






使用PPO强化学习增强LLM输出质量的实验
1. 实验背景与目标
最近Deepseek的r1模型在国内外火的没边,也是借着这股东风,想要深入了解一下RL对于LLM的增强效果到底有多强!在大语言模型(LLM)的应用中,我们也经常会遇到模型输出质量不稳定的问题。有时候回答过于简单,缺乏具体细节;有时候又过于发散,难以聚焦核心内容。本实验旨在探索如何通过强化学习(特别是PPO算法)来优化LLM的输出质量。
1.1 核心目标
- 提高模型输出的具体性和详实度
- 建立可量化的评估指标
- 实现自动化的优化过程
1.2 技术选型

| 超级可爱的羊驼嘻嘻🤭
- 基础模型:Gemma 2B(通过Ollama部署)
- 强化学习算法:PPO(Proximal Policy Optimization)
- 文本分析:jieba分词
- 开发语言:Python
2. 核心原理解析
2.1 PPO算法详解
PPO(Proximal Policy Optimization)是OpenAI在2017年提出的一种强化学习算法。为了便于理解,让我们通过一个简单的例子来解释:
2.1.1 基本概念
想象你在教一个小孩写作文:
- 策略(Policy):就是小孩当前写作文的方式
- 动作(Action):具体的写作选择(如用什么词、写什么内容)
- 状态(State):当前作文的内容和上下文
- 奖励(Reward):对作文质量的评分
2.1.2 PPO的核心思想
-
保守更新原则
- 传统方法:如果发现某个写作方式效果好,就立刻大幅改变写作方式
- PPO方法:即使发现更好的写作方式,也只小幅调整,避免"过度学习"
-
裁剪机制举例
# 假设原来的写作方式得分是0.5 old_policy_score = 0.5 # 新的写作方式得分是0.8 new_policy_score = 0.8 # 计算改进比例 improvement_ratio = new_policy_score / old_policy_score # = 1.6 # PPO裁剪:限制改进比例在[0.8, 1.2]范围内 clipped_ratio = clip(improvement_ratio, 0.8, 1.2) # = 1.2
2.1.3 在本实验中的应用
-
状态特征
# 文本特征作为状态 state = [ 词数, # 反映文本长度 句子数, # 反映结构复杂度 具体名词数, # 反映细节程度 动词数, # 反映动作描述 形容词数 # 反映描述生动性 ] -
动作空间
# 生成增强提示作为动作 action = f"""改进建议: 1. 增加{具体名词数 - 当前名词数}个具体名词 2. 增加{目标动词数 - 当前动词数}个动作描述 3. 增加{目标形容词数 - 当前形容词数}个生动形容词 """ -
奖励计算
# 根据文本特征计算奖励 reward = ( 具体名词数 * 0.4 + # 重视具体细节 动词数 * 0.3 + # 重视动作描述 形容词数 * 0.2 + # 重视描述生动性 词数 * 0.05 + # 适度考虑长度 句子数 * 0.05 # 适度考虑结构 )
2.1.4 PPO的优势
-
稳定性
- 通过裁剪机制防止过大更新
- 避免模型输出质量剧烈波动
-
效率
- 可以多次使用同一批数据
- 减少与语言模型的交互次数
-
实现简单
def ppo_update(self, old_policy, new_policy, advantage): # 计算策略改进比例 ratio = new_policy / old_policy # 裁剪比例 clip_ratio = np.clip(ratio, 1 - self.epsilon, 1 + self.epsilon) # 取最小值作为最终目标 final_objective = min( ratio * advantage, # 原始目标 clip_ratio * advantage # 裁剪后的目标 ) return final_objective
2.1.5 与传统强化学习的对比
| 特点 | 传统策略梯度 | PPO |
|---|---|---|
| 更新幅度 | 不受限制 | 通过裁剪控制 |
| 样本效率 | 每个样本只用一次 | 可多次使用 |
| 实现复杂度 | 较复杂 | 相对简单 |
| 训练稳定性 | 容易不稳定 | 更稳定 |
2.2 文本特征提取
我们设计了一个多维度的特征提取系统,用于评估文本的具体程度:
- 词数统计:反映回答的整体长度
- 句子数:衡量内容的结构复杂度
- 具体名词数:表示具体概念和实例的数量
- 动词数:反映动作描述的丰富程度
- 形容词数:体现描述的生动程度
特征提取代码示例:
def get_features(self, text):
words = list(jieba.cut(text))
sentences = re.split('[。!?]', text)
nouns = len([w for w in words if len(w) >= 2])
