






写了一晚上高性能大作业,人已die...【虽说技术含量不大,但足矣要孩子小命】
目录
一、研究背景与意义
1.1 研究背景
图的单源最短路径问题是指从指定的顶点到图中其他所有顶点之间的最短距离。Dijkstra算法作为一种经典的最短路径算法,以其简单有效的特性被广泛应用于多个领域,如路网规划、网络路由和电路设计等。然而,随着数据规模的不断增长,传统的Dijkstra算法在处理大规模数据时面临着计算效率的问题。
1.2 研究意义:
基于MPI(Message Passing Interface)实现Dijkstra算法的并行化,有助于提高算法在处理大规模数据时的效率。并行化的Dijkstra算法通过多个进程同时处理不同部分的数据,能够显著减少计算时间,提高计算性能。这对于需要快速计算最短路径的实际应用,如实时路网规划和网络路由优化,具有重要意义。
1.3 北京案例分析
在北京这样一个交通复杂且网络密集的城市,快速准确地计算最短路径对于日常交通管理和应急响应至关重要。例如:
-
路网规划: 在北京的交通管理中,能够快速找到从一个地点到另一个地点的最短路径,有助于优化交通流量,减少拥堵,提高交通效率。通过并行化的Dijkstra算法,可以在短时间内计算出大规模路网中的最优路径方案。
-
网络路由: 北京作为一个信息化程度高的城市,网络基础设施十分重要。通过并行化的Dijkstra算法,可以优化网络数据传输路径,减少延迟,提升网络服务质量。
-
应急响应: 在突发事件如自然灾害或公共安全事件发生时,能够快速找到最优的救援路径,对于提高应急响应速度,减少损失,保护市民安全具有重要作用。
二、研究内容
2.1 问题陈述
-
给定一个图,设
是一个有向图,
,
,设
为图中的一个特定顶点,
为每条边的非负权重,表示两个顶点之间的距离。
-
单源最短路径问题:单源最短路径(SSSP)问题是指对于给定的源顶点
,计算从
2.2 Dijkstra算法
-
初始化:创建一个辅助向量
,其中每个元素
表示从源顶点
到其他顶点
的路径长度。
-
选择路径长度最小的顶点,并将其加入已求得最短路径的顶点集合。
-
更新路径长度:对于每个尚未求得最短路径的顶点,计算通过新加入的顶点后是否能得到更短的路径。
Create a cluster cl[V]
Given a source vertex s
While (there exist a vertex that is not in the cluster cl[V])
{
FOR (all the vertices outside the cluster)
Calculate the distance from non-member vertex to s through the cluster
END
** O(V) **
Select the vertex with the shortest path and add it to the cluster
** O(V) **
}2.2.1 传统Dijkstra算法性能分析
运行时间是
-
为了获得路由表,我们需要进行
轮迭代(直到所有顶点都包含在Cluster中)。在每一轮中,我们将更新
缺点
-
如果网络的规模太大,那么获得结果将需要很长时间。
-
对于一些时间敏感的应用程序或实时服务,我们需要减少运行时间。
2.3 并行Dijkstra算法
方法:
-
每个核心识别其与源顶点最近的顶点;
-
使用并行前缀操作选择全局最近的顶点;
-
将结果广播到所有核心;
-
每个核心更新其顶点集合。
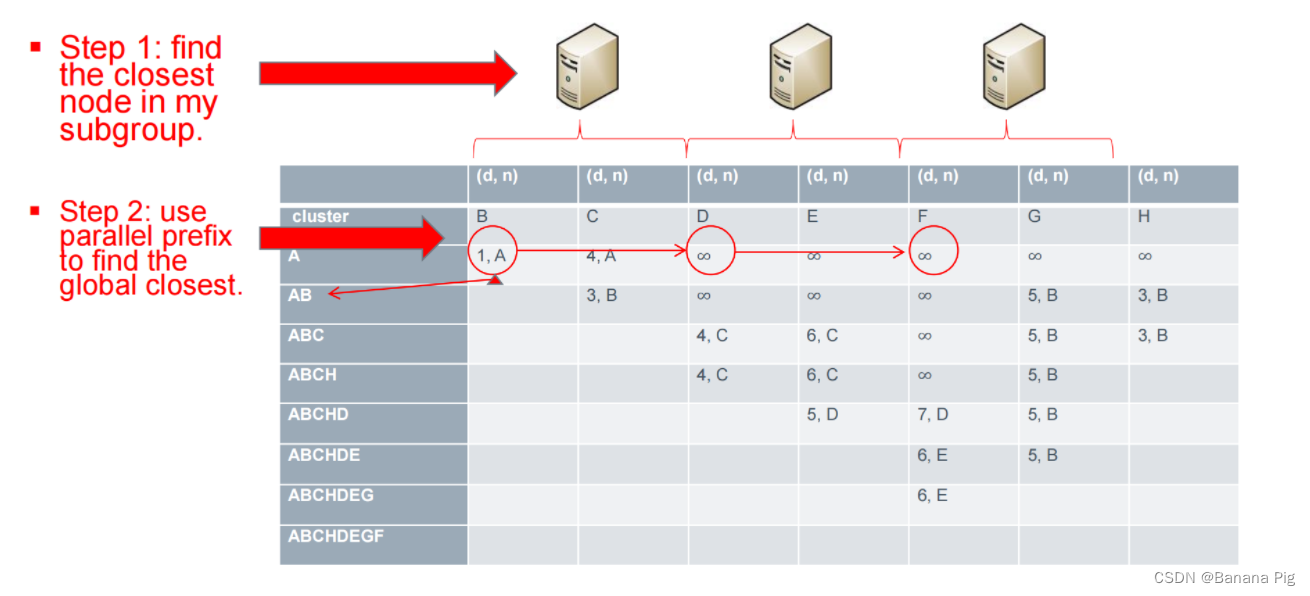
Create a cluster cl[V]
Given a source vertex s
Each core handles a subgroup of V/P vertices
While (there exist a vertex that is not in the cluster cl[V])
{
FOR (vertices in my subgroup but outside the cluster)
Calculate the distance from non-member vertex to s through the cluster;
Select the vertex with the shortest path as the local closest vertex;
END
** Each processor works in parallel O(V/P) **
Use the parallel prefix to find the global closest vertex among all the local closest vertices from each core.
