






目录
三.实现:利用sklearn实现数据集的手机完成鸢尾花的分类
4.加载鸢尾花数据集,调用sklearn库,获取到鸢尾花的数据集
一.k-近邻算法概述
KNN 算法,或者称 k-最近邻算法,是 有监督学习 中的 分类算法 。它可以用于分类或回归问题,但它通常用作分类算法。KNN 的全称是 K Nearest Neighbors,意思是 K 个最近的邻居。该算法用 K 个最近邻来干什么呢?其实,KNN 的原理就是:当预测一个新样本的类别时,根据它距离最近的 K 个样本点是什么类别来判断该新样本属于哪个类别(多数投票)
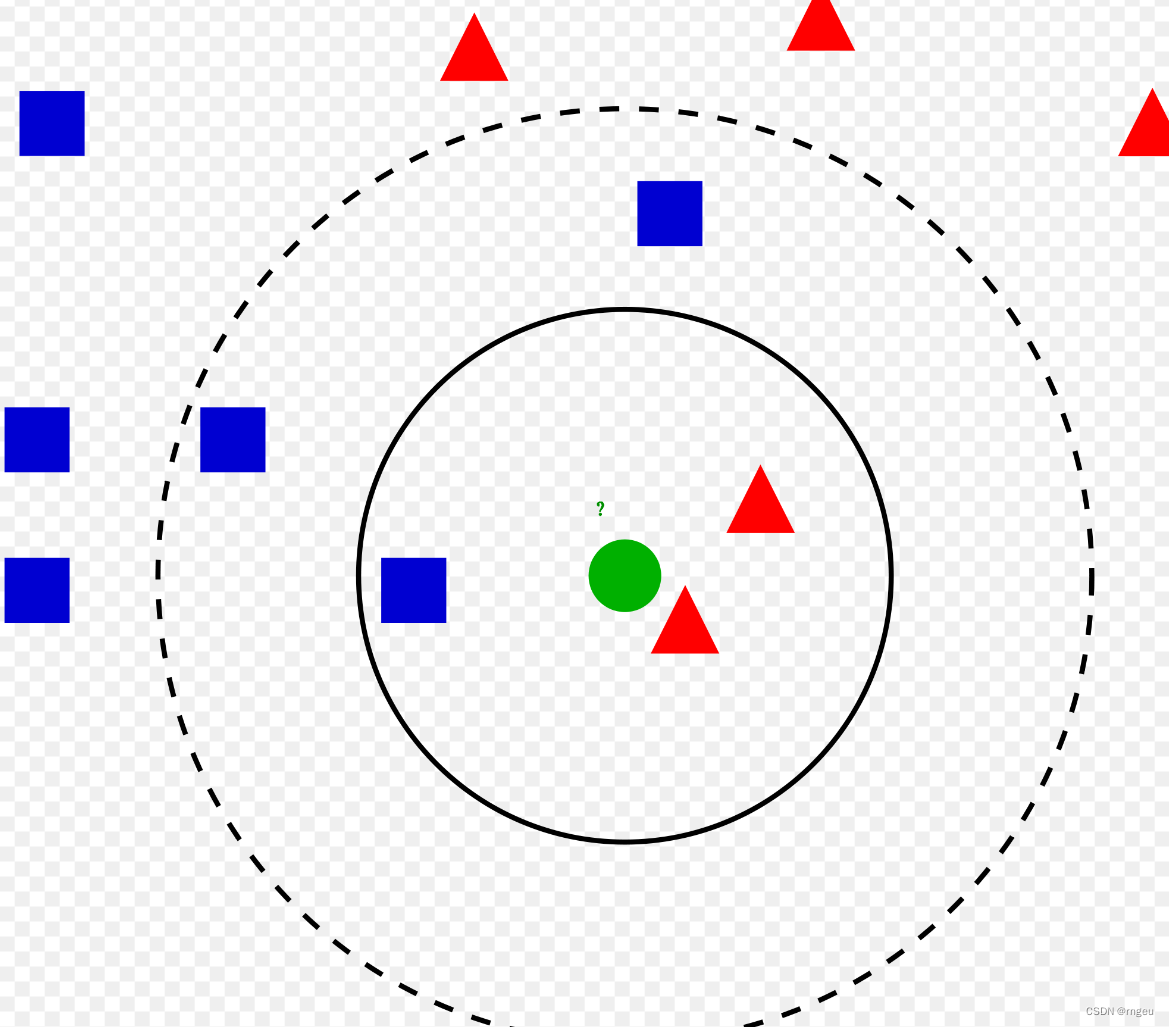
假设k=3,则测试数据中最相近的三个数据中有两个为三角形,则预测结果为三角形
1.KNN算法流程
(1)收集数据:收集带有标签的训练样本数据,其中每个样本都有一个标签,表示样本所属的类别或对应的数值
(2)选择K值:K的选择通常是通过交叉验证来确定,常见的取值范围是1到10之间
(3)计算距离:计算它与训练集中每个样本的距离。常用的距离度量方法包括欧氏距离、曼哈顿距离、闵可夫斯基距离等
(4)找出K个最近邻居:选择与新样本距离最近的K个训练样本作为最近邻居
(5)进行预测:根据K个最近邻居的标签进行投票,选择出现次数最多的类别作为新样本的预测类别
(6)评估模型:使用测试集数据评估模型的性能,常见的评估指标包括准确率、精确率
2.KNN算法的距离计算
闵可夫斯基距离:
当p>=1时,称为曼哈顿距离:
当p=2时,称为欧式距离:
3.有关k值的选择
k过大:预测标签比较稳定,可能过平滑,容易欠拟合
k过小:预测的标签比较容易受到样本的影响,容易过拟合
二.实现:电影类别的分类
1.实现了简单的基于KNN算法的电影分类器
首先简单的构建数据,数据集包含六部电影,每部电影取两个特征值(打斗镜头、接吻镜头),目的是将测试数据输入后能够通过KNN算法预测是属于爱情片还是动作片
rowdata = {'电影名称': ['无问西东', '后来的我们', '前任3', '红海行动', '唐人街探案', '战狼2'],
'打斗镜头': [1, 5, 12, 108, 112, 115],
'接吻镜头': [101, 89, 97, 5, 9, 8],
'电影类型': ['爱情片', '爱情片', '爱情片', '动作片', '动作片', '动作片']}2.代码实现
距离计算使用的是欧式距离
import pandas as pd
class Moviesort():
# 1、构建数据
rowdata = {'电影名称': ['无问西东', '后来的我们', '前任3', '红海行动', '唐人街探案', '战狼2'],
'打斗镜头': [1, 5, 12, 108, 112, 115],
'接吻镜头': [101, 89, 97, 5, 9, 8],
'电影类型': ['爱情片', '爱情片', '爱情片', '动作片', '动作片', '动作片']}
movie_data = pd.DataFrame(rowdata)
# 1、计算距离
def distance(self, new_data):
self.dist = list((((self.movie_data.iloc[:, 1:3] - new_data) ** 2).sum(1)) ** 0.5)
