







目录
2.多次 open 打开同一个文件,在内存中并不会存在多份动态文件。
总结:所以:多次 open 打开同一个文件,共用的是同一块缓存区
一 Linux 系统如何管理文件
1.1静态文件与inode
文件在没有被打开的情况下一般都是存放在磁盘中的,譬如电脑硬盘、移动硬盘、U 盘等外部存储设 备,文件存放在磁盘文件系统中,并且以一种固定的形式进行存放,我们把他们称为静态文件。
文件储存在硬盘上,硬盘的最小存储单位叫做“扇区(”Sector),每个扇区储存 512 字节(相当于 0.5KB), 操作系统读取硬盘的时候,不会一个个扇区地读取,这样效率太低,而是一次性连续读取多个扇区,即一次 性读取一个“块”(block)。这种由多个扇区组成的“块”,是文件存取的最小单位。“块”的大小,最常 见的是 4KB,即连续八个 sector 组成一个 block。
所以由此可以知道,静态文件对应的数据都是存储在磁盘设备不同的“块”中,那么问题来了,我们在 程序中调用 open 函数是如何找到对应文件的数据存储“块”的呢,难道仅仅通过指定的文件路径就可以实现?
我们的磁盘在进行分区、格式化的时候会将其分为两个区域,一个是数据区,用于存储文件中的数据; 另一个是 inode 区,用于存放 inode table(inode 表),inode table 中存放的是一个一个的 inode(也成为 inode节点),不同的 inode 就可以表示不同的文件,每一个文件都必须对应一个 inode,inode 实质上是一个结构 体,这个结构体中有很多的元素,不同的元素记录了文件了不同信息,譬如文件字节大小、文件所有者、文 件对应的读/写/执行权限、文件时间戳(创建时间、更新时间等)、文件类型、文件数据存储的 block(块) 位置等等信息,如下图 中所示(这里需要注意的是,文件名并不是记录在 inode 中)
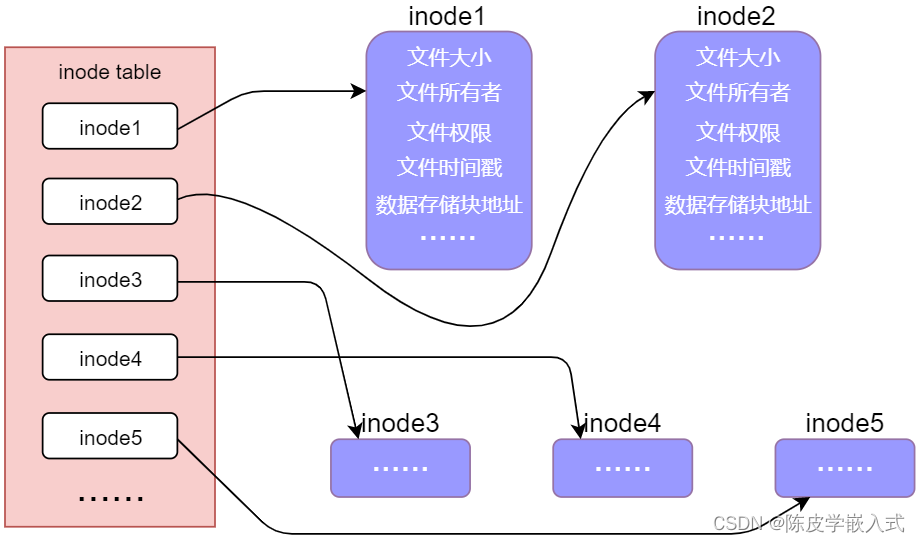
所以由此可知,inode table 表本身也需要占用磁盘的存储空间。每一个文件都有唯一的一个 inode,每 一个 inode 都有一个与之相对应的数字编号,通过这个数字编号就可以找到 inode table 中所对应的 inode。
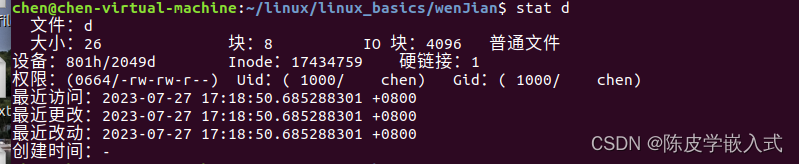
在 Linux 系统下,我们可以通过"ls -i"命令查看文件的 inode 编号,如下所示:

上图中 ls 打印出来的信息中,每一行前面的一个数字就表示了对应文件的 inode 编号。除此之外,还可 以使用 stat 命令查看,用法如下:
通过以上介绍可知,打开一个文件,系统内部会将这个过程分为三步:
- 系统找到这个文件名所对应的 inode 编号;
- 通过 inode 编号从 inode table 中找到对应的 inode 结构体;
- 根据 inode 结构体中记录的信息,确定文件数据所在的 block,并读出数据。
静态文件小总结:
磁盘分为两个区域,数据区(用于存储文件中的数据)和inode 区(inode 表),每一个文件都对应一个 inode,inode 实质上是一个结构 体,这个结构体中记录了文件了不同信息,通过 inode 编号从 inode table 中找到对应的 inode 结构体,根据 inode 结构体中记录的信息,确定文件数据所在的 block,并读出数据。
1.2文件打开时的状态
