







第一部分:问题描述
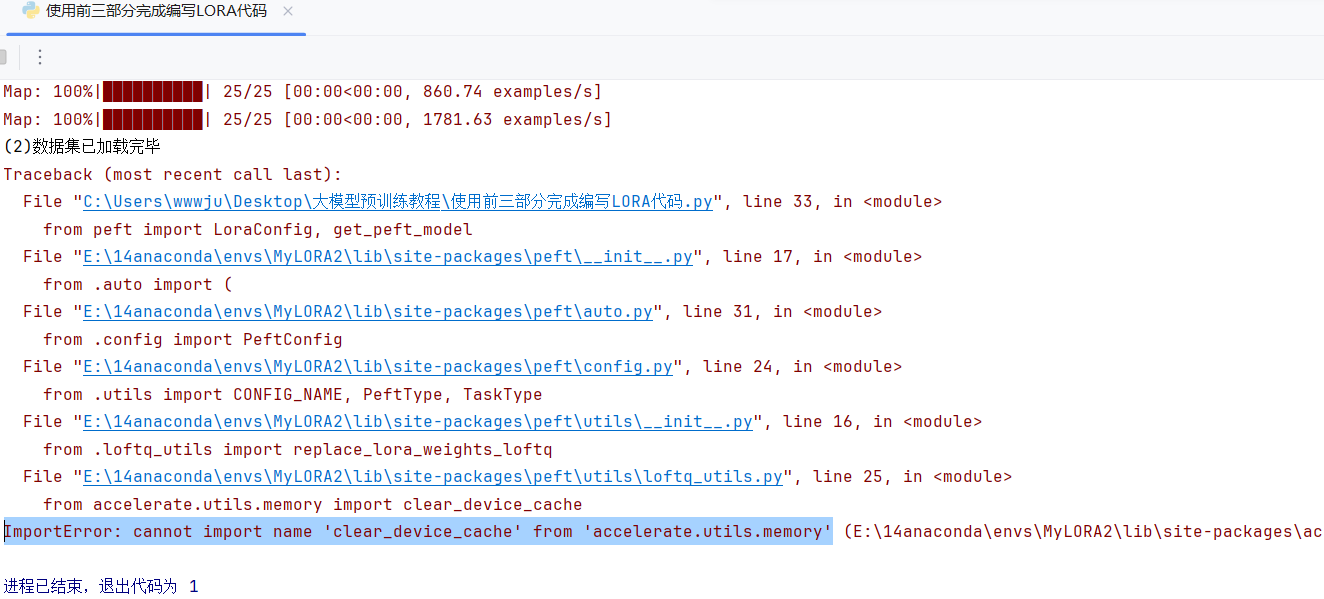
第二部分:解决方法
更新自己的accelerate:
比如我原先的版本是0.21.0
我现在更新:
pip install accelerate==1.2.0
更新自己的accelerate:
比如我原先的版本是0.21.0
我现在更新:
pip install accelerate==1.2.0 1049
4147
1049
4147

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言






