return self.dist
# 2、找出前k个距离最近的值
def dist_label(self, k):
result = []
# 将距离与标签对应
d_l = pd.DataFrame({'dist': self.dist, 'label': (self.movie_data.iloc[:, 3])})
# 对距离值做升序
d_v = d_l.sort_values(by='dist')[:k]
# 对前k个标签进行统计
label_num = d_v.loc[:, 'label'].value_counts()
re = label_num.index[0]
result.append(re)
self.result = result
return self.result
def main():
m = Moviesort()
dist = m.distance([108, 5])
print(dist)
result = m.dist_label(4)
print(result)3.运行结果

可见,在输入测试数据的特征值为[108,5]时以及电影数据集中各个电影之间的距离,预测的结果为动作片
三.实现:利用sklearn实现数据集的手机完成鸢尾花的分类
Scikit-learn(简称sklearn)是一个用于机器学习的Python库,它建立在NumPy、SciPy和Matplotlib等科学计算库的基础上。Scikit-learn提供了各种机器学习算法和工具,包括分类、回归、聚类、降维、模型选择和数据预处理等功能。它的设计简单而高效,易于使用,因此成为了Python中广泛使用的机器学习库之一。
1.导入所需要的库
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pdclass KNN(object):2.数据集简介及显示
鸢尾花数据集记录了三个类别(山鸢尾/0,虹膜锦葵/1,变色鸢尾/2),
每个类别50个样本,每个样本四个特征值(萼片长度,萼片宽度,花瓣长度,花瓣宽度)
我们的目标是当输入一个测试数据时通过KNN算法获得预测结果。
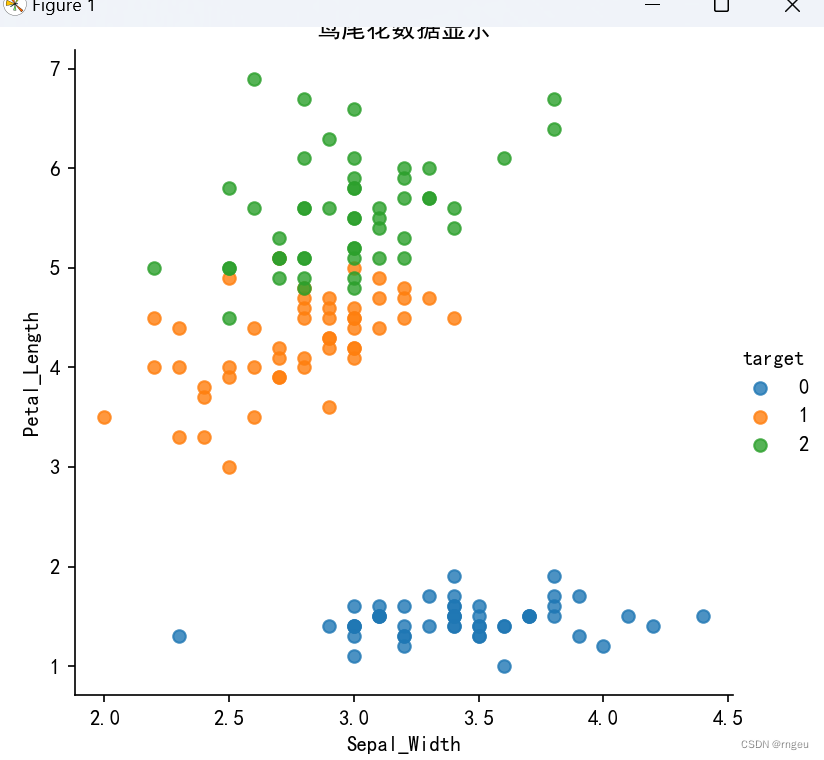
3.数据集显示代码
def iris_plot(data, x_col, y_col):
sns.lmplot(x=x_col, y=y_col, data=data, hue="target", fit_reg=False)
plt.title("鸢尾花数据显示")
plt.show()
# 设置字体为中文黑体
plt.rcParams['font.sans-serif'] = ['SimHei']
# 加载数据集
iris = load_iris()
# 创建数据框
iris_df = pd.DataFrame(data=iris.data, columns=['Sepal_Length', 'Sepal_Width', 'Petal_Length', 'Petal_Width'])
iris_df["target"] = iris.target
# 绘制图表
iris_plot(iris_df, 'Sepal_Width', 'Petal_Length')4.加载鸢尾花数据集,调用sklearn库,获取到鸢尾花的数据集