当我们调用 open 函数去打开文件的时候,内核会申请一段内存(一段缓冲区),并且将静态文件的数 据内容从磁盘这些存储设备中读取到内存中进行管理、缓存(也把内存中的这份文件数据叫做动态文件、内核缓冲区)。打开文件后,以后对这个文件的读写操作,都是针对内存中这一份动态文件进行相关的操作, 而并不是针对磁盘中存放的静态文件。
当我们对动态文件进行读写操作后,此时内存中的动态文件和磁盘设备中的静态文件就不同步了,数据的同步工作由内核完成,内核会在之后将内存这份动态文件更新(同步)到磁盘设备中。由此我们也可以联 系到实际操作中,譬如说:
- 打开一个大文件的时候会比较慢;
- 文档写了一半,没记得保存,此时电脑因为突然停电直接掉电关机了,当重启电脑后,打开编写的 文档,发现之前写的内容已经丢失。
明明也有不少缺点,为什么要这样设计?
ROM是只读存储器,RAM是临时存储器,Flash是非易失性存储器,SRAM是速度非常快的RAM。
因为磁盘、硬盘、U 盘等存储设备基本都是 Flash 块设备,因为块设备硬件本身有读写限制等特征,块设备是以一块一块为单位进行读写的(一个块包含多个扇区,而一个扇区包含多个字节),一个字节的改动 也需要将该字节所在的 block 全部读取出来进行修改,修改完成之后再写入块设备中,所以导致对块设备的 读写操作非常不灵活;
而内存可以按字节为单位来操作,而且可以随机操作任意地址数据,非常地很灵活, 所以对于操作系统来说,会先将磁盘中的静态文件读取到内存中进行缓存,读写操作都是针对这份动态文 件,而不是直接去操作磁盘中的静态文件,不但操作不灵活,效率也会下降很多,因为内存的读写速率远比 磁盘读写快得多。
在 Linux 系统中,内核会为每个进程设置一个专门的数据结构用于管理该进程,譬如用于记录进程的状态信息、运行特征等,我们把这个称为进程控制块(Process control block,缩写PCB)。 PCB 数据结构体中有一个指针指向了文件描述符表(File descriptors),文件描述符表中的每一个元素 索引到对应的文件表(File table),文件表也是一个数据结构体,其中记录了很多文件相关的信息,譬如文 件状态标志、引用计数、当前文件的读写偏移量以及 i-node 指针(指向该文件对应的 inode)等,进程打开 的所有文件对应的文件描述符都记录在文件描述符表中,每一个文件描述符都会指向一个对应的文件表, 其示意图如下所示:
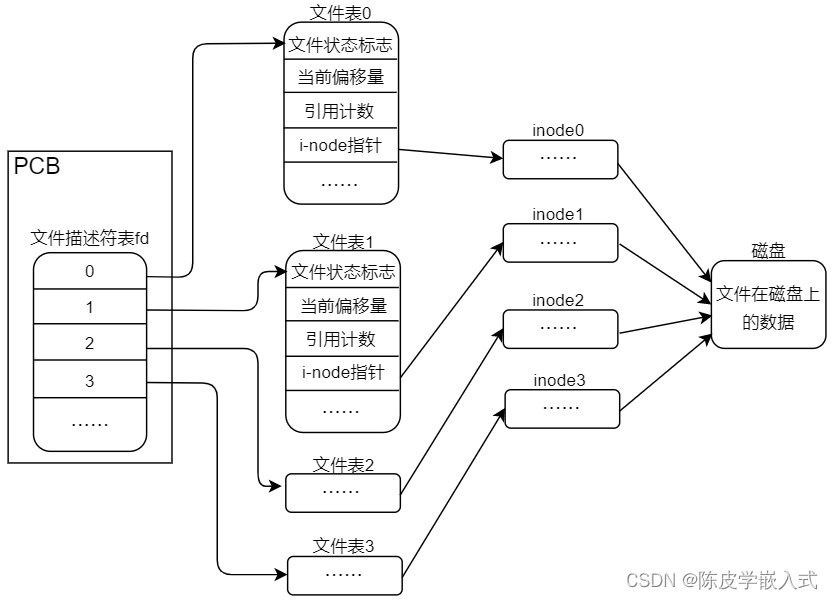
图3.15
图 3.1.5 文件描述符表、文件表以及 inode 之间的关系
前面给介绍了 inode,inode 数据结构体中的元素会记录该文件的数据存储的 block(块)的位置,也就是 说可以通过 inode 找到文件数据存在在磁盘设备中的那个位置,从而把文件数据读取出来。
二 返回错误处理与 errno
在很多情况下,当调用函数出错时,我们都会调用return退出程序,但我们并不知道为什么会出错,什么原因导致此函数执行失败,因为执行出错之后它们的返回值都是-1。
1.怎么让系统给我们指出错误原因?
在Linux系统下对常见的错误做了一个编号,每一个编号都代表着每一种不同的错误类型,当函数执行发生错误的时候,操作系统会将这个错误所对应的编号赋值给errno变量,每一个进程(程序)都维护了自己的errno变量,它是程序中的全局变量,该变量用于存储就近发生的函数执行错误编号,也就意味着下一次的错误码会覆盖上一次的错误码。所以由此可知道,当程序中调用函数发生错误的时候,操作系统内部会通过设置程序的errno变量来告知调用者究竟发生了什么错误!
