






文章目录
1_测试过程分析
1.1_黑箱测试与白箱测试
- 黑箱测试:黑箱,意味着我们不知道代码的内部结构和具体实现,因此黑箱测试只针对代码的功能进行测试,只关心样例的输入与输出是否符合预期;
- 白箱测试:白箱,意味着我们掌握了代码的内部结构以及具体实现,需要根据给出的设计指导书(例如在Unit3中学习的JML),针对代码的内部结构以及具体实现进行多方面测试,包括代码的正确性、安全性以及性能等等;
1.2_对各种类型测试的理解
- 单元测试:指在代码实现中的最小可测试单元进行测试,结合我们学习的模块化设计思想,在OO中,最小可测试单元便是我们构造类中的方法,在做到高内聚低耦合的前提下,我们的每个方法都有明确的职责划分,因此我们可以针对这些功能进行测试,保证最底层代码的正确性,为代码整体的正确性奠定基础;
- 集成测试:与单元测试配套使用,在单元测试确保了最小可测试单元的正确性之后,我们需要将最小可测试单元进行组合形成层级更高的组件,并继续测试这些组件的正确性,这样可以使得在模块化设计中,每个层次的设计正确性都都以保证;
- 功能测试:指对代码需要实现的功能进行测试,和上文中的白箱测试类似,忽略代码的内部结构与具体实现,仅关注代码是否实现了预期的功能;
- 压力测试:对代码的空间性能、时间性能等的测试,在本单元作业中,针对于代码的时间性能进行了较强的压力测试,压力测试往往需要构造较为极端的边界测试样例,这些样例在实际项目中出现频率较低,较容易忽略,但往往是较容易出错误的点;
- 回归测试:指在对代码进行了迭代之后,对新代码进行测试,首先测试迭代后的代码是否引入了新的错误,接着测试迭代后的代码是否仍然能够实现迭代前功能需求,最后才是测试新代码是否能够满足新的需求,这一点在OO课程中非常重要,因为课程作业是单元迭代,同时涉及到了对旧代码进行debug以及优化,在这些环节后都必须进行回归测试,以保证迭代后代码的正确性以满足功能要求;
1.3_数据构造策略
在本单元的测试中,针对正确性与性能都进行了测试。
- 正确性:本单元的指令可以分为构造与查询两种,因为涉及到了图,因此数据构造围绕着图的构建进行,图的构建分为四个阶段:零图——>稀疏图——> 稠密图 ——> 完全图。在每个阶段都进行了大规模的各种查询指令的综合测试,以此来保证数据的覆盖率;
- 性能:主要是针对时间性能,构造了一些极端测试样例,根据方法的JML,找到存在至少两重for循环(即时间复杂度至少为O(n²))的查询方法,构造包含大量该类型查询指令的测试样例,以此来测试代码的时间性能;
2_架构设计
2.1_图模型
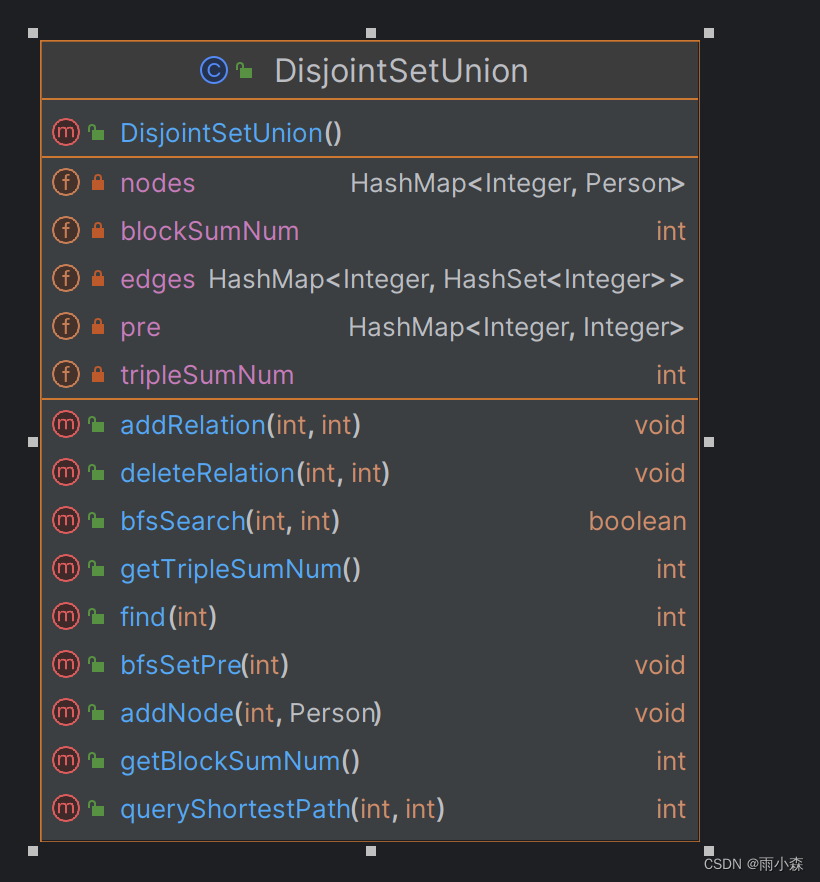
在本单元作业中,我定义了一个专门的类来实现图模型——DisjointSetUnion。
2.1.1_构建
-
类图:
-
模型解释:该图的节点为Person,边为Person之间的关系;
2.1.2_维护
- 并查集:在查询两个Person是否属于同一连通子图时,我采用了并查集的思路,因此需要维护一个
HashMap<Integer, Integer> pre来记录每一个节点的父节点;- 加节点:将该节点的父节点设置为自己;
