







文章目录
课程
- SPMD:单程序多数据,启动一个可执行文件,可能涉及多个相同的线程,每个线程处理一组数据,这多个线程之间是并行的
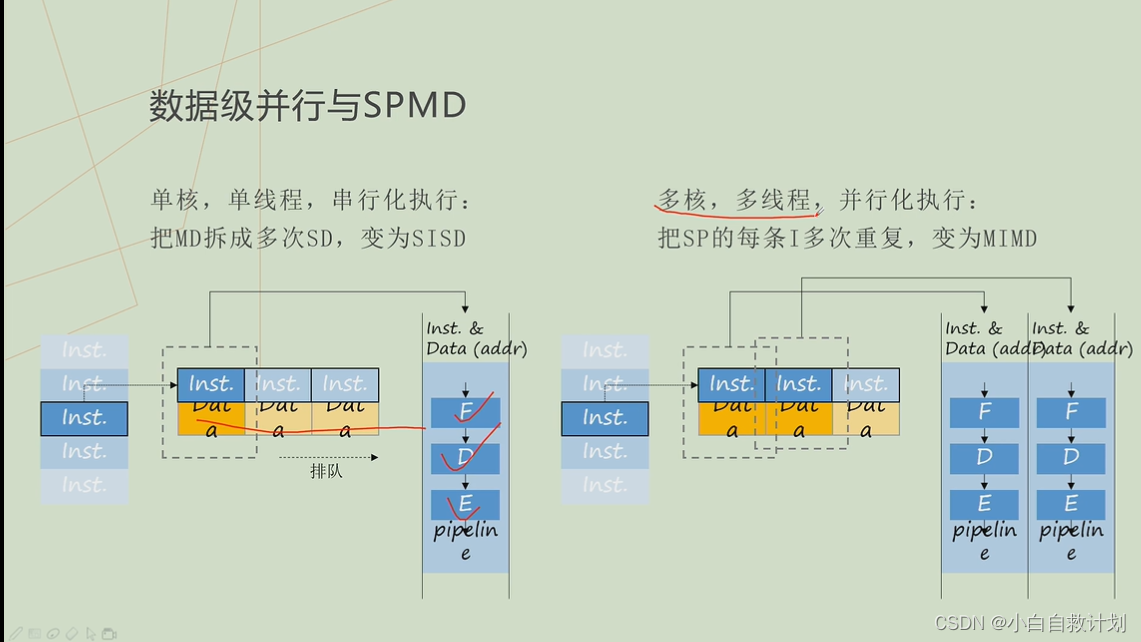 - SISD耗时,MIMD耗电
- SISD耗时,MIMD耗电 

- Fetch:qu取指令,Decode:指令译码


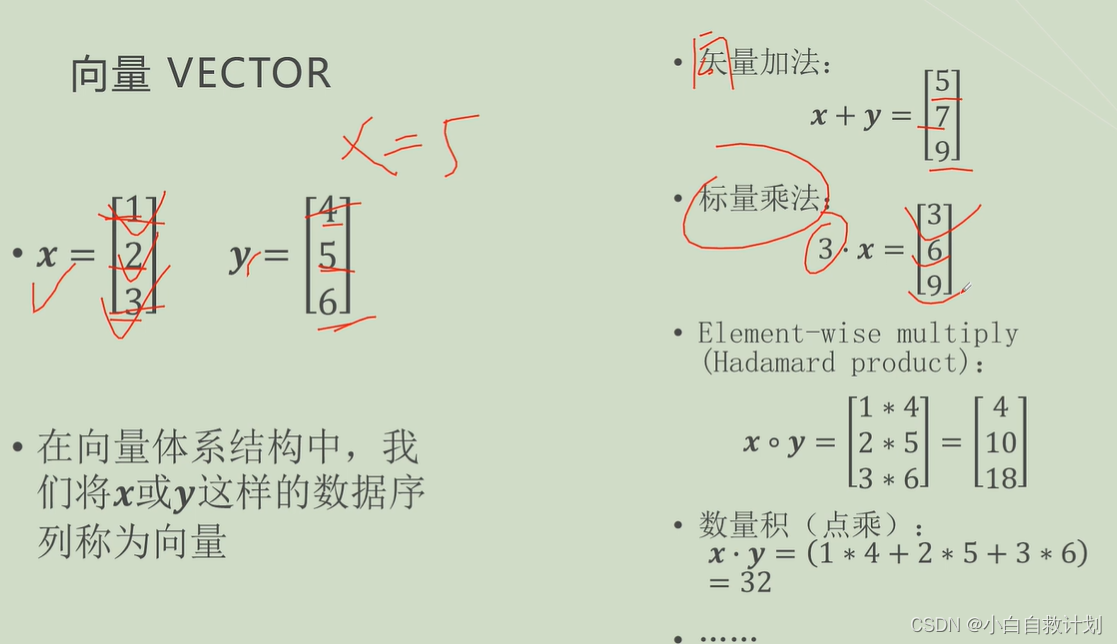

效率低


- 定义的向量长度超过硬件向量寄存器的长度

-
在向量体系结构中用纵向处理比较多,(长度不够用纵横处理)

