







刚开始看会觉得比较晦涩难懂无趣,但是看完会有一个基本了解,对应课本第一章知识点,或有遗漏请见谅
从hello程序进入计算机系统
编写第一个c语言文件
#include <stdio.h>
using namespace std;
int main()
{
printf("Hello,World!\n");
return 0;
}保存得到后缀为.c的文件 -----> hello.c
在终端运行指令
linux$ gcc -o hello hello.c生成一个可执行程序 hello
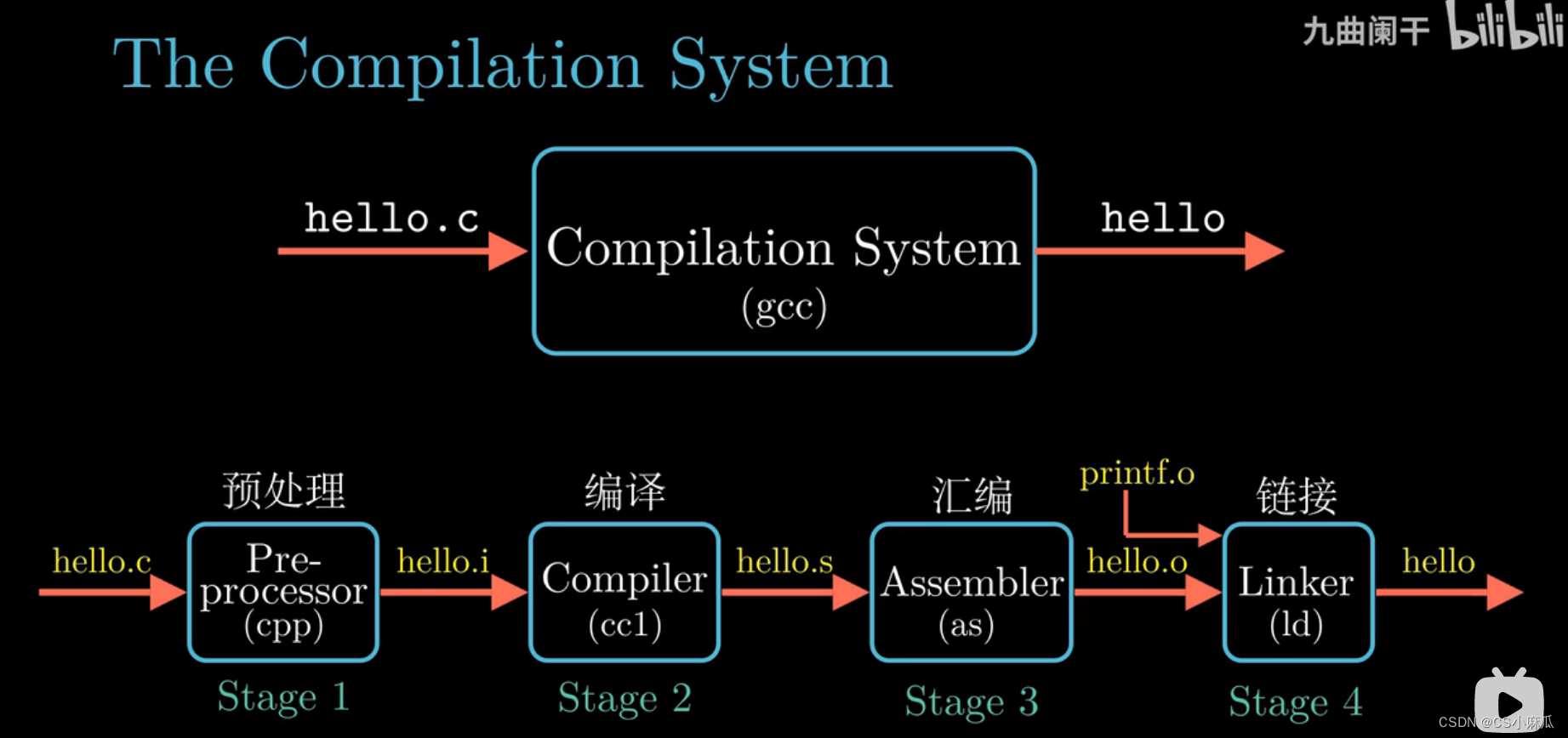
编译系统的处理过程(Compilation System)
四个阶段
- 预处理
- 读取文件hello.c
- 预处理器根据#开头的代码修改原始程序
- 如例子,读取stdio.h头文件中的内容
- 将其中的内容直接插入到源程序中
- 结果得到另一个c程序文件,该文件通常以 .i 结尾(hello.i)
- 编译
- 将hello.o 文件翻译成 hello.s 文件
- 包括词法分析,语法分析,语义分析,中间代码生成以及一系列中间操作
- 汇编
- 汇编器根据指令集将汇编程序 hello.s 翻译成机器指令
- 把一系列的机器指令按照固定的规则进行打包,得到可重定位目标文件 hello.o(二进制文件)
- 链接
- 负责把 hello.o 和 printf.o 进行合并
- 得到可执行文件 hello 存放在系统磁盘(disk)上
为什么要理解编译系统如何工作的
- 优化程序性能,对机器执行的代码有基本了解
- 理解链接过程中出现的错误
- 避免安全漏洞,理解数据和控制信息在程序栈上是如何存储的
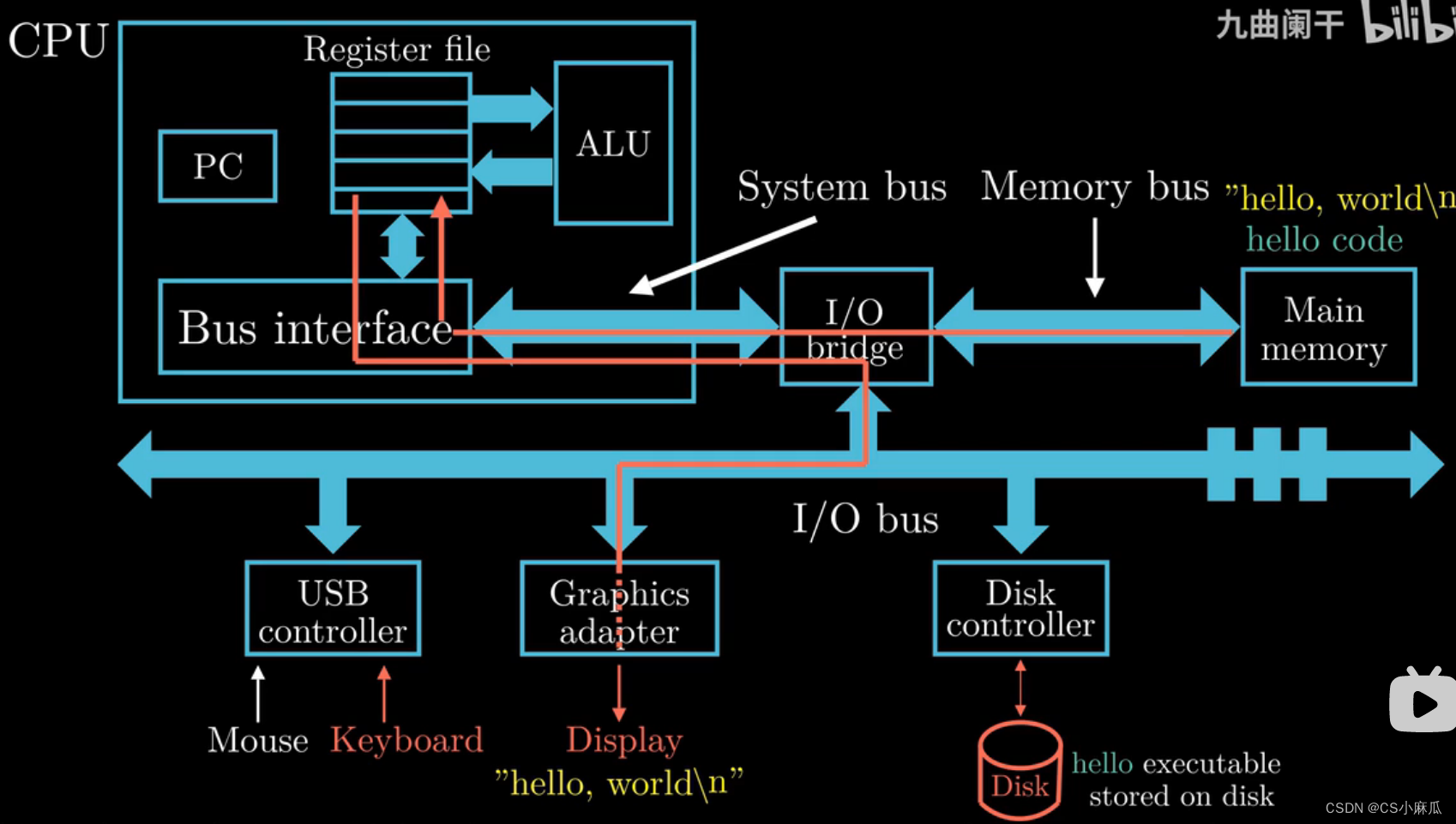