** Parallel prefix log(P) **
}2.3.1 并行Dijkstra算法性能分析
运行时间 
-
P是使用的核心数量。为了获得路由表,我们需要进行
。因此,总运行时间为:
三、算法思想
在Dijkstra算法中,为了计算路径长度,我们引入了一个辅助向量 ,其每个分量
表示源顶点 v 到其他顶点
的路径长度。初始状态设定如下:如果从顶点 v 到顶点
存在路径,则D[i] 为边
的权值;否则,
为无穷大。显然:
表示从顶点 v 出发到其他顶点的一条最短路径的长度,其路径为。对于下一条最短路径长度的计算,实际上很简单。下一条最短路径的长度要么是源顶点 v 直接到某一顶点v[k]的长度,即
;要么是源顶点
经过顶点
到某一顶点的长度,即
。
假设 S为已经求得最短路径的顶点集合,那么下一条最短路径(设其终点为 ),要么是边
,要么为中间只经过 S 中顶点而最后到达终点 x的路径。在一般情况下,下一条最短路径的长度为:
其中 V 为图顶点的集合, 为边
的权值,或者为 D[k]和边
权值之和。
详细说明
-
初始状态的设定: 在Dijkstra算法开始时,我们需要为辅助向量D设定初始值。对于源顶点 v到其直接相连的顶点 v[i],我们将D[i] 设为对应边的权值;对于其他不直接相连的顶点,设为无穷大。这种初始化确保了算法从源顶点开始,逐步扩展到图中的其他顶点。
-
路径选择的过程: 在每一步中,我们从尚未包含在集合S中的顶点中选择一个路径长度最短的顶点 v[j]。将该顶点加入集合 S后,我们更新从源顶点v 到其他顶点的路径长度。这一过程通过比较现有路径长度和经过新加入顶点的路径长度,选择较短者进行更新。
-
算法的迭代: 这一过程持续进行,直到所有顶点都被包含在集合 S 中。在每次迭代中,算法都会确保找到一个新的最短路径,并将相应顶点加入到 S中。这种逐步扩展的策略保证了算法的正确性和有效性。
-
复杂度分析: Dijkstra算法的时间复杂度主要取决于选择最短路径顶点和更新路径长度的过程。使用优先队列等数据结构可以优化这些操作,从而提高算法的效率。
四、算法具体描述
在本文中,我们对Dijkstra算法进行了并行化分析。显然,初始化向量 (对应于算法的第一步)、更新最短路径值和最短路径(对应于算法的第三步)是可以并行化实现的。这是因为一旦确定了当前的最短路径和最短路径值,各个顶点的最短路径计算是相互独立的。因此,在并行化算法中,如何有效地求得当前的最短路径和最短路径值成为关键问题。
我们假设使用 个进程,并且图中有
个顶点。为了实现并行化,我们让每个进程负责 \frac{n}{P} 个顶点,每个进程都有自己的向量 D 和最短路径矩阵 p 。首先,我们可以计算出各个进程的当前最短路径,并将局部最短路径发送给进程0。进程0对这些局部最短路径进行比较,得到当前的全局最短路径,并将这一结果广播到所有的进程。
其算法描述如下:
-
输入:图
的邻接矩阵
,源顶点
-
输出:最短路径值向量
,最短路径矩阵
。
具体步骤:
-
进程0读取邻接矩阵 m 和源节点 v ,并将 m 和 v 广播到所有其他进程。
-
各进程并行初始化各自的局部向量 D 和矩阵 P 。
-
计算最短路径:
-
各进程并行计算各自的局部最短路径值,并将其发送给进程0。
-
进程0求出全局最短路径值和对应的进程号,并将结果广播到所有进程。
-
拥有全局最短路径值的进程将其对应的最短路径广播到其他进程,以便更新各个进程的最短路径。
-
-
各进程并行更新各自的 D 和 P 向量。
通过以上步骤,Dijkstra算法可以高效地进行并行化处理,从而提高计算大规模图最短路径问题的效率。这种并行化算法不仅能够显著减少计算时间,还能够充分利用现代多核处理器的优势,提升整体计算性能。
五、运行结果对比
5.1 串行结果
运行时间结果
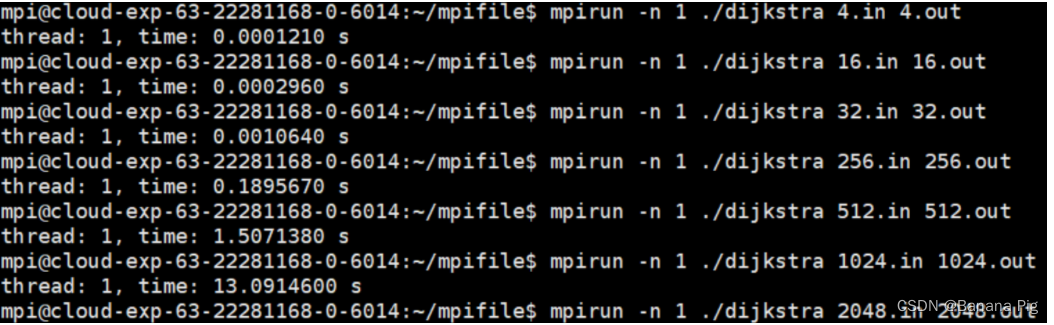
| 矩阵规模 | 串行运行时间 |
|---|---|
| n=4 | 0.0000121 |
| n=16 | 0.000296 |
| n=32 | 0.001064 |
| n=256 | 0.189567 |
| n=512 | 1.507138 |
| n=1024 | 13.09146 |
5.1.1 当Thread = 1时
则可看作串行结果
5.2 并行结果
运行时间结果
| 线程数 矩阵规模 | 4 | 16 | 32 | 256 | 512 | 1024 | 2048 | 4096 |
|---|---|---|---|---|---|---|---|---|
| 4 | 0.000134 | 0.000157 | 0.000476 | 0.067803 | 0.412913 | 3.286958 | 29.042382 | 244.479521 |
| 8 | 0.000072 | 0.000268 | 0.00056 | 0.052817 | 0.214567 | 1.750199 | 15.815377 | 123.539949 |
| 16 | 0.000098 | 0.000438 | 0.000572 | 0.039134 | 0.233561 | 0.987804 | 7.630141 | 65.160611 |
输入:
mpicc dijkstra.c -o dijkstra mpicc print.c -o print设邻接矩阵大小为n*n
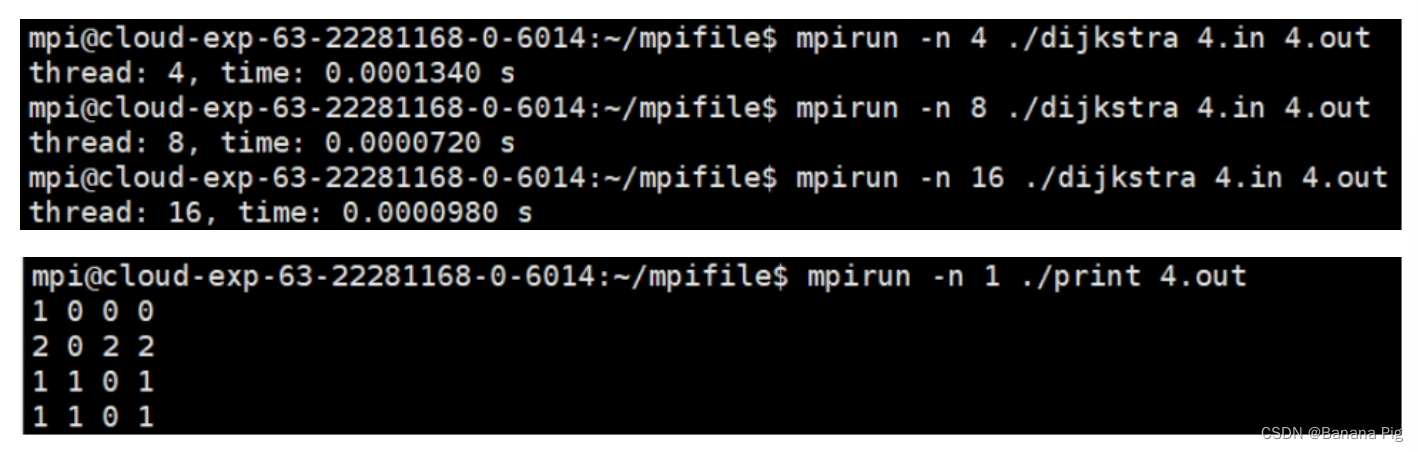