verbs = len([w for w in words if w.endswith('了') or w.endswith('着')])
adj = len([w for w in words if w.endswith('的')])
return np.array([
len(words),
len(sentences),
nouns,
verbs,
adj
])
2.3 奖励计算机制
我们设计了一个加权评分系统,不同特征具有不同的重要性:
def get_reward(self, text):
features = self.get_features(text)
specificity_score = (
features[2] * 0.4 + # 具体名词权重最高
features[3] * 0.3 + # 动词次之
features[4] * 0.2 + # 形容词再次
features[0] * 0.05 + # 词数影响较小
features[1] * 0.05 # 句子数影响较小
)
return specificity_score
3. 实验流程详解
3.1 基线模型调用
首先,我们使用原始的LLM模型生成回答:
def baseline_model(prompt):
response = ollama.chat(model="gemma2:2b", messages=[
{
"role": "system",
"content": "你必须始终使用中文回答。"
},
{
"role": "user",
"content": prompt
}
])
return response['message']['content']
3.2 RL增强过程
RL增强模型的工作流程如下:
- 获取基础回答:使用原始模型生成初始回答
- 特征提取:分析回答的文本特征
- 生成增强提示:基于PPO策略生成改进建议
- 获取增强回答:让模型基于改进建议优化输出
- 更新策略:计算奖励并更新PPO策略
def rl_enhanced_model(prompt, ppo_agent):
# 获取基础回答
base_text = baseline_model(prompt)
# 提取特征
state = ppo_agent.get_features(base_text)
# 生成增强提示
enhanced_prompt = f"""请根据以下要求改进你的回答:
1. 使用更多具体的名词和例子
2. 添加更多动作描述
3. 使用生动的形容词
4. 保持逻辑性和连贯性
原始问题: {prompt}
请改进这个回答: {base_text}"""
# 获取增强回答
enhanced_text = get_enhanced_response(enhanced_prompt)
# 更新策略
reward = ppo_agent.get_reward(enhanced_text)
ppo_agent.update(state, enhanced_text, reward)
return enhanced_text, reward
4. 实验结果分析
4.1 评估指标
我们使用以下指标来评估实验效果:
- 具体度分数:综合考虑文本的多个特征维度
- 改进幅度:RL模型分数与基线模型分数的差值
- 平均改进效果:所有测试案例的平均改进幅度
4.2 示例分析
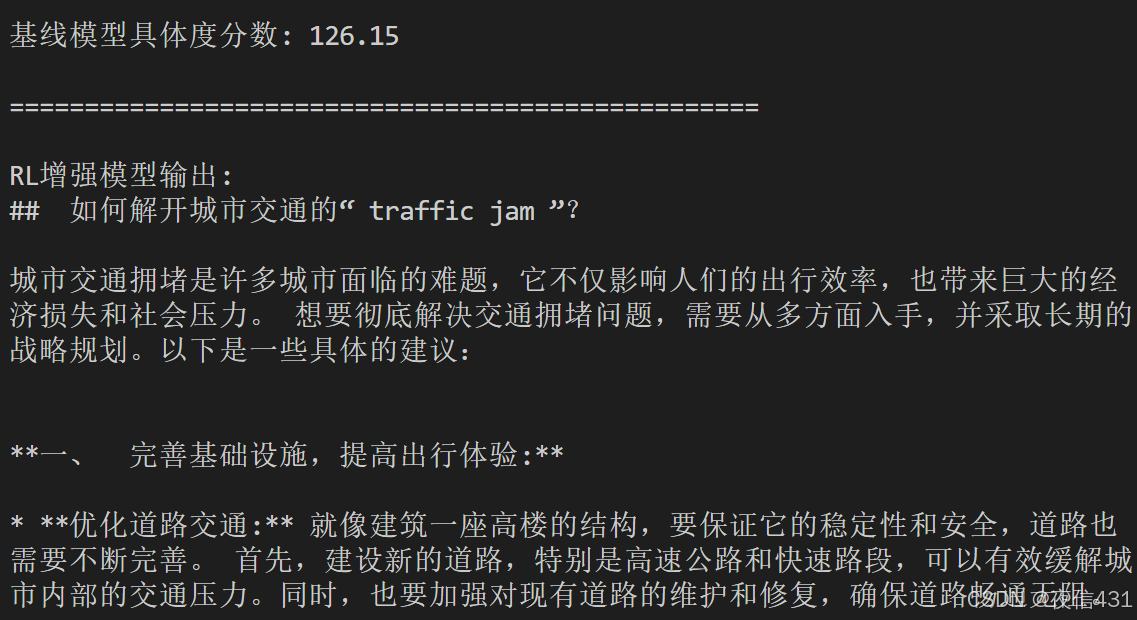
以"森林场景描述"为例,比较基线模型和RL增强模型的输出:
基线模型:
你走在左边的小路上,看到了一些树木和灌木。
RL增强模型:
你小心翼翼地踏上左边的泥泞小径,茂密的松树和橡树在头顶交织成一片深邃的绿色穹顶。潮湿的落叶在脚下发出沙沙声,远处隐约传来猫头鹰的啼叫。
可以看到,RL增强模型的输出:
- 使用了更多具体名词(松树、橡树、落叶、猫头鹰)
- 增加了动作描述(踏上、交织、传来)
- 添加了生动的形容词(茂密的、深邃的、潮湿的)
5. 优化建议
-
特征提取优化:
- 使用更专业的中文词性标注工具
- 添加语义相关性分析
- 考虑句子结构的复杂度
-
奖励机制改进:
- 引入人工评分数据
- 考虑上下文连贯性
- 添加任务相关的特定奖励
-
模型架构升级:
- 使用更复杂的策略网络
- 实现完整的PPO算法
- 添加值函数估计
6. 代码使用说明
6.1 环境配置
# 安装依赖
pip install numpy jieba ollama
# 启动Ollama服务
ollama serve
6.2 运行实验
# 准备测试用例
test_prompts = [
"你站在一个黑暗的森林里,前方有三条路。你决定向左走。接下来会发生什么?",
"请为一个科技公司设计一个创新的产品理念",
"如何解决城市交通拥堵问题?"
]
# 运行实验
run_experiment(test_prompts)
7. 总结与展望
本实验展示了如何使用PPO算法来优化大语言模型的输出质量。通过设计合理的特征提取和奖励机制,我们成功实现了对模型输出的自动化优化。这种方法具有以下优势:
- 可量化:提供了明确的评估指标
