







这篇文章是关于指针与数组的
目录
1. 数组名的理解
int arr[10] = {1,2,3,4,5,6,7,8,9,10};
int *p = &arr[0];这⾥我们使⽤ &arr[0] 的方式拿到了数组第⼀个元素的地址,但是其实数组名本来就是地址,而且
是数组首元素的地址,我们来做个测试。
#include <stdio.h>
int main()
{
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
printf("&arr[0] = %p\n", &arr[0]);
printf("arr = %p\n", arr);
return 0;
}结果
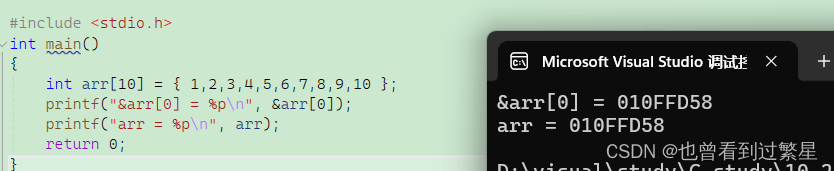
这里能看出来数组名和数组首元素的地址打印出的结果⼀模⼀样,数组名就是数组⾸元素(第⼀个元素)的地址。
sizeof(数组名),sizeof中单独放数组名,这⾥的数组名表示整个数组,计算的是整个数组的大小,
单位是字节
&数组名,这⾥的数组名表示整个数组,取出的是整个数组的地址(整个数组的地址和数组首元素
的地址是有区别的)
除此之外,任何地⽅使⽤数组名,数组名都表示首元素的地址
下面有一组数据
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
printf("&arr[0] = %p\n", &arr[0]);
printf("arr = %p\n", arr);
printf("&arr = %p\n", &arr);这组数据打印的地址是一样的
区别
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
printf("&arr[0] = %p\n", &arr[0]);
printf("&arr[0]+1 = %p\n", &arr[0]+1);
printf("arr = %p\n", arr);
printf("arr+1 = %p\n", arr+1);
printf("&arr = %p\n", &arr);
printf("&arr+1 = %p\n", &arr+1);结果
&arr[0] = 0077F820//原地址
&arr[0]+1 =0077F824 //+1之后
arr = 0077F820 //原地址
arr+1 = 0077F824 //+1之后
&arr = 0077F820 //原地址
&arr+1 = 0077F848 //+1之后这里 &arr[0] 和 &arr[0]+1 相差4个字节, arr和arr+1相差4个字节,
是因为&arr[0]和arr都是首元素元素的地址,+1就是跳过⼀个元素
但是&arr和&arr+1相差40个字节,这就是因为&arr是数组的地址,+1操作是跳过整个数组的。
到这里大家应该搞清楚数组名的意义了吧
2. 使用指针访问数组
#include <stdio.h>
int main()
{
int arr[10] = {0};
//输⼊
int i = 0;
int sz = sizeof(arr)/sizeof(arr[0]);
//输⼊
int* p = arr;
for(i=0; i<sz; i++)
{
scanf("%d", p+i);
//scanf("%d", arr+i);//也可以这样写
}
//输出
for(i=0; i<sz; i++)
{
printf("%d ", *(p+i));
}
return 0;
}将*(p+i)换成p[i]也是能够正常打印的,所以本质上p[i]是等价于*(p+i)。
同理arr[i]应该等价于*(arr+i),数组元素的访问在编译器处理的时候,也是转换成⾸元素的地址+偏移量求出元素的地址,然后解引用来访问的。
3. ⼀维数组传参的本质
把数组传给⼀个函数后,函数内部求数组的元素个数!
#include <stdio.h>
void test(int arr[])
{
int sz2 = sizeof(arr)/sizeof(arr[0]);
printf("sz2 = %d\n", sz2);
}
int main()
{
int arr[10] = {1,2,3,4,5,6,7,8,9,10};
int sz1 = sizeof(arr)/sizeof(arr[0]);
printf("sz1 = %d\n", sz1);
test(arr);
return 0;
}输出结果:
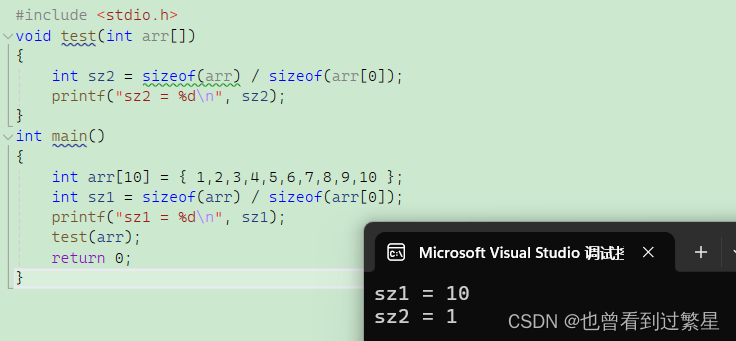
在函数内部是没有正确获得数组的元素个数!!