计算机系统硬件组成
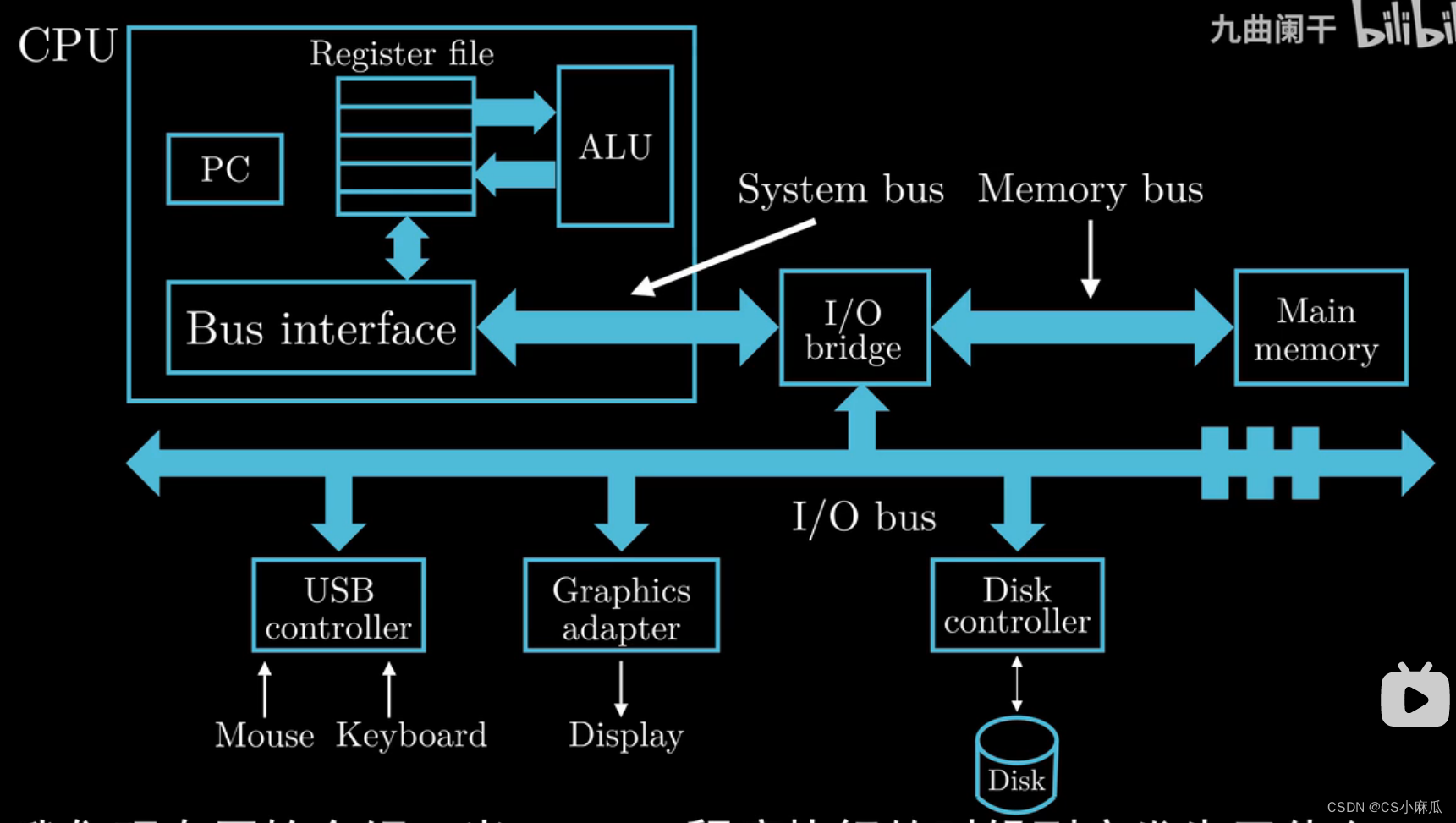
中央处理单元(CPU,处理器)
- PC:英文Program Count,程序计数器,大小为一个字的存储区域(一个字的大小:32-bit 1word=4Byte ; 64-bit 1word=8Byte),存储某一指令的地址,处理器在不断的处理PC指向的指令,然后更新PC指向下一条指令(不一定相邻)
- 寄存器文件:英文Register File,CPU内部的一个存储设备,由一些单字节的寄存器构成,每个寄存器都有自己的名字,可以理解为一个临时存放数据的空间
- ALU:英文Arithmatic/logic Unit,复制寄存器中保存的值,进行算术运算,得到的结果返回到寄存器中,覆盖原来的数据
内存(主存,Main Memory)
- 功能:处理器在执行程序时,内存主要存放程序指令以及数据
- 物理上讲,内存是由随机动态存储器芯片组成
- 逻辑上讲,内存可以堪称一个从零开始的大数组,每个字节都有相应的数据地址
总线(I/O bridge)
- 数据总线,进行数据传递,负责将信息从一个部件传递到另一个部件,如内存和处理器之间通过总线进行数据传递
- 通常被设计成传递固定长度的字节块,也就是字(word),各个系统中的字是多少字节不一致
输入输出设备
- 每一个输入输出设备都通过一个控制器或者适配器与IO总线相连
- 鼠标,键盘,磁盘,显示器等等
控制器与适配器
- 两者主要区别是封装方式
- 功能:在IO设备与IO总线之间传输数据
如何运行可执行程序
打开一个shell程序(命令解释程序,输出一个提示符来等待命令行的输入,然后执行这个命令,如果命令行的第一个单词不是内置的shell命令,shell就会假设这是一个可执行文件的命令,进行加载并运行),输入相应可执行程序的文件名 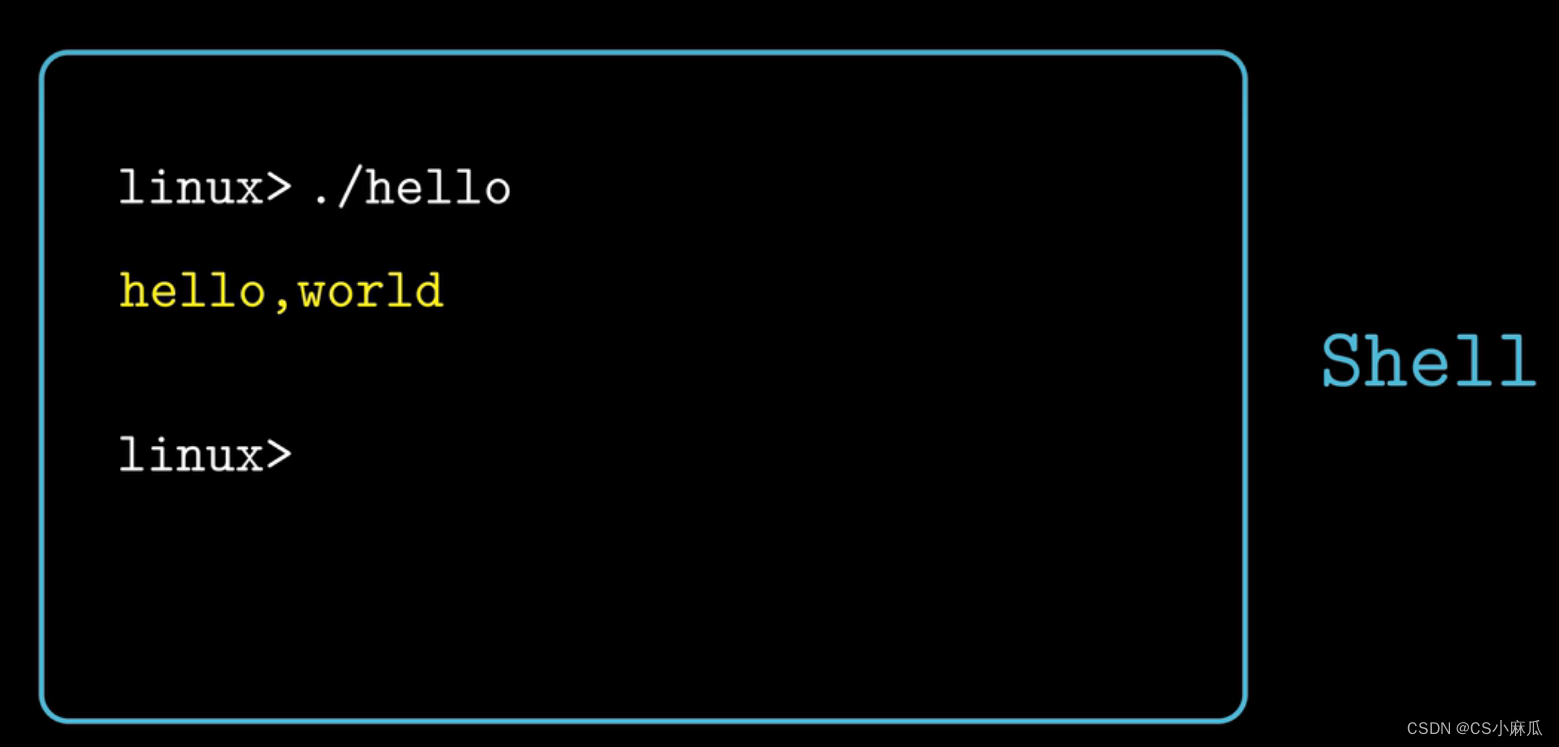