errno本质上是一个int类型的变量,用于存储错误编号,但是需要注意的是,并不是执行所有的系统调用或C库函数出错时,操作系统都会设置errno,那我们需要确定函数出错时系统是否会设置errno值
其实这个通过man手册便可以查到,譬如以open函数为例,执行"man 2 open"打开open函数的帮助信息,找到函数返回值描述段,如下所示:

函数返回错误时会设置errno,当然这里是以open函数为例,其它的系统调用也可以这样查找
小技巧:如果用vim查找返回值,可以直接查VALUE
- 在命令模式下输入/然后输入你需要查找的字符串即可。向光标之下寻找你所输入的字符串。
- 在命令模式下输入?然后输入你需要查找的字符串即可。向光标之上寻找你所输入的字符串

从图中部分描述文字可知,当函数返回错误时会设置errno,当然这里是以open函数为例,其它的系统调用也可以这样查找 ,errno的值也可直接借printf()打印出来
2.strerror 函数
前面给大家说到了 errno 变量,但是 errno 仅仅只是一个错误编号,对于开发者来说,即使拿到了 errno也不知道错误为何?还需要对比源码中对此编号的错误定义,可以说非常不友好,这里介绍一个 C 库函数strerror(),该函数可以将对应的 errno 转换成适合我们查看的字符串信息,其函数原型如下所示(可通过"man 3 strerror"命令查看,注意此函数是 C 库函数,并不是系统调用): #include char *strerror(int errnum);
首先调用此函数需要包含头文件。
函数原型:
#include <string.h>
char *strerror(int errnum); 函数参数和返回值如下:
- errnum:错误编号 errno。
- 返回值:对应错误编号的字符串描述信息。
3.perror 函数
除了 strerror 函数之外,我们还可以使用 perror 函数来查看错误信息,一般用的最多的还是这个函数, 调用此函数不需要传入 errno,函数内部会自己去获取 errno 变量的值,调用此函数会直接将错误提示字符 串打印出来,而不是返回字符串,除此之外还可以在输出的错误提示字符串之前加入自己的打印信息,函数 原型如下所示(可通过"man 3 perror"命令查看):
函数原型:
#include <stdio.h>
void perror(const char *s);
- 函数参数和返回值含义如下: s:在错误提示字符串信息之前,可加入自己的打印信息,也可不加,不加则传入空指针也可即可。
- 返回值:void 无返回值。
#include <unistd.h>
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
int main(void)
{
int fd;
/* 打开文件 */
fd = open("./te_file", O_RDONLY);
if (-1 == fd) {
perror(NULL);
return -1;
}
close(fd);
return 0;
}
三 exit、_exit、_Exit
当程序在执行某个函数出错的时候,如果此函数执行失败会导致后面的步骤不能在进行下去时,应该在 出错时终止程序运行,不应该让程序继续运行下去,那么如何退出程序、终止程序运行呢?有过编程经验的 读者都知道使用 return,一般原则程序执行正常退出 return 0,而执行函数出错退出 return -1,前面所编 写的示例代码也是如此。