- 加边:需要将其中一个节点设置为另外一个节点的父节点;
- 删边:需要判断删除后,这两个节点是否仍然连通,若连通,则无需修改父节点:若不连通,则进行广度优先遍历,从这两个节点出发更新每个节点的父节点;
- 极大连通子图:维护
int blockSumNum来记录图的极大连通子图数量,这样在查询时直接返回该值即可,做到时间复杂度为O(1);- 加边:判断这两个节点是否之前就属于同一个连通子图,若否,则
blockSumNum--; - 删边:判断这两个节点在删边之后是否仍然连通,若否,则
blockSumNum++;
- 加边:判断这两个节点是否之前就属于同一个连通子图,若否,则
- 三阶完全子图:维护
int tripleSumNum来记录图的三阶完全子图数量,这样在查询时直接返回该值即可,做到时间复杂度为O(1);- 加边:判断这两个节点有几个共同好友(即和某个点之间都有边),给
tripleSumNum加上该值; - 删边:判断这两个节点有几个共同好友,给
tripleSumNum减去该值;
- 加边:判断这两个节点有几个共同好友(即和某个点之间都有边),给
2.2_性能优化策略
在本单元的作业中,针对许多查询类型指令都需要进行优化,这些指令都是查询某一个特征量的值,因此我都沿用了上文中与维护图模型相同的维护标志属性的方法,下面我以query_tag_value_sum指令为例,介绍该方法:
[!NOTE] 维护标志属性
在Tag类中维护一个valueSum,这样在查询时直接返回该值即可,时间复杂度为O(1);
- 加人:遍历
Tag中已经有的人,判断是否与新加入的人存在关系,并更新valueSum的值;- 删人:遍历
Tag中已经有的人,判断是否与要删除的人存在关系,并更新valueSum的值;- 加关系:遍历
tagList(存放所有Tag的容器),找出所有同时包含这个关系的两人的Tag并更新其valueSum;- 修改关系:遍历
tagList,找出所有同时包含这个关系的两人的Tag并更新其valueSum;- 删关系:遍历
tagList,找出所有同时包含这个关系的两人的Tag并更新其valueSum;
3_BUG & 规格与实现分离
3.1_BUG分析
在第10次作业中,强测第10个数据点出现了CPU_TIME_LIMIT_EXCEED,该数据点中包含大量query_tag_value_sum指令,我针对该指令的实现是双重for循环,时间复杂度较高,因此出现了超时。
3.2_BUG修复
采用维护标志属性的方法,具体实现在上文2.2_性能优化策略处已经介绍。
3.3_规格与实现分离
在我的理解中,规格有几种作用:
- 对于不同情况的输入应该做出何种处理,可以同时存在多个并列的
normal_behavior与exceptional_behavior; - 输出结果应该满足的条件,在规格中给出的往往是最直观的实现方法,这一实现方法可以保证输出结果的正确性,但却不一定满足时间性能、空间性能等其他要求;
- 对实现过程副作用的约束,规格中会给出可以进行修改的范围,以及在实现结束后仍然需要满足的一些限制(例如按照升序排序等等),我们在具体实现中需要严格按照这些约束进行操作,以保证该处的操作不会给其他方法带来隐患。