hello.c文件执行过程
- 键盘输入`./hello.c`的字符串,闪烁的hello字符串表示键盘输入
- shell程序会将输入的字符串逐一读入寄存器(CPU中的Reg)
- CPU(处理器)会将hello这个字符串放入内存中
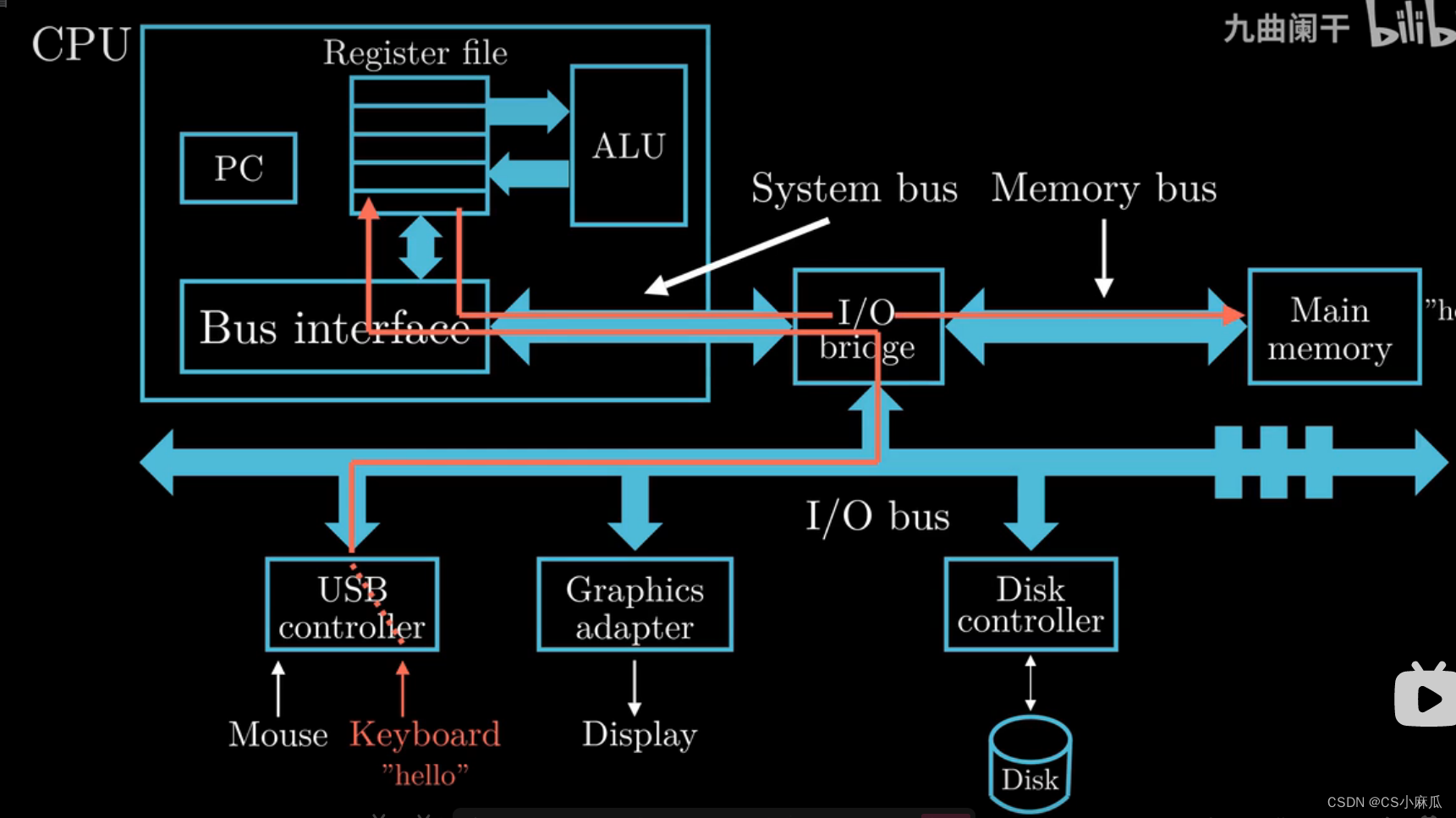
- 按下回车键,shell程序知道命令的输入完成,执行一系列的指令来加载可执行文件hello
- 这些指令将hello中的数据从磁盘复制到内存,数据(要显示输出的`Hello,World!\n`),利用DMA技术,数据不经过处理器直接从磁盘加载到内存
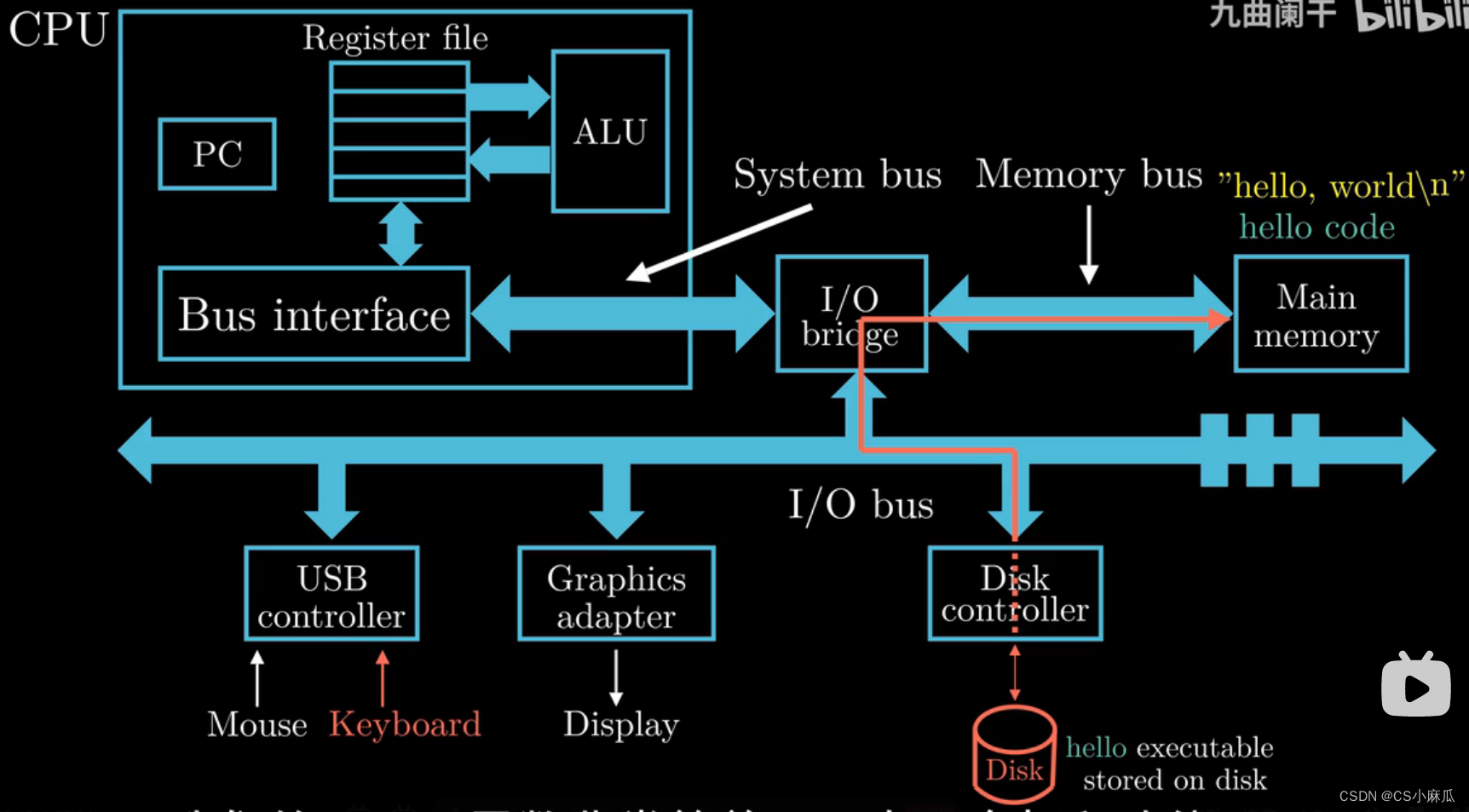
- . 当数据加载到内存中,处理器(CPU)开始执行main函数中的代码,CPU将会将`Hello,World!\n`这个字符串从内存复制到寄存器文件,然后再复制到显示设备,最终显示在屏幕上
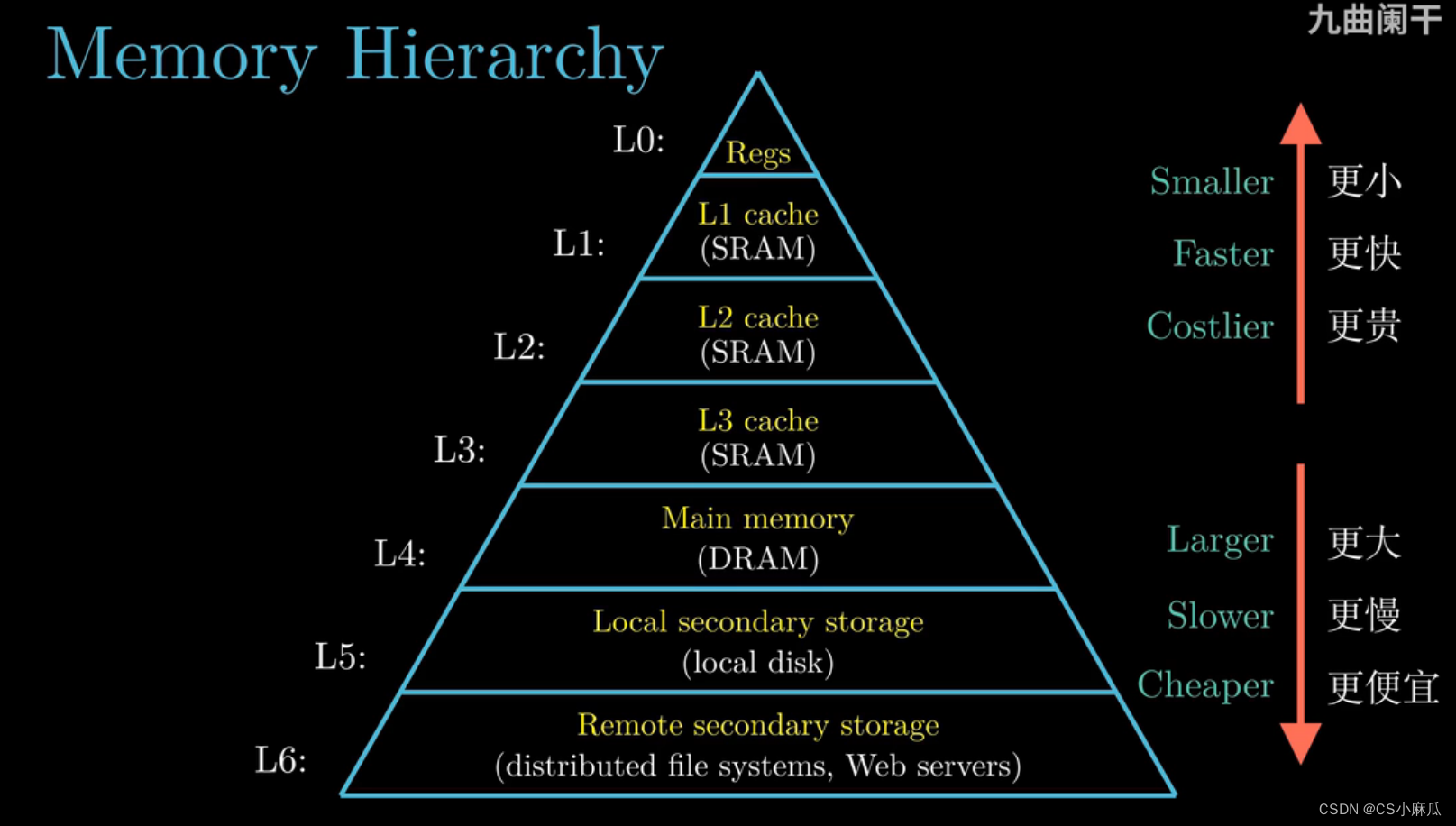
缓存器(Cashes Matter)
- 大容量的存储设备的存取速度比小容量的慢
- 运行速度更快的价格要高于低俗设备的价格
- 内存比寄存器要大得多,所以从内存上读取一个字的时间开销比从内存中读取的花销大1000万倍
- 解决方案:在寄存器文件和内存之间引入了高速缓存(cache)
- 高级的处理器一般为三级高速缓存:L1 cashe,L2 cashe,L3 cashe
- L1 cashe 的访问速度几乎与寄存器一致,容量大小为数万字节
- L2 cashe的访问速度是L1 cashe 的1/5,容量大小为数十万到百万字节之间
- L3 cashe的访问速度最慢,容量也更大

