






一、模型评估概述
1.什么是模型评估
模型评估是机器学习中的一个重要环节,它指的是对训练好的模型进行性能评估,以了解模型在未见过的新数据上的表现。这通常包括使用一系列指标来量化模型的预测能力、泛化能力、稳定性等。模型评估方法不针对模型本身,只针对问题和数据,因此可以用来评价来自不同方法的模型和泛化能力,进行用于部署的最终模型的选择。
数据评估通常包括以下几个方面:
1. 数据质量:检查数据是否存在缺失值、异常值、重复值等问题。这可以通过统计指标、可视化和专业领域知识来进行评估。
2. 数据完整性:评估数据是否完整,即是否缺少必要的字段或记录。例如,检查是否有缺失的关键数据字段。
3. 数据准确性:评估数据的准确性,即数据是否反映了真实情况。这可能涉及与外部数据源进行比对或使用专业知识进行验证。
4. 数据一致性:检查数据是否存在逻辑上的一致性问题。比如,同一类别的数据是否使用了不同的命名规范或单位。
数据评估的目的是确保数据可靠、适合用于分析和建模,并帮助数据科学家和分析师更好地理解数据背后的含义和特点。
2.模型评估的类型
机器学习的任务有回归,分类和聚类,针对不同的任务有不同的评价指标。按照数据集的目标值不同,可以把模型评估分为回归模型评估和分类模型评估。
3.过拟合、欠拟合
过拟合(overfitting)和欠拟合(underfitting)是机器学习中常见的两种模型训练问题。
1. 过拟合(Overfitting):
- 过拟合指的是模型在训练数据上表现良好,但在未见过的测试数据上表现不佳的情况。
- 过拟合通常发生在模型太过复杂,以至于可以完美地“记住”训练数据的细节,但无法泛化到新的数据。
- 过拟合的表现通常是模型在训练集上表现很好,但在测试集或实际应用中表现较差。
2. 欠拟合(Underfitting):
- 欠拟合指的是模型在训练数据上表现不佳,无法捕捉到数据的结构和模式。
- 欠拟合通常发生在模型过于简单,无法捕捉数据的复杂关系或模式。
- 欠拟合的表现通常是模型在训练集和测试集上都表现较差。
解决过拟合和欠拟合的方法包括:
- 过拟合:
- 收集更多的训练数据,以使模型能够更好地泛化。
- 简化模型,如减少特征数量、降低多项式的阶数等,以降低模型复杂度。
- 使用正则化技术,如L1正则化和L2正则化,以减小模型的参数大小。
- 使用交叉验证来评估模型的泛化性能。
- 欠拟合:
- 增加模型的复杂度,如增加特征数量、增加多项式的阶数等。
- 选择更复杂的模型,如使用更多层次的神经网络、增加树的深度等。
- 改进数据质量,如特征工程、数据清洗等,以使模型更容易捕捉到数据的结构和模式。
