







有关fork函数的三个问题
问题1:
为什么在父进程中fork函数会返回子进程的id,而在子进程中fork函数的返回值是0?这个可以用家庭来做对比:一个父亲可以有多个儿子,但是每个儿子只能有一个父亲。在这种情况下,父亲想找某一个儿子就必须指定名字,而任何一个儿子想找父亲就能直接找到,因为只有一个父亲。同样的,一个父进程可以有多个子进程,但是任何一个子进程只能有一个父进程。子进程能返回0是因为子进程可以通过getppid函数获得父进程得id值,所以fork函数可以直接返回0,但是父进程却没有函数能够获取子进程的id,所以只能通过fork函数的返回值记录子进程的id以便于以后的使用。
问题2:
为什么调用一个fork函数却能够有两个返回值?我们以下面的函数为例:
int add(int a,int b)
{
int ret=a+b;
return ret;
}在变量c作为返回值返回之前,add函数已经完成了两个整型变量a和b的相加工作,意思就是add函数的具体功能已经被实现了,类似的,我们的fork函数也是如此。fork函数的具体功能是创建一个子进程,在创建子进程的过程中,首先要创建子进程的PCB,然后将父进程的PCB赋值给他,再创建子进程的地址空间并做赋值,接着创建子进程的页表并赋值,再把子进程的PCB放入进程的队列当中等等一系列操作,完成这一系列工作后再将子进程的pid作为返回值进行返回:
pid_t fork()
{
1.创建子进程PCB
2.赋值
3.创建子进程地址空间
4.赋值
5.创建子进程列表
6.赋值
7.将子进程PCB放入进程的list之中
........
return pid;
}也就是说fork()函数的创建子进程的功能在return执行之前就已经执行完毕,当子进程创建好之后就有两个执行流执行下面的代码,所以return指令会被执行两次,以至于fork函数会有两个不同的返回值,子进程返回0,父进程返回子进程id。
问题3:
我们先来看一段代码:
#include <stdio.h>
#include <unistd.h>
int main()
{
pid_t id=fork();
if(id>0)
{
//执行父进程代码
}
else
{
//执行子进程代码
}
return 0;
}通过之前的学习,我们知道这段代码可以通过条件判断语句使得父子进程分别执行代码不同的部分,在上面我们已经讲过一个fork函数为什么会有两个返回值,这里的问题就是,父子进程return之后,都会执行后面的代码,这其中就包括pid_t id=fork();,那为什么id这个变量能够同时记录两个不同的返回值呢?原因就是上篇文章讲过的写时拷贝,具体内容可以参考下面的图片
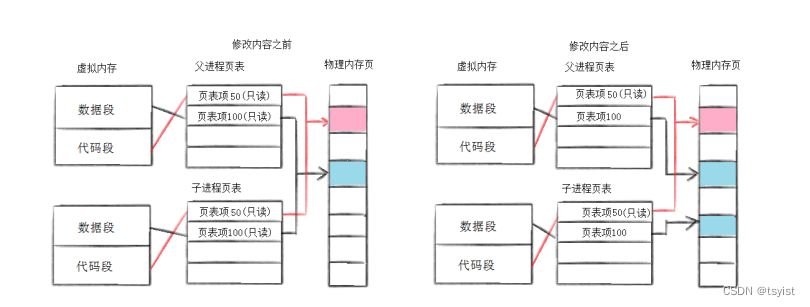