计算机系统信息存储层次结构
- 从上到小,访问速度越来越慢,每字节的造假也越来越便宜
- 主要思想:上一层的存储设备是下一层的存储设备的高速缓存
- 可以利用存储设备的层次结构来优化程序的性能
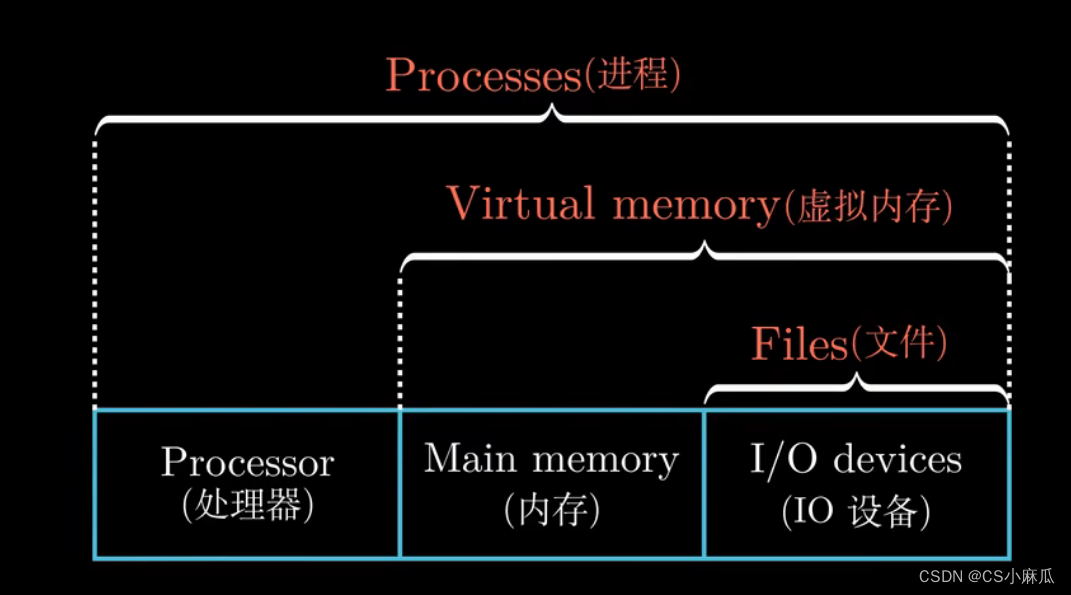
操作系统(The Operating Syetem Manages Hardware)
理解成应用程序和硬件之间的中间层,所有应用程序对硬件的操作都必须通过操作系统来完成。
设计目的:
- 防止硬件被失控的应用程序滥用
- 操作系统通过通一的机制来控制复杂的底层硬件
抽象概念:
- 文件是对IO设备的抽象
- 虚拟内存是对内存和磁盘IO的抽象
- 进程是对处理器,内存和IO设备的抽象
进程(Process)
- 通过hello进程来理解进程的概念
- 场景:只有两个并发的进程,shell进程和hello进程
- 刚开始只有shell进程在运行(在等待命令行输入)
- 通过shell进程来执行hello进程时
- 计算机的动作:请求--->shell进程----通过系统调用(system cell)---->执行请求---->将”控制权“传递---->操作系统---->保持shell的上下文 and 创建一个新的hello进程及其上下文---->将“控制权”传递---->hello进程----执行结束---->操作系统恢复shell进程上下文----将“控制权”传递---->shell进程,继续等待下一命令
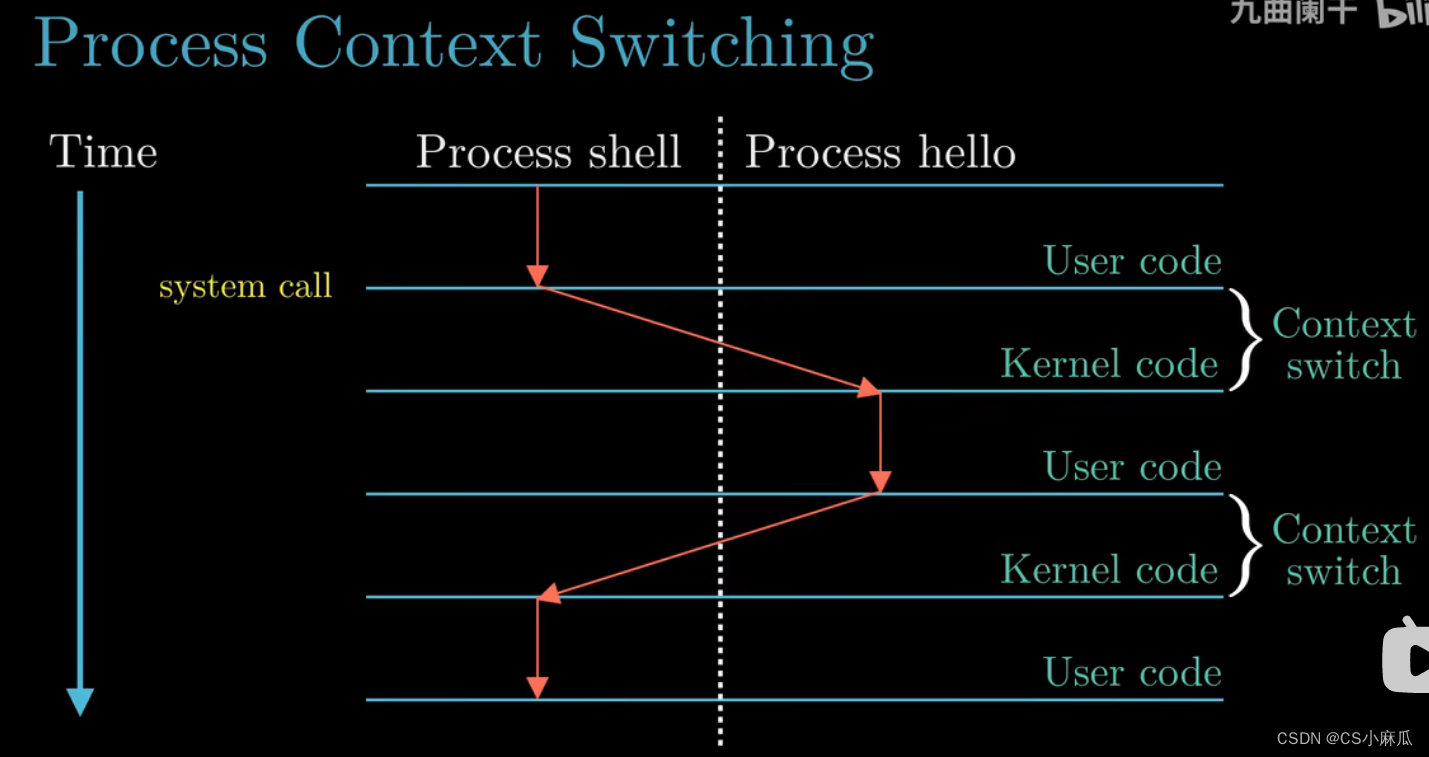
- (控制权的传递流程:shell进程,操作系统,hello进程)