5.2.1 当n=4时
mpirun -n 4 ./dijkstra 4.in 4.out再将线程数由4替换为8和16
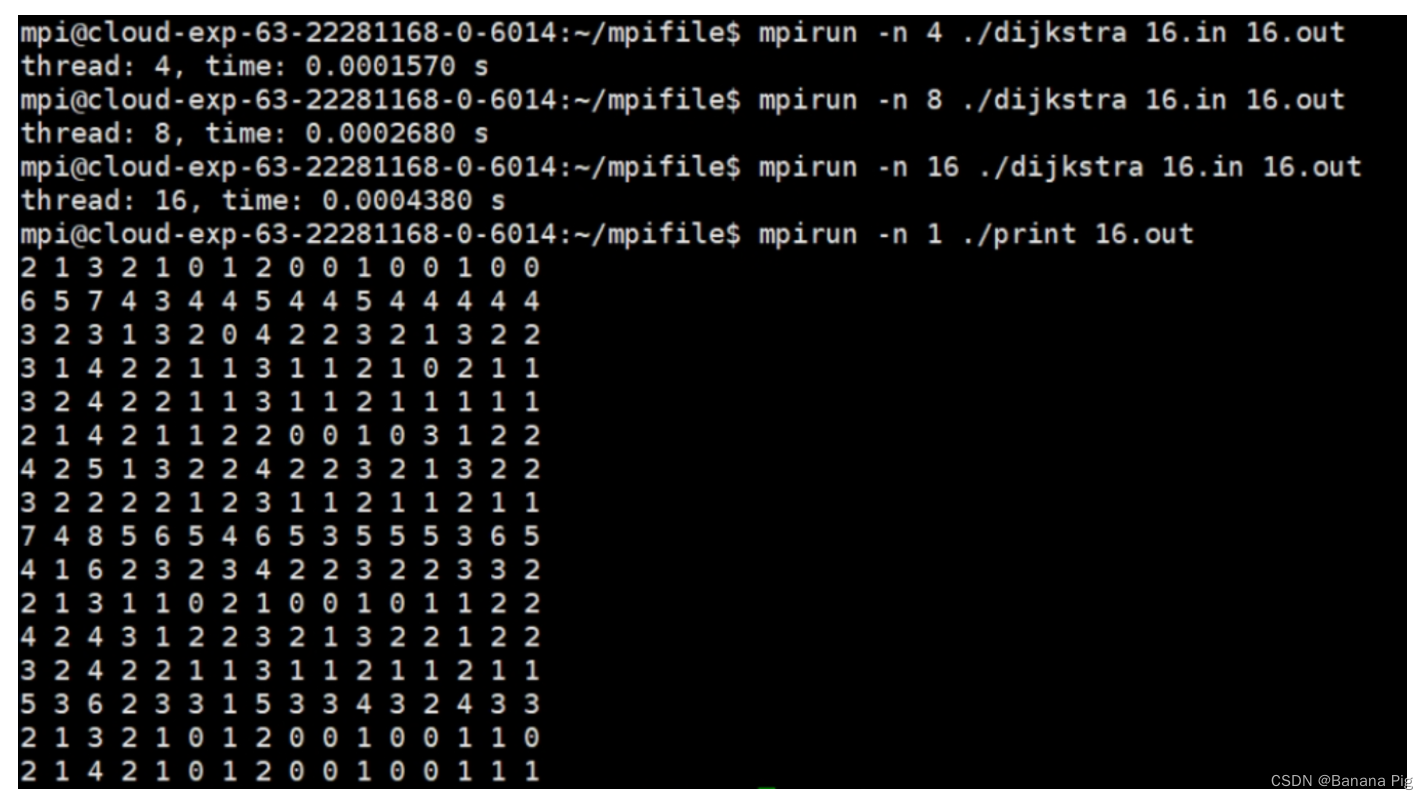
5.2.2 当n=16时
mpirun -n 4 ./dijkstra 16.in 16.out再将线程数由4替换为8和16
5.2.3 当n=32时
mpirun -n 4 ./dijkstra 32.in 32.out再将线程数由4替换为8和16
5.2.4 当n=256时
mpirun -n 4 ./dijkstra 256.in 256.out再将线程数由4替换为8和16

5.2.5 当n=512时
mpirun -n 4 ./dijkstra 512.in 512.out再将线程数由4替换为8和16

5.2.6 当n=1024时
mpirun -n 4 ./dijkstra 1024.in 1024.out再将线程数由4替换为8和16

5.2.7 当n=2048时
mpirun -n 4 ./dijkstra 2048.in 2048.out再将线程数由4替换为8和16

5.2.8 当n=4096时
mpirun -n 4 ./dijkstra 4096.in 4096.out再将线程数由4替换为8和16

5.3 运行结果对比分析
5.3.1 串行并行结果对比
| 矩阵规模 | 串行 | Thread=4 | Thread=8 | Thread=16 |
|---|---|---|---|---|
| n=4 | 0.0000121 | 0.000134 | 0.000072 | 0.000098 |
| n=16 | 0.000296 | 0.000157 | 0.000268 | 0.000438 |
| n=32 | 0.001064 | 0.000476 | 0.000561 | 0.000572 |
| n=256 | 0.189567 | 0.067803 | 0.052817 | 0.039134 |
| n=512 | 1.507138 | 0.412913 | 0.214567 | 0.233561 |
| n=1024 | 13.09146 | 3.286958 | 1.750199 | 0.987804 |
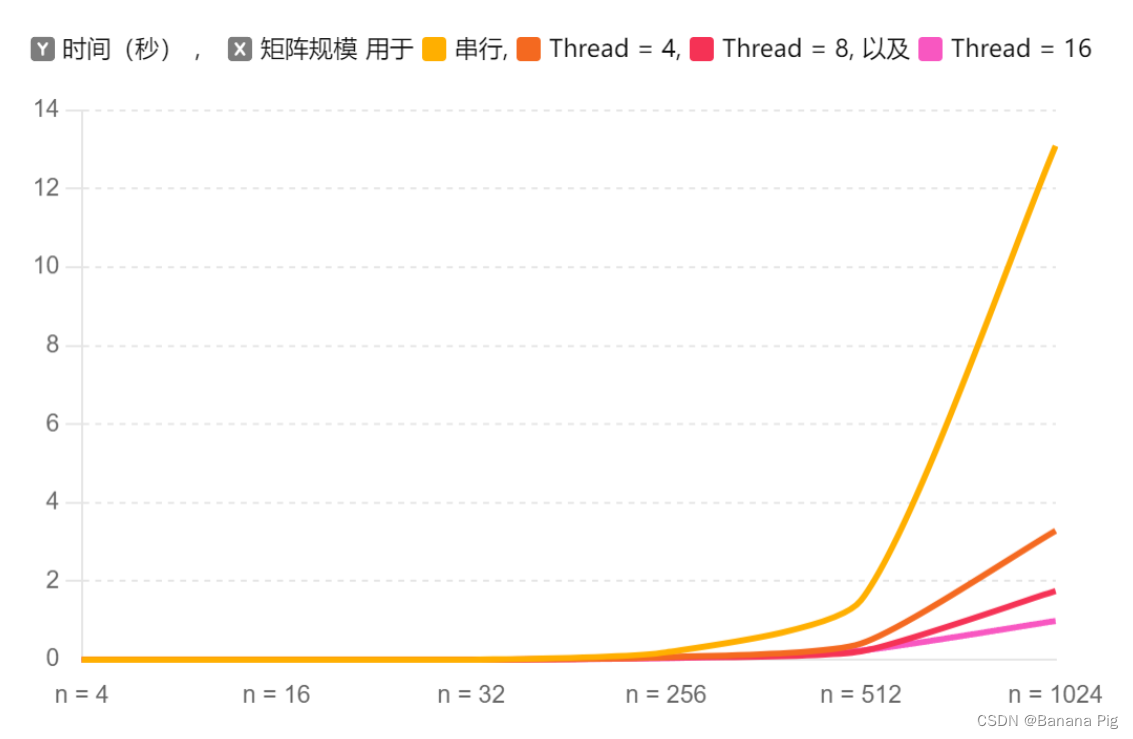
如图展示运行时间随顶点数量 n 的变化趋势,可以观察到以下几点:
-
小规模矩阵(n=4, 16, 32):
-
在小规模矩阵下,串行算法和并行算法的运行时间差异不大。尤其是当线程数较少时,并行算法并未显著优于串行算法。这是因为在小数据规模下,线程间的通信开销可能抵消了并行计算带来的性能提升。
-
-
中等规模矩阵(n=256, 512):
-
对于中等规模的矩阵,随着线程数的增加,运行时间显著减少。Thread=8 和 Thread=16 的并行算法明显优于串行算法,证明了并行计算在处理中等规模数据时的优势。
-
-
大规模矩阵(n=1024):
-
在大规模矩阵下,并行算法的优势更加显著。Thread=16 的运行时间为0.987804秒,远低于串行算法的13.09146秒,展示了并行算法在处理大规模数据时的卓越性能。随着线程数的增加,运行时间显著减少,这表明并行算法能够有效利用多线程处理大规模数据。
-
总结
从上述结果分析可以看出,并行算法在处理中等规模和大规模数据时具有显著优势。尽管在小规模数据下,线程间的通信开销可能会抵消并行处理的优势,但随着数据规模的增加,并行算法的效率提升明显。
-
高效性:并行算法在处理中大规模数据时表现出色,能够显著减少计算时间,提升整体效率。
-
可扩展性:随着线程数的增加,并行算法能够充分利用多核处理器的优势,实现性能的线性或超线性提升。
-
灵活性:并行算法适用于不同规模的数据集,无论是小规模、中等规模还是大规模数据集,并行算法都能有效地分配计算资源,优化处理过程。
5.3.2 线程数与矩阵规模结果对比
| 线程数 矩阵规模 | 4 | 16 | 32 | 256 | 512 | 1024 | 2048 | 4096 |
|---|---|---|---|---|---|---|---|---|
| 4 | 0.000134 | 0.000157 | 0.000476 | 0.067803 | 0.412913 | 3.286958 | 29.042382 | 244.479521 |
| 8 | 0.000072 | 0.000268 | 0.00056 | 0.052817 | 0.214567 | 1.750199 | 15.815377 | 123.539949 |
| 16 | 0.000098 | 0.000438 | 0.000572 | 0.039134 | 0.233561 | 0.987804 | 7.630141 | 65.160611 |
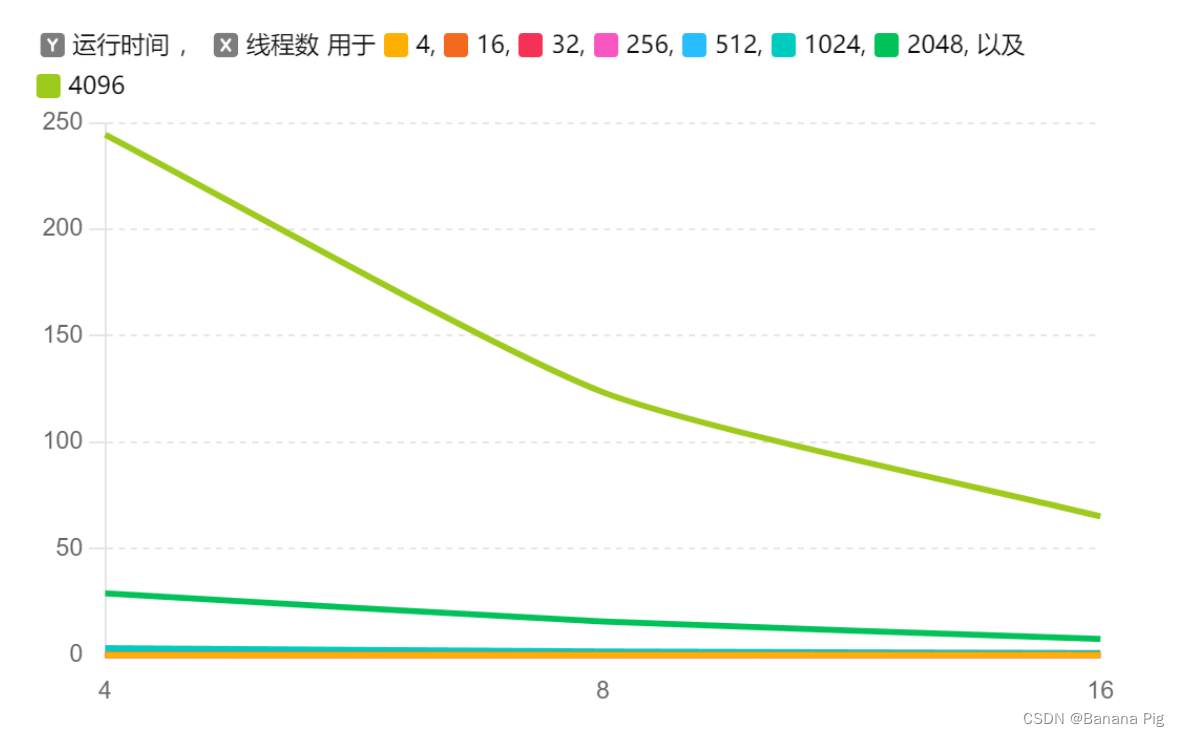
如图展示了运行时间随矩阵规模和线程数的变化趋势,可以观察到以下几点:
-
小规模矩阵(n=4, 16, 32):
-
在小规模矩阵下,增加线程数对运行时间的影响较小。尽管线程数增加能够稍微减少运行时间,但由于数据规模较小,线程间的通信开销可能抵消了并行处理带来的优势。
-
-
中等规模矩阵(n=256, 512):
-