正是因为上述第2点,所以一种规格可以有多种不同的具体实现,我们在构造自己的实现方法时,需要首先严格满足规格的这三种约束,在这一前提下,可以采用多样的算法设计来实现预期功能。
4_规格 & Junit测试
4.1_利用规格编写Junit
我在编写Junit时,一般分为两个部分:数据构造和assert断言设置。这两部分工作都可以参照规格进行设计:
- 数据构造:
- 阅读JML的requires,了解方法数据输入的合法情况有哪几种,然后根据这些合法情况分别进行数据构造;
- 阅读JML的assignable,清楚该方法可以对哪些属性进行修改,在数据构造时,对这些可修改数据按照稀疏——> 稠密的思路进行构造,以保证数据的覆盖率尽可能高;
- 阅读JML,判断是否存在pure,若存在,我们构造的数据需要包含较为全面的属性,以为后续的pure实现判断提供数据支持;
- assert断言设置:在本单元学习之前,编写的Junit往往只对结果的正确性进行测试,在学习了JML后,可以根据JML的ensures来设置assert断言,不仅对方法的正确性进行测试,同时也保证了不会带来其他副作用。
4.2_效果分析
我们知道对代码的测试存在多种类型,不同类型的测试首先都是要检验结果的正确性,这是最基础的一点,而根据JML进行测试编写,除了检验结果的正确性外,更多的是检验在具体实现中,是否仍然满足属性的某些约束,例如在某个int[] array进行了修改后,其是否仍然满足要求的降序排列,这一点可能不影响该方法结果的正确性,但是在后续其他方法利用这个数组进行实现时,就会出现错误。
5_单元学习体会
本单元主要就是学习了JML规格化设计,在单元刚开始的时候,虽然老师和助教已经说明了其重要性,但我其实还是对规格化设计的实用性存在怀疑:认为其总是把一些简单的、一句自然语言可以说明白的话给复杂化。但在第一次作业结束、开始第二次作业迭代之后,我的看法就发生了改变,以下三个方面让我真正体会到了JML的妙用:
- 代码结构严谨、逻辑清晰:我在第二次迭代的过程中感觉到非常顺利,究其原因,是得益于在第一次作业的实现中严格给出的JML进行类以及方法的设计,让我的代码结构严谨、逻辑清晰,大大方便了后续作业的迭代;
- 与他人交流思路无障碍:在之前两单元的作业中,每次与同学进行思路交流,由于大家的设计多种多样,类以及方法的接口都存在较大差异,好的想法不一定可以得到复用,而在本单元作业中,大家都严格按照JML规格进行设计,从宏观角度来看大家的架构具有相似性,因此我在与其他同学一起进行思路交流以及BUG分析的时候是否方便,几乎没有因为代码设计的原因而感到有障碍。
- BUG查找:在第三次作业中,我根据JML编写了Junit测试,其帮助我发现了一个评测机没有找到的bug,让我体会到了根据规格进行测试的好处,可以保证我们的测试的覆盖率尽可能大。















 931
931











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