- 计算机的动作:请求--->shell进程----通过系统调用(system cell)---->执行请求---->将”控制权“传递---->操作系统---->保持shell的上下文 and 创建一个新的hello进程及其上下文---->将“控制权”传递---->hello进程----执行结束---->操作系统恢复shell进程上下文----将“控制权”传递---->shell进程,继续等待下一命令
- 上下文(context)
- 操作系统会跟踪进程运行中所需要的所有状态信息,这种状态称为上下文,例如当前PC和状态寄存器中的值,以及内存中的内容等等
- 现在操作系统中,一个进程由多个线程组成,每个线程都运行在进程的上下文中,共享代码和数据,线程成为越来越重要的编程模型
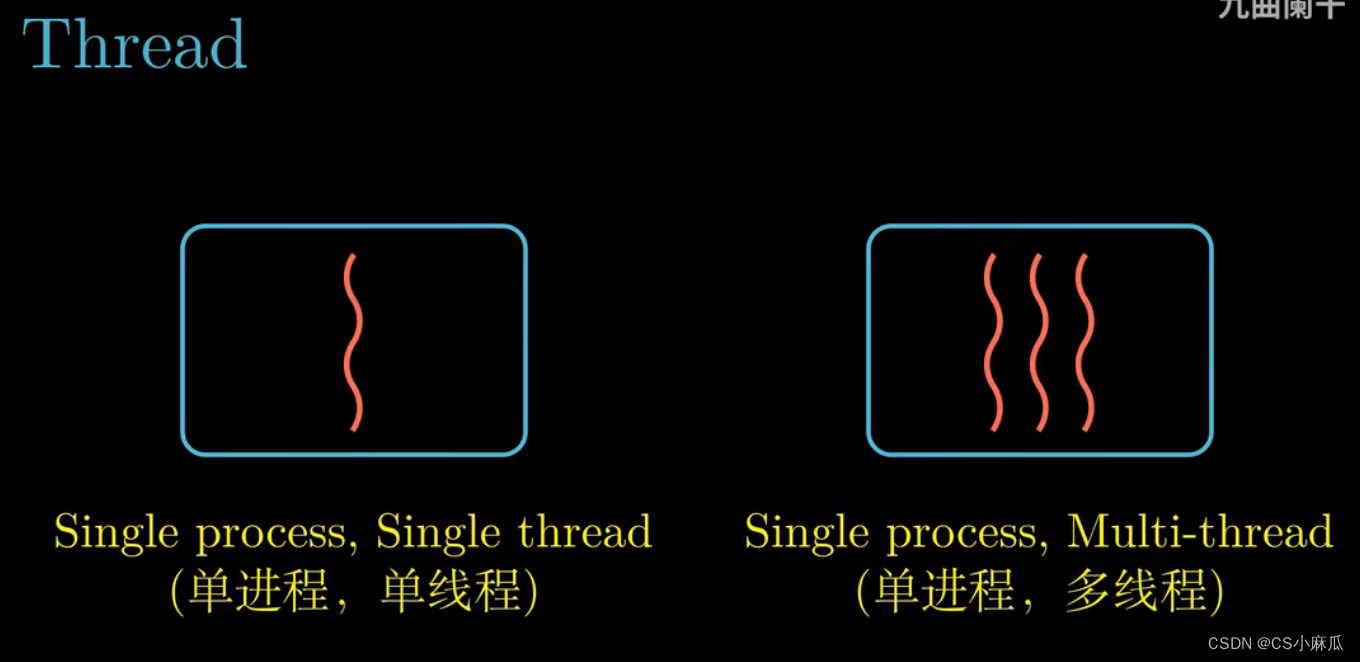
虚拟内存
- 它为每个进程提供了一个假象,每个进程都在独自占用整个内存空间,每个进程看到的内存都是一样的,我们称为虚拟地址空间
- 虚拟内存,从小到大,从0开始,最大容量受CPU地址长度限制(图示为什么是0 - 2^48-1?# x86-64处理器(CPU)只有48位虚拟地址空间,剩下的空间保留给内核)
空间分布:
- 读写数据区域(全局变量) and 只读区域:
- 作用:存放程序的代码和数据
- 内容:从可执行目标文件中加载来的
- 对所有的进程来说,代码都从固定的地址开始,例如c语言中的全局变量存放在这个区域
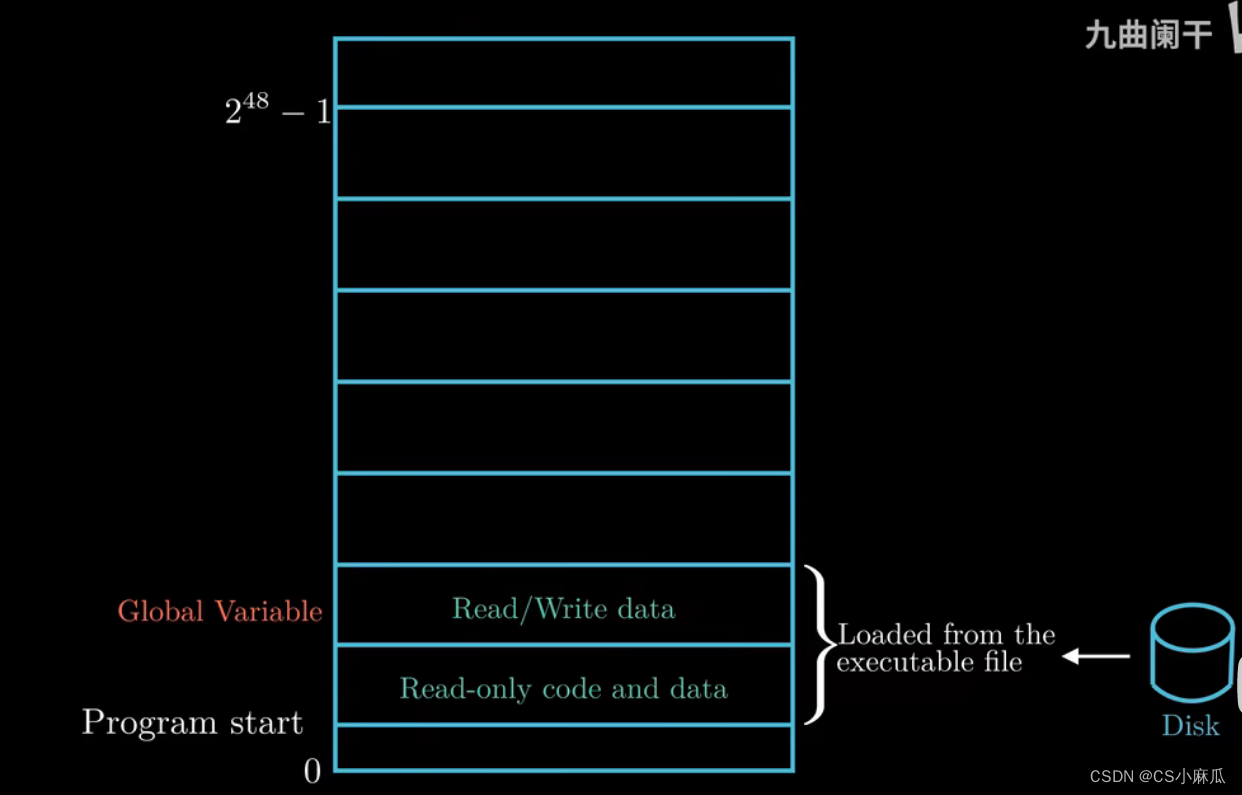
- 堆(heap)
- c语言中的molloc函数就是在堆区开辟只当的空间大小,但是堆可以在运行的时可以动态扩展和收缩
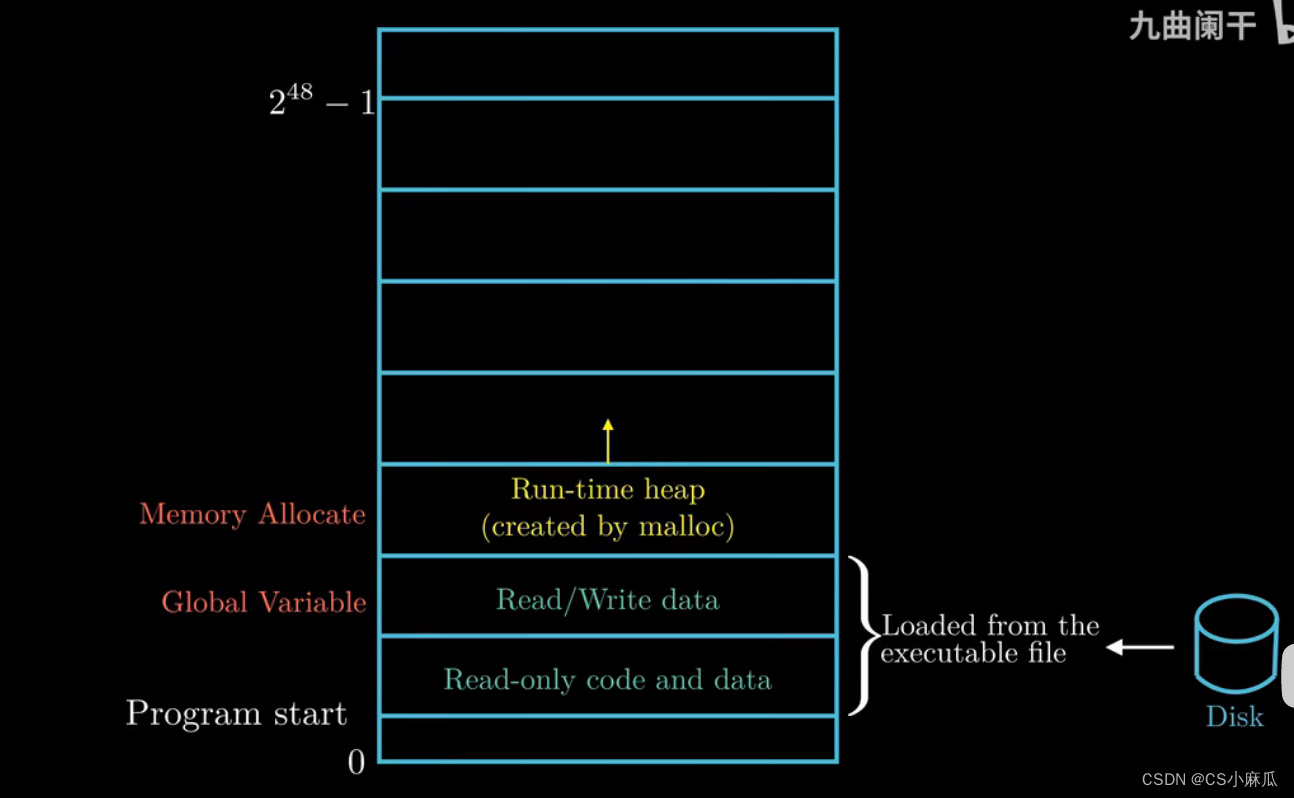
- c语言中的molloc函数就是在堆区开辟只当的空间大小,但是堆可以在运行的时可以动态扩展和收缩
- 共享库的存放区
- 主要存放c语言的标准库和数学库这种共享库的代码和数据
