






 本文介绍了ApacheHive作为分布式SQL计算工具的优势,包括其类SQL接口的易用性以及利用HadoopMapReduce处理大数据的能力。同时,详细解释了HDFS的块存储和副本机制,以确保数据安全性和可靠性。
本文介绍了ApacheHive作为分布式SQL计算工具的优势,包括其类SQL接口的易用性以及利用HadoopMapReduce处理大数据的能力。同时,详细解释了HDFS的块存储和副本机制,以确保数据安全性和可靠性。
Apache Hive的定义:
Apache Hive是一款分布式SQL计算的工具,其主要功能是将SQL语句 翻译成MapReduce程序运行。基于Hive为用户提供了分布式SQL计算的能力写的是SOL、执行的是MapReduce。
为什么使用Hive
1、使用Hadoop MapReduce直接处理数据所面临的问题
人员学习成本太高需要掌握java、Python等编程语言。MapReduce实现复杂查询逻辑开发难度太大
2、使用Hive处理数据的好处
操作接口采用类SQL语法,提供快速开发的能力(简单、容易上手)。底层执行MapReduce,可以完成分布式海量数据的SQL处理
HDFS的存储机制:
按块存储
hdfs对文件存储时默认是按照128M对文件数据拆分,拆分后存储在不同的DateNode服务器上 块数据存储在哪个服务器上实际是由NameNode决定的,其会找到空间充足的服务器进行存储。
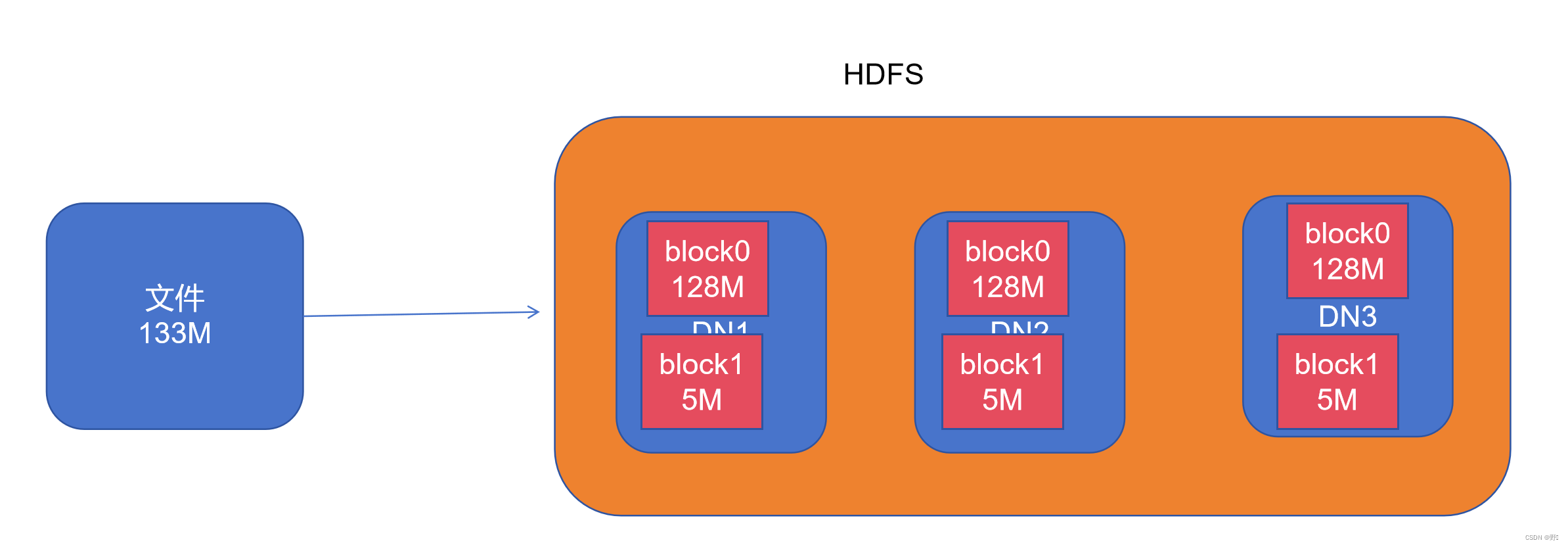
副本机制
为了避免数丢失,hdfs会对数据进行备份,默认会存储三份
第一份: 如果写请求方所在机器是其中一个DataNode,则直接存放在本地,否则随机在集群中选择一个DataNode.
第二份:第二个副本存放于不同第一个副本的所在的机架
第三份:第三个副本存放于第二个副本所在的机架,但是属于不同的服务器节点















 382
382

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