-
‘Power Wall’(功耗墙)是指功耗的限制


- add.d:加法,double(双精度)
- addvv.d(V1,V2,V3),vv表示向量和向量,V1是结果,V2V3是两个操作数
- vs表示向量和标量




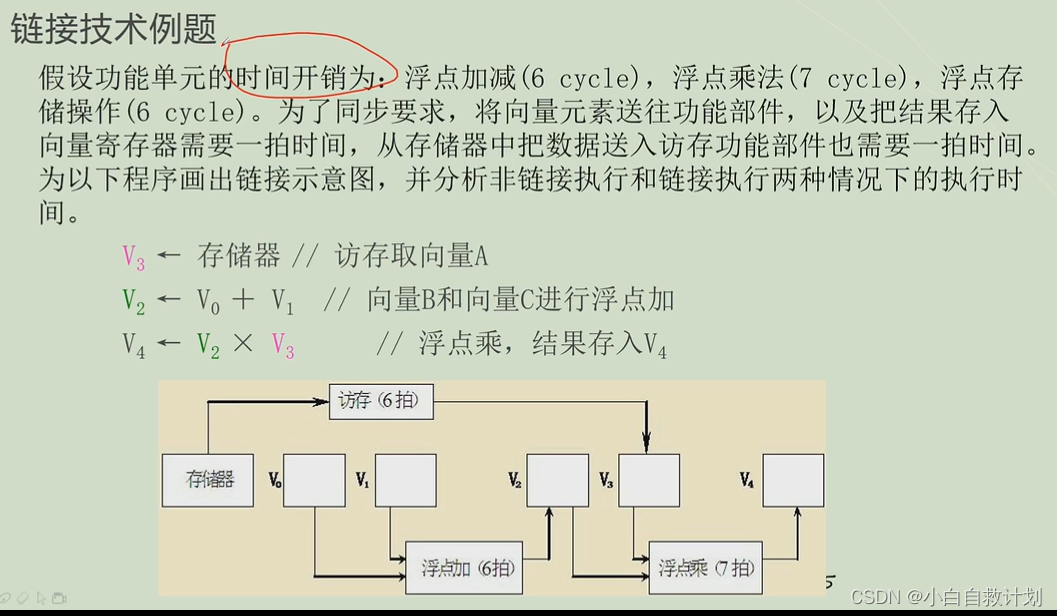
假设串行执行:执行完一条指令才能执行第二条
有n条数据
不链接前二并行: 1+6+1+n-1+1+7+1+n-1
链接执行前二并,执行时间1+6+1+1+7+1+n-1