这就要学习数组传参的本质了
在指针(1)里面了解了数组名是数组⾸元素的地址;
那么在数组传参的时候,传递的是数组名,也就是说本质上数组传参传递的是数组首元素的地址。
所以函数形参的部分理论上应该使⽤指针变量来接收首元素的地址。那么在函数内部我们写
sizeof(arr) 计算的是⼀个地址的大小(单位字节)而不是数组的大小(单位字节)。正是因为函
数的参数部分是本质是指针,所以在函数内部是没办法求的数组元素个数的。
void test(int arr[])//参数写成数组形式,本质上还是指针
{
printf("%d\n", sizeof(arr));
}
void test(int* arr)//参数写成指针形式
{
printf("%d\n", sizeof(arr));//计算⼀个指针变量的⼤⼩
}
int main()
{
int arr[10] = {1,2,3,4,5,6,7,8,9,10};
test(arr);
return 0;
}总结:⼀维数组传参,形参的部分可以写成数组的形式,也可以写成指针的形式。
4.冒泡排序
冒泡排序的核心思想就是:两两相邻的元素进行比较
如果不满足顺序就交换,满足顺序就找下一对
图片演示
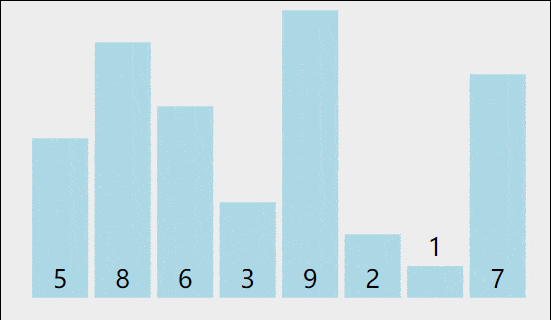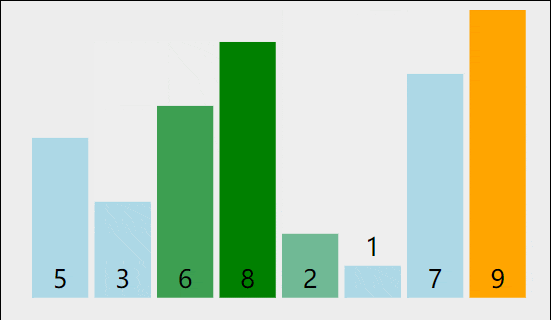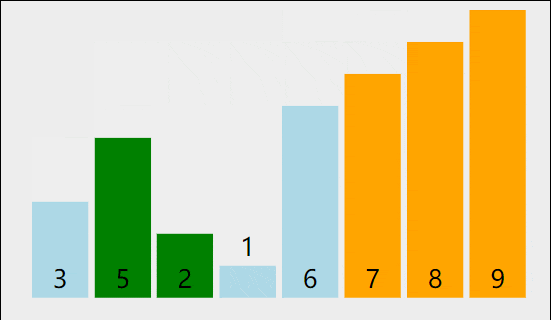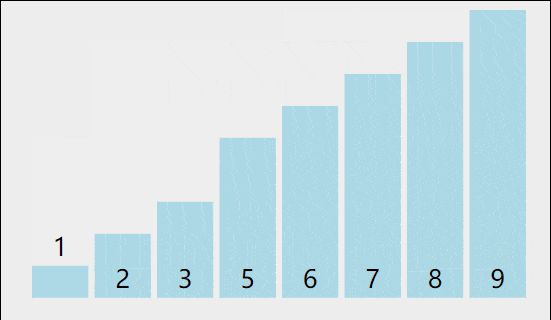
比如说一个元素个数为8的整形数组要进行冒泡排序,我们想让小的数字排在左面,那么比较中小的数字应该和大的数字进行交换,相邻的数组进行比较,那么进行一次比较后,数组应该是
也就是5和8进行调换,进行第二次比较,比较8和6,,那么当这一轮比较完的时候,数组应该是
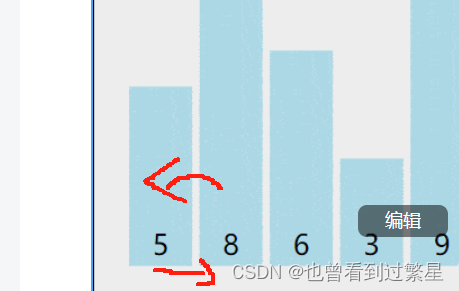
最后因为1>0所以不发生交换,在这一轮交换中,我们将最小的数字排在了最右面,现在要进入第二轮比较,由于最小的数字已经排在了最有面,所以第二轮只需要比较9个数字,以此类推,十个元素的数组一共需要比较9轮,每轮比较的元素个数依次减少。
代码如下
#include<stdio.h>
void bubble_sort(int arr[], int sz)
{
int i = 0, j = 0;
for (i = 0; i < sz; i++)
{
for (j = 0; j < sz - 1 - i; j++)
{
if (arr[j] < arr[j + 1])
{
arr[j] = arr[j] + arr[j + 1];
arr[j + 1] = arr[j] - arr[j + 1];
arr[j] = arr[j] - arr[j + 1];
}
}
}
}
int main()
{
int arr[8] = {5,8,6,3,9,2,1,7 };
int sz = sizeof(arr) / sizeof(arr[0]);
printf("排序前\n");
for (int i = 0; i < sz; i++)
{
printf("%d ", arr[i]);
}
printf("\n");
bubble_sort(arr, sz);
printf("排序后\n");
for (int i = 0; i < sz; i++)
{
printf("%d ", arr[i]);
}
return 0;
}结果
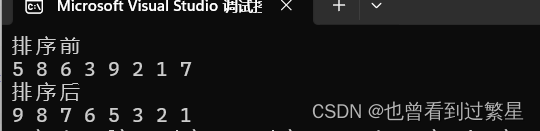
对于冒泡排序函数内的外层i循环,是为了达到sz-1轮循环,而内层的j循环,是为了每轮的比较,其中,sz-1是因为每次比较时都是相邻的两个数字进行比较,遍历数组时只需要到倒数第二个元素就可以,而倒数第二个元素的下标为sz-2,在此基础上-i是因为随着循环的轮数增加,每轮进行比较的元素个数也会减少。
那么这样一个简单的冒泡排序就写好了。















 11万+
11万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