在创建子进程之后,修改数据之前,子进程和父进程共用一段代码区和数据区。当子进程想对内存上的公共数据进行修改时,操作系统会开辟一个新的空间将原来数据区的内容复制到新的空间之中,并且修改进程的页表指向新空间,这便使子进程对数据的修改不会影响到父进程,使进程之间具有独立性。
调用fork函数创建子进程之后,到底是父子进程谁先执行后续的代码我们不知道,那是调度器的工作,但是我们知道无论谁先执行后续的代码,肯定有一个进程对id进行修改,发生修改时就会产生写时拷贝,所以内存上其实会存在两个变量记录fork函数的返回值,而不是一个变量记录两个值。
fork函数的两种常见用法
第一种:
父子进程同时执行后续的代码内容
1 #include<stdio.h>
2 #include<unistd.h>
3 int main()
4 {
5 fork();
6 printf("hello fork\n");
7 return 0;
8 }
父子进程都执行后续的代码,上述代码的结果就是屏幕会出现两次打印的结果
第二种:
使父子进程执行后续代码的不同部分
1 #include<stdio.h>
2 #include<unistd.h>
3 int main()
4 {
5 int id = fork();
6 if(id==0)
7 {
8 //子进程执行的代码
9 }
10 else
11 {
12 //父进程执行的代码
13 }
14 return 0;
15 }
第一种用法就是子承父业,父子同时执行后续的代码;第二种用法就类似于儿子在其他领域别有一番作为,在代码上就体现为通过fork函数创建子进程让他执行与父进程不同的代码,具体怎样做我们以后再讲。
进程失败
引子:fork函数调用失败的原因
在显示生活中,我们有饮酒故好,可不要贪杯哟的概念,在程序中也是如此,我们调用fork函数创建子进程的时候会消耗cpu的资源,并且占用内存,当我们不停地使用fork函数创建子进程的时候,必然会导致cpu的资源和内存消耗完,这时在调用fork的时候就会报错,我们可以通过一下代码的运行结果理解:
#include<stdio.h>
#include<unistd.h>
int main()
{
int cnt =1;
while(1)
{
int ret=fork();
if(ret<0)
{
printf("fork error,cnt:%d\n",cnt);
}
else if(ret==0)
{
while(1)
{
sleep(1);
}
}
}
cnt++;
return 0;
}
这段代码通过外层循环使父进程不断的创建子进程,并且由于内层死循环的缘故,创建出来的子进程无法结束退出,所以这段代码会无休止地创建子进程,直至服务器资源被消耗完崩溃,这是就可以通过printf出的语句看到刚刚一共创建了多少个子进程。(最好不要测试这段代码,服务器会直接崩溃。如果一定要测试的话,在服务器奔溃后,过一段时间再重启即可)
main函数的返回值