很重要




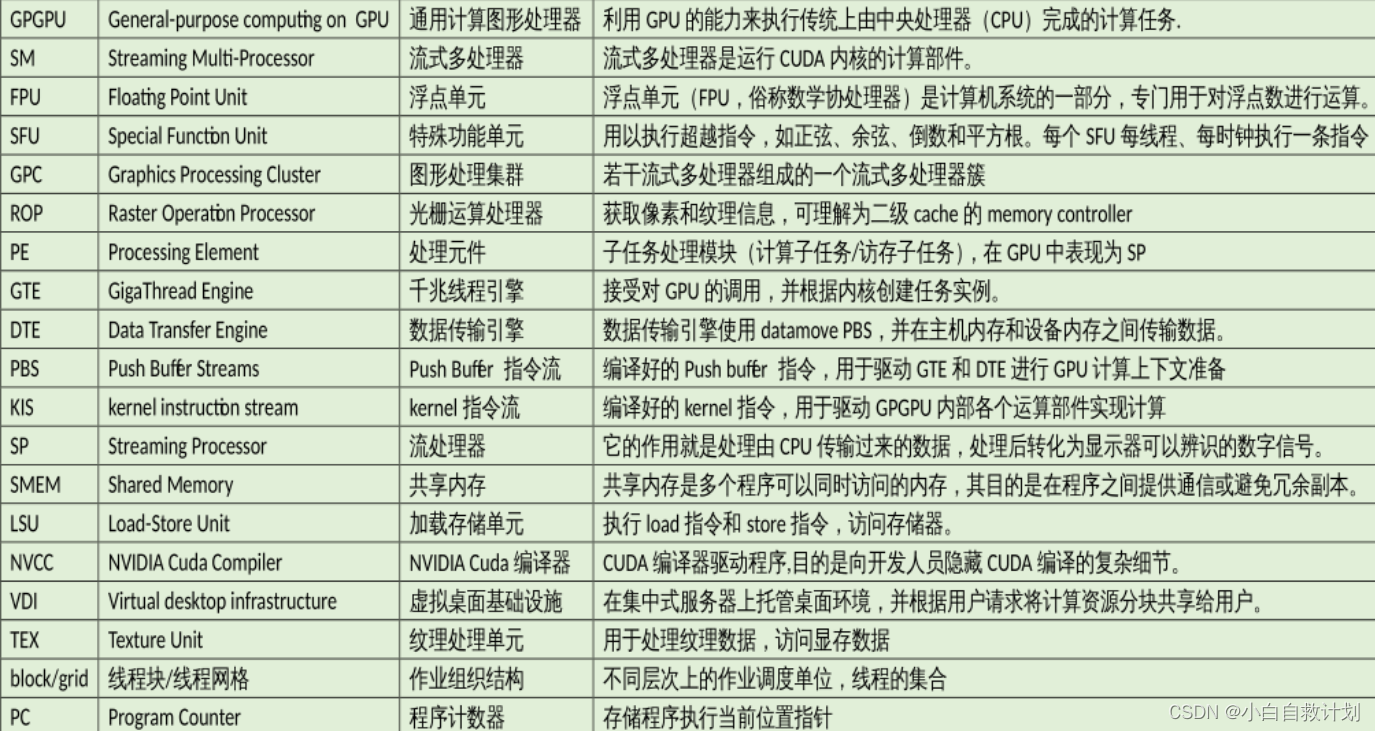

了解即可。
题
简述向量体系结构和GPU体系结构的差异。
向量体系结构
“窄而深”
指令流水线深,ALU宽度窄。
单次指令流水后能处理更多数据,掩盖不必要的流水线时间。
GPU
“宽而浅”
指令流水线浅,ALU宽度宽。
流水本身比较简单,直接对更多的数据进行并行计算,同一时刻处理更多数据
简述GPU和CPU在设计理念上的差异性。
CPU和GPU均有自己的存储,控制逻辑和运算单元,但区别是CPU的控制逻辑更复杂,而GPU的运算单元虽然较小但是众多,GPU也可以提供更多的寄存器和程序员可控的多级存储资源。
简述GPU各个层次组件间的相似性。
gpu在任务的划分上,存在着自相似性;
每一个第i级的任务,都可以划分为一组i-1级的任务;
并且同一级别的任务之间是并行的。
gpu在硬件上,同样也体现出了自相似性。
逐层的,都是相似的结构,包括调度器、任务的buffer、数据存储和处理单元。
简述GPGPU虚拟化的思想。
企业级做云计算时常常采用虚拟化技术:
一个GPU的SM很多,但是对于单用户只能用很少的SM,这样利用率很低;
硬件上把多个SM进行分割成多个切片;
软件上为每个用户分配一个SM切片;
使得每个用户都能满负荷使用SM;
每个用户感觉自己拥有了一个GPU。
简述 向量长度寄存器和向量屏蔽寄存器的作用。
向量长度寄存器VL
64位,每一位对应于向量寄存器的一个单元。
VL控制所有向量运算的长度,包括ld/st。
作用:将软件层程序中实际向量长度N与硬件层向量寄存器中的元素数目64相适配
向量屏蔽寄存器VM
当向量长度小于64时,或者条件语句控制下对向量某些元素进行单独运算时使用。
即使掩码(maskcode)中有大量的0,使用VM的向量指令速度依然远远快于标量计算模式。
简述指令编队 的思想
由一组不包含结构冒险的向量指令组成,一个编队中的所有向量指令在硬件条件允许时可以并行执行。
简述链接技术的思想
当两条指令出现“写后读”相关时,若它们不存在功能部件冲突和向量寄存器(源或目的) 冲突,就有可能把它们所用的功能部件头尾相接,形成一个链接(长)流水线,进行流水处理。
简述分段开采技术的思想。
当向量的长度大于向量寄存器的长度时,必须把长向量分成长度固定的段,然后循环分段处理,每一次循环只处理一个向量段。
这种技术称为分段开采技术。
在向量机器上,按照链接方式执行下述4条向量指令(括号中给出了相应功能部件的执行时间),如果向量寄存器和功能部件之间的数据传送需要1拍,试求此链接流水线的通过时间是多少拍?如果向量长度为64,则需多少拍才能得到全部结果?
V0←存储器 (从存储器中取数:7拍)
V2←V0+V1 (向量加:3拍)
V3←V2<A3 (按(A3)左移:4拍)
V5←V3∧V4 (向量逻辑乘:2拍)
答:链接流水线的通过时间:(7+1)+(1+3+1)+(1+4+1)+(1+2+1)=23
如果向量长度是64需要23+(64-1)=86拍得到全部结果
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