对于中等规模的矩阵,增加线程数明显提高了算法的性能。线程数为16时,运行时间显著低于线程数为4和8的情况,表明并行处理在处理中等规模矩阵时具有较大的优势。
-
-
大规模矩阵(n=1024, 2048, 4096):
-
在大规模矩阵下,并行算法的优势更加显著。随着线程数的增加,运行时间大幅减少。特别是在线程数为16时,运行时间显著低于线程数为4和8的情况,证明了并行算法在处理大规模矩阵时的高效性。
-
总结
-
并行算法的高效性:并行算法在处理中大规模矩阵时表现出色,能够显著减少运行时间,提升整体效率。对于需要处理大量数据的实际应用,如大规模图计算和复杂网络分析,并行算法具有重要意义。
-
线程数的影响:随着线程数的增加,运行时间显著减少。特别是在处理中等和大规模矩阵时,增加线程数能够充分利用多核处理器的优势,实现性能的线性或超线性提升。
-
数据规模的重要性:并行算法在处理大规模数据时优势最为明显。在小规模数据下,线程间的通信开销可能抵消并行处理的优势,但在大规模数据下,并行处理能够显著提高计算效率。
五、总结与展望
在这次实验中,我们学到了很多关于混合并行编程模型和大规模图处理的知识。结合MPI和OpenMP、CUDA等技术,我们可以形成一个混合并行编程模型,从而更好地利用多核CPU和GPU的计算能力,进一步提升算法性能。例如,使用MPI进行进程间的通信,OpenMP进行进程内的并行计算,CUDA进行GPU加速,这种组合方式极大地提高了计算效率。
未来的研究可以探索更高效的图分割技术,使得超大规模图能够被分割成适合并行计算的小图块,从而使得算法能够处理更大规模的图。此外,结合分布式文件系统(如HDFS)和计算框架(如Apache Spark),实现分布式存储和计算,处理超大规模图,这将是一个非常有前景的研究方向。
在应用和扩展方面,我们可以扩展Dijkstra算法,支持多目标优化,例如同时考虑距离和时间等多个因素,并行化处理多个目标的最短路径问题。这种扩展在大规模社交网络分析、基因网络分析、物联网路径规划等领域,能极大地提升应用领域的计算效率。
此外,研究并行实时算法能够在动态图(图结构随时间变化)中快速更新最短路径信息,适用于需要实时响应的应用场景,如交通导航、网络路由等。同时,增量式并行计算技术可以在图发生小规模变化时,仅计算变化部分,从而提高计算效率。
这次实验让我们深入了解了并行计算在处理大规模图数据方面的优势,同时也认识到结合多种并行技术和分布式计算的潜力。在未来的研究和应用中,这些技术将为我们解决更复杂的问题提供有力的支持。
六、伪代码
算法:分布式Dijkstra算法
1. 初始化MPI环境
2. 从命令行参数读取输入和输出文件名
3. 获取并行进程数量 (parallelize_size)
4. 获取当前进程编号 (rank)
5. 定义变量:
- 图 graph
- 顶点数量 n
- 最终结果矩阵 result
6. 如果是根进程(rank为0):
a. 从输入文件读取邻接矩阵到 graph
b. 获取顶点数量 n
c. 分配结果矩阵的内存
d. 记录开始时间
7. 将顶点数量广播到所有进程
8. 如果不是根进程:
a. 设置图的顶点数量 n
b. 分配邻接矩阵的内存
9. 将邻接矩阵广播到所有进程
10. 计算每个进程需要处理的顶点数量 (interval_size)
11. 计算每个进程处理的顶点区间:
- range_start = interval_size * rank
- range_end = interval_size * rank + interval_size - 1
- 如果是最后一个进程,调整 range_end 为 n - 1
12. 使用Dijkstra算法计算分配范围内的最短路径 (djstra)
13. 使用MPI_Gatherv收集所有进程的最短路径结果到根进程
14. 如果是根进程:
a. 记录结束时间
b. 计算耗时
c. 打印线程数量和耗时
d. 将最终结果写入输出文件
15. 结束MPI环境
算法:djstra (图 graph, int start, int end)
1. 初始化变量:
- 顶点数量 n
- 局部结果数组 local_result
- 标记数组 mark
2. 将邻接矩阵的相关部分复制到 local_result
3. 对于每个顶点从 start 到 end:
a. 重置标记数组
b. 对于图中的每个顶点:
i. 使用 get_min 获取未标记顶点中距离最小的顶点索引
ii. 标记该顶点
iii. 对于图中的每个顶点:
- 如果顶点已标记,继续
- 如果找到更短路径,更新距离
4. 返回 local_result
算法:get_min (const int* dis, const int* flag, int n)
1. 初始化变量:
- 最小距离顶点索引 min_dis_vertex
- 最小距离 min_dis
2. 对于每个顶点:
a. 如果顶点已标记,继续
b. 如果当前顶点的距离小于 min_dis:
i. 更新 min_dis
ii. 更新 min_dis_vertex
3. 返回 min_dis_vertex
算法:read_adjacency_matrix (const char* input_file_name, 图 graph)
1. 打开输入文件
2. 从文件中读取顶点数量
3. 分配邻接矩阵内存
4. 从文件中读取邻接矩阵数据
5. 关闭文件
算法:write_graph (const int* shortest_distance, int vertices_number, const char* fname)