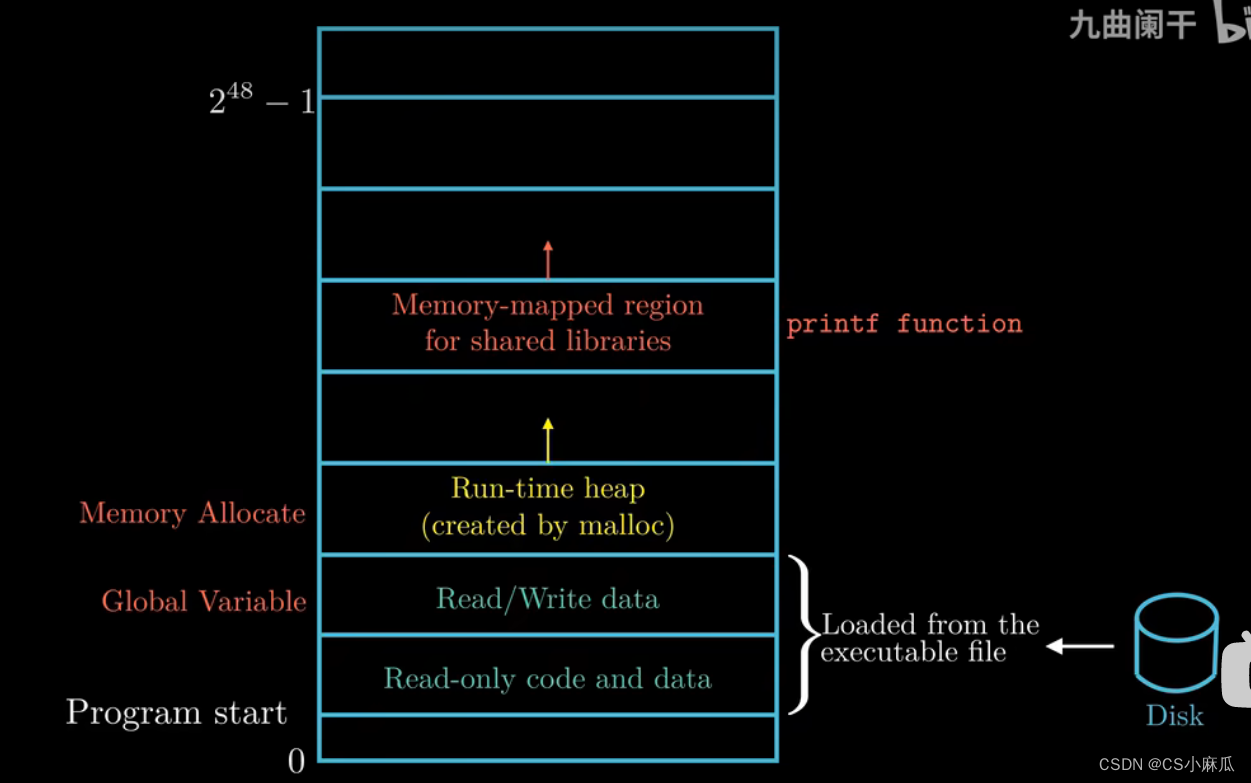
- 主要存放c语言的标准库和数学库这种共享库的代码和数据
- 用户栈(user stack)
- 每一次程序进行函数调用的时候,栈就会增长;函数执行完毕时,栈就会收缩
- 栈的增长方向:从高地址到低地址
- 顶部空间,为内核保留的区域
- 对应用程序不可见,不能调用函数,不能读写数据
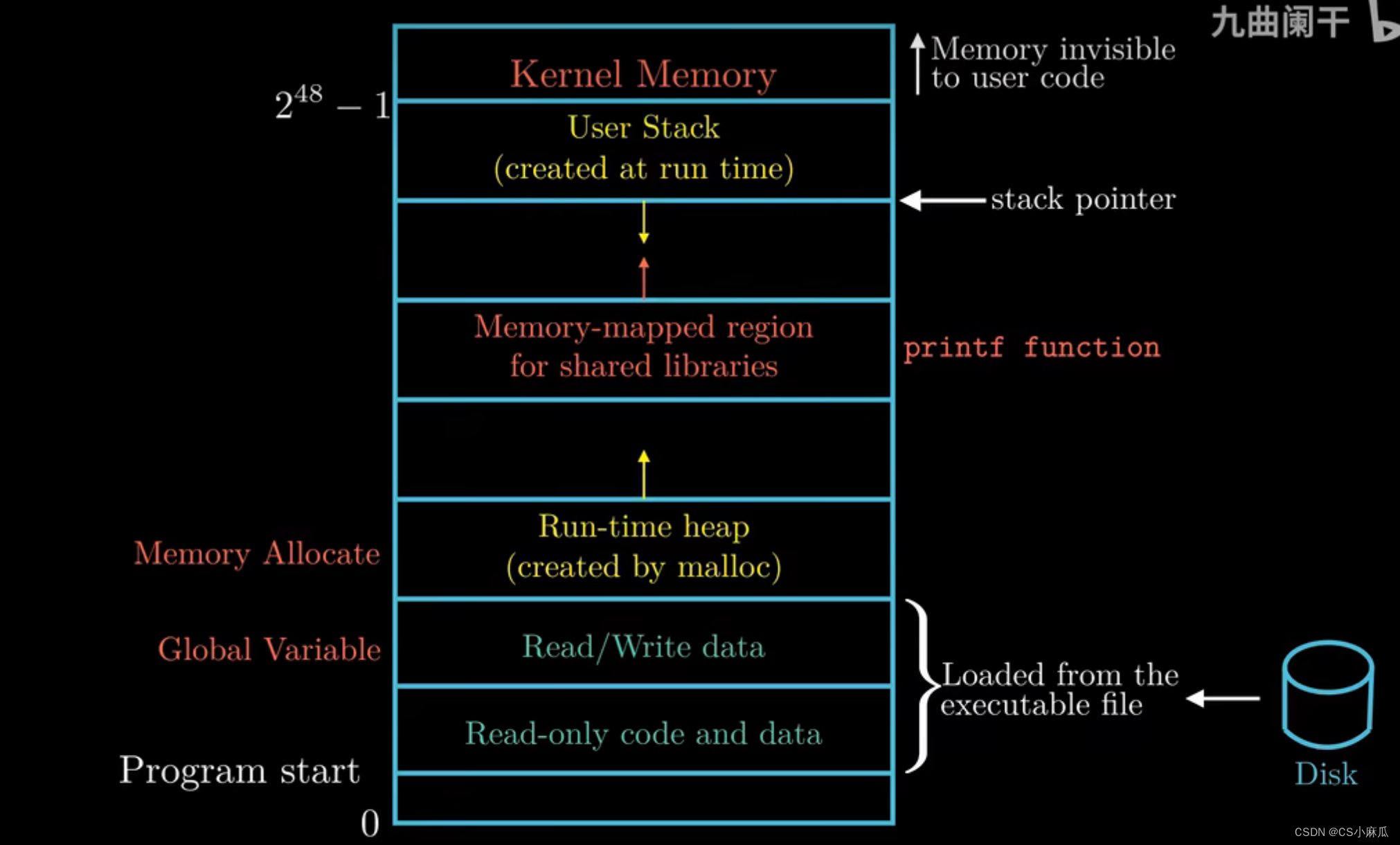
- 对应用程序不可见,不能调用函数,不能读写数据
Linux 系统哲学思想 :一切皆为文件
所有的IO设备(鼠标,键盘,磁盘,显示器,甚至网络)都可以看成文件,系统的输入输出都可以通过读写文件完成。
从系统的角度来看,网络设备也可以看作一个IO设备 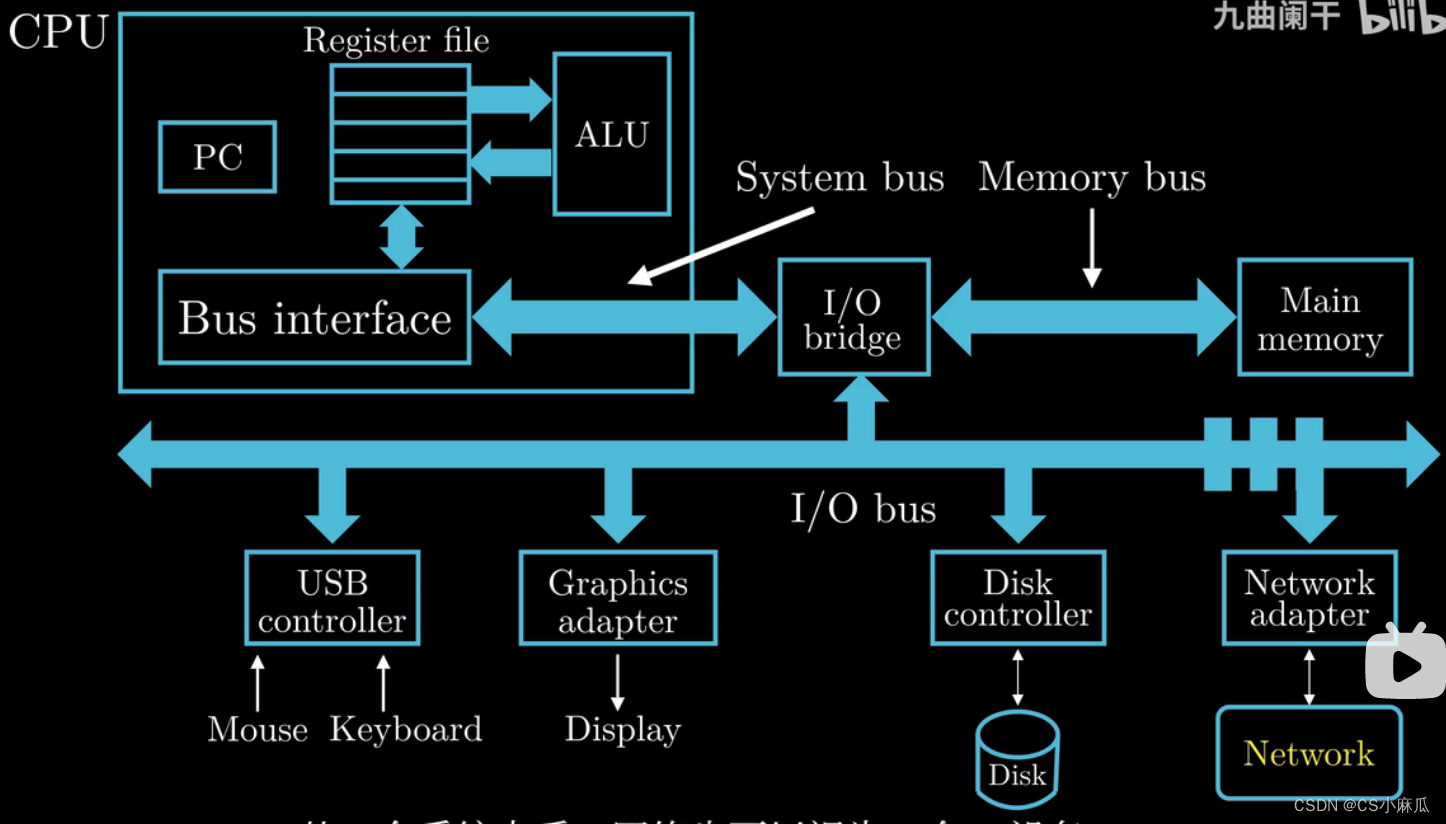
如何通过网络在远程主机上执行hello程序(web服务器)
- 利用telnet通过网络远程运行hello,由于telnet的安全性问题,目前ssh的连接方式更普遍

- 流程
- 在本地ssh客户端==输入hello字符串==并且==敲入回车==后----通过网络---->将字符串发送到ssh服务端---->ssh接受到字符串---->将字符串传送给远程主机上的shell程序---->shell程序负责hello程序的加载---->运行结果返回到ssh的服务端---->将程序的运行结果发送给ssh的客户端---->在屏幕上显示运行结果
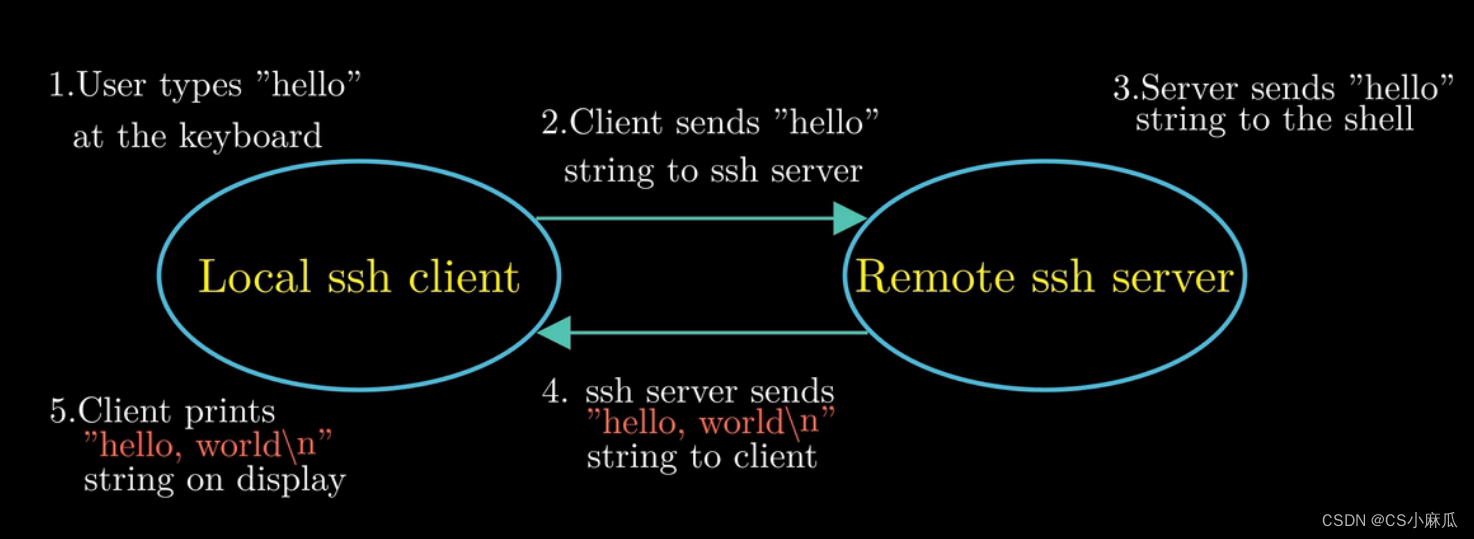