我们之前写代码,main函数总是以return 0;为结尾,实际上,我们把main函数里面的return 0称作退出码,退出码的作用就是标定当前程序执行结果是否正确,当main函数返回0时代表程序执行结果正确,返回非0时代表程序执行结果错误,例如:下面的代码我们本意是想计算100的阶乘,如果结果错误的话就会返回1。
1 #include<stdio.h>
2 #include<unistd.h>
3 int addtotarget(int from,int to)
4 {
5 int sum =0;
6 for(int i=from;i<to;++i)
7 {
8 sum+=i;
9 }
10 return sum;
11 }
12 int main()
13 {
14 int num =addtotarget(1,100);
15 if(num==5050)
16 {
17 return 0;
18 }
19 else
20 {
21 return 1;
22 }
23 return 0;
24 }
上面的代码其实是我们故意写错的,他最后的返回值就是1。那么我们如何查看呢?在linux里有一个变量名为?(没错,就是个问号),这个变量存储的永远会是最近一个进程的退出码,所以我们可以使用echo $?的命令查看最近一个程序执行的结果。
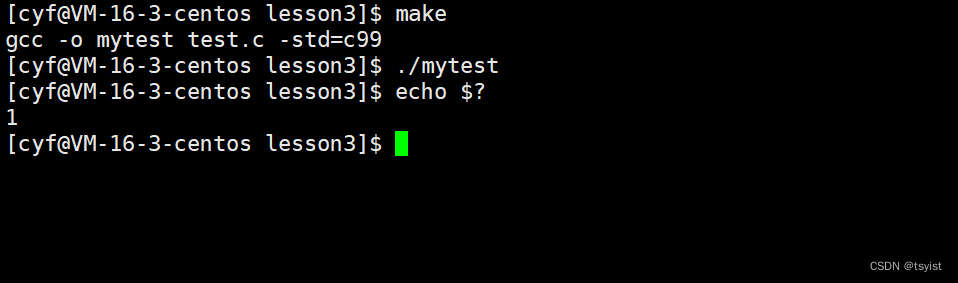
我们可以看到,以上代码的运行结果就为1。
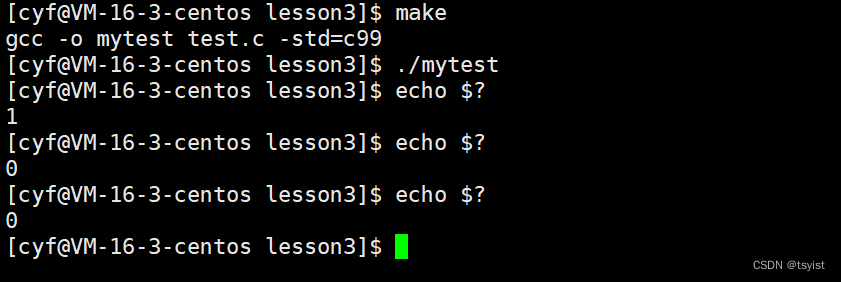
但是我们再运行两次就会发现,退出码变成了0,这是因为echo自己也是一个程序,我们接下来2次查看的都是上一次echo命令的退出码,而我们对应的上一次echo命令都执行的正确,所以下面两次查询的退出码都是0。
未来我们在写程序的时候如果不关心进程结果的对错,直接return 0就行,但是如果想要关心进程结果的对错的话就得在程序的返回值中表明特定的错误,返回0代表结果正确,返回非0代表结果错误,而返回的数字具体是几就代表具体是哪种错误。数字对人不友好,但是对计算机友好,所以退出码都会有对应退出码的文字描述,这个文字描述可以自定义,也可以直接使用系统的映射关系。
查看不同退出码对应的内容
我们通过c语言的strerror函数将不同的退出码转换成文字信息。
1 #include<stdio.h>
2 #include<string.h>
3 int main()
4 {
5 for(int i=0;i<=150;++i)
6 {
7 printf("%d:%s\n",i,strerror(i));
8 }
9 return 0;
10 }
我们运行这段代码的结果则为:
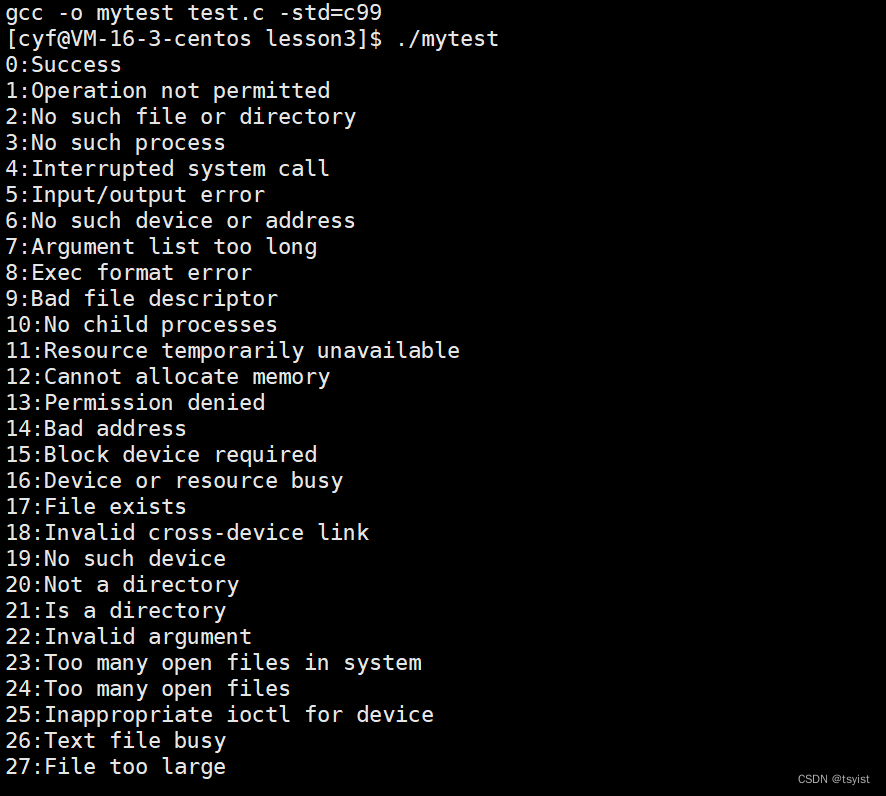
我们就可以看到各个退出码的文字描述信息,总共从0~133,共134条。
如何退出进程
进程有三个退出情况:
1.代码跑完了,结果正确这时退出码为0。
2.代码跑完了,结果不正确这时退出码为非0.