1. 打开输出文件
2. 将顶点数量写入文件
3. 将最短距离矩阵写入文件
4. 关闭文件
算法:collect_data (int vertices_number, int* shortest_dis_apart, int* result, int size, int parallelize_size)
1. 初始化变量:
- 每个进程的区间大小 intvl
- 每个进程结果的起始位置 start_pos_each_process
- 每个进程结果的长度 length_each_process
2. 计算每个进程结果数据的起始位置
3. 计算每个进程结果数据的长度
4. 使用 MPI_Gatherv 收集所有进程的结果到根进程七、完整代码
7.1 串行代码(用于时间对比测试)
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#include <string.h>
// 图结构体定义
typedef struct {
int vertices_number;
int* adjacency_matrix;
} Graph;
int get_min(const int* dis, const int* flag, int n);
/* 功能:使用 Dijkstra 算法计算顶点之间的最短距离
* 参数:
* graph:图结构
* start:计算最短距离的起始顶点编号
* 返回值:最短距离数组
*/
int* djstra(Graph* graph, int start) {
int n = graph->vertices_number; // 获取图的顶点数量
int* local_result = (int*)malloc(sizeof(int) * n); // 为结果数组分配内存
memcpy(local_result, graph->adjacency_matrix + start * n, n * sizeof(int)); // 拷贝邻接矩阵的部分数据到结果数组
int* mark = (int*)malloc(sizeof(int) * n); // 为标记数组分配内存
memset(mark, 0, sizeof(int) * n); // 重置标记数组
int i = 0;
while (i++ < n) { // 循环 n 次
int vertex = get_min(local_result, mark, n); // 获取当前未标记顶点中距离最小的顶点
mark[vertex] = 1; // 标记该顶点
int j = 0;
for (; j < n; j++) { // 遍历所有顶点
if (mark[j] == 1) { // 如果顶点已经标记过,跳过
continue;
}
// 更新距离
if (local_result[vertex] + graph->adjacency_matrix[vertex * n + j] < local_result[j]) {
local_result[j] = local_result[vertex] + graph->adjacency_matrix[vertex * n + j];
}
}
}
free(mark);
return local_result; // 返回数组
}
/* 功能:从数组 dis 中找到未标记的顶点中距离最小的顶点,并返回该顶点的索引
* 参数:
* dis:整数指针
* flag:用于标记是否需要跳过元素
* n:检查的元素数量
* 返回值:最小距离的顶点编号
*/
int get_min(const int* dis, const int* flag, int n) {
int min_dis_vertex = -1; // 初始化最小距离顶点
int min_dis = INT_MAX; // 初始化最小距离为最大值
int i = 0;
for (; i < n; i++) { // 遍历所有顶点
if (flag[i] == 1) { // 如果顶点已经标记过,跳过
continue;
}
if (dis[i] < min_dis) { // 如果当前顶点的距离小于最小距离
min_dis = dis[i]; // 更新最小距离
min_dis_vertex = i; // 更新最小距离顶点的索引
}
}
return min_dis_vertex; // 返回最小距离顶点的索引
}
/*
* 功能:从二进制文件读取权重矩阵。
* 为了方便在 mpi上处理数据,使用一维数组保存矩阵的权重。
* 参数:
* input_file_name:输入文件名
* 返回值:一维整数数组
*/
void read_adjacency_matrix(const char* input_file_name, Graph* graph) {
FILE* input_f = fopen(input_file_name, "rb"); // 打开输入文件,以二进制模式读取
if (input_f == NULL) { // 检查文件是否成功打开
fprintf(stderr, "无法打开文件 %s!\n", input_file_name); // 如果文件无法打开,输出错误信息
exit(1); // 终止程序
}
