







本文内容为:快速排序的介绍,一次“划分”的三种方法:挖坑法、左右指针法、前后指针法。快速排序的优化:三数取中,快速排序的时间、空间复杂度和稳定性分析。
快速排序的步骤是:
- 我们取在待排序列中取一个元素pivot作为枢轴(或基准,通常为首元素),把这个元素排到它该在的位置,即pivot前的元素都小于或等于它,pivot后的元素都大于或等于它,我们称这一步操作为一次划分。
- 我们经过一次划分后会得到pivot左边的子表和pivot右边的子表,我们对左右子表同样进行一次划分操作,...最后我们会对只有一个元素的子表进行划分操作,整个序列就有序了。
一次划分的三种方法:
①挖坑法:
- 我们保存首元素为pivot,首元素就形成了一个可以填充其他元素的坑。并设置两个下标low和high分别指向首元素和尾元素。
- high下标先往左迭代,当找到比pivot小的元素时把这个元素放到坑里,然后high此时所指的位置就形成了一个新的坑。
- 然后low下标再往右迭代,当找到比pivot大的元素时把这个元素放到坑里,然后low此时所指的位置就又形成了一个新的坑。
- 最后停止迭代的条件时low和high相遇,此时两者指向的地方是一个坑,我们把pivot填进去即可。
思路分析:high下标往左迭代发现比pivot小的值都放在左半部分的坑中,low下标往右迭代发现比pivot大的值都放在右半部分的坑中,最后pivot完美地落在左半部分和右半部分的中间。
代码如下:
int Partition(ElemType A[],int low,int high)
{//一次划分,返回划分后pivot正确的位置用于对左右子表划分
ElemType pivot=A[low];//将首元素设为枢轴
while(low<high)
{ while(low<high&&A[high]>=pivot)//向左迭代,找到比pivot小的
{
--high;
}
A[low]=A[high];//填到左边坑里然后形成新的坑
while(low<high&&A[low]<=pivot)//向右迭代,找到比pivot大的
{
++low;
}
A[high]=A[low];//填到右边坑里然后形成新的坑
}
A[low]=pivot;//或者A[high]=pivot
return low;
}②左右指针法:
- 我们保存首元素为pivot,并设置两个下标low和high分别指向首元素和尾元素。
- high下标先往左迭代,当找到比pivot小的元素时停下。
- 然后low下标再往右迭代,当找到比pivot大的元素时停下。
- 然后交换low下标和high下标所指的元素。
- 最后停止迭代的条件为low下标和high下标相遇,将这个位置的值填入首元素位置,然后将pivot填入这个位置。
思路分析:high下标往左迭代发现比pivot小的值,low下标往右迭代发现比pivot大的值,然后它们交换,这样比pivot大的值就去了右半部分,比pivot小的值去了左半部分。
我们来分析一下最后停下的位置是哪里?high下标先往左找比pivot小的,一种情况是没有找到会一直迭代到low下标位置,就是首元素,相当于pivot填入首元素所在位置。
另一种情况是找到了然后停下,low下标向右迭代如果没有找到比pivot大的于是停在了high位置,然后相遇位置的值填入首元素位置,pivot填入该位置。,low下标向右迭代如果找到了就与high位置元素交换,循环继续。
代码实现如下:
int Partition(ElemType A[],int low,int high)
{//一次划分,返回划分后pivot正确的位置用于对左右子表划分
ElemType pivot=A[low];//将首元素设为枢轴
int left=low;//low一会移动了,先保存首元素位置left
while(low<high)
{ while(low<high&&A[high]>=pivot)//向左迭代,找到比pivot小的
{
--high;
}
while(low<high&&A[low]<=pivot)//向右迭代,找到比pivot大的
{
++low;
}
swap(&A[low],&A[high])//交换low和high位置的元素
}
swap(&A[low],&A[left]);//或写成 swap(&A[high],&A[left]);
return low;
}③前后指针法
- 我们保存首元素为pivot,并设置两个下标prev和cur分别指向首元素和首元素下个位置。
- cur下标向右迭代,当找到比pivot小的元素时进行一个操作:++prev,然后交换cur位置元素和prev位置的元素。
