2. 如何更改模型以生成适当的单词,而不是字符序列?
答案:
要从字符级别的文本生成转变为单词级别的文本生成,需进行以下修改:
(1) 数据预处理
- 使用分词器(如 NLTK、spaCy 或 BPE 编码)将原始文本切分为单词或子词单元。
- 构建词汇表(vocabulary),将每个单词映射为一个唯一的整数索引。
from torchtext.vocab import build_vocab_from_iterator
def yield_tokens(data_iter):
for text in data_iter:
yield tokenize(text)
vocab = build_vocab_from_iterator(yield_tokens(train_data), specials=["<unk>"])
(2) 输入嵌入层
- 在模型中加入
nn.Embedding层,将单词索引映射为稠密向量。
embedding = nn.Embedding(num_embeddings=len(vocab), embedding_dim=256)
(3) 输出层调整
- 输出不再是字符空间的概率分布,而是词汇表大小的概率分布。
- 最终输出层改为线性层,输出维度为
len(vocab)。
output_layer = nn.Linear(hidden_size, len(vocab))
(4) 解码策略
- 使用贪婪解码或采样方式生成下一个词语,而不是字符。
- 可引入 Beam Search 提高生成质量。
3. 在给定隐藏层维度的情况下,比较门控循环单元、长短期记忆网络和常规循环神经网络的计算成本。要特别注意训练和推断成本。
答案:
| 模型 | 参数数量 | 计算复杂度(训练 & 推理) | 特点 |
|---|---|---|---|
| RNN | O ( d ⋅ d ) O(d \cdot d) O(d⋅d) | 低 | 简单但容易出现梯度消失,难以捕捉长期依赖 |
| GRU | O ( 3 ⋅ d ⋅ d ) O(3 \cdot d \cdot d) O(3⋅d⋅d) | 中等 | 包含重置门和更新门,运算比 LSTM 略快,适合资源有限场景 |
| LSTM | O ( 4 ⋅ d ⋅ d ) O(4 \cdot d \cdot d) O(4⋅d⋅d) | 高 | 引入遗忘门、输入门、输出门,功能更强,但计算开销更大 |
说明:
- 设隐藏状态维度为 d d d,输入维度也为 d d d。
- RNN 的权重矩阵只有一套,而 GRU 和 LSTM 分别有三组和四组门控参数。
- 因此,在相同维度下,LSTM 的参数最多,GRU 其次,RNN 最少。
- 结果是:LSTM > GRU > RNN,在训练和推理时计算成本依次递减。
实际影响:
- 训练成本:LSTM 收敛较慢,训练时间最长;RNN 虽然训练快,但效果差。
- 推理成本:LSTM 推理速度最慢,但对长序列任务准确率更高;GRU 平衡了速度与性能。
4. 既然候选记忆元通过使用 tanh \tanh tanh 函数来确保值范围在 ( − 1 , 1 ) (-1,1) (−1,1) 之间,那么隐状态需要再次使用 tanh \tanh tanh 函数来确保输出值范围在 ( − 1 , 1 ) (-1,1) (−1,1) 之间呢?
答案:
虽然候选记忆元已经经过了 tanh \tanh tanh,但隐状态再次使用 tanh \tanh tanh 是为了进一步筛选和标准化最终输出的表示。具体原因如下:
-
记忆元 vs 隐状态的功能不同:
- 记忆元是长期存储的信息管道,其值应尽量保持稳定,便于跨时间步传递。
- 隐状态是当前时刻的输出,用于后续预测或作为下一时刻的输入,因此需要具有良好的数值稳定性。
-
输出门控制信息流比例:
- 输出门由 sigmoid 函数产生一个介于 0 到 1 的值,表示有多少记忆元内容应该被输出。
- 若直接使用记忆元输出,则未经过非线性激活,可能出现超出 ( − 1 , 1 ) (-1,1) (−1,1) 范围的情况。
-
tanh \tanh tanh 的作用:
- 再次应用 tanh \tanh tanh 可以保证隐状态的值始终处于 ( − 1 , 1 ) (-1,1) (−1,1) 之间,防止数值爆炸。
- 同时也增强了模型的非线性表达能力。
公式回顾:
h
t
=
o
t
⊙
tanh
(
c
t
)
h_t = o_t \odot \tanh(c_t)
ht=ot⊙tanh(ct)
其中
o
t
o_t
ot 是输出门的结果,
tanh
(
c
t
)
\tanh(c_t)
tanh(ct) 是对整个记忆元状态做非线性变换后的结果。
因此,双重 tanh \tanh tanh 的设计是为了分别满足记忆元的稳定性与输出表示的规范化需求。
5. 实现一个能够基于时间序列进行预测而不是基于字符序列进行预测的长短期记忆网络模型。
答案:
下面是一个基于 PyTorch 实现的时间序列预测用 LSTM 模型示例:
import torch
import torch.nn as nn
class LSTMTimeseries(nn.Module):
def __init__(self, input_size=1, hidden_size=64, num_layers=2, output_size=1):
super(LSTMTimeseries, self).__init__()
self.lstm = nn.LSTM(input_size=input_size,
hidden_size=hidden_size,
num_layers=num_layers,
batch_first=True)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x):
# x shape: [batch_size, seq_len, input_size]
out, _ = self.lstm(x) # out shape: [batch_size, seq_len, hidden_size]
out = self.fc(out[:, -1, :]) # 取最后一个时间步的输出进行预测
return out
关键点解释:
- 输入形状为
[batch_size, sequence_length, input_size]:input_size=1表示每个时间步只有一个特征,如温度、股价等。
- LSTM 层处理序列输入并输出隐藏状态。
- **全连接层(fc)**将最后一个时间步的隐藏状态映射到输出值(如未来某时刻的预测值)。
示例训练流程(略简化):
model = LSTMTimeseries()
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
for epoch in range(100):
for X_batch, y_batch in train_loader:
outputs = model(X_batch)
loss = criterion(outputs, y_batch)
optimizer.zero_grad()
loss.backward()
optimizer.step()
该模型适用于股票价格预测、天气预报、IoT传感器数据分析等领域。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