fread(&graph->vertices_number, sizeof(int), 1, input_f); // 从文件中读取顶点数量
int n = graph->vertices_number; // 获取顶点数量
graph->adjacency_matrix = (int*)malloc(sizeof(int) * n * n); // 为邻接矩阵分配内存
fread(graph->adjacency_matrix, sizeof(int), n * n, input_f); // 从文件中读取邻接矩阵数据
fclose(input_f); // 关闭文件
}
/**
* 功能:将结果保存到二进制文件
* 参数:
* shortest_distance:最短距离数组
* vertices_number:顶点数量
* fname:文件名
*/
void write_graph(const int* shortest_distance, int vertices_number, const char* fname) {
FILE* out_f = fopen(fname, "wb"); // 打开输出文件,以二进制模式写入
if (out_f == NULL) { // 检查文件是否成功打开
fprintf(stderr, "无法打开文件 %s!\n", fname); // 如果文件无法打开,输出错误信息
exit(1); // 终止程序
}
fwrite(&vertices_number, sizeof(int), 1, out_f); // 将顶点数量写入文件
fwrite(shortest_distance, sizeof(int), vertices_number * vertices_number, out_f); // 将最短距离矩阵写入文件
fclose(out_f); // 关闭文件
}
int main(int argc, char* argv[]) {
clock_t start_time, finish_time;
const char* input_file_name = argv[1];
const char* output_file_name = argv[2];
Graph graph;
read_adjacency_matrix(input_file_name, &graph);
int n = graph.vertices_number;
int* result = (int*)malloc(sizeof(int) * n * n);
start_time = clock();
for (int i = 0; i < n; i++) {
int* distances = djstra(&graph, i);
memcpy(result + i * n, distances, sizeof(int) * n);
free(distances);
}
finish_time = clock();
double duration = (finish_time - start_time * 1.0) / CLOCKS_PER_SEC;
printf("time: %.7f s\n", duration);
write_graph(result, n, output_file_name);
free(graph.adjacency_matrix);
free(result);
return 0;
}7.2 并行代码
#include <stdio.h>
#include <mpi.h>
#include <stdlib.h>
#include <time.h>
#include <string.h>
//图结构体定义
typedef struct {
int vertices_number;
int* adjacency_matrix;
} Graph;
int get_min(const int* dis, const int* flag, int n);
/* 功能:使用 Dijkstra 算法计算顶点之间的最短距离
* 参数:
* graph:图结构
* start:计算最短距离的起始顶点编号
* end:计算最短距离的终止顶点编号
* 返回值:最短距离数组
*/
int* djstra(Graph* graph, int start, int end) {
int n = graph->vertices_number; // 获取图的顶点数量
int* local_result = (int*)malloc(sizeof(int) * (end - start + 1) * n); // 为结果数组分配内存
memcpy(local_result, graph->adjacency_matrix + start * n, (end - start + 1) * n * sizeof(int)); // 拷贝邻接矩阵的部分数据到结果数组
int* mark = (int*)malloc(sizeof(int) * n); // 为标记数组分配内存
int vertex_no = start;
for (; vertex_no <= end; vertex_no++) { // 遍历每个顶点
memset(mark, 0, sizeof(int) * n); // 重置标记数组
int i = 0;
while (i++ < n) { // 循环 n 次
int offset = (vertex_no - start) * n; // 计算当前顶点在结果数组中的偏移量