- 可扩展:易于添加新的特征和优化目标
- 自动化:无需人工干预的优化过程
未来的研究方向可以包括:
- 引入更复杂的NLP特征
- 设计任务特定的奖励函数
- 实现多目标强化学习
- 探索其他强化学习算法的应用
完整代码
import ollama
import time
import numpy as np
from collections import deque
import jieba
import re
class SimplePPO:
def __init__(self):
self.memory = deque(maxlen=1000) # 经验回放池
self.learning_rate = 0.01
self.epsilon = 0.2 # PPO裁剪参数
self.gamma = 0.99 # 折扣因子
# 简单的策略网络(这里用词向量长度作为特征)
self.weights = np.random.randn(5) # 5个特征:词数、句子数、具体名词数、动词数、形容词数
def get_features(self, text):
"""提取文本特征"""
words = list(jieba.cut(text))
sentences = re.split('[。!?]', text)
# 词性标注(简化版)
nouns = len([w for w in words if len(w) >= 2]) # 假设长度>=2的词更可能是具体名词
verbs = len([w for w in words if w.endswith('了') or w.endswith('着')])
adj = len([w for w in words if w.endswith('的')])
return np.array([
len(words), # 词数
len(sentences), # 句子数
nouns, # 具体名词数
verbs, # 动词数
adj # 形容词数
])
def get_reward(self, text):
"""计算奖励(基于回答的具体程度)"""
features = self.get_features(text)
# 奖励计算
specificity_score = (
features[2] * 0.4 + # 具体名词权重最高
features[3] * 0.3 + # 动词次之
features[4] * 0.2 + # 形容词再次
features[0] * 0.05 + # 词数影响较小
features[1] * 0.05 # 句子数影响较小
)
return specificity_score
def update(self, state, action, reward):
"""更新策略"""
self.memory.append((state, action, reward))
if len(self.memory) >= 10: # 每收集10个样本更新一次
self._train()
def _train(self):
"""训练策略网络"""
batch = list(self.memory)
states, actions, rewards = zip(*batch)
# 简化的PPO更新
for _ in range(3): # PPO迭代次数
for state, action, reward in zip(states, actions, rewards):
old_prob = self._get_prob(state)
new_prob = old_prob + self.learning_rate * reward
# PPO裁剪
ratio = new_prob / old_prob
clipped_ratio = np.clip(ratio, 1 - self.epsilon, 1 + self.epsilon)
# 更新权重
self.weights += self.learning_rate * min(ratio * reward, clipped_ratio * reward)
self.memory.clear()
def _get_prob(self, state):
"""获取动作概率(简化版)"""
return np.dot(state, self.weights)
def baseline_model(prompt):
"""基线模型:直接使用原始LLM"""
response = ollama.chat(model="gemma2:2b", messages=[
{
"role": "system",
"content": "你必须始终使用中文回答。"
},
{
"role": "user",
"content": prompt
}
])
return response['message']['content']
def rl_enhanced_model(prompt, ppo_agent):
"""使用PPO增强的模型"""