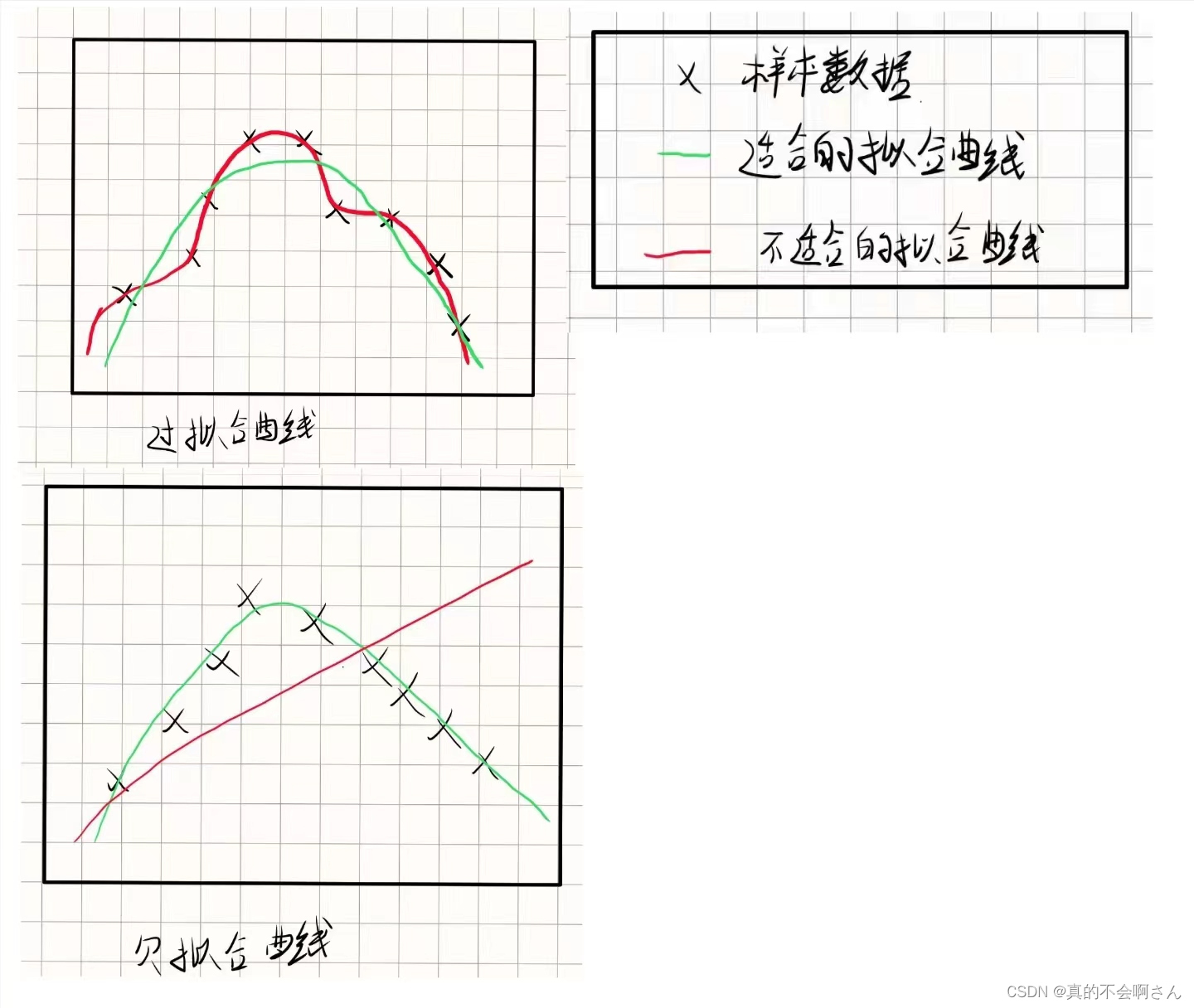
有多种因素可能导致过拟合
比如
1. 模型复杂度过高:模型具有过多的参数或复杂的结构,以致可以在训练数据上完美地拟合各种细节和噪声,但无法泛化到未见过的数据。例如,高阶多项式模型或具有大量隐藏层的神经网络可能会导致过拟合。
2. 训练数据不足:当训练数据量不足时,模型可能会记住训练数据中的特定样本和噪声,而无法学习到数据背后的真实模式。这会导致模型在未见过的数据上表现不佳。
3. 特征选择不当:如果选择了与目标变量无关或冗余的特征,模型可能会在训练数据上学习到无关的模式或噪声,从而导致过拟合。
4. 噪声干扰:训练数据中的噪声或异常值可能会干扰模型的学习过程,使其过度拟合这些异常值,从而降低了模型的泛化能力。
5. 训练数据与测试数据分布不一致:如果训练数据和测试数据的分布不一致,例如训练数据与真实场景中的数据有差异,模型可能会过拟合训练数据,而无法泛化到测试数据。
6. 过度拟合噪声:当训练数据中存在噪声时,模型可能会过度拟合这些噪声,而不是真实的模式,从而导致在未见过的数据上表现不佳。
为避免过拟合,可以采取以下措施:
- 使用更简单的模型或者减少模型的复杂度。
- 增加训练数据量,或者通过数据增强技术扩充训练数据。
- 进行特征选择,只选择与目标变量相关的特征。
- 使用正则化技术,如L1正则化(Lasso)或L2正则化(Ridge),来限制模型参数的大小。
- 使用交叉验证等技术来评估模型的泛化能力,并调整模型参数以降低过拟合的风险。
4.模型泛化能力
模型的泛化能力指的是模型在未见过的数据上的表现能力。一个具有良好泛化能力的模型能够对未见过的数据进行准确预测,而不仅仅是在训练数据上表现良好。泛化能力是衡量模型的一个重要指标,因为一个模型只有在面对真实世界中的新数据时表现良好,才能够被认为是有效的。
一个具有良好泛化能力的模型通常具备以下特征:
1. 适度的复杂度:模型既不过于简单(导致欠拟合),也不过于复杂(导致过拟合)。适度的复杂度可以使模型在训练数据和测试数据上都表现良好。
2. 有效的特征表示:模型能够从输入数据中提取并学习到有效的特征表示,这些特征能够准确地捕捉数据中的结构和模式。
3. 有效的正则化:模型使用了合适的正则化技术来控制模型的复杂度,防止过拟合的发生。常见的正则化技术包括L1正则化、L2正则化等。
4. 有效的训练过程:模型使用了合适的优化算法和训练策略,在训练过程中能够有效地学习到数据的结构和模式,而不是简单地记住训练数据。
5. 鲁棒性:模型对于噪声和不完整数据的表现良好,能够处理数据中的异常情况和变化。