在 Linux 系统下,进程(程序)退出可以分为正常退出和异常退出,注意这里说的异常并不是执行函数 出现了错误这种情况,异常往往更多的是一种不可预料的系统异常,可能是执行了某个函数时发生的、也有 可能是收到了某种信号等,这里我们只讨论正常退出的情况。
在 Linux 系统下,进程正常退出除了可以使用 return 之外,还可以使用 exit()、_exit()以及_Exit(),下面 我们分别介绍。
1. 三种终止进程的方法:
- main 函数中运行 return;
- 调用 Linux 系统调用_exit()或_Exit();
- 调用 C 标准库函数 exit()。
2._exit()和_Exit()函数
main 函数中使用 return 后返回,return 执行后把控制权交给调用函数,结束该进程。调用_exit()函数会 清除其使用的内存空间,并销毁其在内核中的各种数据结构,关闭进程的所有文件描述符,并结束进程、将 控制权交给操作系统。
_exit()函数原型:
#include <unistd.h>
void _exit(int status); 调用函数需要传入 status 状态标志,0 表示正常结束、若为其它值则表示程序执行过程中检测到有错误 发生。使用示例如下:
3.示例代码: _exit()和_Exit()函数使用
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <stdio.h>
int main(void)
{
int fd;
/* 打开文件 */
fd = open("./test_file", O_RDONLY);
if (-1 == fd) {
perror("open error");
_exit(-1);
}
close(fd);
_exit(0);
} 用法很简单,就是程序正常退出就0,非正常就是-1
_Exit()函数原型如下所示:
#include <stdlib.h>
void _Exit(int status); _exit()和_Exit()两者等价,用法作用是一样的,需要注意的是这 2 个函数都是系统调 用。
4.exit()函数
exit()函数_exit()函数都是用来终止进程的,exit()是一个标准 C 库函数,而_exit()和_Exit()是系统调用。 执行 exit()会执行一些清理工作,最后调用_exit()函数。
exit()函数原型:
#include <stdlib.h>
void exit(int status);该函数是一个标准 C 库函数,使用该函数需要包含头文件,该函数的用法和_exit()/_Exit()是 一样的
四 空洞文件
1.什么是空洞文件(hole file)
当lseek()系统调用,使用 lseek 可以修 改文件的当前读写位置偏移量,此函数不但可以改变位置偏移量,并且还允许文件偏移量超出文件长度,这 是什么意思呢?譬如有一个 test_file,该文件的大小是 4K(也就是 4096 个字节),如果通过 lseek 系统调 用将该文件的读写偏移量移动到偏移文件头部 6000 个字节处,接下来使用 write()函数对文件进行写入操作,也就是说此时将是从偏移文件头部 6000 个字节处开始写 入数据,也就意味着 4096~6000 字节之间出现了一个空洞,因为这部分空间并没有写入任何数据,所以形 成了空洞,这部分区域就被称为文件空洞,那么相应的该文件也被称为空洞文件。
文件空洞部分实际上并不会占用任何物理空间,直到在某个时刻对空洞部分进行写入数据时才会为它 分配对应的空间,但是空洞文件形成时,逻辑上该文件的大小是包含了空洞部分的大小的,这点需要注意。
2.空洞文件有什么用呢?