def get_iris_data(self):
iris = load_iris()
iris_data = iris.data
iris_target = iris.target
return iris_data, iris_target5.实现 KNN 分类器的训练和测试
def run(self):
iris_data, iris_target = self.get_iris_data()
x_train, x_test, y_train, y_test = train_test_split(iris_data, iris_target, test_size=0.25)
std = StandardScaler()
x_train = std.fit_transform(x_train)
x_test = std.transform(x_test)
knn = KNeighborsClassifier(n_neighbors=5)
knn.fit(x_train, y_train)
y_predict = knn.predict(x_test)
labels = ["山鸢尾", "虹膜锦葵", "变色鸢尾"]
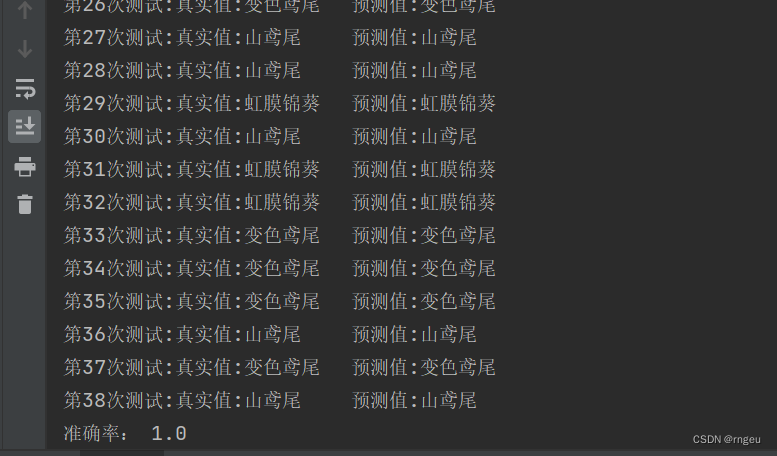
for i in range(len(y_predict)):
print("第%d次测试:真实值:%s\t预测值:%s" % ((i + 1), labels[y_test[i]], labels[y_predict[i]]))
print("准确率:", knn.score(x_test, y_test))if __name__ == '__main__':
knn = KNN()
knn.run()
6.运行结果
四.实验结论
K最近邻(KNN)算法是一种简单而有效的监督学习算法,其原理是基于实例的学习,通过对特征空间中最近的K个邻居的投票来进行分类或回归。
具有以下优点和缺点:
优点:
- 简单易理解:KNN算法的原理简单直观,易于理解和实现。
- 无需训练:KNN是一种懒惰学习(lazy learning)算法,无需显式地训练模型,在预测时仅需计算距离。
- 适用于多分类问题:KNN算法适用于多分类问题,且对类别不平衡的数据集也能处理得较好。
- 对异常值不敏感:由于KNN算法基于距离度量,对于异常值不敏感,不会受到异常值的影响。
缺点:
- 计算复杂度高:KNN算法在预测时需要计算待预测样本与所有训练样本的距离,计算复杂度较高,尤其是对于大型数据集。
- 存储空间大:KNN算法需要保存全部训练样本,占用存储空间较大。
- 预测速度慢:由于需要计算距离,预测速度相对较慢,特别是在特征空间维度较高时。
- 需要调参:KNN算法中的K值需要人工设定,选择不当可能导致模型性能下降。
综上所述,KNN算法简单而有效,适用于一些简单的分类问题,但在处理大型数据集和高维特征空间时可能面临计算复杂度高、存储空间大和预测速度慢的问题。同时,KNN算法需要谨慎选择K值,并且对数据预处理和特征选择要求较高。















 4366
4366











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