通过评估模型在测试数据上的表现来评估模型的泛化能力。如果模型在测试数据上表现良好,则说明模型具有较好的泛化能力;反之,如果模型在测试数据上表现不佳,则可能存在过拟合或欠拟合的问题,需要进一步调整模型或改进训练过程。
二、性能度量
1.回归性能指标
在预测任务中,给定样例集D={(x1,y1),(x2,y2),...,(xm,ym)},其中yi是示例xi的真实标记。要评估学习器f的性能,就要把学习器预测结果f(x)与真实标记y进行比较。
回归任务最常用的性能度量是均方误差:
![]()
更一般的,对于数据分布D和概率密度函数p(.),均方误差可描述为:

2.分类性能指标
(1)错误率与精度
错误率是分类错误的样本数占样本总数的比例,精度则是分类正确的样本数占样本总数的比例。
对于样例集D,分类错误率定义为
精度则定义为![]()
更一般的,对于数据分布D和概率密度函数p(.),错误率与精度可分别描述为
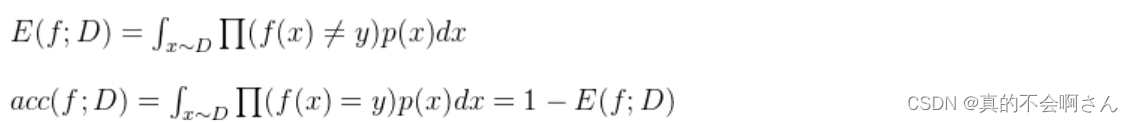
三、常见的分类模型评估
1. 混淆矩阵
混淆矩阵是监督学习中的一种可视化工具,主要用于模型的分类结果和实例的真实信息的比较 。
矩阵中的每一行代表实例的预测类别,每一列代表实例的真实类别。
真实值是positive,模型认为是positive的数量(True Positive=TP)
真实值是positive,模型认为是negative的数量(False Negative=FN):这就是统计学上的第一类错误(Type I Error)
真实值是negative,模型认为是positive的数量(False Positive=FP):这就是统计学上的第二类错误(Type II Error)
真实值是negative,模型认为是negative的数量(True Negative=TN)
将这四个指标一起呈现在表格中,就能得到如下这样一个矩阵,我们称它为混淆矩阵(Confusion Matrix):
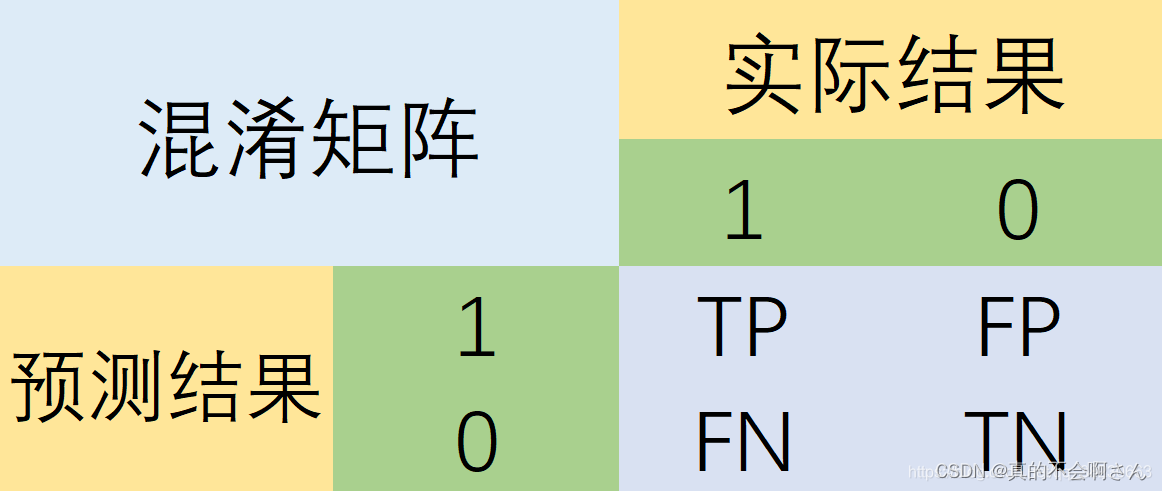
注意:预测性分类模型,肯定是希望越准越好。那么,对应到混淆矩阵中,那肯定是希望TP与TN的数量大,而FP与FN的数量小。所以当我们得到了模型的混淆矩阵后,就需要去看有多少观测值在第二、四象限对应的位置,这里的数值越多越好;反之,在第一、三四象限对应位置出现的观测值肯定是越少越好。注意:预测性分类模型,肯定是希望越准越好。那么,对应到混淆矩阵中,那肯定是希望TP与TN的数量大,而FP与FN的数量小。所以当我们得到了模型的混淆矩阵后,就需要去看有多少观测值在第二、四象限对应的位置,这里的数值越多越好;反之,在第一、三四象限对应位置出现的观测值肯定是越少越好。