- 最后cur下标等于high下标时停止迭代,并把prev位置的值放在首元素位置,pivot放入prev位置。
思路分析:cur向右找到比pivot小的值时,++prev与cur交换,这其实就是比pivot大或等于的值与cur找到的比pivot小的值交换的过程。
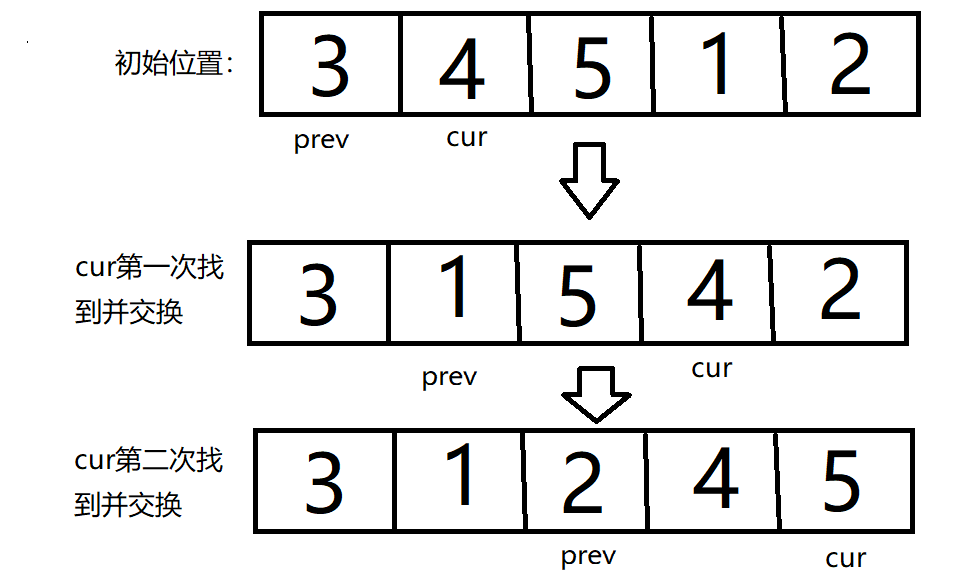
最后prev位置元素放在首元素位置,pivot放在prev位置,我们就完成了以pivot为枢轴的一次划分。
代码实现如下:
int Partition(ElemType A[],int low,int high)
{//一次划分,返回划分后pivot正确的位置用于对左右子表划分
ElemType pivot=A[low];//将首元素设为枢轴
int prev=low;
int cur=low+1;
while(cur<=high)
{ if(A[cur]<pivot)//当cur找到比pivot小的元素位置时
{
++prev;
swap(&A[prev],&A[cur]);//交换cur和prev位置的元素
}
cur++;//向右迭代
}
swap(&A[low],&A[prev]);
return prev;
}当待排序列是顺序或者逆序时,我们取首元素为pivot时,它的右半部分或者左半部分已经全是比它小的了,但是我们的一次划分的代码还会继续循环下去,以挖坑法为例,high指针向左迭代找比pivot小的元素发现找不到一直走到首元素位置,这样很明显是无用功。
如果我们不选取首元素位置作pivot而是随机选取会好很多,只需要交换首元素和随机选取的元素就不用改变我们基于pivot在首元素位置而写的代码。
三数取中就是我们取首元素,尾元素,和中间元素三个元素中元素大小排中间的元素放在首元素位置作为pivot。
代码实现如下:
int GetMidenum(ElemType A[],int low,int high)
{
int mid=low+(high-low)/2;
int getmid=A[mid];
if((A[mid]<=A[low]&&A[mid]>=A[high])||(A[mid]>=A[low]&&A[mid]<=A[high]))
getmid=A[mid];//A[mid]比A[low]大比A[high]小或者A[mid]比A[low]小比A[high]大
if((A[low]<=A[mid]&&A[low]>=A[high])||(A[low]>=A[mid]&&A[low]<=A[high]))
getmid=A[low];
if((A[high]<=A[mid]&&A[high]>=A[low])||(A[high]>=A[mid]&&A[high]<=A[low]))
getmid=A[high];
return getmid;
}我们解决了一次划分之后,我们会得到左右子表,再分别对它们进行划分,如此递归下去。
递归的代码如下:
void Quick_Sort(ElemType A[],int low,int high)
{
if(low<high)//递归跳出的条件
{
int pivotpos=Partition(A,low,high);
Quick_Sort( A,low,pivotpos-1);
Quick_Sort( A,pivotpos+1,high);
}
}一次划分:对于一个待排表,把一个pivot排在正确位置。一趟快速排序:我们在递归调用这一层里面已经有了许多pivot,它们的每一个的左右子表都进行一次划分叫一趟快速排序。
一次划分类似于二叉树中的一个结点分出一个孩子结点。一趟快速排序类似于二叉树中的一层的结点都分出左右孩子结点。
空间复杂度分析:递归函数需要借助一个递归工作栈来保存每层递归调用的必要信息,其容量与递归调用的最大深度一致,最好情况下我们每趟快速排序的pivot都在子表的中间,栈的深度为 O(logn);最坏情况下,每趟快速排序的pivot都在表头或者表尾,要进行n-1次递归调用,栈的深度为O(n),平均情况下,栈的深度为O(logn)。
时间复杂度分析:上面已经分析过最坏情况下快速排序有n-1趟递归调用,而每次递归调用的时间复杂度为O(n),所以快速排序最坏时间复杂度为O(),最好时间复杂度为O(nlogn),平均时间复杂度为O(nlogn)。
稳定性分析:在一次划分算法中,我们把右端的元素移到了左端,这个过程可能会改变相同元素的相对位置,所以快速排序是不稳定排序。
快速排序按不同视角被分到:
- 不稳定排序
- 改进排序
- 内排序
- 交换排序
















 678
678











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