int vertex = get_min(local_result + offset, mark, n); // 获取当前未标记顶点中距离最小的顶点
mark[vertex] = 1; // 标记该顶点
int j = 0;
for (; j < n; j++) { // 遍历所有顶点
if (mark[j] == 1) { // 如果顶点已经标记过,跳过
continue;
}
// 更新距离
if (local_result[offset + vertex] + graph->adjacency_matrix[vertex * n + j] < local_result[offset + j]) {
local_result[offset + j] = local_result[offset + vertex] + graph->adjacency_matrix[vertex * n + j];
}
}
}
}
return local_result; // 返回数组
}
/* 功能:从数组 dis 中找到未标记的顶点中距离最小的顶点,并返回该顶点的索引
* 参数:
* dis:整数指针
* flag:用于标记是否需要跳过元素
* n:检查的元素数量
* 返回值:最小距离的顶点编号
*/
int get_min(const int* dis, const int* flag, int n) {
int min_dis_vertex = 0; // 初始化最小距离顶点为第一个顶点
int min_dis = dis[0]; // 初始化最小距离为第一个顶点的距离
int i = 1;
for (; i < n; i++) { // 遍历所有顶点
if (flag[i] == 1) { // 如果顶点已经标记过,跳过
continue;
}
if (dis[i] < min_dis) { // 如果当前顶点的距离小于最小距离
min_dis = dis[i]; // 更新最小距离
min_dis_vertex = i; // 更新最小距离顶点的索引
}
}
return min_dis_vertex; // 返回最小距离顶点的索引
}
/*
* 功能:从二进制文件读取权重矩阵。
* 为了方便在 mpi上处理数据,使用一维数组保存矩阵的权重。
* 参数:
* input_file_name:输入文件名
* 返回值:一维整数数组
*/
void* read_adjacency_matrix(const char* input_file_name, Graph* graph) {
FILE* input_f = fopen(input_file_name, "rb"); // 打开输入文件,以二进制模式读取
if (input_f == NULL) { // 检查文件是否成功打开
fprintf(stderr, "无法打开文件 %s!\n", input_file_name); // 如果文件无法打开,输出错误信息
exit(1); // 终止程序
}
fread(&graph->vertices_number, sizeof(int), 1, input_f); // 从文件中读取顶点数量
int n = graph->vertices_number; // 获取顶点数量
graph->adjacency_matrix = (int*)malloc(sizeof(int) * n * n); // 为邻接矩阵分配内存
fread(graph->adjacency_matrix, sizeof(int), n * n, input_f); // 从文件中读取邻接矩阵数据
fclose(input_f); // 关闭文件
}
/**
* 功能:将结果保存到二进制文件
* 参数:
* shortest_distance:最短距离数组
* vertices_number:顶点数量
* fname:文件名
*/
void write_graph(const int* shortest_distance, int vertices_number, const char* fname) {
FILE* out_f = fopen(fname, "wb"); // 打开输出文件,以二进制模式写入
if (out_f == NULL) { // 检查文件是否成功打开
fprintf(stderr, "无法打开文件 %s!\n", fname); // 如果文件无法打开,输出错误信息
exit(1); // 终止程序
}
fwrite(&vertices_number, sizeof(int), 1, out_f); // 将顶点数量写入文件
fwrite(shortest_distance, sizeof(int), vertices_number * vertices_number, out_f); // 将最短距离矩阵写入文件
fclose(out_f); // 关闭文件
}
/**
* 功能:收集每个进程的结果到根进程
* 参数
* vertices_number:顶点数量
* shortest_dis_apart:单个进程的结果
* result:最终结果
* size:结果大小
* parallelize_size:并行进程数量
*/
void collect_data(int vertices_number, int* shortest_dis_apart, int* result, int size, int parallelize_size) {