3.代码没跑完,程序异常,这时程序的退出码就没有任何意义。
进程也有三个退出的方式:
1.在main函数里面通过return来结束进程
2.在任意地方调用exit函数来结束进程。
3.使用系统调用接口_exit函数来结束进程。
_exit属于系统调用接口,而exit函数属于c语言的函数调用接口,实际上exit函数属于对_exit函数进行了封装之后所形成的,他们的区别就是_exit在调用的时候不会刷新缓冲区,而exit函数在调用的时候会刷新缓冲区。
而我们在上面的现象中能推断出什么呢?画一张图来表示一下:

我们可以通过上面的现象来推断出我们的缓冲区在哪里?是在操作系统内核里?还是在我们的用户空间里?我们刚才说exit函数在调用的时候会刷新缓冲区,而exit函数实际是对_exit系统调用接口的封装,如果缓冲区在操作系统内核中,那么exit函数调用会刷新缓冲区的话,_exit函数调用的时候也一定会刷新缓冲区,因为exit函数是调用_exit函数的。
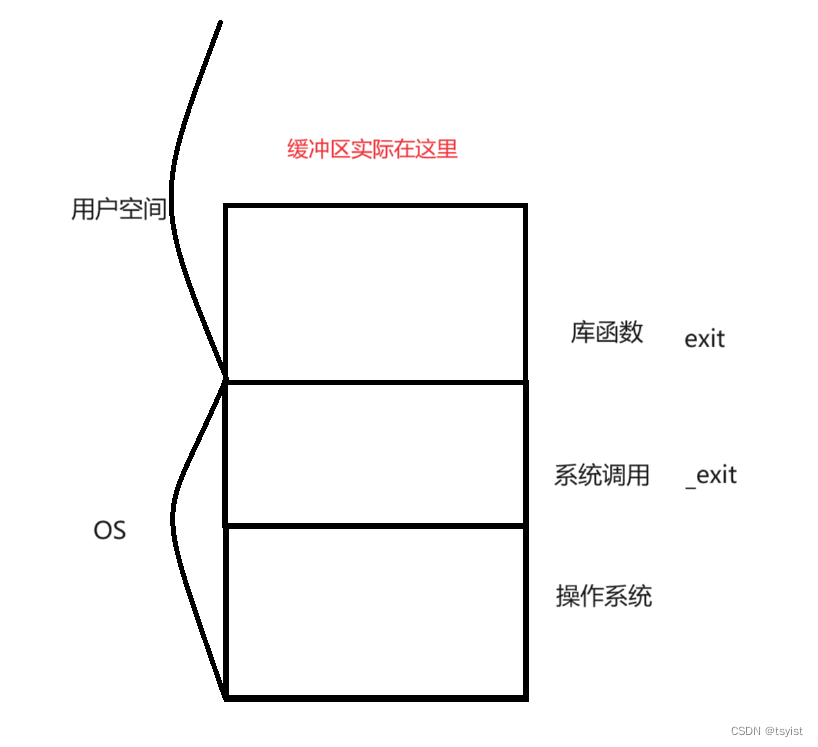
那么也就说明,我们的缓冲区是在用户空间中,它实际上是用户级的缓冲区,有关详细的知识会在基础IO部分详细解说。















 1431
1431











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