空洞文件对多线程共同操作文件是及其有用的,有时候我们创建 一个很大的文件,如果单个线程从头开始依次构建该文件需要很长的时间,有一种思路就是将文件分为多 段,然后使用多线程来操作,每个线程负责其中一段数据的写入;这个有点像我们现实生活当中施工队修路 的感觉,比如说修建一条高速公路,单个施工队修筑会很慢,这个时候可以安排多个施工队,每一个施工队 负责修建其中一段,最后将他们连接起来。
来看一下实际中空洞文件的两个应用场景:
- 在使用迅雷下载文件时,还未下载完成,就发现该文件已经占据了全部文件大小的空间,这也是空 洞文件;下载时如果没有空洞文件,多线程下载时文件就只能从一个地方写入,这就不能发挥多线 程的作用了;如果有了空洞文件,可以从不同的地址同时写入,就达到了多线程的优势;
- 在创建虚拟机时,你给虚拟机分配了 100G 的磁盘空间,但其实系统安装完成之后,开始也不过只 用了 3、4G 的磁盘空间,如果一开始就把 100G 分配出去,资源是很大的浪费。
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <string.h>
#include <stdlib.h>
void main()
{
int fd = open("./kd_test",O_RDWR|O_CREAT,S_IRUSR | S_IWUSR | S_IRGRP | S_IROTH);
if(-1 == fd)
{
perror("");
exit(-1);
}
lseek(fd,1024*4, SEEK_SET);
char buf[1024];
memset(buf,1,sizeof(buf));
for(int i = 0;i<4;i++)
{
write(fd,buf,1024);
}
close(fd);
}示例代码中,我们使用 open 函数新建了一个文件 hole_file,在 Linux 系统中,新建文件大小是 0,也就 是没有任何数据写入,此时使用lseek函数将读写偏移量移动到4K字节处,再使用write函数写入数据0xFF, 每次写入 1K,一共写入 4 次,也就是写入了 4K 数据,也就意味着该文件前 4K 是文件空洞部分,而后 4K数据才是真正写入的数据。

使用 ls 命令查看到空洞文件的大小是 8K,使用 ls 命令查看到的大小是文件的逻辑大小,自然是包括了 空洞部分大小和真实数据部分大小;当使用 du 命令查看空洞文件时,其大小显示为 4K,du 命令查看到的 大小是文件实际占用存储块的大小
五 多次打开同一个文件
同一个文件可以被 多次打开,譬如在一个进程中多次打开同一个文件、在多个不同的进程中打开同一个文件,那么这些操作都是被允许的。一个进程内多次 open 打开同一个文件,那么会得到多个不同的文件描述符 fd,同理在关闭文件的 时候也需要调用 close 依次关闭各个文件描述符。
1. 代码测试:一个进程可以多次打开同个文件
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <stdlib.h>
#include <unistd.h>
void main()
{
int fd = open("./duoge",O_WRONLY|O_CREAT,0600);
if(-1 == fd)
{
perror("");
exit(-1);
}
int fd1 = open("./duoge",O_WRONLY|O_CREAT,0600);
if(-1 == fd1)
{
perror("");
exit(-1);
}
int fd2 = open("./duoge",O_WRONLY|O_CREAT,0600);
if(-1 == fd)
{
perror("");
exit(-1);
}
printf("fd = %d ,fd1 = %d ,fd2 = %d ",fd,fd1,fd2);
close(fd);
close(fd1);
close(fd2);
}
从打印结果可知,三次调用 open 函数得到的文件描述符分别为 3、4、5,通过任何一个文件描述符对 文件进行 IO 操作都是可以的,为啥不是0,1,2呢?因为标准输入、标准输出和标准错误 0、1、2。
2.多次 open 打开同一个文件,在内存中并不会存在多份动态文件。
当调用 open 函数的时候,会将文件数据(文件内容)从磁盘等块设备读取到内存中,将文件数据在内 存中进行维护,内存中的这份文件数据我们就把它称为动态文件!