int intvl = vertices_number / parallelize_size;
int* start_pos_each_process = (int*)malloc(sizeof(int) * parallelize_size);
int* length_each_process = (int*)malloc(sizeof(int) * parallelize_size);
// 计算每个进程结果数据存储的起始位置
int i = 0;
for (; i < parallelize_size; i++) {
start_pos_each_process[i] = intvl * vertices_number * i;
}
// 计算每个进程结果数据的大小
i = 0;
for (; i < parallelize_size - 1; i++) {
length_each_process[i] = intvl * vertices_number;
}
length_each_process[parallelize_size - 1] = (vertices_number - intvl * (parallelize_size - 1)) * vertices_number;
// 收集每个进程的结果到根进程
MPI_Gatherv(shortest_dis_apart, size, MPI_INT, result, length_each_process, start_pos_each_process, MPI_INT, 0,
MPI_COMM_WORLD);
}
int main(int argc, char* argv[]) {
clock_t start_time, finish_time;
MPI_Init(&argc, &argv);
const char* input_file_name = argv[1];
const char* output_file_name = argv[2];
// 读取并行进程数量
int parallelize_size;
MPI_Comm_size(MPI_COMM_WORLD, ¶llelize_size);
// 读取当前进程编号
int rank;
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
// 保存所有进程汇总的结果
int* result;
Graph graph;
int n;
if (rank == 0) {
// 在根进程读取图数据
read_adjacency_matrix(input_file_name, &graph);
n = graph.vertices_number;
result = (int*)malloc(sizeof(int) * n * n);
// 在根进程记录时间
start_time = clock();
}
// 将顶点数量广播到所有其他进程
MPI_Bcast(&n, 1, MPI_INT, 0, MPI_COMM_WORLD);
if (rank != 0) {
graph.vertices_number = n;
graph.adjacency_matrix = (int*)malloc(sizeof(int) * n * n);
}
// 将权重矩阵广播到所有其他进程,然后以分布式方式计算每个顶点之间的最短距离
MPI_Bcast(graph.adjacency_matrix, n * n, MPI_INT, 0, MPI_COMM_WORLD);
// 每个进程要处理的顶点数量
int interval_size = n / parallelize_size;
// 顶点区间
int range_start = interval_size * rank;
int range_end = interval_size * rank + interval_size - 1;
// 最后一个进程处理的顶点数量可能不等于区间大小
if (rank == parallelize_size - 1) {
range_end = n - 1;
}
int* result_a_process = djstra(&graph, range_start, range_end);
collect_data(n, result_a_process, result, (range_end - range_start + 1) * n, parallelize_size);
if (rank == 0) {
// 在根进程记录时间
finish_time = clock();
double duration = (finish_time - start_time * 1.0) / CLOCKS_PER_SEC;
printf("thread: %d, time: %.7f s\n", parallelize_size, duration);
write_graph(result, n, output_file_name);
}
MPI_Finalize();
return 0;
}
















 1656
1656

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