2. 准确率(Accuracy):分类正确的样本数占总样本数的比例。
Accuracy = (TP+TN)/(TP+FN+FP+TN)
3. 精确率(Precision):在所有预测为正类的样本中,确实为正类的比例。
Precision = TP/(TP+FP)
4.召回率(Recall):在所有真正为正类的样本中,被正确预测为正类的比例。
Recall = TP/(TP+FN)
5. F1值(F1-score):精确率和召回率的调和平均数,综合考虑了模型的准确性和召回率。
2/F1 = 1/Precision + 1/Recall
6. ROC曲线(Receiver Operating Characteristic Curve):以假正例率(False Positive Rate,FPR)为横坐标,真正例率(True Positive Rate,TPR)为纵坐标,用于衡量二分类模型在不同阈值下的性能。
7. PR曲线(Precision-Recall Curve):以召回率为横坐标,精确率为纵坐标,用于评估模型在不同阈值下的表现。
8. ROC曲线和PR曲线的差异:
- ROC曲线关注的是真正例率和假正例率之间的权衡,适用于样本不平衡的情况,比如异常检测。
- PR曲线关注的是精确率和召回率之间的权衡,适用于正例数量较少的情况,比如信息检索。
四、具体实现
1.绘制K为2的roc曲线
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import roc_curve, auc
# 生成一些示例数据
X, y = make_classification(n_samples=1000, n_features=20, n_classes=2, random_state=42)
# 划分数据集为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建并训练k=2的k最近邻分类器
knn = KNeighborsClassifier(n_neighbors=2)
knn.fit(X_train, y_train)
# 获取测试集上的预测概率
y_scores = knn.predict_proba(X_test)[:, 1]
# 计算ROC曲线的真正例率(TPR)和假正例率(FPR)
fpr, tpr, thresholds = roc_curve(y_test, y_scores)
# 计算曲线下的面积(AUC)
roc_auc = auc(fpr, tpr)
# 绘制ROC曲线
plt.figure()