- 在本地ssh客户端==输入hello字符串==并且==敲入回车==后----通过网络---->将字符串发送到ssh服务端---->ssh接受到字符串---->将字符串传送给远程主机上的shell程序---->shell程序负责hello程序的加载---->运行结果返回到ssh的服务端---->将程序的运行结果发送给ssh的客户端---->在屏幕上显示运行结果
阿姆达尔定律(Amdahl's Law)
- 主要思想:对系统某一部分进行加速时,被加速部分的加速程度和重要性影响整体系统性能的关键因素
- 可加速部分为a,不可加速的部分就是1-a,可加速部分提升性能比例为k

- 例子
- 当a=0.6,k=3时,
- 当k->正无穷时,
,说明 如果要把计算机性能优化两倍那就要把大部分组件优化。

- 当a=0.6,k=3时,
获得更高的计算能力
- 线程级并发
- 指令集并行
- 单指令,多数据并行
多核处理器的组织结构
- 以四核处理器为例,举其中两个个CPU为例,其他两个个用省率号代替
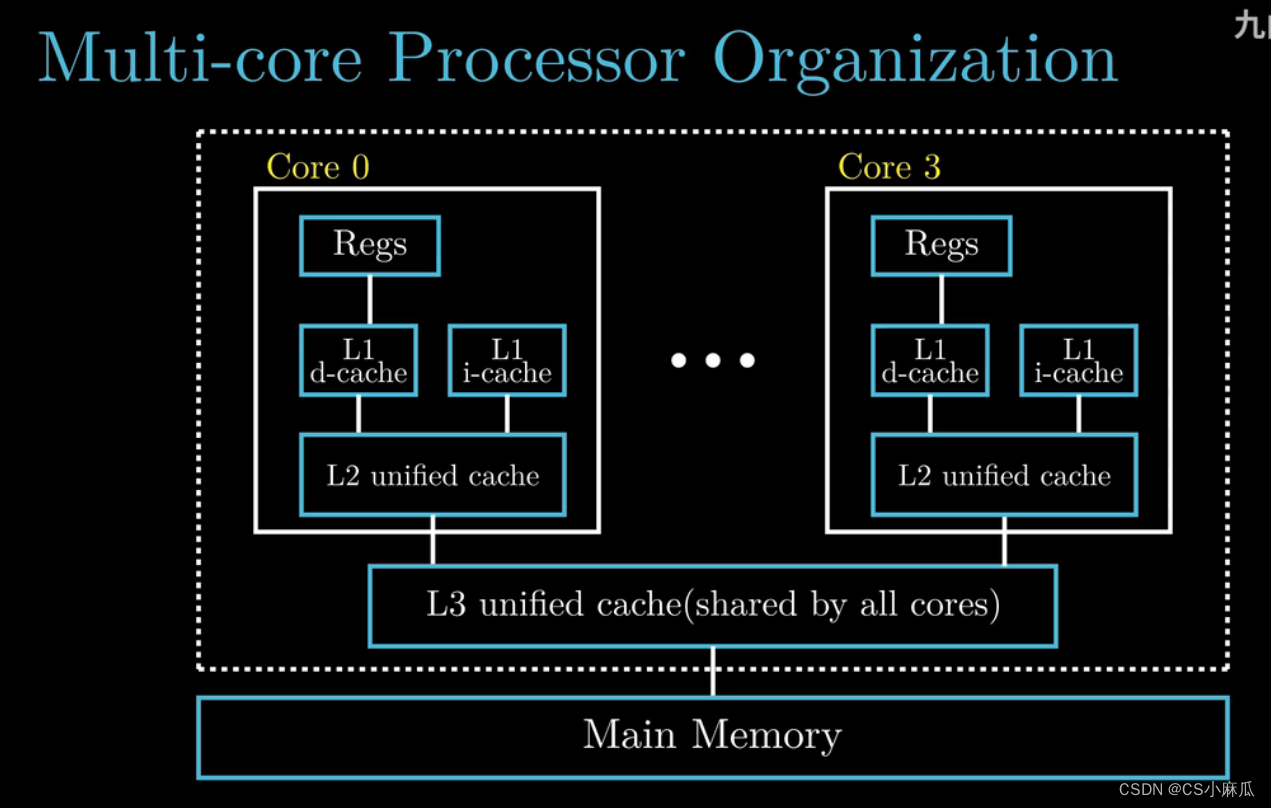
- 每个CPU核心都有自己的 寄存器组 L1 cashe 和 L2 cashe (高速缓存区),四个CPU核心共用一个L3 cashe,四个CPU核心集成在一个芯片上,通过增加CPU的核心数可以提高系统的性能
超线程(Hyperthreading)也称同时多线程
- 如果每个核心可以执行两个线程,那么四个核心就可以并行执行8个线程
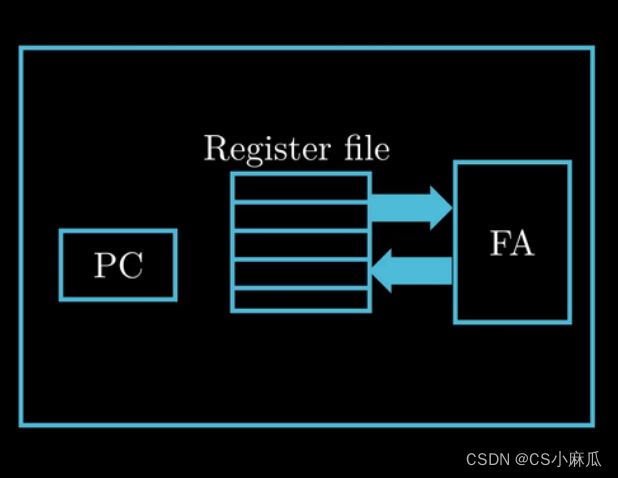
- 单个CPU的核心如何实现超线程
- CPU内部PC(程序计数器)和Reg(寄存器文件)有多个备份,而浮点运算部件(AU)只有一个
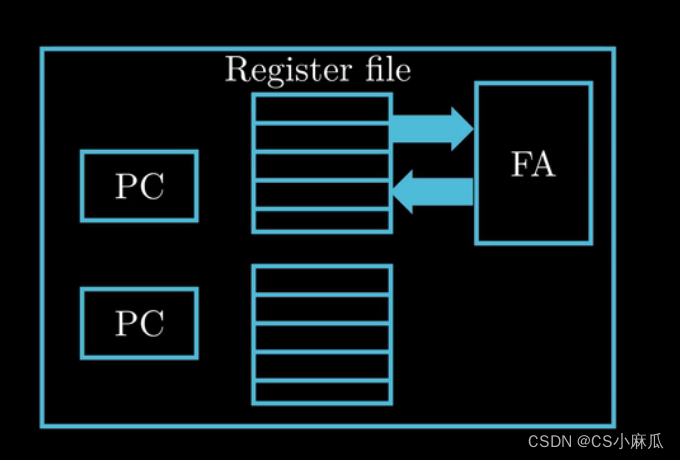
- 常规单线程处理器在做线程切换时,大概需要20000个时钟周期,而超线程可以在单线程的基础上决定执行哪一个线程,CPU可以更好的处理资源,当一个线程因为等待数据而进入等待状态时,CPU可以去执行另一个线程,其中线程之间的切换只需要极少的时间代价