# 获取基础回答
base_response = ollama.chat(model="gemma2:2b", messages=[
{
"role": "system",
"content": "你必须始终使用中文回答。"
},
{
"role": "user",
"content": prompt
}
])
base_text = base_response['message']['content']
# 提取特征
state = ppo_agent.get_features(base_text)
# 根据PPO策略增强回答
enhanced_prompt = f"""请根据以下要求改进你的回答:
1. 使用更多具体的名词和例子
2. 添加更多动作描述
3. 使用生动的形容词
4. 保持逻辑性和连贯性
原始问题: {prompt}
请改进这个回答: {base_text}"""
response = ollama.chat(model="gemma2:2b", messages=[
{
"role": "system",
"content": "你必须始终使用中文回答。"
},
{
"role": "user",
"content": enhanced_prompt
}
])
enhanced_text = response['message']['content']
# 计算奖励并更新策略
reward = ppo_agent.get_reward(enhanced_text)
ppo_agent.update(state, enhanced_text, reward)
return enhanced_text, reward
def run_experiment(test_prompts):
"""运行对比实验"""
print("=== 开始实验 ===\n")
ppo_agent = SimplePPO()
results = []
for i, prompt in enumerate(test_prompts, 1):
print(f"\n测试案例 {i}:")
print(f"提示词: {prompt}\n")
print("基线模型输出:")
baseline_output = baseline_model(prompt)
baseline_score = ppo_agent.get_reward(baseline_output)
print(baseline_output)
print(f"\n基线模型具体度分数: {baseline_score:.2f}")
print("\n" + "="*50 + "\n")
time.sleep(2)
print("RL增强模型输出:")
rl_output, rl_score = rl_enhanced_model(prompt, ppo_agent)
print(rl_output)
print(f"\nRL模型具体度分数: {rl_score:.2f}")
print("\n" + "="*50 + "\n")
results.append({
'prompt': prompt,
'baseline_score': baseline_score,
'rl_score': rl_score,
'improvement': rl_score - baseline_score
})
# 输出实验统计
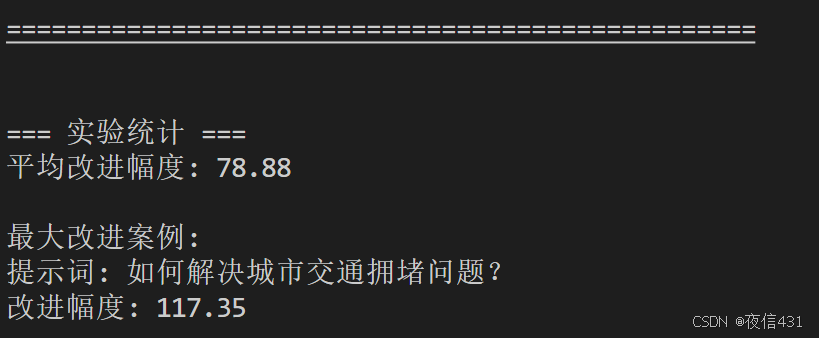
print("\n=== 实验统计 ===")
avg_improvement = np.mean([r['improvement'] for r in results])
print(f"平均改进幅度: {avg_improvement:.2f}")
best_case = max(results, key=lambda x: x['improvement'])
print(f"\n最大改进案例:")
print(f"提示词: {best_case['prompt']}")
print(f"改进幅度: {best_case['improvement']:.2f}")
# 测试用例
test_prompts = [
"你站在一个黑暗的森林里,前方有三条路。你决定向左走。接下来会发生什么?",
"请为一个科技公司设计一个创新的产品理念",
"如何解决城市交通拥堵问题?"
]
if __name__ == "__main__":
run_experiment(test_prompts)
结果展示:
参考资料
- PPO算法原论文:Proximal Policy Optimization Algorithms
- Ollama项目:https://github.com/ollama/ollama
- jieba分词:https://github.com/fxsjy/jieba

















 541
541

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