plt.plot(fpr, tpr, color='darkorange', lw=2, label='ROC curve (area = %0.2f)' % roc_auc)
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic (k=2)')
plt.legend(loc="lower right")
plt.grid(True)
plt.show()
结果:

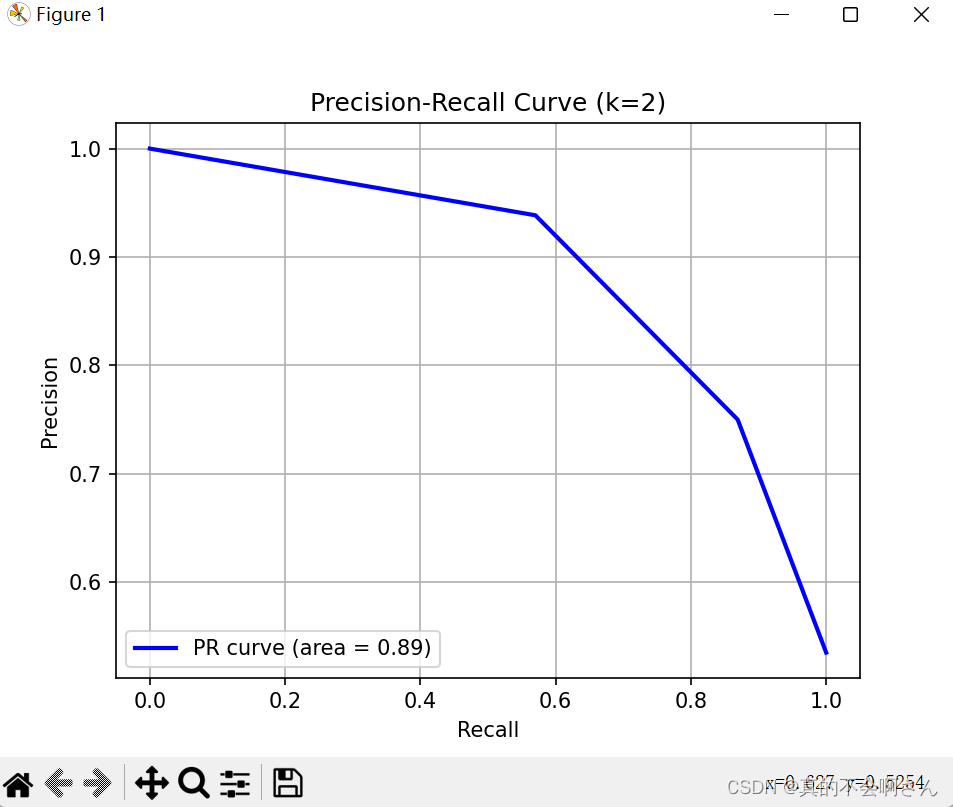
2. 绘制K为2的pr曲线
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import precision_recall_curve, auc
# 生成一些示例数据
X, y = make_classification(n_samples=1000, n_features=20, n_classes=2, random_state=42)
# 划分数据集为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建并训练k=2的k最近邻分类器
knn = KNeighborsClassifier(n_neighbors=2)
knn.fit(X_train, y_train)
# 获取测试集上的预测概率
y_scores = knn.predict_proba(X_test)[:, 1]
# 计算PR曲线的精确率(Precision)和召回率(Recall)
precision, recall, _ = precision_recall_curve(y_test, y_scores)
# 计算曲线下的面积(AUC)
pr_auc = auc(recall, precision)
# 绘制PR曲线
plt.figure()
plt.plot(recall, precision, color='blue', lw=2, label='PR curve (area = %0.2f)' % pr_auc)
plt.xlabel('Recall')
plt.ylabel('Precision')
plt.title('Precision-Recall Curve (k=2)')
plt.legend(loc="lower left")
plt.grid(True)
plt.show()
结果:















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