- CPU内部PC(程序计数器)和Reg(寄存器文件)有多个备份,而浮点运算部件(AU)只有一个
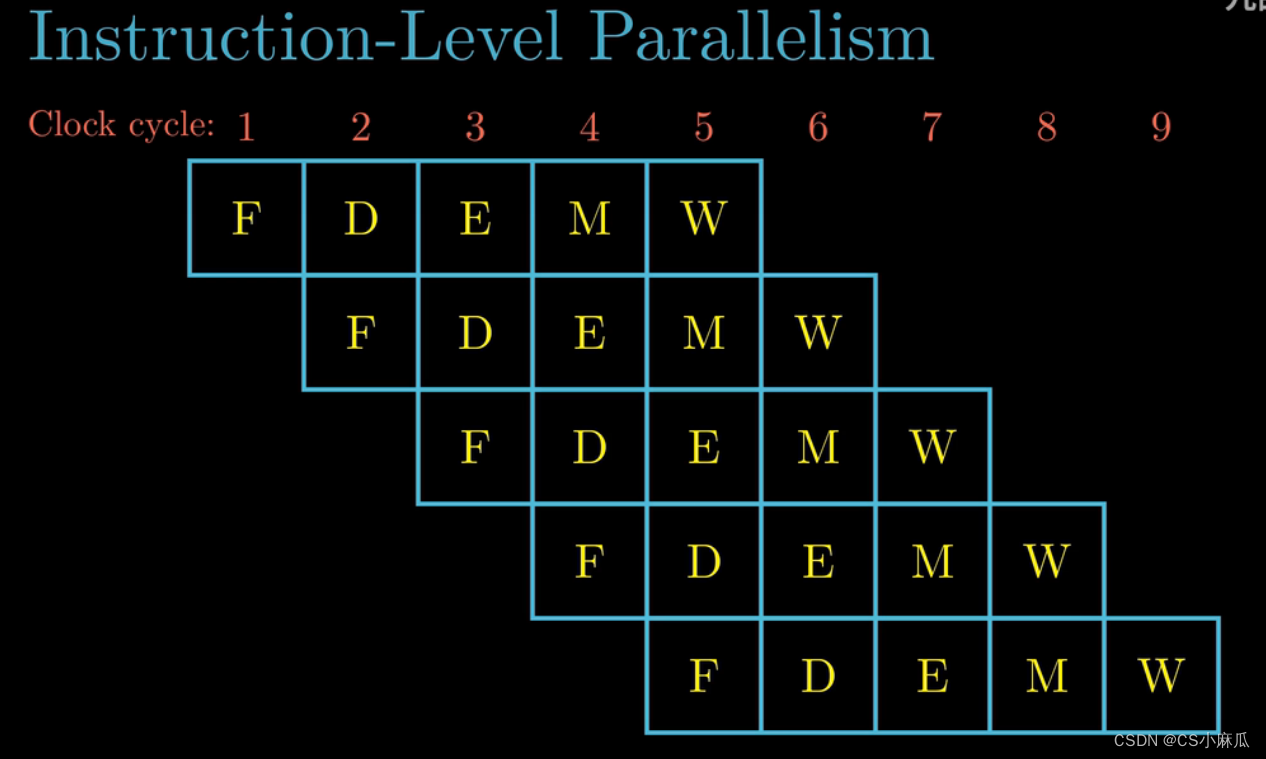
指令级并行(Instruction-Level Parallelism)
- 现代处理器可以同时执行多条指令的属性成为指令集并行,每条指令从开始到结束大概需要20个时钟周期或者更多,但是处理器采用了非常多的技巧可以同时处理多达100条指令,2020年的处理器可以保持每个周期同时执行2~4条指令的执行效率,具体体现是流水线技术
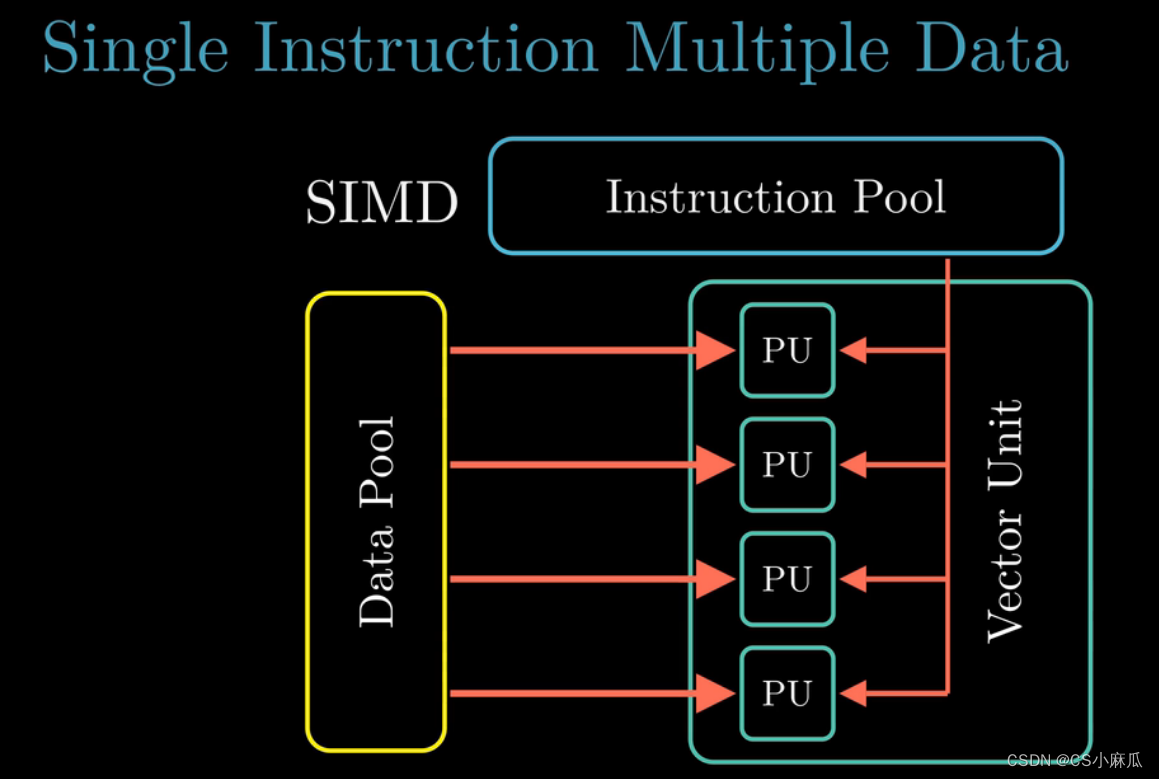
单指令多数据(Single Instruction Multi Data)
- 特殊的硬件部件
- 功能:允许一条指令执行多个并行的操作
- SIMD的指令多是为了提高梳理视频,以及声音这类数据的执行速度,比较新的Inter以及AMD的处理器都是支持SIMD指令加速的
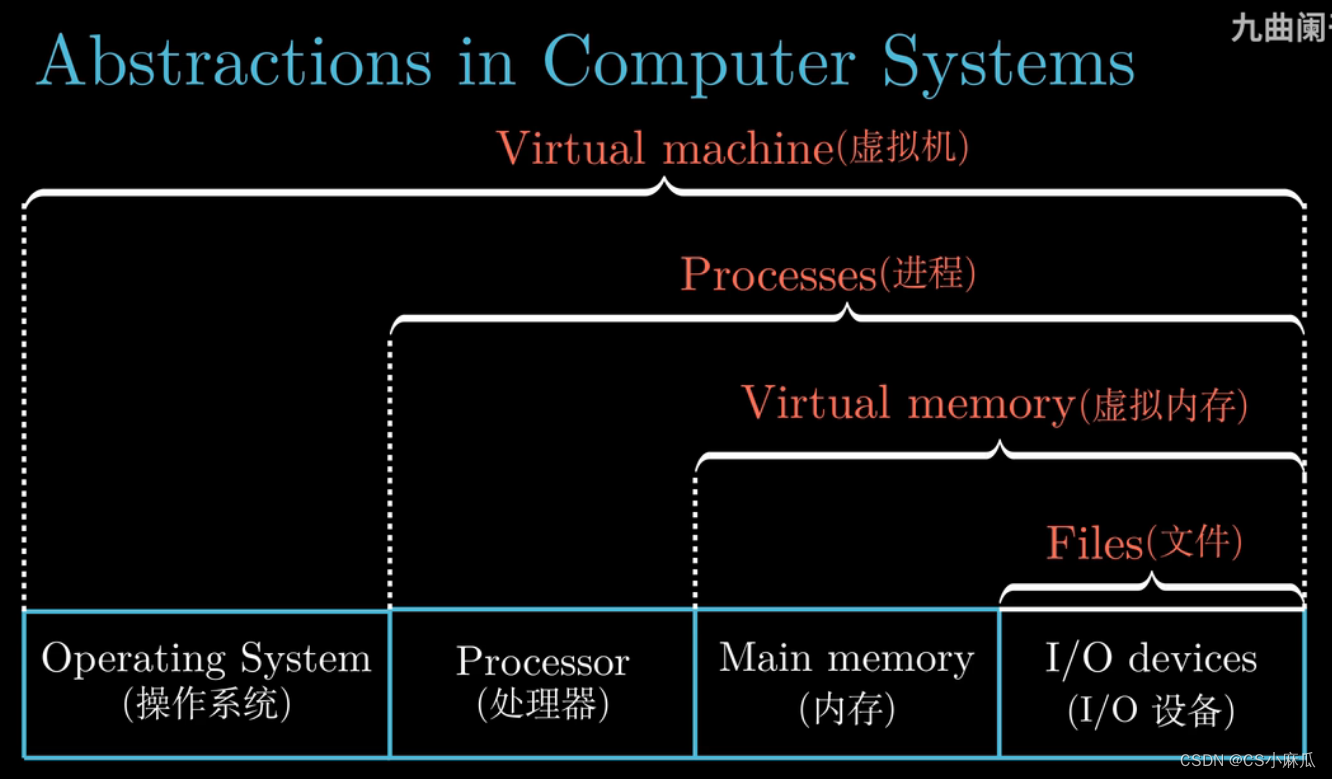
Abstraction in Computer System
四个抽象层次
- 文件(File) :对IO设备的抽象
- 虚拟内存(Virtual Memory):对IO设备和内存的抽象
- 进程(Process):对处理器,内存和IO设备的抽象
- 虚拟机(Virtual Machine):对操作系统,处理,内存和IO设备的抽象,即对计算机系统的抽象















 2490
2490











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