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
//怎么验证打开同个文件打开多次,共用一块内核缓冲区
//1 多次调用open打开共个文件
//2 向第一次打开的文件写入数据
//3 将光标移到开头
//4 调用read函数读第二次打开的文件的动态文件
//如果读到的数据为第一次写入的数据,那证明多次打开文件生成的缓存区为同一块
void main()
{
//1多次打开文件
int fd = open("./duoge",O_WRONLY|O_CREAT,S_IRUSR | S_IWUSR | S_IRGRP | S_IROTH);
if(-1 == fd)
{
perror("");
exit(-1);
}
int fd1 = open("./duoge",O_RDONLY|O_CREAT,S_IRUSR | S_IWUSR | S_IRGRP | S_IROTH);
if(-1 == fd1)
{
perror("");
exit(-1);
}
//2写入数据
char buf[][4] = {"0x01","0x02","0x03","0x04"};
int ret = write(fd,buf,16);
if(-1 == ret)
{
perror("");
exit(-1);
}
//3将光标移到前方
lseek(fd1,0,SEEK_SET);
//4读数据
memset(buf,'\0',sizeof(buf));
int len = read(fd1,buf,16);
if(-1 == len)
{
perror("");
printf("%d = ",len);
}
printf("%s ",*buf);
close(fd);
close(fd1);
}![]()
上图中打印显示读取出来的数据是 0x01/0x02/0x03/0x04,所以由此可知,即使多次打开同一个文件,内存中也只有一份动态文件。
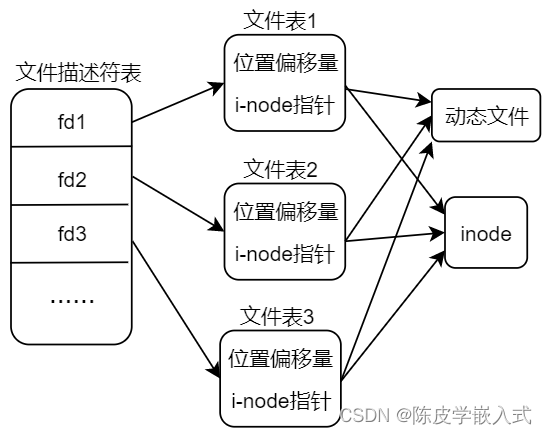
一个进程内多次 open 打开同一个文件,不同文件描述符所对应的读写位置偏移量是相互独立的。
同一个文件被多次打开,会得到多个不同的文件描述符,也就意味着会有多个不同的文件表,而文件读 写偏移量信息就记录在文件表数据结构中,所以从这里可以推测不同的文件描述符所对应的读写偏移量是 相互独立的,并没有关联在一起,并且文件表中 i-node 指针指向的都是同一个 inode
















 9492
9492











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











